Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede eski Azure Databricks görselleştirmeleri açıklanmaktadır. SQL düzenleyicisinde veya not defterinde görselleştirme oluştururken geçerli görselleştirme desteği için bkz. Databricks not defterlerindeki görselleştirmeler ve SQL düzenleyicisi. AI/BI panolarındaki görselleştirmelerle çalışma hakkında bilgi için bkz. AI/BI pano görselleştirme türleri.
Azure Databricks ayrıca Python ve R'deki görselleştirme kitaplıklarını yerel olarak destekler ve üçüncü taraf kitaplıklarını yükleyip kullanmanıza olanak tanır.
Eski görselleştirme oluşturma
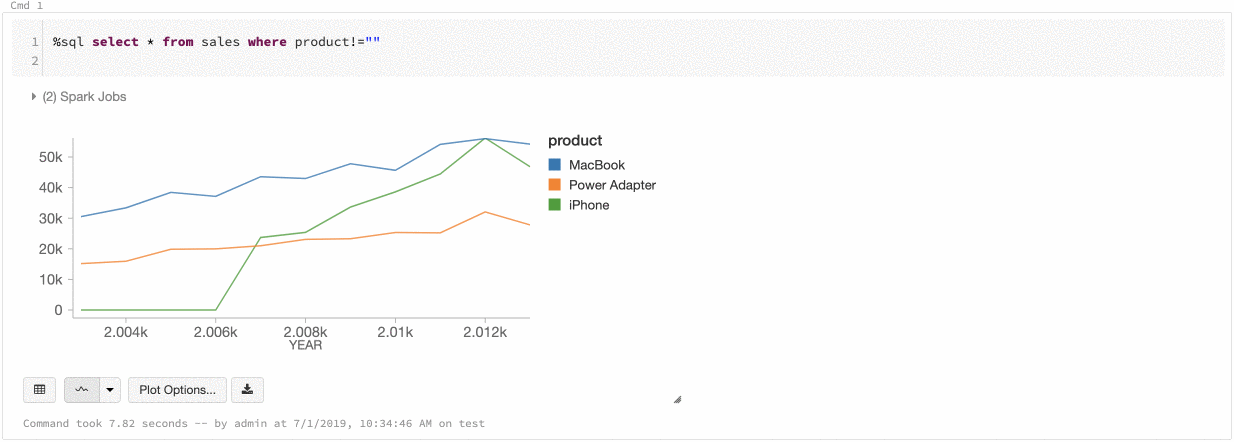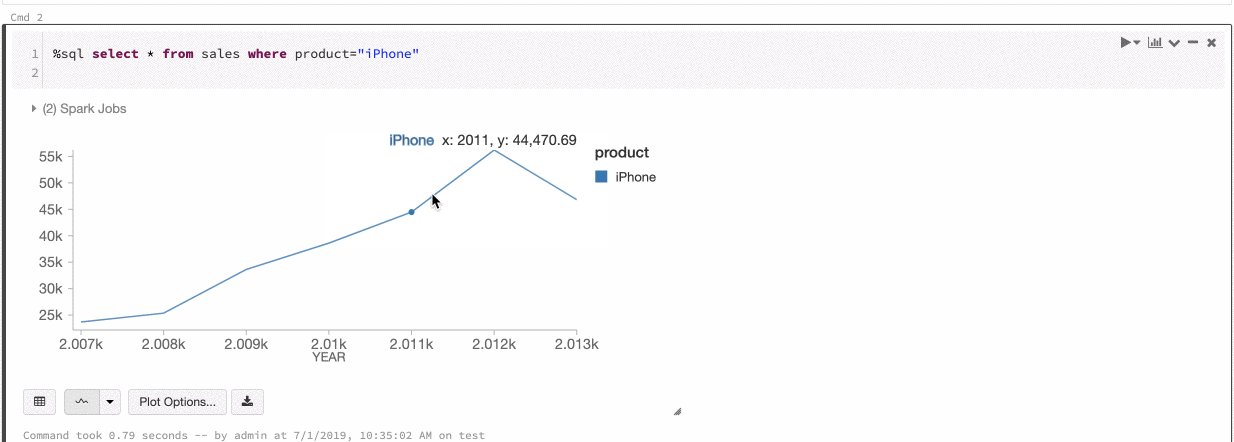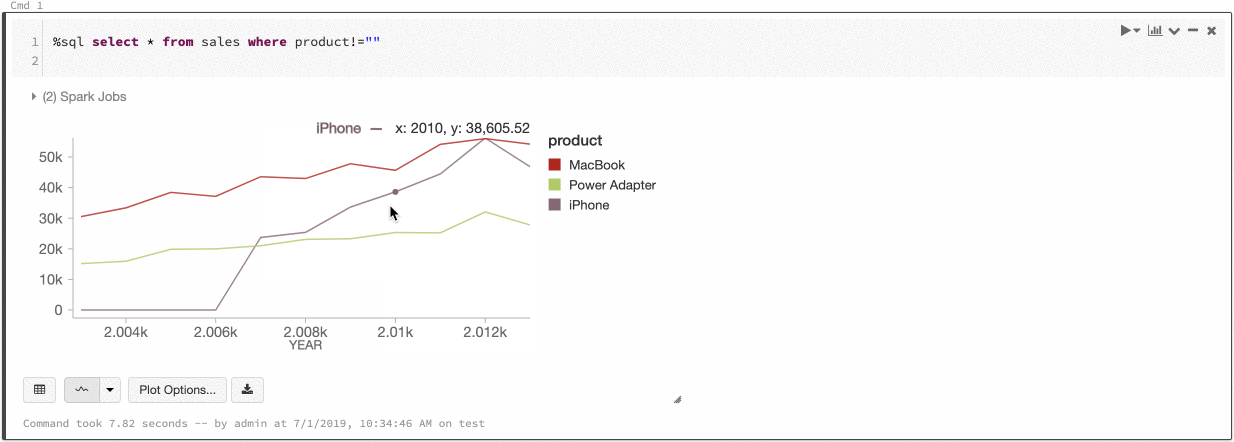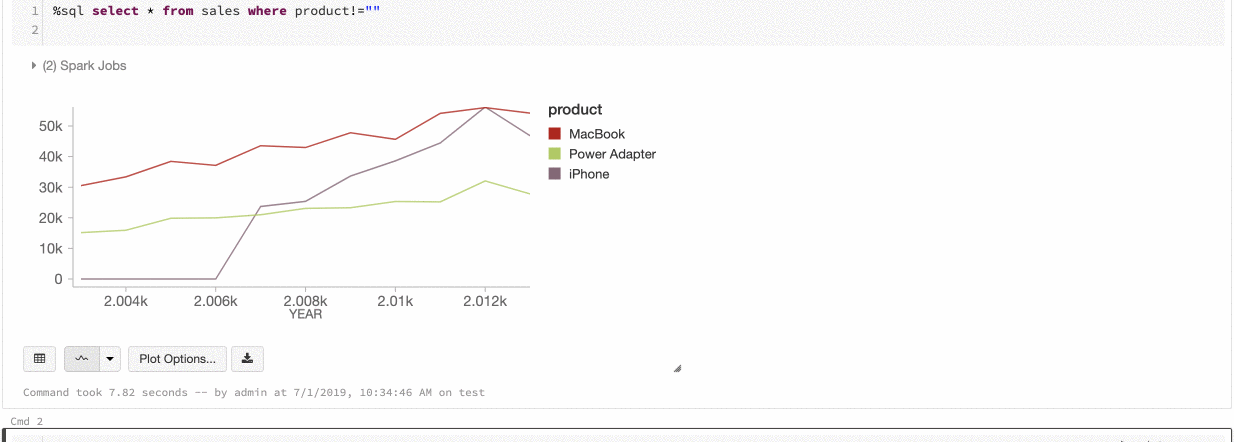
Sonuç hücresinden eski bir görselleştirme oluşturmak için +'a tıklayın ve Legacy Visualizationseçin.
Eski görselleştirmeler zengin çizim türleri kümesini destekler:
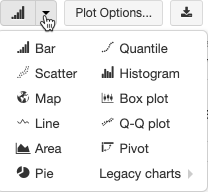
Eski grafik türünü seçme ve yapılandırma
Çubuk grafik seçmek için çubuk grafik simgesine  tıklayın:
tıklayın:
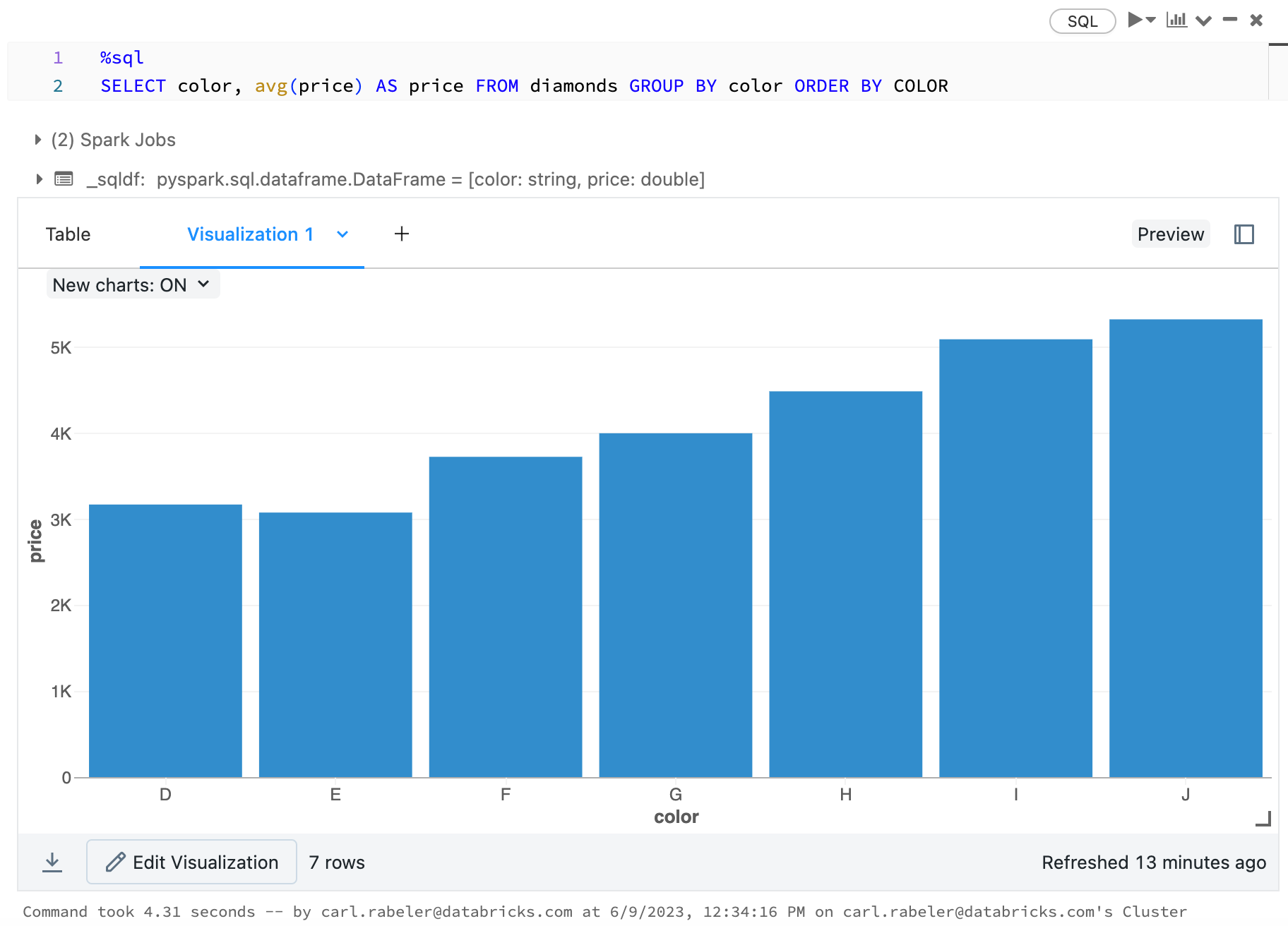
Başka bir çizim türü seçmek için çubuk grafiğin ![]() sağındaki öğesine tıklayın ve çizim türünü seçin.
sağındaki öğesine tıklayın ve çizim türünü seçin.
