Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Uyarlamalı sorgu yürütme (AQE), sorgu yürütme sırasında gerçekleşen sorgu yeniden iyileştirmesidir.
Çalışma zamanında yeniden iyileştirme yapmanın motivasyonu, Azure Databricks'in karıştırma ve yayın alışverişinin sonunda en güncel doğru istatistiklere sahip olmasıdır (AQE'de sorgu aşaması olarak adlandırılır). Sonuç olarak, Azure Databricks daha iyi bir fiziksel stratejiyi seçebilir, en uygun karıştırma sonrası bölüm boyutunu ve bölüm sayısını belirleyebilir veya dengesiz birleşim işleme gibi daha önce ipuçları gerektiren optimizasyonları gerçekleştirebilir.
bu, istatistik koleksiyonu açık olmadığında veya istatistikler eski olduğunda çok yararlı olabilir. Karmaşık bir sorgunun ortasında veya veri dengesizliği oluştuktan sonra statik olarak türetilmiş istatistiklerin yanlış olduğu yerlerde de yararlıdır.
Yetenekler
AQE varsayılan olarak etkindir. 4 ana özelliğe sahiptir:
- Sıralama birleştirme bağlantısını dinamik olarak yayınlama karma bağlantısına dönüştürür.
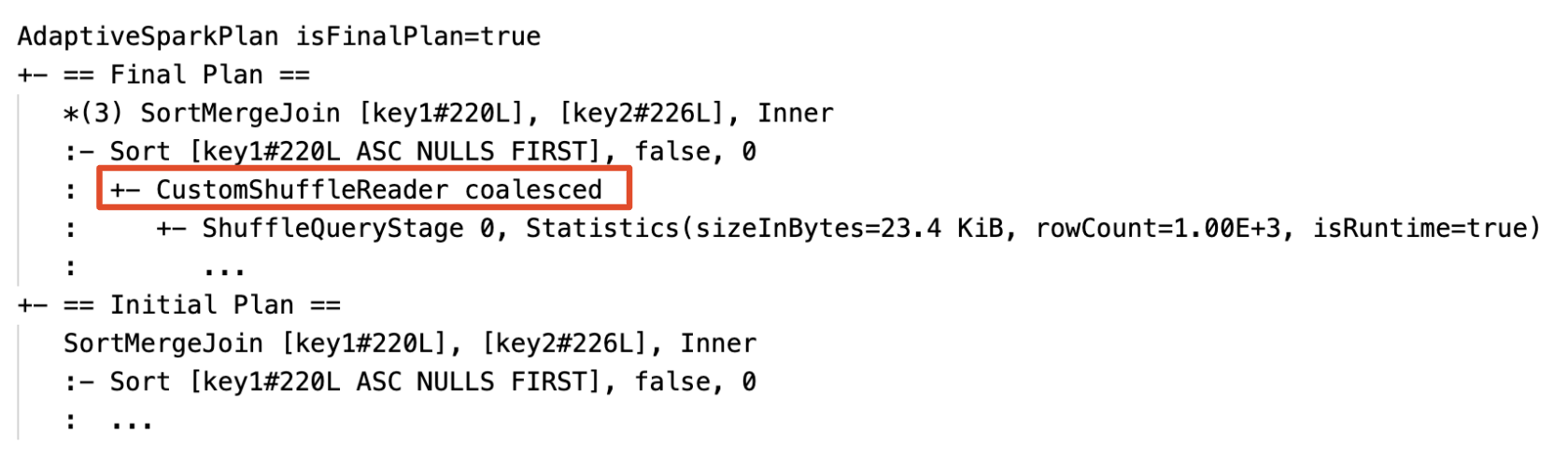
- Karıştırmalı değişimden sonra, bölümleri dinamik olarak birleştirir (küçük bölümleri daha makul boyutlardaki bölümler hâline getirir). Çok küçük görevler daha kötü G/Ç aktarım hızına sahiptir ve zamanlama ek yükü ve görev kurulumu ek yükünden daha fazla zarar görür. Küçük görevlerin birleştirilmesi, kaynak tasarrufu sağlar ve küme aktarım hızını artırır.
- Dengesiz görevleri, sıralama birleştirme ve karıştırma karma birleştirme işlemlerinde dinamik olarak işler, bunları gerekirse çoğaltarak kabaca eşit boyutlu görevlere böler.
- Dinamik olarak boş ilişkileri algılar ve iletir.
Uygulama
AQE, aşağıdaki tüm sorgular için geçerlidir:
- Yayın yapılmıyor
- En az bir değişim (genellikle birleştirme, toplama veya pencere olduğunda), bir alt sorgu veya her ikisini birden içerir.
