Apache Hive'ı Ayıklama, Dönüştürme ve Yükleme (ETL) aracı olarak kullanma
Genellikle gelen verileri analize uygun bir hedefe yüklemeden önce temizlemeniz ve dönüştürmeniz gerekir. Verileri hazırlamak ve bir veri hedefine yüklemek için Ayıklama, Dönüştürme ve Yükleme (ETL) işlemleri kullanılır. HDInsight üzerinde Apache Hive yapılandırılmamış verileri okuyabilir, verileri gerektiği gibi işleyebilir ve ardından karar destek sistemleri için ilişkisel bir veri ambarı'na yükleyebilir. Bu yaklaşımda veriler kaynaktan ayıklanır. Ardından Azure Depolama blobları veya Azure Data Lake Depolama gibi uyarlanabilir depolama alanında depolanır. Daha sonra veriler hive sorguları dizisi kullanılarak dönüştürülür. Ardından hive içinde hedef veri deposuna toplu yükleme hazırlığında hazırlandı.
Kullanım örneğine ve modele genel bakış
Aşağıdaki şekilde, ETL otomasyonu için kullanım örneğine ve modeline genel bir bakış gösterilmektedir. Giriş verileri uygun çıkışı oluşturmak için dönüştürülür. Bu dönüştürme sırasında veriler şekil, veri türü ve hatta dil değiştirir. ETL işlemleri Imperial'ı ölçüme dönüştürebilir, saat dilimlerini değiştirebilir ve hedefteki mevcut verilerle düzgün bir şekilde uyumlu hale getirmek için duyarlığı iyileştirebilir. ETL işlemleri, raporlamayı güncel tutmak veya mevcut veriler hakkında daha fazla içgörü sağlamak için yeni verileri mevcut verilerle birleştirebilir. Raporlama araçları ve hizmetler gibi uygulamalar bu verileri istenen biçimde kullanabilir.
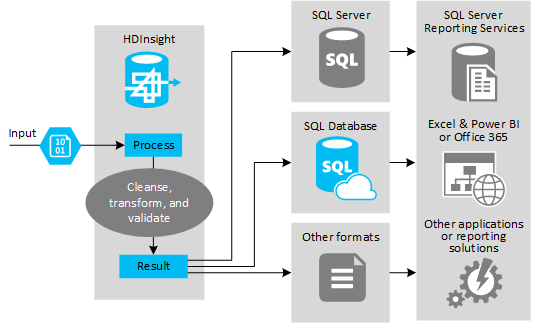
Hadoop genellikle çok sayıda metin dosyasını (CSV gibi) içeri aktaran ETL işlemlerinde kullanılır. Ya da daha küçük ama sık değişen metin dosyası sayısı ya da her ikisi. Hive, verileri veri hedefine yüklemeden önce hazırlamak için harika bir araçtır. Hive, CSV üzerinden bir şema oluşturmanıza ve verilerle etkileşim kuran MapReduce programları oluşturmak için SQL benzeri bir dil kullanmanıza olanak tanır.
ETL yapmak için Hive kullanmanın tipik adımları şunlardır:
Azure Data Lake Depolama veya Azure Blob Depolama'e veri yükleyin.
Şemalarınızı depolamak için Hive tarafından kullanılmak üzere bir Meta Veri Deposu veritabanı (Azure SQL Veritabanı kullanarak) oluşturun.
HDInsight kümesi oluşturun ve veri depoyu bağlayın.
Veri deposundaki veriler üzerinde okuma zamanında uygulanacak şemayı tanımlayın:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Verileri dönüştürün ve hedefe yükleyin. Dönüştürme ve yükleme sırasında Hive'ı kullanmanın birkaç yolu vardır:
- Hive kullanarak verileri sorgulayın ve hazırlayın ve Azure Data Lake Depolama veya Azure blob depolama alanında CSV olarak kaydedin. Ardından BU CSV'leri almak ve verileri SQL Server gibi bir hedef ilişkisel veritabanına yüklemek için SQL Server Integration Services (SSIS) gibi bir araç kullanın.
- Hive ODBC sürücüsünü kullanarak verileri doğrudan Excel veya C# ile sorgula.
- Apache Sqoop kullanarak hazırlanan düz CSV dosyalarını okuyun ve hedef ilişkisel veritabanına yükleyin.
Veri kaynakları
Veri kaynakları genellikle veri deponuzdaki mevcut verilerle eşleştirilebilen dış verilerdir, örneğin:
- Sosyal medya verileri, günlük dosyaları, algılayıcılar ve veri dosyaları oluşturan uygulamalar.
- Hava durumu istatistikleri veya satıcı satış numaraları gibi veri sağlayıcılarından alınan veri kümeleri.
- Uygun bir araç veya çerçeve aracılığıyla yakalanan, filtrelenen ve işlenen akış verileri.
Çıkış hedefleri
Hive'ı kullanarak aşağıdakiler dahil olmak üzere farklı hedef türlerine veri çıkışı yapabilirsiniz:
- SQL Server veya Azure SQL Veritabanı gibi bir ilişkisel veritabanı.
- Azure Synapse Analytics gibi bir veri ambarı.
- Excel.
- Azure tablosu ve blob depolama.
- Verilerin belirli biçimlerde veya belirli bilgi yapısı türleri içeren dosyalar olarak işlenmesini gerektiren uygulamalar veya hizmetler.
- Azure Cosmos DB gibi bir JSON Belge Deposu.
Dikkat edilmesi gereken noktalar
ETL modeli genellikle aşağıdakileri yapmak istediğinizde kullanılır:
* Akış verilerini veya büyük hacimli yarı yapılandırılmış veya yapılandırılmamış verileri dış kaynaklardan mevcut bir veritabanına veya bilgi sistemine yükleyin.
* Verileri yüklemeden önce, belki de kümeden geçen birden fazla dönüştürme geçişi kullanarak temizleyin, dönüştürün ve doğrulayın.
* Düzenli olarak güncelleştirilen raporlar ve görselleştirmeler oluşturun. Örneğin, raporun gün içinde oluşturulması çok uzun sürüyorsa, raporu gece çalışacak şekilde zamanlayabilirsiniz. Hive sorgusunu otomatik olarak çalıştırmak için Azure Logic Apps ve PowerShell'i kullanabilirsiniz.
Verilerin hedefi bir veritabanı değilse, sorgu içinde uygun biçimde bir dosya oluşturabilirsiniz, örneğin CSV. Bu dosya daha sonra Excel'e veya Power BI'a aktarılabilir.
ETL işleminin bir parçası olarak veriler üzerinde birkaç işlem yürütmeniz gerekiyorsa bunları nasıl yönettiğinizi göz önünde bulundurun. İşlemler çözüm içinde iş akışı olarak değil dış program tarafından denetlenerek bazı işlemlerin paralel olarak yürütülip yürütülemeyeceğine karar verin. Ve her işin ne zaman tamamlanmasını algılamak için. Hadoop içinde Oozie gibi bir iş akışı mekanizması kullanmak, dış betikleri veya özel programları kullanarak bir dizi işlemi düzenlemeye çalışmaktan daha kolay olabilir.