Eski grafik araç çubuğu
Hem çizgi hem de çubuk grafikler, zengin bir istemci tarafı etkileşim kümesini destekleyen yerleşik bir araç çubuğuna sahiptir.
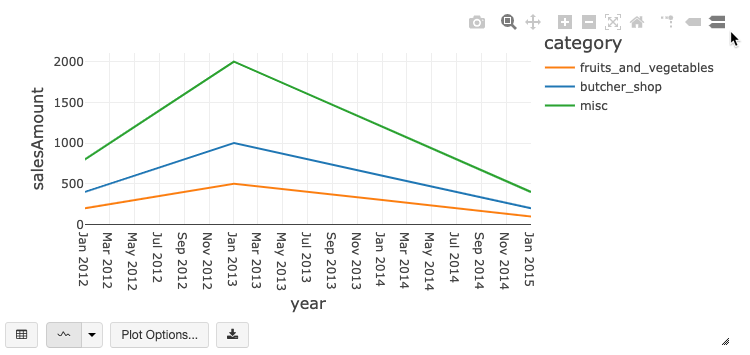
Bir grafiği yapılandırmak için Çizim Seçenekleri...'ne tıklayın.
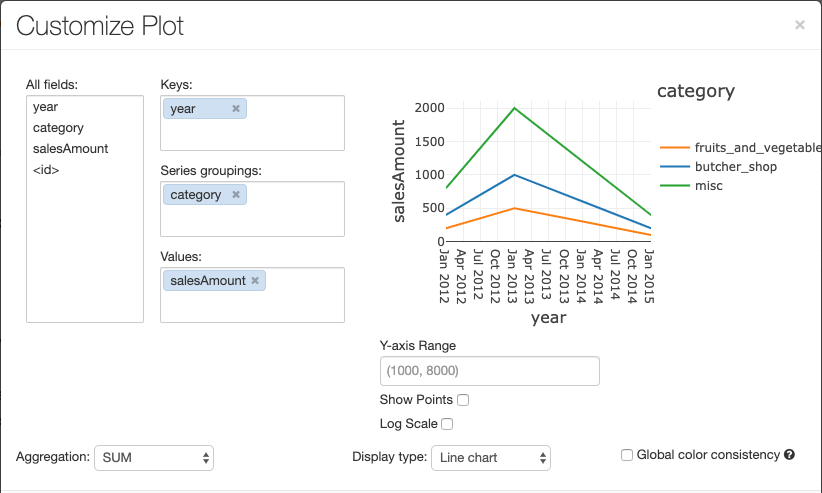
Çizgi grafiğin birkaç özel grafik seçeneği vardır: Y ekseni aralığını ayarlama, noktaları gösterme ve gizleme, Y eksenini logaritmik bir ölçekle görüntüleme.
Eski grafik türleri hakkında bilgi için bkz.
Grafikler arasında renk tutarlılığı
Azure Databricks, eski grafikler arasında iki tür renk tutarlılığını destekler: seri kümesi ve genel.