AQE tarafından uygulanan sorguların tümü mutlaka yeniden iyileştirilmemiştir. Yeniden iyileştirme statik olarak derlenenden farklı bir sorgu planıyla gelebilir veya olmayabilir. Bir sorgunun planının AQE tarafından değiştirilip değiştirilmediğini belirlemek için aşağıdaki Sorgu planları bölümüne bakın.
Sorgu planları
Bu bölümde sorgu planlarını farklı şekillerde nasıl inceleyebileceğiniz açıklanır.
Bu bölümde:
- Spark kullanıcı arabirimi
DataFrame.explain()SQL EXPLAIN
Spark Kullanıcı Arabirimi
AdaptiveSparkPlan düğümü
AQE uygulanan sorgular genellikle her ana sorgunun veya alt sorgunun kök düğümü olarak bir veya daha fazla AdaptiveSparkPlan düğümü içerir.
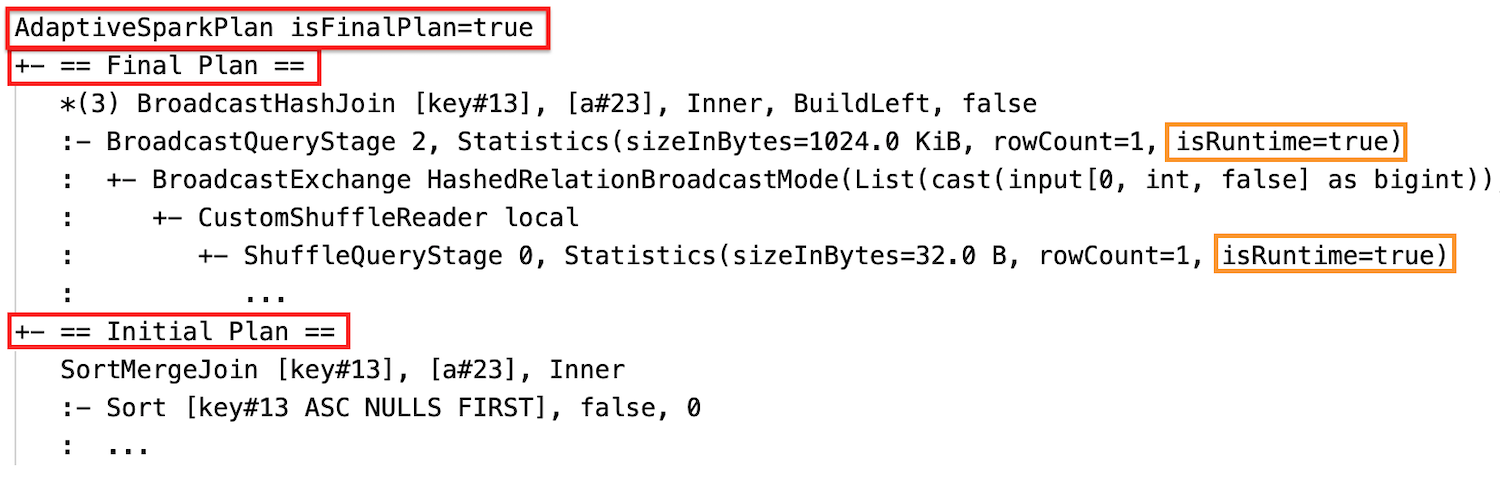
Sorgu çalışmadan önce veya çalıştırıldığında ilgili isFinalPlan düğümünün AdaptiveSparkPlan bayrağı falseolarak gösterilir; Sorgu yürütme tamamlandıktan sonra isFinalPlan bayrağı true. olarak değişir
Değişen plan
Yürütme ilerledikçe sorgu planı diyagramı gelişir ve yürütülmekte olan en güncel planı yansıtır. Önceden yürütülen ve ölçümlerin kullanılabildiği düğümler değişmez, ancak yürütülmeyen düğümler, yeniden iyileştirmeler sonucunda zaman içinde değişebilir.
Aşağıda bir sorgu planı diyagramı örneği verilmiştir:
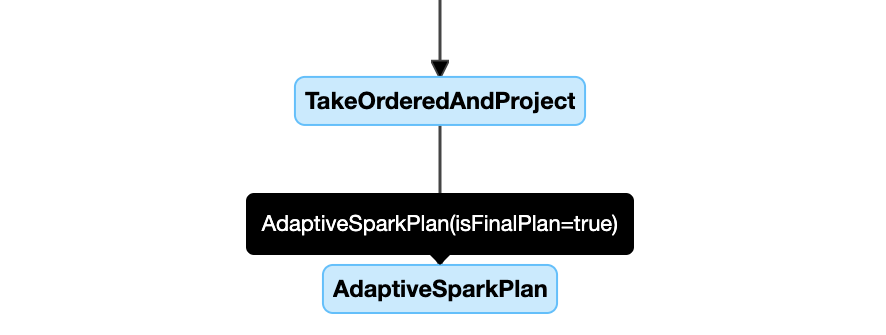
DataFrame.explain()
AdaptiveSparkPlan düğümü
AQE uygulanan sorgular genellikle her ana sorgunun veya alt sorgunun kök düğümü olarak bir veya daha fazla AdaptiveSparkPlan düğümü içerir. Sorgu çalışmadan önce veya çalıştırıldığında ilgili isFinalPlan düğümünün AdaptiveSparkPlan bayrağı falseolarak gösterilir; sorgu yürütme tamamlandıktan sonra, isFinalPlan bayrağı trueolarak değişir.
