Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Genel Veri Koruma Yönetmeliği (GDPR) ve California Tüketici Gizliliği Yasası (CCPA), şirketlerin açık istekleri üzerine bir müşteri hakkında toplanan tüm kişisel bilgileri (PII) kalıcı ve tamamen silmesini gerektiren gizlilik ve veri güvenliği düzenlemeleridir. "Unutulma hakkı" (RTBF) veya "veri silme hakkı" olarak da bilinen silme isteklerinin belirli bir süre içinde (örneğin, bir takvim ayı içinde) yürütülmesi gerekir.
Bu makale, Databricks'te depolanan veriler üzerinde RTBF'yi uygulama konusunda size yol gösterir. Bu makaledeki örnek, bir e-ticaret şirketinin veri kümelerini modeller ve kaynak tablolardaki verileri silmeyi ve bu değişiklikleri aşağı akış tablolarına yayma işlemini gösterir.
"Unutulma hakkı" uygulama şeması
Aşağıdaki diyagramda "unutulma hakkı"nın nasıl uygulanacağı gösterilmektedir.
GDPR uyumluluğunu uygulamayı gösteren 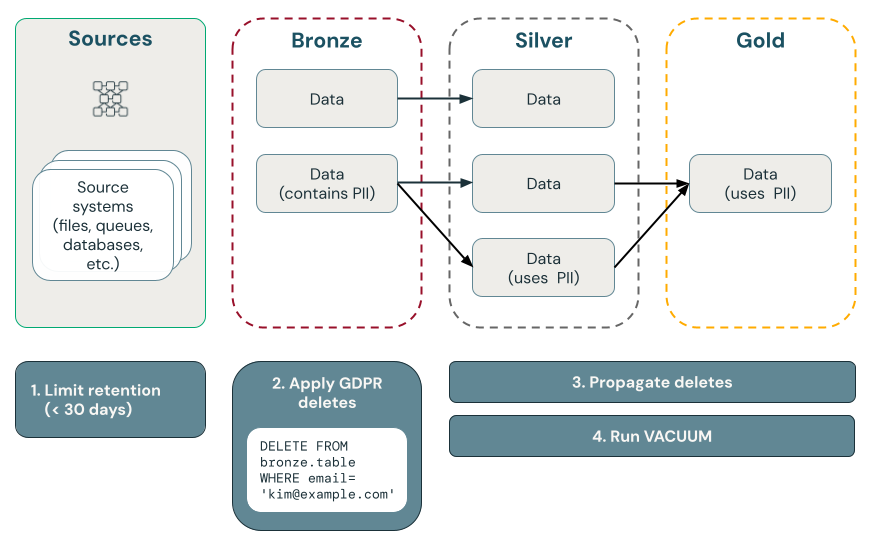
Delta Lake ile Noktası silindi
Delta Lake, ACID işlemleriyle büyük veri göllerinde nokta silme işlemlerini hızlandırarak, tüketici GDPR veya CCPA isteklerine yanıt olarak kişisel olarak doğrulanabilir bilgileri (PII) bulmanızı ve kaldırmanızı sağlar.
Delta Lake tablo geçmişini korur ve belirli bir nokta tarihi için sorguları ve geri alma işlemlerini kullanılabilir hale getirir. VACUUM işlevi, delta tablosu tarafından artık başvurulmamış ve belirtilen saklama eşiğinden daha eski olan veri dosyalarını kaldırır ve verileri kalıcı olarak siler. Varsayılanlar ve öneriler hakkında daha fazla bilgi edinmek için Delta Lake tablo geçmişiyle çalışmabölümüne bakın.
Silme vektörleri kullanılırken verilerin silindiğinden emin olun
Silme vektörlerinin etkinleştirildiği tablolar için, kayıtları sildikten sonra, temel alınan kayıtları kalıcı olarak silmek için de komutunu çalıştırmanız REORG TABLE ... APPLY (PURGE) gerekir. Buna Delta Lake tabloları, malzemeleştirilmiş görünümler ve akış tabloları dahildir. Bkz Parquet veri dosyalarına değişiklik uygulama.