Serisi kümesi renk tutarlılığı, aynı değerlere sahip ancak farklı sıralamalarda olan serileriniz varsa, aynı değere aynı rengi atar (örneğin, A = ["Apple", "Orange", "Banana"] ve B = ["Orange", "Banana", "Apple"]). Değerler çizimden önce sıralandığından, her iki gösterge de aynı şekilde (["Apple", "Banana", "Orange"]) sıralanır ve aynı değerlere aynı renkler verilir. Ancak, C = ["Orange", "Banana"]serisine sahipseniz, küme aynı olmadığından A kümesiyle renk tutarlılığı olmaz. Sıralama algoritması C kümesindeki ilk rengi "Muz" olarak, ikinci rengi ise A kümesindeki "Muz" olarak atar. Bu serilerin renk tutarlılığı olmasını istiyorsanız grafiklerin genel renk tutarlılığı olması gerektiğini belirtebilirsiniz.
genel renk tutarlılığında, serinin hangi değerleri olursa olsun her değer her zaman aynı renge eşlenir. Bunu her grafikte etkinleştirmek için Genel renk tutarlılığı onay kutusunu seçin.
Not
Bu tutarlılığı elde etmek için Azure Databricks, değerlerden renklere doğrudan hash oluşturur. Çakışmaları önlemek için (iki değerin aynı renge denk geldiği durumlarda) karma, çok fazla renkten oluşan büyük bir kümeye yapılır, bu da güzel görünen veya kolayca ayırt edilebilen renklerin garanti edilememesi gibi bir yan etkiye sahiptir; birçok renk arasında çok benzer görünen bazı renklerin olması kaçınılmazdır.
Makine öğrenmesi görselleştirmeleri
Eski görselleştirmeler, standart grafik türlerine ek olarak aşağıdaki makine öğrenmesi eğitim parametrelerini ve sonuçlarını destekler:
Fazlalıklar
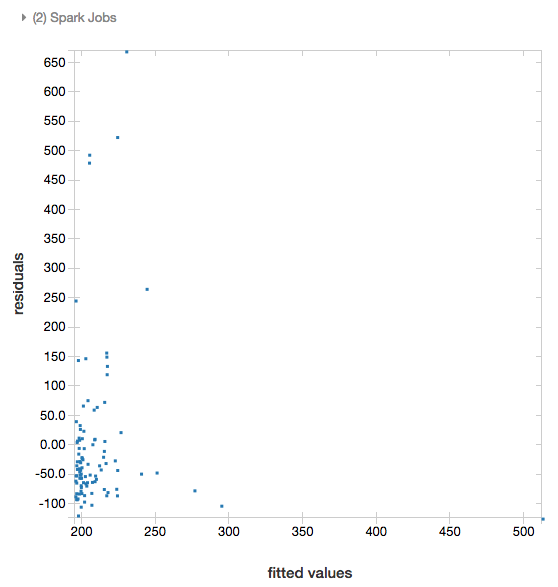
Doğrusal ve lojistik regresyonlar için bir uygun değerler ve artıkları grafiği oluşturabilirsiniz. Bu çizimi elde etmek için modeli ve DataFrame'i sağlayın.
Aşağıdaki örnek, şehir nüfusundan ev satış fiyatı verilerine doğrusal bir regresyon oluşturur ve sonra fazlalıklara karşılık uydurulan verileri görüntüler.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
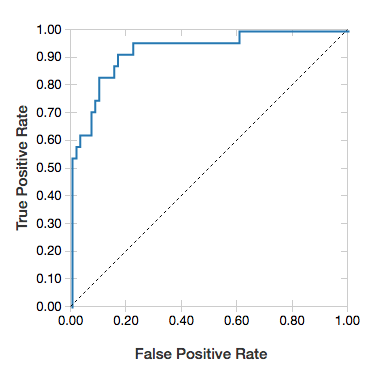
ROC eğrileri
Lojistik regresyonlar için bir ROC eğrisi işleyebilirsiniz. Bu çizimi elde etmek için modeli, yöntemine fit giriş olan önceden oluşturulmuş verileri ve parametresini "ROC"sağlayın.
Aşağıdaki örnek, bir bireyin çeşitli özniteliklerinden yılda =50K veya <50 bin kazanıp kazanmadığını >tahmin eden bir sınıflandırıcı geliştirir. Yetişkin veri kümesi nüfus sayım verilerinden alınır ve 48.842 birey ile yıllık gelirleri hakkında bilgi içerir.