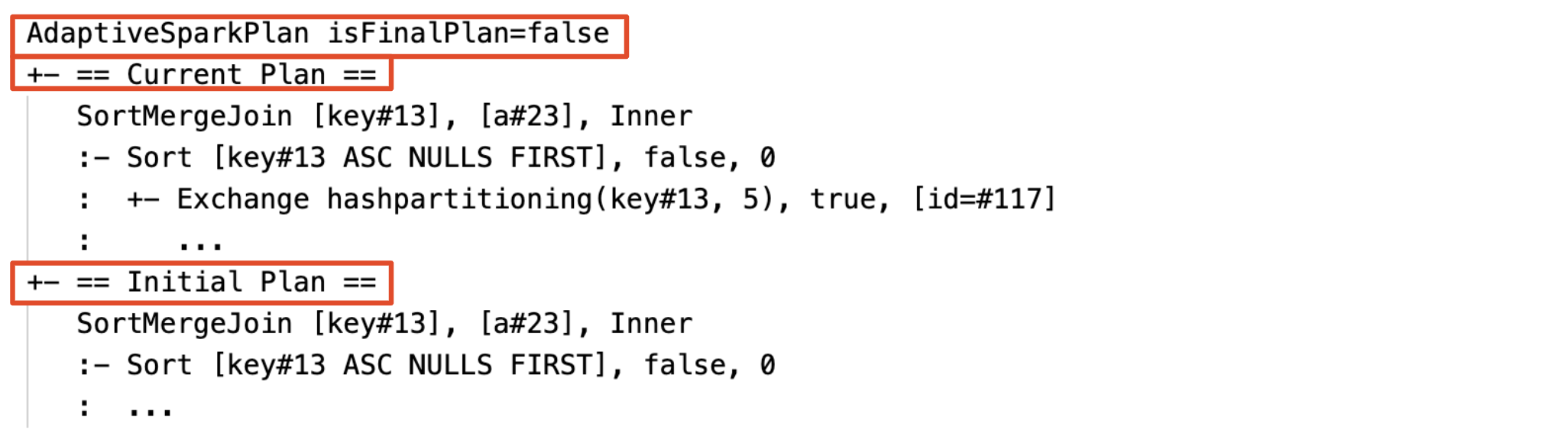
Şu andaki ve ilk plan
Her AdaptiveSparkPlan düğümün altında, yürütmenin tamamlanıp tamamlanmadığına bağlı olarak hem ilk plan (AQE iyileştirmelerini uygulamadan önceki plan) hem de geçerli veya son plan bulunur. Yürütme ilerledikçe geçerli plan gelişecektir.
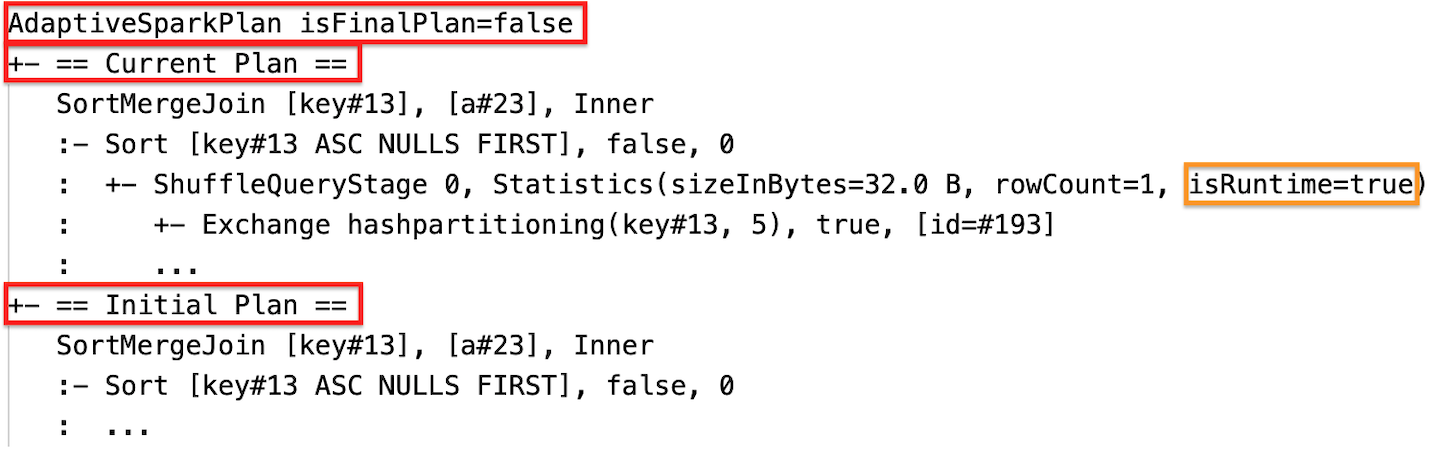
Çalışma zamanı istatistikleri
Her karıştırma ve yayın aşaması veri istatistikleri içerir.