Yukarı akış kaynaklarındaki verileri silme
GDPR ve CCPA, Kafka, dosyalar ve veritabanları gibi Delta Lake dışındaki kaynaklardaki veriler de dahil olmak üzere tüm veriler için geçerlidir. Databricks'teki verileri silmeye ek olarak kuyruklar ve bulut depolama gibi yukarı akış kaynaklarındaki verileri silmeyi de unutmamanız gerekir.
Tam silme, gizlemeye tercih edilir
Verileri silme ve gizleme arasında seçim yapmanız gerekir. Gizleme, takma ad, veri maskeleme vb. kullanılarak uygulanabilir. Ancak, en güvenli seçenek tamamen silinmektir çünkü uygulamada yeniden kimlik doğrulama riskini ortadan kaldırmak genellikle PII verilerinin tamamen silinmesini gerektirir.
Bronz katmandaki verileri silin ve silmeleri gümüş ve altın katmanlara yayma
GDPR ve CCPA uyumluluğunu, silme isteklerini içeren bir kontrol tablosunu sorgulayan zamanlanmış bir iş tarafından yönlendirilen bronz katmandaki verileri silmeye başlayarak başlatmanızı öneririz. Veriler bronz katmandan silindikten sonra değişiklikler gümüş ve altın katmanlara yayılabilir.
Geçmiş dosyalardan verileri kaldırmak için tabloları düzenli olarak tutma
Varsayılan olarak Delta Lake, silinen kayıtlar dahil olmak üzere tablo geçmişini 30 gün boyunca korur ve zaman yolculuğu ve geri alma işlemleri için kullanılabilir hale getirir. Ancak verilerin önceki sürümleri kaldırılsa bile, veriler yine de bulut depolamada tutulur. Bu nedenle, verilerin önceki sürümlerini kaldırmak için tabloları ve görünümleri düzenli olarak tutmanız gerekir. Önerilen yol, Unity Catalog tarafından yönetilen tablolar için tahmine dayalı iyileştirme , hem akış tablolarını hem de maddileştirilmiş görünümleri akıllı bir şekilde korur.
- Tahmine dayalı iyileştirme ile yönetilen tablolar için Lakeflow Bildirimli İşlem Hatları, kullanım desenlerine göre hem akış tablolarını hem de gerçekleştirilmiş görünümleri akıllı bir şekilde korur.
- Tahmine dayalı iyileştirme etkinleştirilmemiş tablolar için Lakeflow Bildirimli İşlem Hatları, akış tablolarının ve gerçekleştirilmiş görünümlerin güncelleştirilmesini izleyen 24 saat içinde bakım görevlerini otomatik olarak gerçekleştirir.
Tahmine dayalı iyileştirme veya Lakeflow Bildirimli İşlem Hatları kullanmıyorsanız, verilerin önceki sürümlerini kalıcı olarak kaldırmak için Delta tablolarında bir VACUUM komut çalıştırmanız gerekir. Varsayılan olarak, bu, yapılandırılabilirbir ayar olan zaman yolculuğu özelliklerini 7 güne indirir ve söz konusu verilerin geçmiş sürümlerini de bulut depolama alanından kaldırır.
Bronz katmandan PII verilerini silme
Göl evi tasarımınıza bağlı olarak, PII ile PII olmayan kullanıcı verileri arasındaki bağlantıyı kesebilirsiniz. Örneğin, e-posta gibi doğal bir anahtar yerine user_id gibi doğal olmayan bir anahtar kullanıyorsanız PII verilerini silebilirsiniz; bu da PII olmayan verileri yerinde bırakır.
Bu makalenin geri kalanında, RTBF'yi tüm bronz tablolardan kullanıcı kayıtlarını tamamen silerek ele alır. Aşağıdaki kodda gösterildiği gibi bir DELETE komutu yürüterek verileri silebilirsiniz:
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
Aynı anda çok sayıda kaydı birlikte silerken MERGE komutunu kullanmanızı öneririz. Aşağıdaki kod, gdpr_control_table sütunu içeren user_id adlı bir denetim tablonuz olduğunu varsayar. Bu tabloya "unutulma hakkı" isteyen her kullanıcı için bu tabloya bir kayıt eklersiniz.