Bu bölümdeki örnek kodda one-hot kodlama kullanılır.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
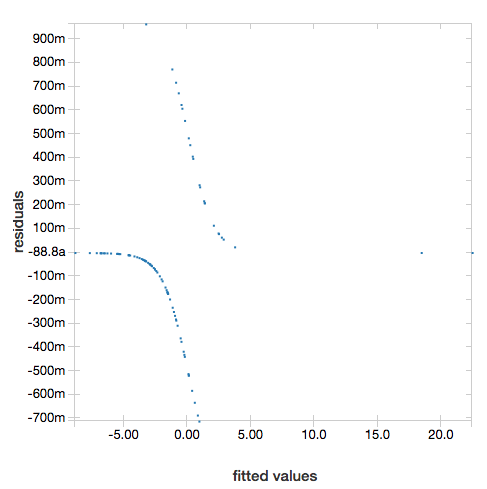
Fazlalıkları görüntülemek için "ROC" parametresini çıkarın:
display(lrModel, preppedDataDF)
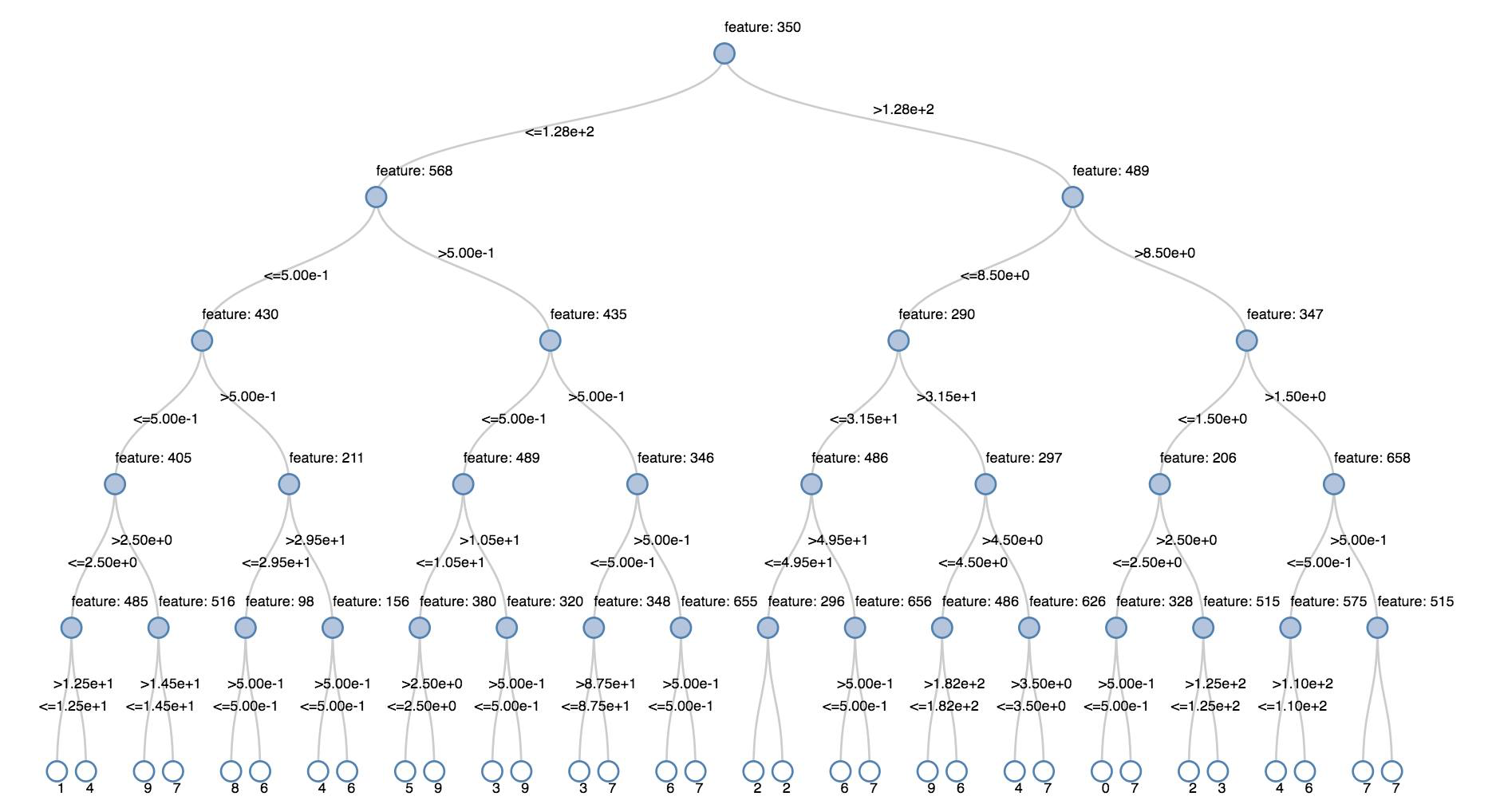
Karar ağaçları
Eski görselleştirmeler, bir karar ağacının oluşturulmasını destekler.
Bu görselleştirmeyi edinmek için karar ağacı modelini sağlayın.
Aşağıdaki örnekler, el ile yazılan rakamların görüntülerinden oluşan MNIST veri kümesinden rakamları (0 - 9) tanıyan bir ağacı eğitir ve sonra ağacı görüntüler.
Piton
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala programlama dili
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
Yapılandırılmış Akış Veri Çerçeveleri
Bir akış sorgusunun sonucunu gerçek zamanlı olarak görselleştirmek için, Scala ve Python'da bir Yapılandırılmış Akış Veri Çerçevesini display ile görüntüleyebilirsiniz.