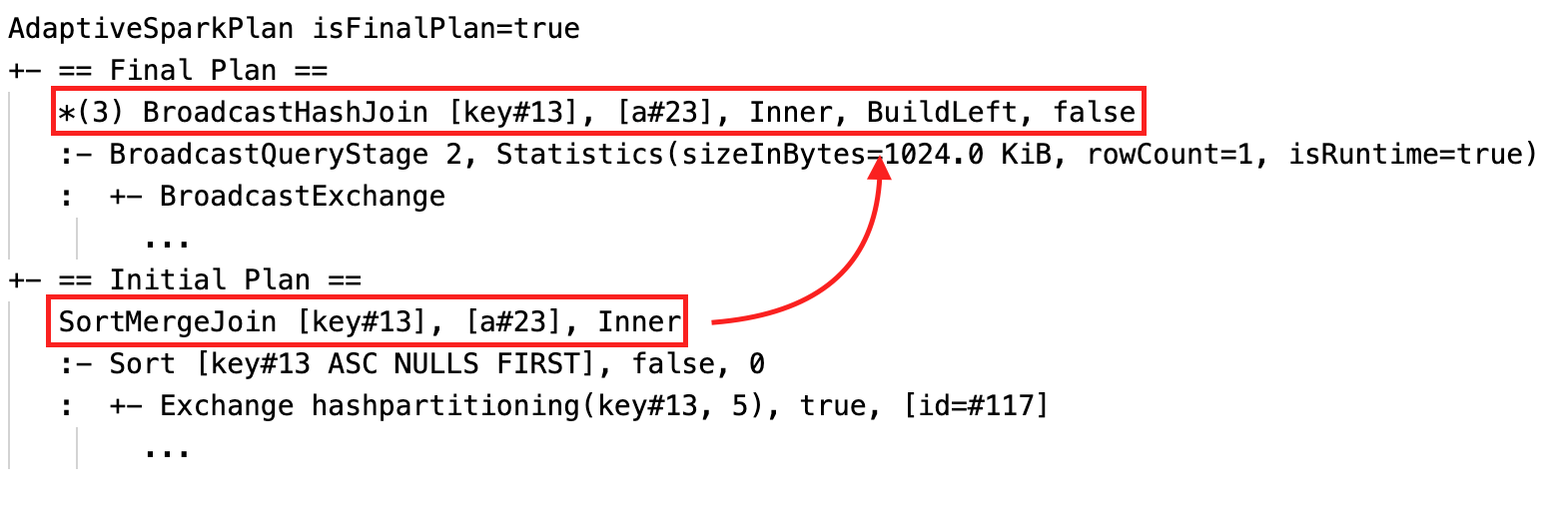
Aşama çalışmadan önce veya aşama çalışırken istatistikler derleme zamanı tahminleridir ve bayrak isRuntimefalseolur, örneğin: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Aşama yürütme tamamlandıktan sonra istatistikler çalışma zamanında toplanır ve bayrak isRuntimetrueolur, örneğin: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Aşağıda DataFrame.explain bir örnek verilmiştir:
Yürütmeden önce
yürütmeden önce
Yürütme sırasında
İdamdan sonra
Yürütme sonrası
SQL EXPLAIN
AdaptiveSparkPlan düğümü
AQE tarafından uygulanan sorgular genellikle her ana sorgunun veya alt sorgunun kök düğümü olarak bir veya daha fazla AdaptiveSparkPlan düğümü içerir.
Geçerli plan yok
SQL EXPLAIN sorguyu yürütmediğinden, geçerli plan her zaman ilk planla aynıdır ve AQE tarafından nelerin yürütüleceğini yansıtmaz.
Aşağıda bir SQL açıklama örneği verilmiştir:

Etkinliği
Bir veya daha fazla AQE iyileştirmesi geçerli olursa sorgu planı değişir. Bu AQE iyileştirmelerinin etkisi, geçerli ve son planlarla ilk plan ve bu planlardaki özel plan düğümleri arasındaki fark sayesinde gösterilmiştir.
