Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfa, Delta tablolarının Spark Yapılandırılmış Akışı ile readStream ve writeStream için kaynak ve havuz olarak nasıl kullanılacağını açıklar. Delta Lake, akış sistemleri ve dosyaları için yaygın performans ve güvenilirlik sorunlarını çözer. Avantajlara şunlar dahildir:
- Düşük gecikme süresiyle üretilen küçük dosyaları birleştirir ve performansı geliştirir.
- Birden fazla akışla (veya eşzamanlı toplu işlerle) "tam olarak bir kez" işlemeyi koruyun.
- Dosyaları akış kaynağı olarak kullanırken yeni dosyaları verimli bir şekilde keşfedin.
Databricks SQL'de akış tablolarını kullanarak veri yüklemeyi öğrenmek için bkz. Databricks SQL'de akış tablolarını kullanma.
Delta Lake ile akış-statistik birleşimleri için bakınız: Akış-statistik birleşimleri.
Delta tablolarını havuz olarak kullanma
Yapılandırılmış Akış kullanarak Delta tablosuna veri yazabilirsiniz. Delta Lake işlem günlüğü, tabloda eşzamanlı olarak çalışan başka akışlar veya toplu sorgular olsa bile tam olarak bir kez işlemeyi garanti eder.
Yapılandırılmış Akış havuzu kullanarak Delta tablosuna yazdığınızda epochId = -1 ile boş işlemeler görebilirsiniz. Bunlar beklenir ve genellikle gerçekleşir:
- Her akış sorgusu çalıştırmasının ilk toplu işleminde (bu,
Trigger.AvailableNowiçin her toplu işlemde gerçekleşir). - Şema değiştirildiğinde (sütun ekleme gibi).
Bu boş işlemeler kasıtlıdır ve bir hataya işaret etmemektedir. Sorgunun doğruluğunu veya performansını önemli bir şekilde etkilemez.
Note
Delta Lake işlevi Delta Lake VACUUM tarafından yönetilmeyen tüm dosyaları kaldırır ancak ile _başlayan dizinleri atlar. gibi <table-name>/_checkpointsbir dizin yapısı kullanarak Delta tablosu için denetim noktalarını diğer veri ve meta verilerin yanı sıra güvenle depolayabilirsiniz.
Ölçümlerle iş listesini izleme
Akış sorgusu işleminin iş yükü miktarını izlemek için aşağıdaki ölçümleri kullanın:
-
numBytesOutstanding: Birikmiş işlem sırasındaki henüz işlenmemiş bayt sayısı. -
numFilesOutstanding: Geri kütükte henüz işlenecek dosya sayısı. -
numNewListedFiles: Bu işlem grubunun birikimini hesaplamak için listelenen Delta Lake dosyalarının sayısı. -
backlogEndOffset: Geri logu hesaplamak için kullanılan Delta tablosu sürümü.
Not defterinde, akış sorgusu ilerleme durumu panosundaki Ham Veri sekmesinin altında bu ölçümleri görüntüleyin:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Ekleme modu
Varsayılan olarak, akışlar ekleme modunda çalışır ve tabloya yalnızca yeni kayıtlar ekler.
Tablolara akış yaparken toTable yöntemini kullanın.
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Tamamlama modu
Her toplu işlemden sonra tablonun tamamını değiştirmek için Tam mod ile Yapılandırılmış Akış'ı kullanın. Örneğin, toplu bir özet olay tablosunu müşteriye göre sürekli güncelleştirebilirsiniz:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Katı gecikme süresi gereksinimleri olmayan uygulamalar için, gibi AvailableNowtek seferlik tetikleyicilerle bilgi işlem kaynaklarından ve maliyetlerinden tasarruf edebilirsiniz. Örneğin, bu tetikleyiciyi kullanarak belirli bir zamanlamaya göre özet toplama tablolarını güncelleştirin ve yalnızca son güncelleştirmeden sonra gelen yeni verileri işleyin. Bkz AvailableNow. Artımlı toplu işlem.
Kaynak Delta tablolarındaki değişiklikleri işleme
Yapılandırılmış Akış, Delta tablolarını artımlı olarak okur. Bir akış sorgusu bir Delta tablosundan okuma yaptığında, yeni tablo sürümleri kaynak tabloya işlendiğinde, yeni kayıtlar idempotent bir şekilde işlenir. Yapılandırılmış Akış yalnızca ekleme girişlerini kabul eder ve kaynak Delta tablosunda herhangi bir değişiklik olursa bir özel durum oluşturur. Örneğin, bir UPDATE, DELETE, MERGE INTOveya OVERWRITE işlemi akış sorgusu tarafından okunan bir kaynak Delta tablosunu değiştirirse, akış bir hatayla başarısız olur.