Piton
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala programlama dili
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display aşağıdaki isteğe bağlı parametreleri destekler:
-
streamName: akış sorgusu adı. -
trigger(Scala) veprocessingTime(Python): Akış sorgusunun ne sıklıkla çalıştırılacağını tanımlar. Belirtilmezse, sistem önceki işlem tamamlandıktan hemen sonra yeni verilerin kullanılabilirliğini denetler. Databricks, üretim maliyetini azaltmak için her zaman bir tetikleyici aralığı ayarlamanız gerektiğini önerir. Varsayılan tetikleyici aralığı 500 ms'dir. -
checkpointLocation: Sistemin tüm denetim noktası bilgilerini yazdığı konum. Belirtilmezse, sistem otomatik olarak DBFS üzerinde geçici bir denetim noktası konumu oluşturur. Akışınızın verileri kaldığınız yerden işlemeye devam edebilmesi için bir denetim noktası konumu sağlamanız gerekir. Databricks üretim ortamında her zamancheckpointLocationseçeneğini belirtmenizi önerir.
Piton
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala programlama dili
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Bu parametreler hakkında daha fazla bilgi için bkz. Akış Sorgularını Başlatma.
displayHTML işlevi
Azure Databricks programlama dili not defterleri (Python, R ve Scala), displayHTML işlevini kullanan HTML grafiklerini destekler; işleve herhangi bir HTML, CSS veya JavaScript kodunu geçirebilirsiniz. Bu işlev, D3 gibi JavaScript kitaplıklarını kullanan etkileşimli grafikleri destekler.
displayHTML kullanımına örnekler için bkz.
Not
displayHTML iframe, databricksusercontent.com etki alanından sunulur ve iframe korumalı alanı allow-same-origin özniteliğini içerir.
databricksusercontent.com tarayıcınızdan erişilebilir olmalıdır. Şu anda şirket ağınız tarafından engelleniyorsa, izin verme listesine eklenmesi gerekir.
Görüntü
Görüntü veri türlerini içeren sütunlar zengin HTML olarak işlenir. Azure Databricks, Spark DataFrameile eşleşen sütunlar için küçük görüntüleri oluşturmaya çalışır.