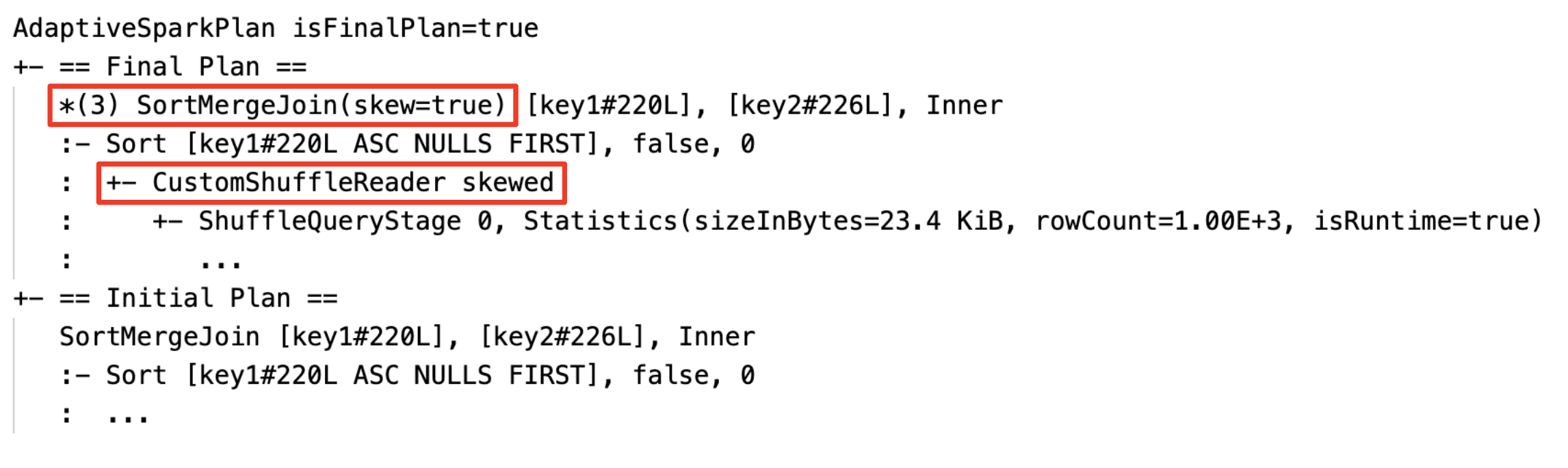
Sıralama birleşimini dinamik olarak yayın karma birleşimine dönüştürme: geçerli/son plan ile başlangıç planı arasında farklı fiziksel birleşim düğümleri
Bölümleri dinamik olarak birleştir:
CustomShuffleReaderözelliği ile düğümCoalesced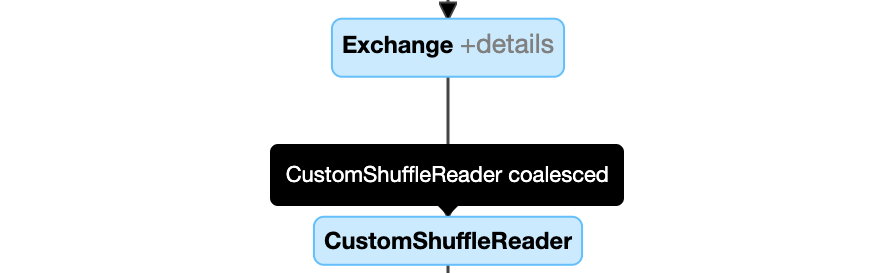
Düğüm
SortMergeJoinile alanisSkew, doğru olduğunda dinamik olarak dengesiz birleştirmeyi yönetmek üzere işleyin.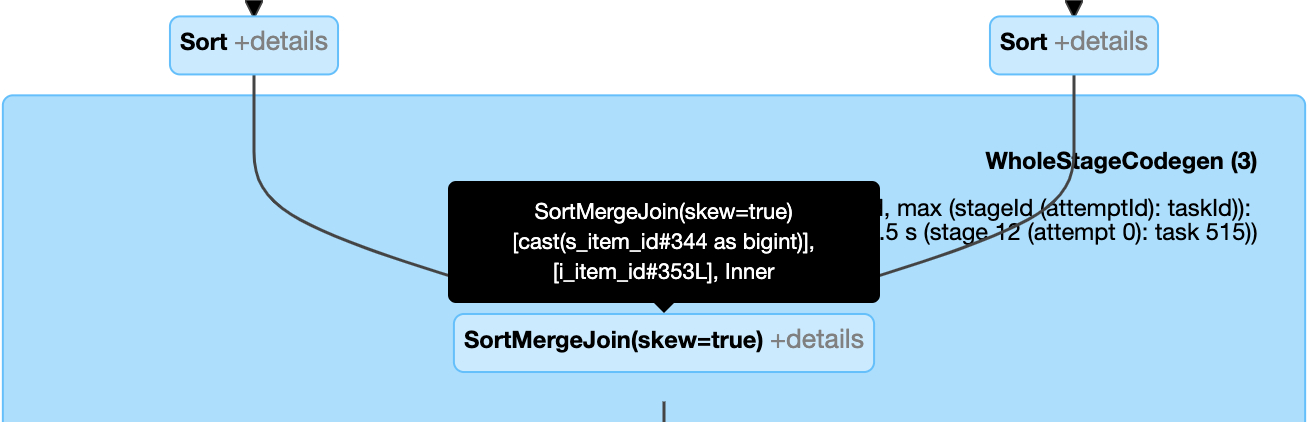
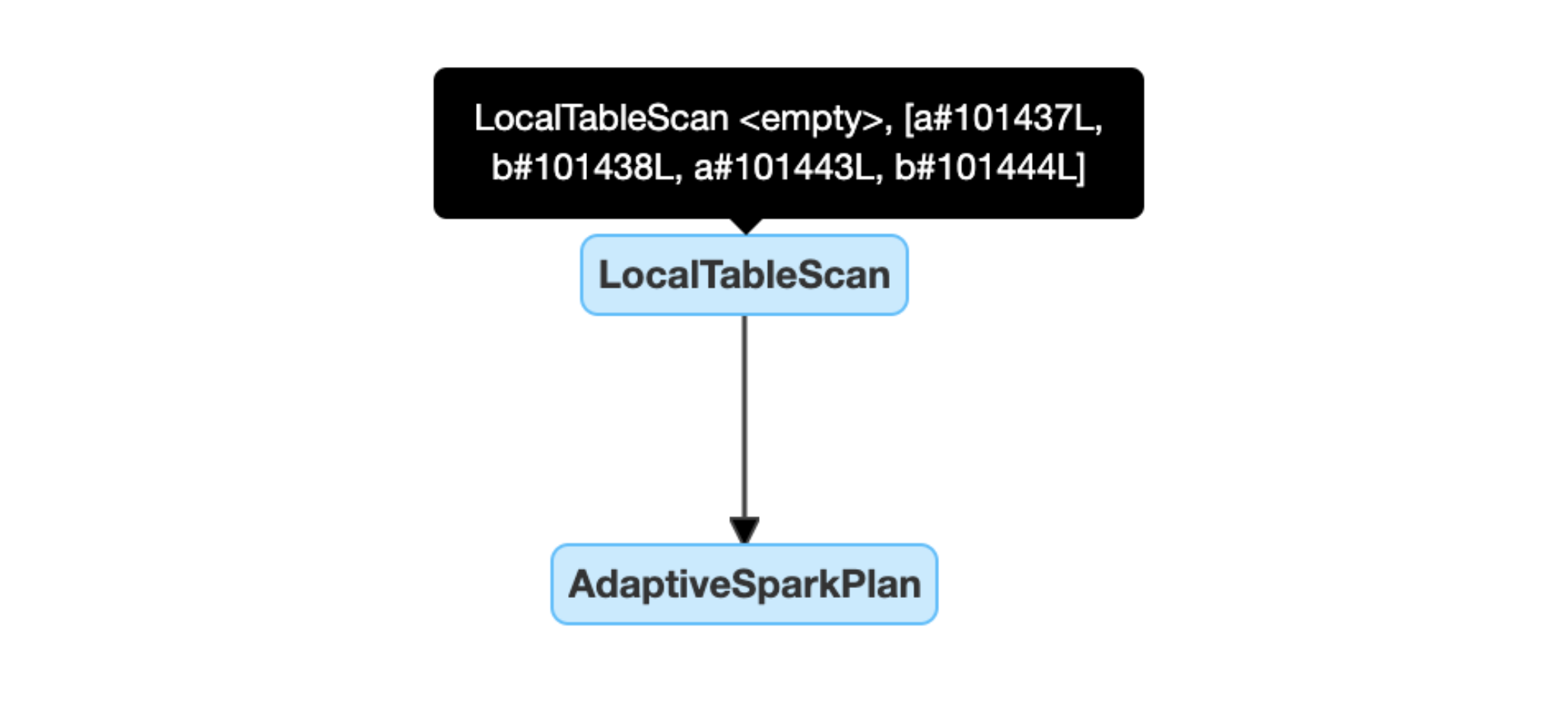
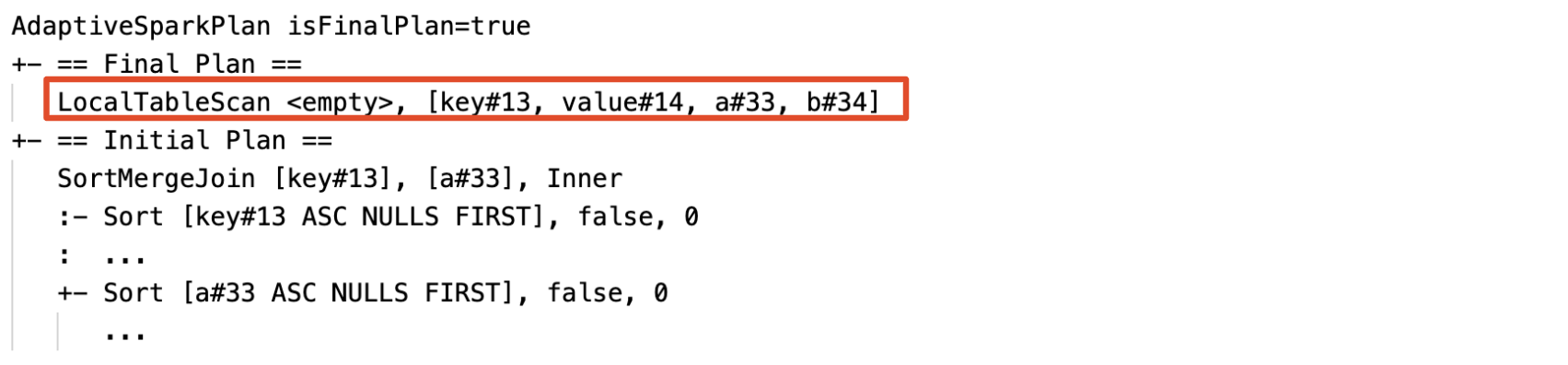
Boş ilişkileri dinamik olarak algılayın ve yayınlayın: Planın bir bölümü (veya tamamı), ilişki alanı boş olan LocalTableScan düğümüyle değiştirilir.
Konfigürasyon
Bu bölümde:
- Uyarlamalı sorgu yürütme etkinleştirme ve devre dışı bırakma
- Otomatik olarak iyileştirilmiş karıştırmayı etkinleştir
- Sıralama birleştirme birleştirmesini dinamik bir şekilde yayın karma birleştirmesine değiştirme
- Bölümleri dinamik olarak birleştir
- Skew join işlemini dinamik olarak yönet
- Boş ilişkileri dinamik olarak algılama ve yayma
Uyarlamalı sorgu yürütmeyi etkinleştirme ve devre dışı bırakma
| Mülk |
|---|
|
spark.databricks.optimizer.adaptive.enabled Tür: BooleanUyarlamalı sorgu yürütmeyi etkinleştirme veya devre dışı bırakma. Varsayılan değer: true |
Otomatik olarak optimize edilmiş karıştırmayı etkinleştir
| Mülk |
|---|
|
spark.sql.shuffle.partitions Tür: IntegerBirleştirmeler veya toplamalar için verileri karıştırırken kullanılacak varsayılan bölüm sayısı. auto değerinin ayarlanması, otomatik olarak iyileştirilmiş karıştırmayı etkinleştirir ve bu da bu sayıyı sorgu planına ve sorgu giriş veri boyutuna göre otomatik olarak belirler.Not: Yapılandırılmış Akış için bu yapılandırma aynı denetim noktası konumundan sorgu yeniden başlatmaları arasında değiştirilemez. Varsayılan değer: 200 |
Sıralama birleştirme eklemesini dinamik olarak yayın özeti birleştirmeye dönüştürme
| Mülk |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Tür: Byte StringÇalışma zamanında yayın katılımına geçmeyi tetikleme eşiği. Varsayılan değer: 30MB |
Bölümleri dinamik olarak birleştirme
| Mülk |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Tür: BooleanBölüm birleştirmeyi etkinleştirme veya devre dışı bırakma. Varsayılan değer: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Tür: Byte StringKoalesan işlemi sonrası hedeflenen boyut. Birleştirilmiş bölüm boyutları bu hedef boyuta yakın ancak bundan büyük olmayacaktır. Varsayılan