Kullanım örneğine bağlı olarak kaynak Delta tablolarında yukarı akış değişikliklerini işlemek için dört tipik yaklaşım vardır. Referans tablosu ve her biri hakkında ayrıntılar aşağıda verilmiştir.
| Yaklaşım | Pros | Cons |
|---|---|---|
skipChangeCommits |
Basit, karmaşık mantık yazmanızı gerektirmez. Yukarı akış değişikliklerinin ayrı olarak işlendiği yalnızca ekleme işlemleri veya hatalı bir kaydı geçici olarak işlemek için kullanışlıdır. | Değişiklikleri yaymaz ve yalnızca ekleme işlemlerini gerçekleştirir. |
| Tam yenileme | Ayrıca basit, karmaşık mantık yazmanızı gerektirmez. Nadir yukarı akış değişiklikleri olan küçük veri kümeleri için kullanışlıdır. | Büyük veri kümeleri için pahalıdır. Tüm aşağı akış tablolarının yeniden işlenmesini gerektirir. |
| Veri akışını değiştir | Tüm değişiklik türlerini (eklemeler, güncelleştirmeler ve silmeler) işleyin. Databricks, mümkün olduğunda doğrudan tablodan değil Delta tablosunun CDC beslemesinden akış yapmayı önerir. | Her değişiklik türünü işlemek için daha karmaşık bir mantık yazmanızı gerektirir. |
| Gerçekleştirilmiş görünümler | Otomatik değişiklik yayma özelliğine sahip Yapılandırılmış Akış'a basit alternatif. | Daha yüksek gecikme süresi. Yalnızca Lakeflow Spark Bildirimli İşlem Hatları ve Databricks SQL'de kullanılabilir. |
ile yukarı akış değişiklik işlemelerini atla skipChangeCommits
Yalnızca eklemeleri işlemek ve mevcut kayıtları silen veya değiştiren işlemleri yoksaymak için skipChangeCommits olarak ayarlayın. Bu, mevcut verilerde yapılan değişikliklerin akış üzerinden yayılması gerekmediğinde veya bu değişiklikleri işlemek için ayrı mantık tercih ettiğinizde kullanışlıdır. Bir kerelik değişiklikleri geçici olarak yoksaymak istiyorsanız skipChangeCommits'yi açıp kapatabilirsiniz.
Databricks, değişiklik veri akışlarını kullanmayan çoğu iş yükü için kullanılmasını skipChangeCommits önerir.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Delta tablosunun şeması, akış veri okuma işlemi tabloda başladıktan sonra değişirse, sorgu başarısız olur. Çoğu şema değişikliğinde, şema uyuşmazlıklarını çözmek ve işlemeye devam etmek için akışı yeniden başlatabilirsiniz.
Databricks Runtime 12.2 LTS ve altında, sütunları yeniden adlandırma veya bırakma gibi eklemeli olmayan şema evriminden geçmiş sütun eşlemesi etkinleştirilmiş bir Delta tablosundan akış yapamazsınız. Ayrıntılar için bkz. Sütun eşleme ve akış.
Note
Databricks Runtime 12.2 LTS ve üzeri sürümlerde skipChangeCommits, ignoreChanges yerine kullanılır. Databricks Runtime 11.3 LTS ve altında ignoreChanges desteklenen tek seçenektir. Ayrıntılar için Eski seçenek: ignoreChanges bölümüne bakın.
Eski seçenek: ignoreDeletes
ignoreDeletes yalnızca bölüm sınırlarında (tam bölüm silme) verileri silen işlemleri işleyen eski bir seçenektir. Bölüm dışı silmeleri, güncelleştirmeleri veya diğer değişiklikleri işlemeniz gerekiyorsa, bunun yerine kullanın skipChangeCommits .