Küçük resim oluşturma, spark.read.format('image') işlevi aracılığıyla başarıyla okunan tüm görüntüler için çalışır. Azure Databricks, diğer yollarla oluşturulan görüntü değerleri için 1, 3 veya 4 kanal görüntüsünün işlenmesini (her kanalın tek bir baytten oluştuğu) aşağıdaki kısıtlamalarla destekler:
-
Tek kanallı görüntüler:
modealanı 0'a eşit olmalıdır.height,widthvenChannelsalanlarıdataalanındaki ikili görüntü verilerini doğru olarak betimlemelidir. -
Üç kanallı görüntüler:
modealanı 16'ya eşit olmalıdır.height,widthvenChannelsalanlarıdataalanındaki ikili görüntü verilerini doğru olarak betimlemelidir.dataalanı, kanal sıralaması her piksel için(blue, green, red)olacak şekilde üç baytlık öbekler halinde piksel verileri içermelidir. -
Dört kanallı görüntüler:
modealanı 24'e eşit olmalıdır.height,widthvenChannelsalanlarıdataalanındaki ikili görüntü verilerini doğru olarak betimlemelidir.dataalanı, kanal sıralaması her piksel için(blue, green, red, alpha)olacak şekilde dört baytlık öbekler halinde piksel verileri içermelidir.
Örnek
Bazı görüntüler içeren bir klasörünüz olduğunu varsayalım:

Görüntüleri bir DataFrame'de okur ve ardından DataFrame'i görüntülerseniz Azure Databricks görüntülerin küçük resimlerini işler:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Python'da görselleştirmeler
Bu bölümde:
Seaborn
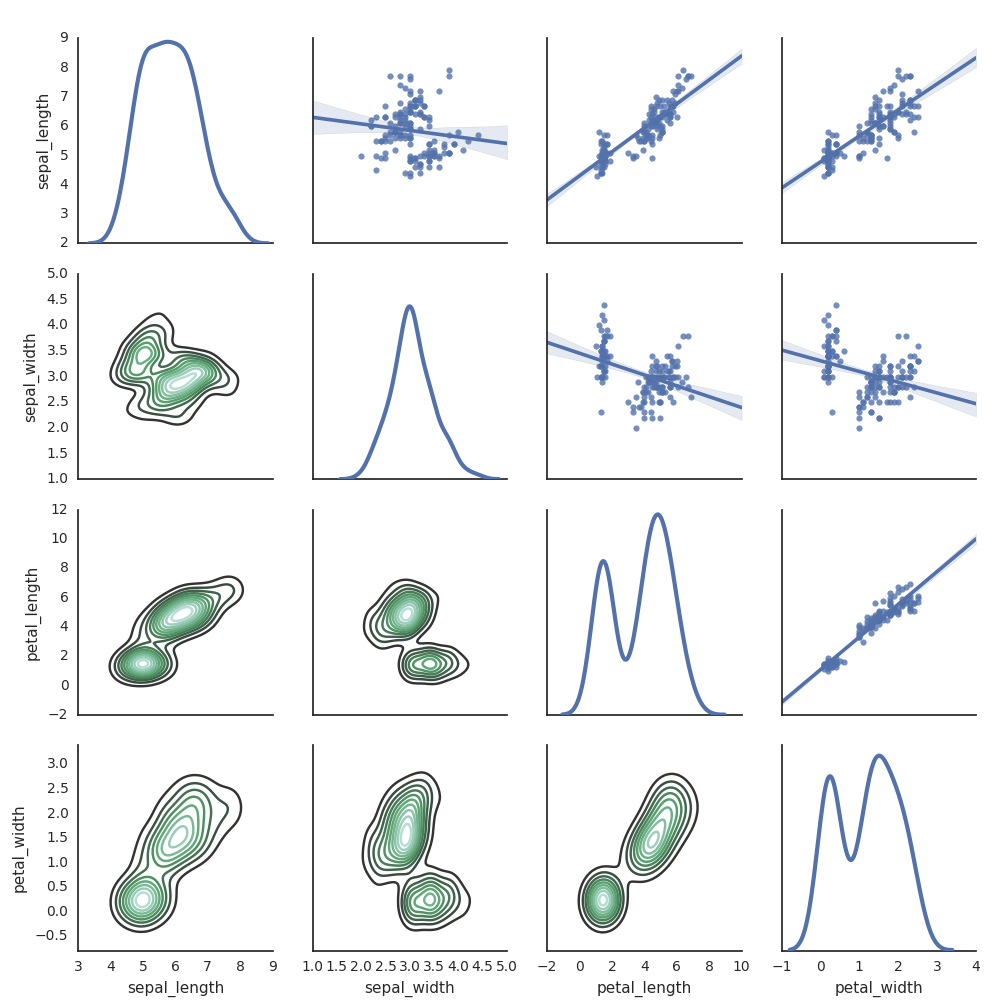
Çizimler oluşturmak için diğer Python kitaplıklarını da kullanabilirsiniz. Databricks Runtime, seaborn görselleştirme kitaplığını içerir. Bir seaborn grafik oluşturmak için kitaplığı içeri aktarın, grafik oluşturun ve grafiği display işlevine gönderin.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Diğer Python kitaplıkları
R'de görselleştirmeler
R'de veri grafiği çizmek için display işlevini aşağıdaki gibi kullanın:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Varsayılan R plot işlevini kullanabilirsiniz.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
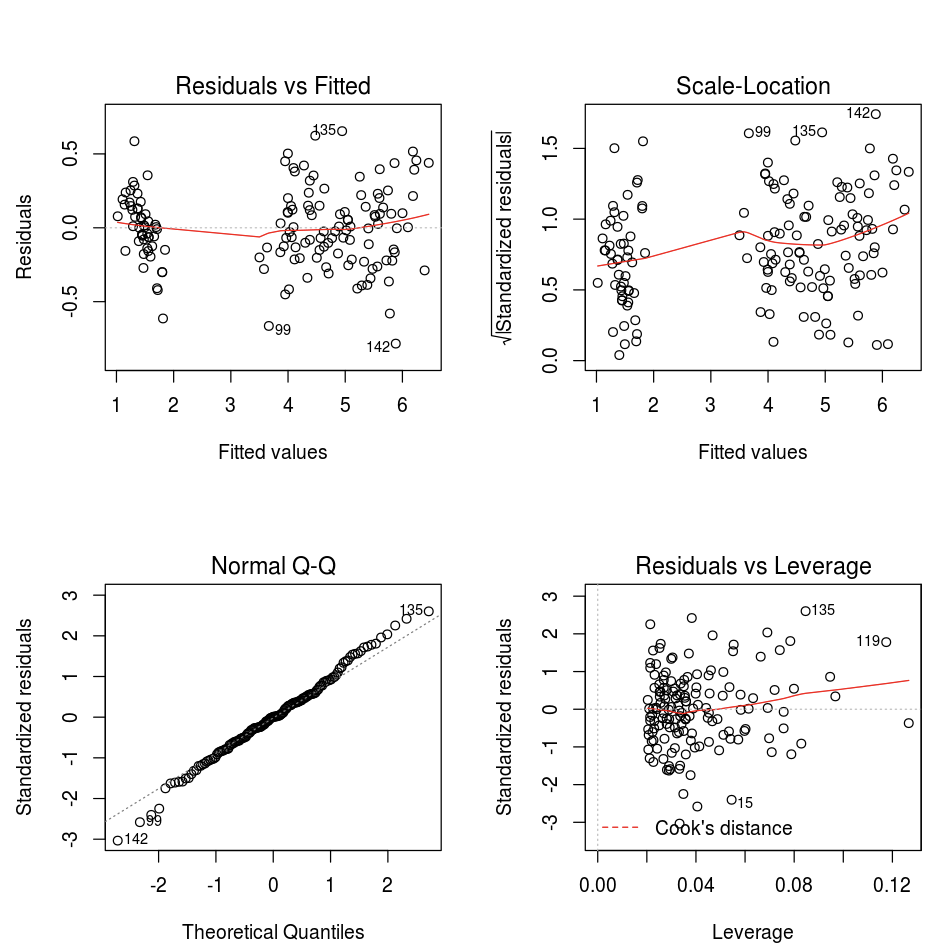
Herhangi bir R görselleştirme paketini de kullanabilirsiniz. R not defteri, ortaya çıkan çizimi bir .png olarak yakalar ve satır içi görüntüler.