değer: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Tür: Byte StringBirleştirildikten sonraki bölümlerin minimum boyutu. Birleştirilmiş bölüm boyutları bu boyuttan küçük olmayacaktır. Varsayılan değer: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Tür: IntegerBirleştirme sonrası minimum bölüm sayısı. Ayarın açık bir şekilde geçersiz kılınması nedeniyle önerilmez. spark.sql.adaptive.coalescePartitions.minPartitionSize.Varsayılan değer: Küme çekirdeklerinin sayısının 2 katı |
Çarpık birleşimi dinamik olarak ele alma
| Mülk |
|---|
|
spark.sql.adaptive.skewJoin.enabled Tür: BooleanEğme birleştirme işlemesini etkinleştirme veya devre dışı bırakma. Varsayılan değer: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Tür: IntegerOrtanca bölüm boyutuyla çarpıldığında bir bölmenin dengesiz olup olmadığını belirlemeye katkıda bulunan bir faktör. Varsayılan değer: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Tür: Byte StringBir bölmenin dengesizliğini belirlemede katkıda bulunan bir eşik. Varsayılan değer: 256MB |
(partition size > skewedPartitionFactor * median partition size) ve (partition size > skewedPartitionThresholdInBytes) her ikisi de true olduğunda, bir bölüm dengesiz olarak kabul edilir.
Boş ilişkileri dinamik olarak algılama ve yayma
| Mülk |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Tür: BooleanDinamik boş ilişki yayma özelliğinin etkinleştirilip etkinleştirilmeyileceği veya devre dışı bırakılmayacağı. Varsayılan değer: true |
Sık sorulan sorular (SSS)
Bu bölümde:
- AQE neden küçük bir birleştirme tablosu yayınlamadı?
- AQE etkinleştirildiğinde yayın birleştirme stratejisi ipucunu kullanmaya devam etmeli miyim?
- Eğme birleştirme ipucu ile AQE eğme birleştirme optimizasyonu arasındaki fark nedir? Hangisini kullanmalıyım?
- AQE birleşim sıralamamı neden otomatik olarak ayarlamadı?
- AQE neden veri dengesizliğimi algılamadı?
AQE neden küçük bir birleştirme tablosu yayınlamadı?
Yayınlanması beklenen ilişkinin boyutu bu eşiğin altına düşerse ancak yine de yayınlanmadıysa:
- Birleştirme türünü denetleyin. Belirli birleştirme türleri için yayın desteklenmez; örneğin, bir
LEFT OUTER JOIN'nin sol ilişkisi yayınlanamaz. - Ayrıca ilişki çok fazla boş bölüm içeriyor olabilir; bu durumda görevlerin büyük bölümü sıralı birleştirme ile hızlı bir şekilde tamamlanabilir veya dengesiz birleştirme işlemesi ile optimize edilebilir. AQE, boş olmayan bölümlerin yüzdesi
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin'den düşükse, bu tür sıralama-birleştirme işlemlerini yayın tabanlı karma birleştirmeler olarak değiştirmekten kaçınıyor.
AQE'nin etkin olduğu bir yayın birleştirme stratejisi ipucunu kullanmaya devam etmeli miyim?
Evet. Statik planlanan bir yayın birleşimi, genellikle AQE tarafından dinamik planlanan bir birleşimden daha yüksek performans gösterir çünkü AQE, her iki taraf için karıştırma gerçekleştirilene kadar (o sırada gerçek ilişki boyutları elde edilir) yayın birleşimine geçmeyebilir. Bu nedenle, sorgunuzu iyi biliyorsanız yayın ipucu kullanmak yine de iyi bir seçim olabilir. AQE, sorgu ipuçlarını statik iyileştirmeyle aynı şekilde dikkate alır, ancak yine de ipuçlarından etkilenmeyen dinamik iyileştirmeler uygulayabilir.
Eğme birleştirme ipucu ile AQE eğme birleştirme optimizasyonu arasındaki fark nedir? Hangisini kullanmalıyım?
AQE çapraz birleşimi tamamen otomatik olduğundan ve genel olarak ipucuna kıyasla daha iyi performans sergilediğinden, çapraz birleşim ipucunu kullanmak yerine AQE çapraz birleşim işlemesine güvenmeniz önerilir.
AQE birleşim sıralamamı neden otomatik olarak ayarlamadı?
Dinamik sıralama yeniden düzenlemesi, AQE'nin bir parçası değildir.
AQE neden veri dengesizliğimi algılamadı?
AQE'nin bir bölümü çarpık bölüm olarak algılaması için karşılanması gereken iki boyut koşulu vardır:
- Bölüm boyutu
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes'den daha büyük (varsayılan 256 MB) - Bölüm boyutunuz, tüm bölümlerin ortanca boyutunun çarpık bölüm faktörü
spark.sql.adaptive.skewJoin.skewedPartitionFactor(varsayılan 5) ile çarpılmasından daha büyüktür.
Buna ek olarak, belirli birleştirme türleri için eğiklik işleme desteği sınırlıdır; örneğin LEFT OUTER JOIN'da sadece sol taraftaki eğiklik iyileştirilebilir.
Miras
Spark 1.6'dan bu yana "Uyarlamalı Yürütme" terimi mevcut, ancak Spark 3.0'daki yeni AQE temelde farklıdır. İşlevsellik açısından Spark 1.6 yalnızca "dinamik olarak bölümleri birleştirme" bölümünü yapar. Teknik mimari açısından yeni AQE, çalışma zamanı istatistiklerine göre sorguların dinamik planlama ve yeniden planlanması çerçevesini oluşturur. Bu çerçeve, bu makalede açıkladığımız iyileştirmeler gibi çeşitli iyileştirmeleri destekler ve daha fazla olası iyileştirme sağlamak için genişletilebilir.