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Eski seçenek: ignoreChanges
ignoreChanges Databricks Runtime 11.3 LTS ve altında kullanılabilir. Databricks Runtime 12.2 LTS ve üzeri sürümlerinde bu, skipChangeCommits ile değiştirilir.
ignoreChanges Etkinleştirildiğinde, kaynak tablodaki yeniden yazılan veri dosyaları , UPDATEMERGE INTO , (bölümler içinde) veya DELETEgibi OVERWRITEbir veri değişikliği işleminden sonra yeniden gönderilir. Değişmeyen satırlar genellikle yeni satırlarla birlikte yayılır, bu nedenle aşağı akış tüketicilerinin yinelenenleri işleyebilmesi gerekir. Silme işlemleri aşağı akışa yayılmaz.
ignoreChanges ' den önceliklidir ignoreDeletes.
Buna karşılık, skipChangeCommits dosya değiştirme işlemlerini tamamen göz ardı eder. Yeniden yazılan veri dosyaları, UPDATE, MERGE INTO, DELETE ve OVERWRITE gibi veri değiştirme işlemleri nedeniyle kaynak tablodaki tamamen yoksayılır. Akış kaynağı tablolarındaki değişiklikleri yansıtmak için, bu değişiklikleri yaymak için ayrı mantık uygulamanız gerekir.
Databricks, tüm yeni iş yükleri için skipChangeCommits kullanılmasını önerir. Bir iş yükünü ignoreChanges'den skipChangeCommits'ye geçirmek için akış mantığınızı yeniden düzenleyin.
Aşağı akış tablolarının tam yenilemesi
Yukarı akış değişiklikleri nadirse ve veriler yeniden işlenebilir kadar küçükse, akış denetim noktasını ve çıkış tablosunu silebilir ve ardından akışı baştan yeniden başlatabilirsiniz. Bu, akışın kaynak tablodaki tüm verileri yeniden işlemesine neden olur. Bu yaklaşımın, bu akışın çıkışına bağlı olan tüm aşağı akış tablolarının yeniden işlenmesini de gerektirdiğini unutmayın.
Bu yaklaşım, yukarı akış değişikliklerinin seyrek görüldüğü ve tam yenileme maliyetinin kabul edilebilir olduğu daha küçük veri kümeleri veya iş yükleri için uygundur.
Değişiklik veri akışını kullanma
Tüm değişiklik türlerini (eklemeler, güncelleştirmeler ve silmeler) işleyen iş yükleri için Delta Lake değişiklik veri akışını kullanın. Değişiklik veri akışı, satır düzeyindeki değişiklikleri delta tablosuna kaydederek bu değişiklikleri akışa almanızı ve aşağı akış tablolarındaki her değişiklik türünü işlemek için mantık yazmanızı sağlar. Kodunuz her tür değişiklik olayını açıkça işlediğinden bu en güçlü yaklaşımdır. Bkz. Azure Databricks üzerinde Delta Lake değişiklik veri akışını kullanma.
Lakeflow Spark Bildirimli İşlem Hatları kullanıyorsanız bkz. AUTO CDC API'leri: İşlem hatları ile değişiklik verilerini yakalamayı basitleştirme.
Important
Databricks Runtime 12.2 LTS ve altında, sütun eşlemesi etkinleştirilmiş ve eklemeli olmayan şema evrimi geçiren (örneğin, sütunları yeniden adlandırma veya bırakma) bir Delta tablosundan değişiklik veri beslemesi ile akış yapamazsınız. Bkz. Sütun eşleme ve akış.
Somutlaştırılmış görünümleri kullanın
Gerçekleştirilmiş görünümler, kaynak veriler değiştiğinde sonuçları yeniden derleyerek yukarı akış değişikliklerini otomatik olarak işler. Olası en düşük gecikme süresine ihtiyacınız yoksa ve akış karmaşıklığını yönetmekten kaçınmak istiyorsanız, gerçekleştirilmiş bir görünüm mimarinizi basitleştirebilir. Gerçekleştirilmiş görünümler Lakeflow Spark Bildirimli İşlem Hatları işlem hatlarında ve Databricks SQL'de kullanılabilir. Bkz Gerçekleştirilmiş görünümler.
Example
Örneğin, user_events, date, user_email ve action sütunlarına sahip, date tarafından bölümlenmiş bir tablonuz olduğunu varsayalım.
user_events tablosundan veri akışıyla çıktığınızda GDPR nedeniyle bu verileri silmeniz gerekir.
skipChangeCommits birden çok bölümdeki verileri silmenize olanak tanır (bu örnekte, üzerinde user_emailfiltreleme). Aşağıdaki sözdizimini kullanın:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
deyimiyle user_email güncelleştirdiğinizdeUPDATE, söz konusu dosyayı içeren user_email dosya yeniden yazılır.
skipChangeCommits kullanarak değiştirilen veri dosyalarını yoksayın.
Databricks, silmelerin her zaman tam bölüm düşüşü olduğundan emin olmadığınız sürece skipChangeCommits yerine ignoreDeletes kullanılmasını önerir.
İdemponent tablo yazma işlemleri için foreachBatch kullanın
Note
Databricks, foreachBatchkullanmak yerine güncelleştirmek istediğiniz her havuz için ayrı bir akış yazma yapılandırması önerir. Birden fazla foreachBatch havuza yazma işlemi paralelleştirmeyi azaltır ve foreachBatch içinde birden çok tabloya yazma işlemi serileştirildiğinden genel gecikmeyi artırır.
Delta tabloları, DataFrameWriter içindeki birden çok tabloya yazma işlemlerini idempotent yapmak için aşağıdaki foreachBatch seçeneklerini destekler.
-
txnAppId: Her bir DataFrame yazma işleminde kullanabileceğiniz benzersiz bir dize. Örneğin, StreamingQuery Kimliğini olaraktxnAppIdkullanabilirsiniz.txnAppIdkullanıcı tarafından oluşturulan herhangi bir benzersiz dize olabilir ve akış kimliğiyle ilişkili olması gerekmez. -
txnVersion: İşlem sürümü işlevi gören monoton olarak artan bir sayı.
Delta Lake, yinelenen yazmaları tanımlamak ve yoksaymak için txnAppId ve txnVersion kullanır. Örneğin, bir hata toplu yazma işlemini kestikten sonra, toplu işlemi aynı txnAppId ve txnVersion ile yeniden çalıştırarak yinelenenleri doğru şekilde tanımlayıp yoksayabilirsiniz. Bkz. Rastgele veri havuzlarına yazmak için foreachBatch kullanma.
Warning
Akış kontrol noktasını siler ve sorguyu yeni bir kontrol noktasıyla yeniden başlatırsanız, farklı bir txnAppId sağlamanız gerekir. Yeni denetim noktaları toplu iş kimliğiyle 0başlar. Delta Lake, toplu iş kimliğini ve txnAppId benzersiz bir anahtar olarak kullanır ve önceden görülen değerleri içeren toplu işlemleri atlar.
Aşağıdaki kod örneği bu düzeni gösterir:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Akış sorgularını kullanarak güncelle veya ekle (upsert) foreachBatch
Akış sorgusundan Delta tablosuna karmaşık upsert'ler yazmak için merge ve foreachBatch kullanabilirsiniz. Bkz. Rastgele veri havuzlarına yazmak için foreachBatch kullanma.
Bu yaklaşımın birçok uygulaması vardır:
- Çıkış moduyla
updateyazma performansını geliştirin, ancakcompleteçıkış modu her mikrobatch için sonuç tablosunun tamamını yeniden yazmayı gerektirir. - Birleştirme sorgusu kullanarak bir delta tablosuna değişiklik verilerini
foreachBatch'ye yazmak suretiyle sürekli bir değişiklik akışı uygulamakta olun. Bkz. Delta Lake ile yavaş değişen veri (SCD) ve değişiklik verisi yakalama (CDC). - Akış işleme sırasında verileri yinelenmekten arındırma. Delta tablosuna otomatik şekilde yinelenenleri kaldırarak sürekli veri yazmak için
foreachBatch'da yalnızca ekleme birleştirme sorgusu kullanabilirsiniz. Bkz. Delta tablolarına yazarken yinelenen verileri kaldırma.
Note
mergedeyiminizinforeachBatchiçinde idempotent olduğunu doğrulayın. Aksi takdirde, akış sorgusu yeniden başlatıldığında, işlem aynı veri toplu işlemine defalarca uygulanabilir. Bkz. Idempotent tablo yazma işlemlerindeforeachBatchkullanın.mergeiçindeforeachBatchkullanıldığında, giriş veri hızı ölçümü verilerin kaynakta oluşturulduğu gerçek oranın bir katını döndürebilir.mergegiriş verilerini birden çok kez okur ve bu da ölçümleri çarpar. Metrik çarpmasını önlemek için, batch DataFrame'imergeöncesinde önbelleğe alın vemergesonrasında önbellekten çıkarın.Giriş veri hızı,
StreamingQueryProgressaracılığıyla ve defter akış hızı grafiğinde kullanılabilir. Bkz. Azure Databricks üzerinde Yapılandırılmış Akış sorgularını izleme.
Örneğin, içinde MERGESQL deyimlerini kullanabilirsinizforeachBatch:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Streaming upsert'ler için Delta Lake API'lerini de kullanabilirsiniz.
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Değişiklikleri işlemek için ilk tablo sürümünü ayarlama
Varsayılan olarak, akışlar kullanılabilir en son Delta tablosu sürümüyle başlar. Bu, tablonun o anda tam bir anlık görüntüsünü ve gelecekteki tüm değişiklikleri içerir. Databricks, çoğu iş yükü için varsayılan ilk tablo sürümünü kullanmanızı önerir.
İsteğe bağlı olarak, delta Lake akış kaynağının başlangıç noktasını tablonun tamamını işlemeden belirtmek için aşağıdaki seçenekleri kullanabilirsiniz.
startingVersion: Okumaya başlamak için Delta tablosu sürümü. Belirtilen sürümde veya sonrasında uygulanan tüm tablo değişiklikleri akış tarafından okunur. Belirtilen sürüm kullanılamıyorsa akış başlatılamaz.Kullanılabilir işleme sürümlerini bulmak için komutunu çalıştırın
DESCRIBE HISTORYve denetleyinversion. Yalnızca en son değişiklikleri döndürmek için belirtinlatest. Delta tablo sürümleri hakkında bilgi için bkz. Tablo geçmişiyle çalışma.startingTimestamp: Okumaya başlamak için zaman damgası. Belirtilen zaman damgasında veya sonrasında kaydedilen tüm tablo değişiklikleri veri akışı tarafından okunur. Sağlanan zaman damgası tüm tablo işlemelerinden önce gelirse, akış okuması en erken kullanılabilir zaman damgasıyla başlar. İki durumdan birini ayarlayın:- Zaman damgası dizesi. Örneğin,
"2019-01-01T00:00:00.000Z". - Tarih dizgisi. Örneğin,
"2019-01-01".
- Zaman damgası dizesi. Örneğin,
Hem startingVersion hem de startingTimestamp aynı anda ayarlanamaz. Bu ayarlar yalnızca yeni akış sorgularına uygulanır. Akış sorgusu başlatıldıysa ve ilerleme durumu denetim noktasına kaydedildiyse, bu ayarlar yoksayılır.
Important
Akış kaynağını belirtilen bir sürümden veya zaman damgasından başlatabilirsiniz, ancak akış kaynağının şeması her zaman Delta tablosunun en son şemasıdır. Belirtilen sürümden veya zaman damgasından sonra Delta tablosunda uyumsuz şema değişikliği olmadığından emin olmanız gerekir. Aksi takdirde, akış kaynağı verileri yanlış bir şemayla okurken yanlış sonuçlar döndürebilir.
Example
Örneğin, bir tablonuz user_eventsolduğunu varsayalım. Sürüm 5'ten bu yana yapılan değişiklikleri okumak istiyorsanız şunu kullanın:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
2018-10-18'den bu yana yapılan değişiklikleri okumak istiyorsanız şunu kullanın:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Verileri bırakmadan ilk anlık görüntüyü işleme
Bu özellik Databricks Runtime 11.3 LTS ve üzerinde kullanılabilir.