Bu bölümde:
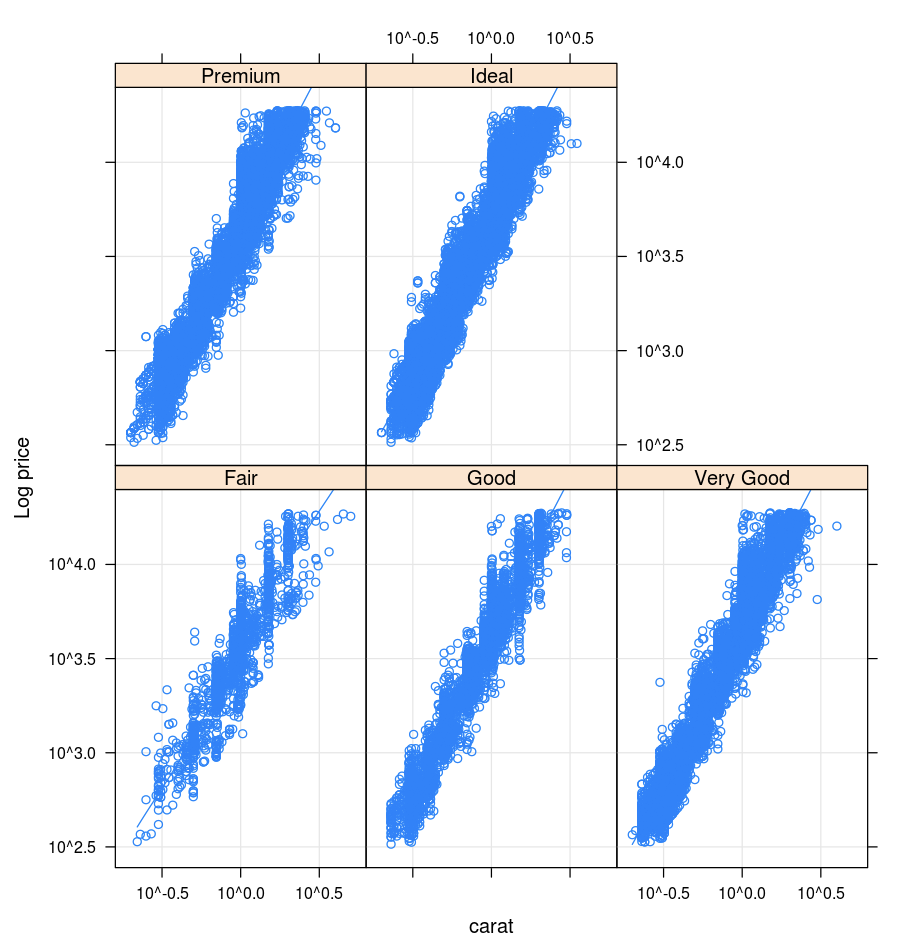
Örgü
Lattice paketi bir veya daha fazla değişken koşullu bir değikeni veya değişkenler arasındaki ilişkiyi görüntüleyen trellis grafiklerini destekler.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
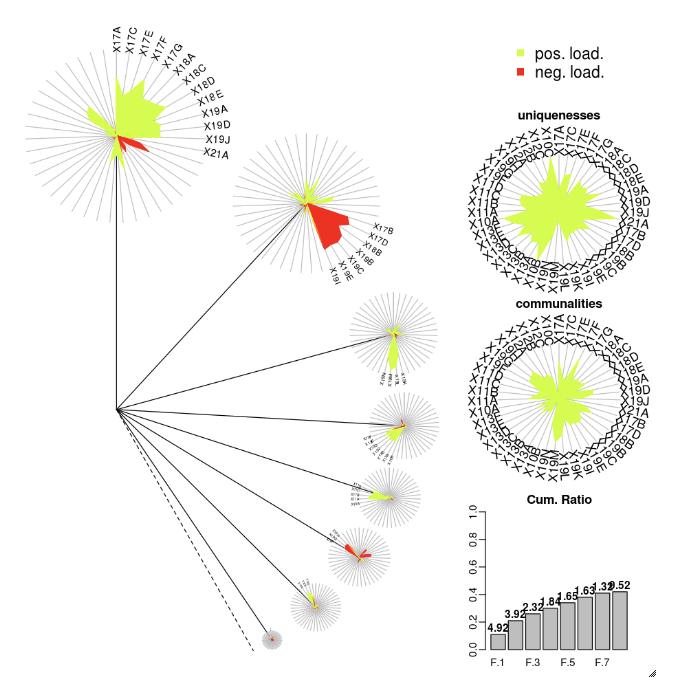
DandEFA
DandEFA paketi dandelion çizimlerini destekler.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Çizim
Plotly R paketi, R için htmlwidgets'e dayanır. Yükleme yönergeleri ve not defteri için bkz. htmlwidgets.
Diğer R kitaplıkları
Scala'da görselleştirmeler
Scala'da veri grafiği çizmek için display işlevini aşağıdaki gibi kullanın:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Python ve Scala için ayrıntılı not defterleri
Python görselleştirmelerine ayrıntılı bir bakış için not defterine bakın:
Scala görselleştirmelerine ayrıntılı bir bakış için not defterine bakın: