Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
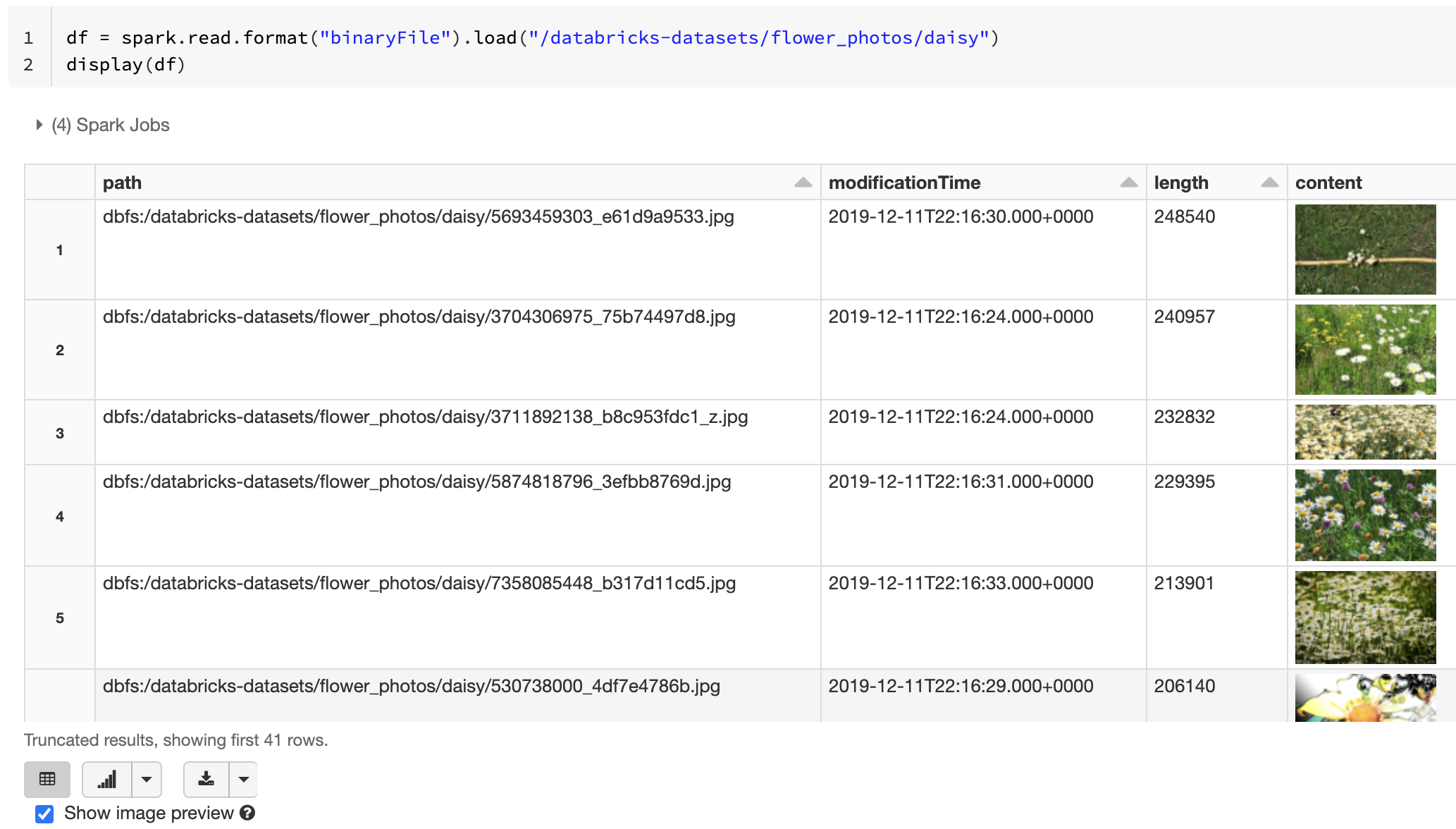
Azure Databricks ikili dosyaları okuyan ve her dosyayı dosyanın ham içeriğini ve meta verilerini içeren tek bir kayda dönüştüren ikili dosya veri kaynağını destekler. Genellikle aşağı akış işleme veya ML çıkarımı için görüntüler, ses veya PDF dosyaları gibi yapılandırılmamış verileri yüklemek için kullanılır. İkili dosyaları okumak için veri kaynağını format olarak binaryFilebelirtin.
Prerequisites
Azure Databricks ikili dosyaları kullanmak için ek yapılandırma gerektirmez.
Seçenekler
İkili dosya veri kaynağını yapılandırmak için DataFrameReader öğesinin .option() ve .options() yöntemlerini kullanın. Desteklenen seçeneklerin tam listesi için bkz. Spark API seçenekleri başvurusu.
Çıkış şeması
İkili dosya veri kaynağı, aşağıdaki sütunları ve tüm bölüm sütunlarını içeren bir DataFrame oluşturur:
-
path (StringType): Dosyanın yolu. -
modificationTime (TimestampType): Dosyanın değişiklik zamanı. Bazı Hadoop FileSystem uygulamalarında bu parametre kullanılamayabilir ve değer varsayılan değere ayarlanır. -
length (LongType): Dosyanın bayt cinsinden uzunluğu. -
content (BinaryType): Dosyanın içeriği.
Usage
Aşağıdaki örneklerde Spark DataFrame API'sini ve SQL'i kullanarak ikili dosyaları yükleme, dosya türüne göre filtreleme, görüntü önizlemelerini görüntüleme ve gelişmiş okuma performansı için Delta tablosuna kaydetme işlemleri gösterilmektedir.
İkili dosyaları okuma
Dönüştürme, görüntüleme veya aşağı akış işleme için ikili dosyaları bir DataFrame'e yüklemek için Apache Spark DataFrame API'sini kullanın.
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
display(df)
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
df.show()
SQL
SELECT path, length, modificationTime FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
Okuma seçeneklerini yapılandırma
Bölüm bulma davranışını koruyarak belirli bir glob deseniyle eşleşen yollara sahip dosyaları yüklemek için pathGlobFilter seçeneğini kullanabilirsiniz. Aşağıdaki kod, bölüm bulma ile giriş dizinindeki tüm JPG dosyalarını okur:
Python
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
Scala
val df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg'
)
Bölüm bulmayı yoksaymak ve giriş dizini altındaki dosyaları yinelemeli olarak aramak istiyorsanız recursiveFileLookup seçeneğini kullanın. Bu seçenek, adları gibi bir bölüm adlandırma düzenini izlemese bile, iç içe geçmiş dizinlerde arama yapar.
Aşağıdaki kod, giriş dizininden tüm JPG dosyalarını özyinelemeli olarak okur ve bölüm bulmayı yoksayar:
Python
df = (spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/"))
Scala
val df = spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg',
recursiveFileLookup => true
)
Görüntüleri yükleyin ve görüntüleyin
Databricks, görüntü verilerini yüklemek için ikili dosya veri kaynağını kullanmanızı önerir. Databricks display işlevi, ikili veri kaynağı kullanılarak yüklenen görüntü verilerinin görüntülenmesini destekler.
Yüklenen tüm dosyaların dosya adı görüntü uzantısına sahipse, görüntü önizlemesi otomatik olarak etkinleştirilir:
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df) # image thumbnails are rendered in the "content" column
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
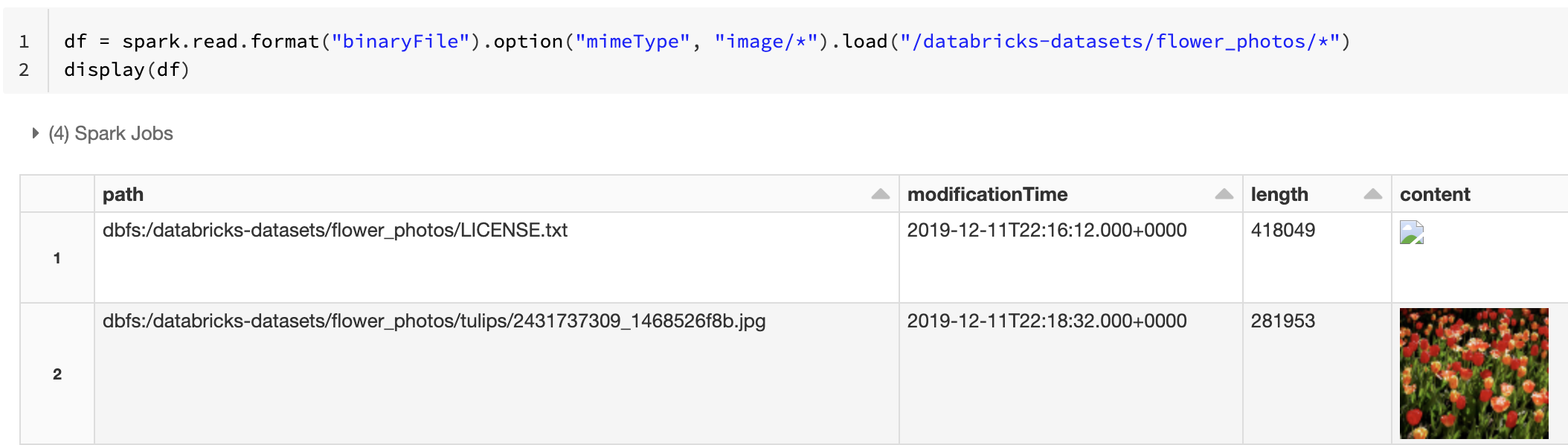
İkili sütuna açıklama eklemek için bir dize değeri olan mimeType ile "image/*" seçeneğini kullanarak alternatif olarak görüntü önizleme işlevselliğini etkinleştirebilirsiniz. Görüntülerin kodu, ikili içerikteki biçim bilgilerine göre çözüldü. Desteklenen görüntü türleri : bmp, gif, jpegve png. Desteklenmeyen dosyalar bozuk bir görüntü simgesi olarak görünür.
Python
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df)
Scala
val df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
mimeType => 'image/*'
)
Görüntü verilerini işlemek için önerilen iş akışı için bkz . Görüntü uygulamaları için başvuru çözümü.
Delta tablosuna kaydet
Verileri geri yüklediğinizde okuma performansını geliştirmek için Azure Databricks ikili dosyalardan yüklenen verilerin Delta tablosuna kaydedilmesini önerir.
Python
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Scala
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Ek kaynaklar
- Görüntü dosyalarını okuma: İş yükünüz ham baytlar yerine yükseklik, genişlik ve kanal verileri gibi yapılandırılmış görüntü alanları gerektiriyorsa, görüntü veri kaynağı kodu çözülen bir şema sağlar.