MERGE komutu, eşleşen satırların koşulunu belirtir. Bu örnekte, target_table kayıtları gdpr_control_tabletemelinde user_id'daki kayıtlarla eşleştirir. Eşleşme varsa (örneğin, hem user_id'de hem de target_table'de gdpr_control_table olması), target_table içindeki satır silinir. Bu MERGE komutu başarılı olduktan sonra, isteğin işlendiğini onaylamak için denetim tablosunu güncelleştirin.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Bronz katmandaki değişiklikleri gümüş ve altın katmanlara yaymak
Bronz katmandaki veriler silindikten sonra, değişiklikleri gümüş ve altın katmanlardaki tablolara yaymalısınız.
Gerçekleştirilmiş görünümler: Silme işlemlerini otomatik olarak işleme
Gerçekleştirilmiş görünümler, kaynaklarda silme işlemlerini otomatik olarak işler. Bu nedenle, gerçekleştirilmiş bir görünümün kaynaktan silinmiş verileri içermediğinden emin olmak için özel bir şey yapmanız gerekmez. Silme işlemlerinin tamamen işlendiğinden emin olmak için malzemeleşmiş bir görünümü yenilemeniz ve bakım yapmanız gerekir.
Gerçekleştirilmiş bir görünüm, her zaman doğru sonucu döndürür çünkü, eğer tam yeniden hesaplamadan daha ucuzsa, artımlı hesaplama kullanılır; ancak bu hiçbir zaman doğruluğu riske atmaz. Başka bir deyişle, bir kaynaktan veri silmek maddi bir görünümün tamamen yeniden hesaplanmasına neden olabilir.
Silme işlemlerinin otomatik olarak nasıl işleneceğini gösteren 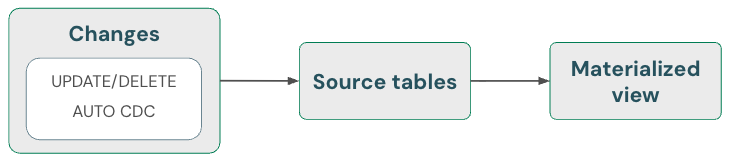
Akış tabloları: skipChangeCommits kullanarak verileri silme ve akış kaynağını okuma
Akış tabloları yalnızca ekleme verilerini işleyebilir. Yani akış tabloları, akış kaynağında yalnızca yeni veri satırlarının gösterilmesini bekler. Akış için kullanılan kaynak tablodan herhangi bir kaydı güncelleştirme veya silme gibi diğer işlemler desteklenmez ve akışı bozar.
akış tablolarında silme işlemlerinin nasıl işleneceğini gösteren 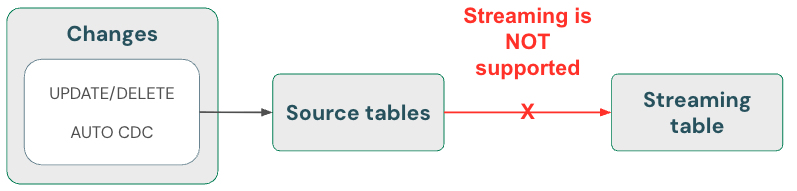
Akış yalnızca yeni verileri işlediği için, verilerdeki değişiklikleri kendiniz işlemeniz gerekir. Önerilen yöntem: (1) akış kaynağındaki verileri silme, (2) akış tablosundaki verileri silme ve ardından (3) skipChangeCommitskullanmak için akış okumasını güncelleştirme. Bu bayrak Databricks'e akış tablosunun güncelleştirmeler veya silmeler gibi eklemeler dışında herhangi bir şeyi atlanması gerektiğini gösterir.
