Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makale, Azure Databricks'te derin öğrenme tabanlı öneri modellerinin iki örneğini içerir. Derin öğrenme modelleri, geleneksel öneri modelleriyle karşılaştırıldığında daha yüksek kaliteli sonuçlar elde edebilir ve daha büyük miktarda veriye ölçeklendirilebilir. Bu modeller gelişmeye devam ettikçe Databricks, yüz milyonlarca kullanıcıyı işleyebilen büyük ölçekli öneri modellerini etkili bir şekilde eğitmeye yönelik bir çerçeve sağlar.
Genel bir öneri sistemi, diyagramda gösterilen aşamalarla huni olarak görüntülenebilir.
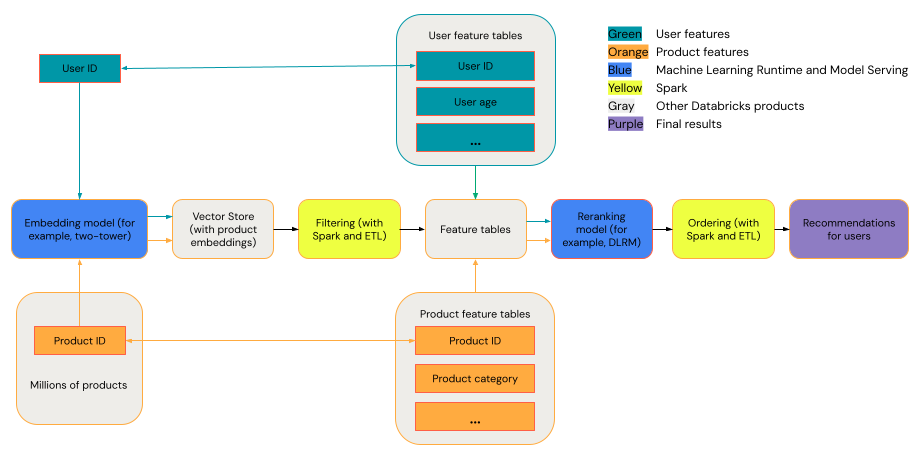
İki kuleli model gibi bazı modeller, bilgi alma modelleri olarak daha iyi performans gösterir. Bu modeller daha küçüktür ve milyonlarca veri noktasında etkili bir şekilde çalışabilir. DLRM veya DeepFM gibi diğer modeller, yeniden sıralama modelleri olarak daha iyi performans gösterir. Bu modeller daha fazla veri alabilir, daha büyüktür ve ayrıntılı öneriler sağlayabilir.
Gereksinimler
Databricks Runtime 14.3 LTS ML sürümü
Araçlar
Bu makaledeki örneklerde aşağıdaki araçlar gösterilmektedir:
- TorchDistributor: TorchDistributor, Databricks üzerinde büyük ölçekli PyTorch model eğitimi çalıştırmanızı sağlayan bir çerçevedir. Düzenleme için Spark kullanır ve kümenizde kullanılabilir olan sayıda GPU'ya ölçeklendirilebilir.
- Mozaik StreamingDataset: StreamingDataset, önceden oluşturma ve araya ekleme gibi özellikleri kullanarak Databricks'te büyük veri kümelerinde eğitimin performansını ve ölçeklenebilirliğini artırır.
- MLflow: MLflow parametreleri, ölçümleri ve model denetim noktalarını izlemenizi sağlar.
- TorchRec: Modern öneri sistemleri, yüksek kaliteli öneriler oluşturmak üzere milyonlarca kullanıcı ve öğeyi işlemek için arama tabloları ekleme özelliğini kullanır. Daha büyük ekleme boyutları model performansını artırır, ancak önemli GPU belleği ve çoklu GPU kurulumları gerektirir. TorchRec, öneri modellerini ve arama tablolarını birden çok GPU arasında ölçeklendirmek için bir çerçeve sağlayarak büyük eklemeler için idealdir.
Örnek: İki kuleli model mimarisi kullanan film önerileri
İki kuleli model, kullanıcı ve öğe verilerini birleştirmeden önce ayrı ayrı işleyerek büyük ölçekli kişiselleştirme görevlerini işlemek için tasarlanmıştır. Yüzlerce veya binlerce iyi kalite önerisini verimli bir şekilde üretebilme özelliğine sahiptir. Model genellikle üç giriş bekler: user_id özelliği, product_id özelliği ve kullanıcının, ürün etkileşiminin <pozitif mi (ürünü> satın alan kullanıcı) yoksa negatif mi (kullanıcı ürüne bir yıldız derecelendirmesi verdi) olduğunu tanımlayan ikili etiket. Modelin çıkışları, hem kullanıcılar hem de öğeler için eklemelerdir ve bunlar daha sonra kullanıcı öğesi etkileşimlerini tahmin etmek için genel olarak birleştirilir (genellikle noktalı ürün veya kosinüs benzerliği kullanılır).