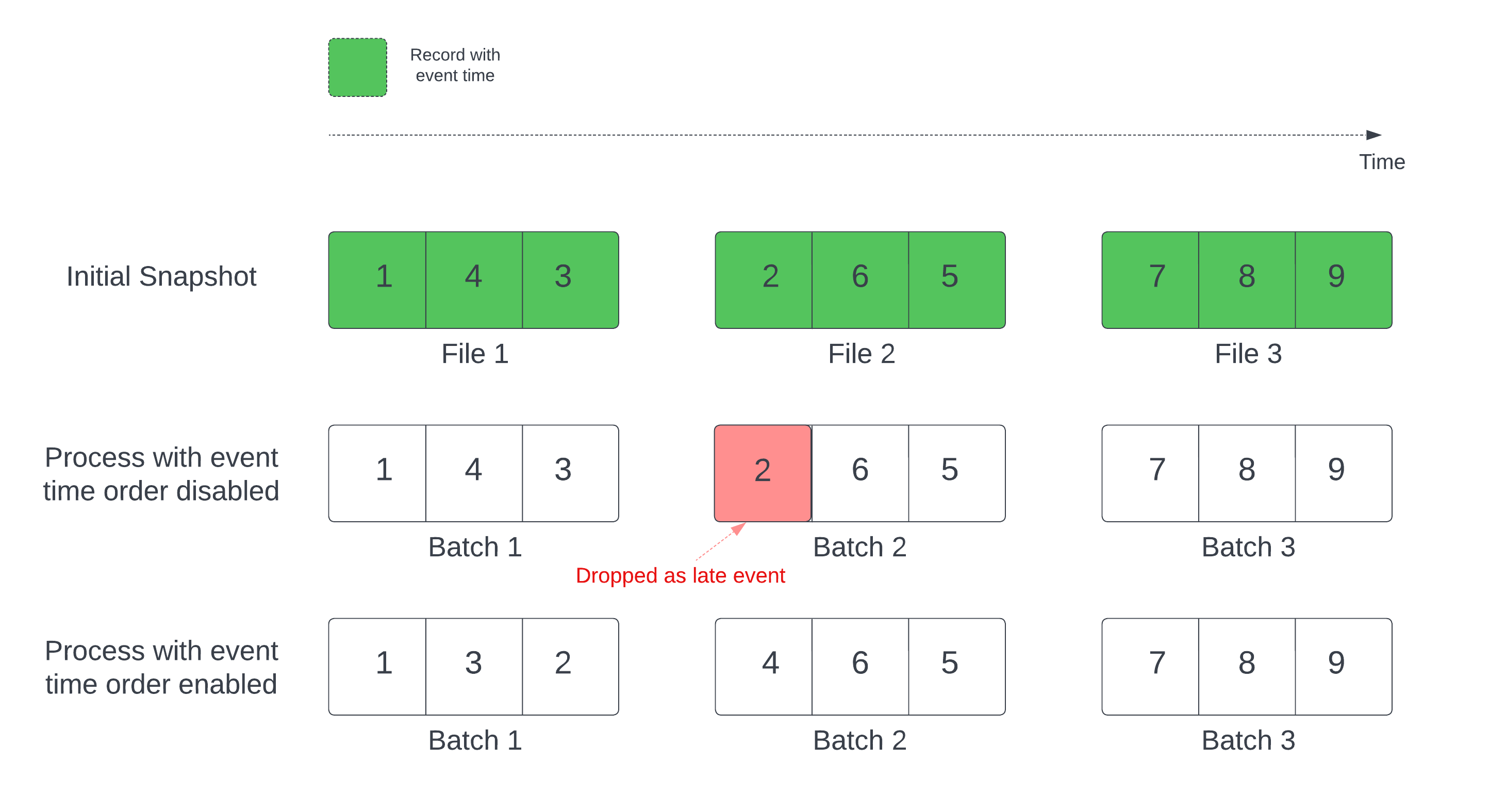
Tanımlı filigranı olan durum bilgisi olan bir akış sorgusunda, dosyaları değiştirme zamanına göre işlemek, kayıtların yanlış sırada işlenmesine yol açabilir. Bu, filigranın kayıtları hatalı bir şekilde geç olaylar olarak işaretlemesine ve bırakmasına neden olabilir. Bu durum yalnızca ilk Delta anlık görüntüsü varsayılan sırada işlendiğinde oluşabilir.
Delta kaynak tablosuna sahip akışlar için sorgu önce tabloda bulunan tüm verileri işler ve ilk anlık görüntü adlı bir sürüm oluşturur. Varsayılan olarak, Delta tablosunun veri dosyaları en son hangi dosyanın değiştirildiğine göre işlenir. Ancak, son değişiklik saati mutlaka kayıt olayı saat sırasını temsil etmez.
İlk anlık görüntü işleme sırasında veri düşüşlerini önlemek için seçeneğini etkinleştirin withEventTimeOrder .
withEventTimeOrder ilk anlık görüntü verilerinin olay zaman aralığını zaman demetlerine böler. Her mikro parti, belirli bir zaman aralığındaki verileri filtreleyerek bir kovayı işler.
maxFilesPerTrigger ve maxBytesPerTrigger seçenekleri, mikro toplu iş boyutunu denetlemek için hala geçerlidir, ancak yalnızca işleme yaklaşımından dolayı yaklaşık olarak geçerlidir.