skipChangeCommits kullanan bir GDPR uyumluluk yöntemini gösteren 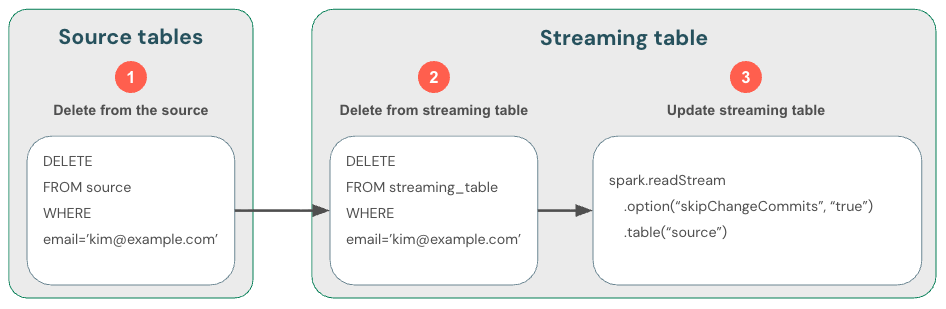
Alternatif olarak, (1) kaynaktan veri silebilir, (2) akış tablosundan silebilir ve ardından (3) akış tablosunu tam olarak yenileyebilirsiniz. Akış tablosunu tamamen yenilediğinizde, tablonun akış durumunu temizler ve tüm verileri yeniden işler. Saklama süresini aşan herhangi bir yukarı akış veri kaynağı (örneğin, verileri 7 gün sonra eskiten bir Kafka konusu) yeniden işlenmez ve bu da veri kaybına neden olabilir. Bu seçenek yalnızca geçmiş verilerin kullanılabilir olduğu ve yeniden işlenmesinin maliyetli olmayacağı senaryoda akış tabloları için önerilir.
Akış tablosunda tam yenileme gerçekleştiren GDPR uyumluluk yöntemini gösteren 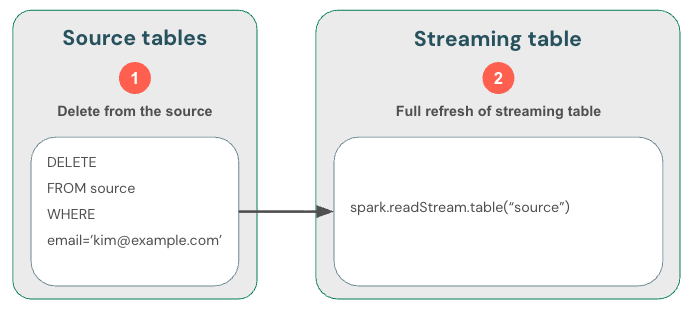
Delta tabloları: readChangeFeed kullanarak silmeleri işleme
Normal Delta tabloları, yukarı akış silme işlemlerinin özel bir işlemesini içermez. Bunun yerine, silmeleri onlara yaymak için kendi kodunuzu yazmanız gerekir (örneğin, spark.readStream.option("readChangeFeed", true).table("source_table")).
Örnek: E-ticaret şirketi için GDPR ve CCPA uyumluluğu
Aşağıdaki diyagramda GDPR & CCPA uyumluluğunun uygulanması gereken bir e-ticaret şirketi için madalyon mimarisi gösterilmektedir. Kullanıcının verileri silinmiş olsa da, aşağı akış toplamalarındaki etkinliklerini saymak isteyebilirsiniz.