İki kuleli model hem kullanıcılar hem de ürünler için eklemeler sağladığından, bu eklemeleri Mozaik AI Vektör Araması gibi bir vektör dizinine yerleştirebilir ve kullanıcılar ve öğeler üzerinde benzerlik arama benzeri işlemler gerçekleştirebilirsiniz. Örneğin, tüm öğeleri bir vektör deposuna yerleştirebilir ve her kullanıcı için vektör deposunu, kullanıcıya ait gömülerle benzerlik gösteren ilk yüz öğeyi bulmak amacıyla sorgulayabilirsiniz.
Aşağıdaki örnek not defteri, bir kullanıcının belirli bir filmi yüksek oranda derecelendirme olasılığını tahmin etmek için "Öğe Kümelerinden Öğrenme" veri kümesini kullanarak iki kuleli model eğitimini uygular. Dağıtılmış veri yükleme için Mozaik StreamingDataset, dağıtılmış model eğitimi için TorchDistributor ve model izleme ve günlüğe kaydetme için MLflow kullanır.
İki kuleli önerilen model not defteri
not defteri alma
Bu not defteri Databricks Marketi'nde de kullanılabilir: İki kuleli model not defteri
Not
- İki kuleli modele yönelik girdiler en sık olarak kategorik özellikler user_id ve product_id'dir. Model, hem kullanıcılar hem de ürünler için birden çok özellik vektörlerini destekleyecek şekilde değiştirilebilir.
- İki kuleli modelin çıkışları genellikle kullanıcının ürünle pozitif veya negatif bir etkileşime sahip olup olmayacağını gösteren ikili değerlerdir. Model regresyon, çok sınıflı sınıflandırma ve birden çok kullanıcı eyleminin olasılıkları (örneğin, kapatma veya satın alma) gibi diğer uygulamalar için değiştirilebilir. Rakip hedefler model tarafından oluşturulan eklemelerin kalitesini düşürebileceğinden karmaşık çıkışlar dikkatli bir şekilde uygulanmalıdır.
Örnek: Yapay veri kümesi kullanarak DLRM mimarisi eğitme
DLRM, kişiselleştirme ve öneri sistemleri için özel olarak tasarlanmış son sınıf bir sinir ağı mimarisidir. Kullanıcı öğesi etkileşimlerini etkili bir şekilde modellemek ve kullanıcı tercihlerini tahmin etmek için kategorik ve sayısal girişleri birleştirir. DLRM'ler genellikle hem seyrek özellikleri (kullanıcı kimliği, öğe kimliği, coğrafi konum veya ürün kategorisi gibi) hem de yoğun özellikleri (kullanıcı yaşı veya öğe fiyatı gibi) içeren girişleri bekler. DLRM'nin çıktısı genellikle tıklama oranları veya satın alma olasılığı gibi bir kullanıcı etkileşimi tahminidir.
DLRM'ler, büyük ölçekli verileri işleyebilen, çeşitli etki alanlarındaki karmaşık öneri görevleri için uygun hale getiren yüksek oranda özelleştirilebilir bir çerçeve sunar. İki kuleli mimariden daha büyük bir model olduğundan, bu model genellikle yeniden boyutlandırma aşamasında kullanılır.
Aşağıdaki örnek not defteri, yoğun (sayısal) özellikleri ve seyrek (kategorik) özellikleri kullanarak ikili etiketleri tahmin etmek için bir DLRM modeli oluşturur. Modeli eğitmek için yapay bir veri kümesi, dağıtılmış veri yükleme için Mozaik StreamingDataset, dağıtılmış model eğitimi için TorchDistributor ve model izleme ve günlüğe kaydetme için MLflow kullanır.
DLRM defter
not defteri alma
Bu not defteri, Databricks Pazarı'nda da mevcuttur: DLRM not defteri.
İki kuleli ve DLRM modellerinin karşılaştırması
Tabloda, hangi öneri modelinin kullanılacağını seçmek için bazı yönergeler gösterilmektedir.
| Model türü | Eğitim için gereken veri kümesi boyutu | Model boyutu | Desteklenen giriş türleri | Desteklenen çıkış türleri | Kullanım örnekleri |
|---|---|---|---|---|---|
| İki kuleli | Küçük | Küçük | Genellikle iki özellik (user_id, product_id) | Esas olarak ikili sınıflandırma ve ekleme oluşturma | Yüzlerce veya binlerce olası öneri oluşturma |
| DLRM | Daha büyük | Daha büyük | Çeşitli kategorik ve yoğun özellikler (user_id, cinsiyet, geographic_location, product_id, product_category, ...) | Çok sınıflı sınıflandırma, regresyon, diğerleri | Ayrıntılı seçme (onlarca yüksek oranda ilgili öğeyi önerme) |
Özetle, iki kuleli model en iyi şekilde binlerce iyi kalite önerisini çok verimli bir şekilde oluşturmak için kullanılır. Bir kablo sağlayıcısının film önerileri örnek olabilir. DLRM modeli, daha fazla veriye göre çok özel öneriler oluşturmak için en iyi şekilde kullanılır. Müşteriye satın alma olasılığı yüksek olan daha az sayıda ürün sunmak isteyen bir satıcı buna örnek olabilir.