Aşağıdaki diyagramda bu işlem gösterilmektedir:
Sınırlamalar
- Akış sorgusu başlatıldıysa ve ilk anlık görüntü etkin olarak işleniyorsa
withEventTimeOrder'yi değiştiremezsiniz. Değiştirilmiş olarakwithEventTimeOrderyeniden başlatmak için denetim noktasını silmeniz gerekir. - Etkinleştirilirse
withEventTimeOrder, ilk anlık görüntü işleme tamamlanana kadar akışı bu özelliği desteklemeyen bir Databricks Runtime sürümüne düşüremezsiniz. Eski sürüme düşürmek için ilk anlık görüntünün tamamlanmasını bekleyin veya kontrol noktasını silip sorguyu yeniden başlatın. - Bu özellik aşağıdaki senaryolarda desteklenmez:
- Olay zamanı sütunu, oluşturulmuş bir sütundur ve Delta kaynağı ile filigran arasında projeksiyon kapsamı dışı dönüşümler bulunmaktadır.
- Akış sorgusunda birden fazla Delta kaynağı içeren bir filigran bulunmaktadır.
Performans
Etkinleştirilirse withEventTimeOrder , ilk anlık görüntü işleme performansı daha yavaş olabilir. Her mikro toplu işlem, ilgili olay zaman aralığındaki verileri filtrelemek için ilk anlık görüntüyü tarar. Filtreleme performansını geliştirmek için:
- Veri atlamanın uygulanabilmesi için olay zamanı olarak Delta kaynak sütununu kullanın. Bkz. Veri atlama.
- Tabloyu olay zamanı sütunu boyunca bölümleme.
Belirli bir mikro toplu iş için kaç Delta dosyasının taranmış olduğunu görmek için Spark kullanıcı arabirimini kullanın.
Example
Varsayalım ki user_events adında bir tablonuz var ve bu tabloda event_time sütunu bulunuyor. Akış sorgunuz bir toplama sorgusudur. Veri kaybı olmadan ilk anlık görüntü işleme işlemini sağlamak istiyorsanız, şunları kullanabilirsiniz:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Bunu tüm akış sorgularına uygulamak için kümede spark yapılandırmasıyla ayarlayabilirsiniz withEventTimeOrder : spark.databricks.delta.withEventTimeOrder.enabled true.
İşleme performansını geliştirmek için giriş hızını sınırlayın
Yapılandırılmış Akış varsayılan olarak her mikro toplu işlemde mümkün olduğunca çok dosya işler. Toplu iş başına işlenen veri miktarını sınırlamak ve bellek kullanımını yönetmek, gecikme süresini dengelemek veya bulut depolama maliyetlerini azaltmak için aşağıdaki seçenekleri kullanın:
-
maxFilesPerTrigger: Her mikro toplu işlemde dikkate alınması gereken yeni dosyaların sayısı. Varsayılan değer 1000’dir. -
maxBytesPerTrigger: Her mikro toplu işlemde işlenen veri miktarı. Bu seçenek bir "soft max" ayarlar; başka bir deyişle bir toplu işlem yaklaşık olarak bu miktarda veriyi işler ve en küçük giriş biriminin bu sınırdan büyük olduğu durumlarda akış sorgusunun ileriye doğru ilerlemesini sağlamak için sınırdan daha fazlasını işleyebilecektir. Bu varsayılan olarak ayarlanmaz.
Hem maxBytesPerTrigger hem de maxFilesPerTrigger kullanırsanız, mikro-batch işlemi, maxFilesPerTrigger veya maxBytesPerTrigger sınırına ulaşılana kadar verileri işler.
Note
Varsayılan olarak, kaynak tablodaki işlemleri temizlerse logRetentionDuration ve akış sorgusu bu sürümleri işlemeye çalışırsa, sorgu veri kaybını önleyemiyor demektir. Veri kaybını yoksaymak ve işlemeye devam etmek için failOnDataLoss seçeneğini false olarak ayarlayabilirsiniz. Bkz Zaman yolculuğu sorguları için veri saklamayı yapılandırma.
Bulut depolama maliyetini denetleme
Akış sorguları, , processingTimeve availableNowgibi realTimemaliyet ve gecikme süresini dengelemenize olanak sağlayan çeşitli tetikleyici modlarına sahiptir. Bkz. Bulut depolama maliyetini denetleme.