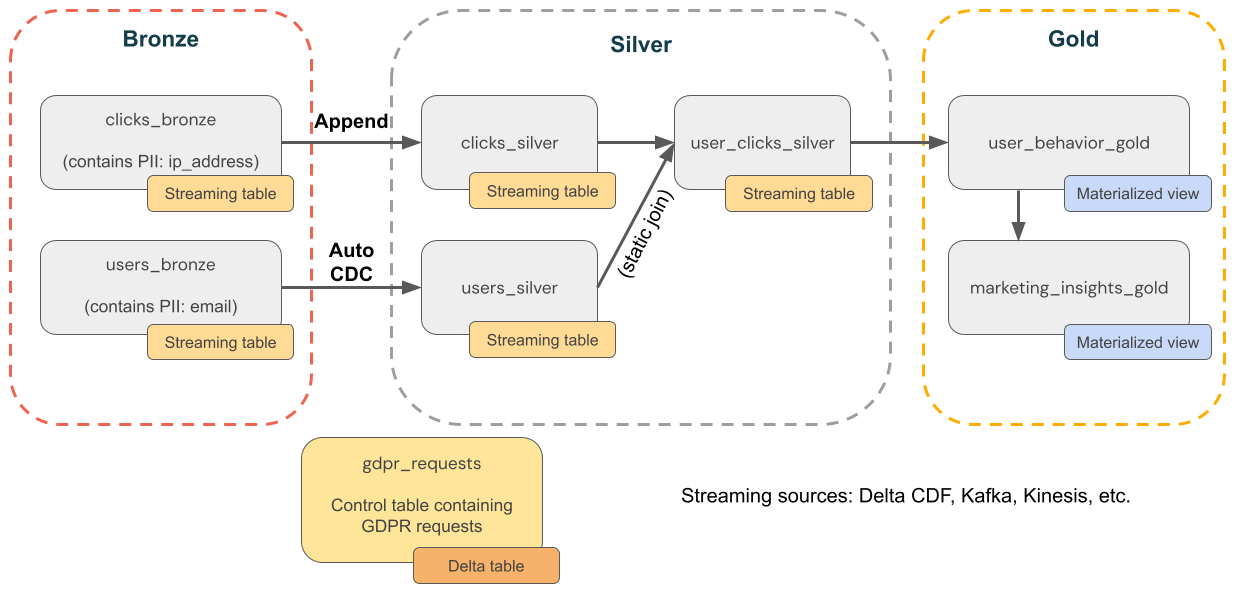
-
bronz katman
-
users- Kullanıcı boyutları. PII içerir (örneğin, e-posta adresi). -
clickstream- Tıklama olayları. PII içerir (örneğin, IP adresi). -
gdpr_requests- "Unutulma hakkı"na tabi kullanıcı kimliklerini içeren denetim tablosu.
-
-
Gümüş katmanı
-
clicks_hourly- Saatteki toplam tıklama sayısı. Bir kullanıcıyı silerseniz, yine de tıklamalarını saymak istersiniz. -
clicks_by_user- Kullanıcı başına toplam tıklama sayısı. Bir kullanıcıyı silerseniz, tıklamalarını saymak istemezsiniz.
-
-
Gold katmanı
-
revenue_by_user- Her kullanıcının toplam harcaması.
-
1. Adım: Tabloları örnek verilerle doldurma
Aşağıdaki kod şu iki tabloyu oluşturur:
-
source_userskullanıcılar hakkında boyutlu veriler içerir. Bu tabloemailadlı bir PII sütunu içerir. -
source_clicks, kullanıcılar tarafından gerçekleştirilen etkinliklerle ilgili olay verilerini içerir.ip_addressadlı bir PII sütunu içerir.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write..mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
2. Adım: PII verilerini işleyen bir işlem hattı oluşturma
Aşağıdaki kod, yukarıda gösterilen madalyon mimarisinin bronz, gümüş ve altın katmanlarını oluşturur.
import dlt
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dlt.expect_or_drop('valid_email', "email IS NOT NULL")
def users_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dlt.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dlt.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dlt.table(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
3. Adım: Kaynak tablolardaki verileri silme
Bu adımda, PII'nin bulunduğu tüm tablolardaki verileri silersiniz.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
4. Adım: Etkilenen akış tablolarının tanımlarına skipChangeCommits ekleme
Bu adımda, Lakeflow Deklaratif İşlem Hatlarına ekleme olmayan satırları atlamalarını belirtmeniz gerekir. skipChangeCommits seçeneğini aşağıdaki yöntemlere ekleyin. Gerçekleştirilmiş görünümlerin tanımlarını güncelleştirmeniz gerekmez çünkü bunlar güncelleştirmeleri ve silmeleri otomatik olarak işler:
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
Aşağıdaki kod, users_bronze yönteminin nasıl güncelleştirileceklerini gösterir:
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
İşlem hattını yeniden çalıştırdığınızda başarıyla güncelleştirilir.