Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu hızlı başlangıçta Azure portalını kullanarak Azure HDInsight'ta bir Apache Spark kümesi oluşturacaksınız. Ardından bir Jupyter Not Defteri oluşturur ve Apache Hive tablolarında Spark SQL sorguları çalıştırmak için bunu kullanırsınız. Azure HDInsight, kuruluşlar için yönetilen, tam spektrumlu bir açık kaynak analiz hizmetidir. HDInsight için Apache Spark çerçevesi, bellek içi işlemeyi kullanarak hızlı veri analizi ve küme bilişimi sağlar. Jupyter Notebook verilerinizle etkileşim kurmanıza, kodu markdown metniyle birleştirmenize ve basit görselleştirmeler yapmanıza olanak tanır.
Kullanılabilir yapılandırmaların ayrıntılı açıklamaları için bkz. HDInsight'ta kümeleri ayarlama. Küme oluşturmak için portalın kullanımı hakkında daha fazla bilgi için bkz. Portalda küme oluşturma.
Birden çok kümeyi birlikte kullanıyorsanız bir sanal ağ oluşturmak isteyebilirsiniz; Spark kümesi kullanıyorsanız Hive Ambarı Bağlayıcısı'nı da kullanmak isteyebilirsiniz. Daha fazla bilgi için Azure HDInsight için sanal ağ planlama ve Apache Spark ve Apache Hive'ı Hive Ambar Bağlayıcı ile tümleştirme konularına bakın.
Önemli
HDInsight kümeleri için faturalama, kullanım durumuna bakılmaksızın dakika başına hesaplanır. Kullanmayı bitirdikten sonra kümenizi sildiğinizden emin olun. Daha fazla bilgi için bu makalenin Kaynakları temizleme bölümüne bakın.
Önkoşullar
Aktif bir aboneliğe sahip bir Azure hesabı. Ücretsiz bir hesap oluşturun.
HDInsight'ta Apache Spark kümesi oluşturma
Azure portalını kullanarak küme depolama alanı olarak Azure Depolama Blobları kullanan bir HDInsight kümesi oluşturursunuz. Data Lake Storage 2. Nesil'i kullanma hakkında daha fazla bilgi için bkz . Hızlı Başlangıç: HDInsight'ta kümeleri ayarlama.
Azure portalınaoturum açın.
Üstteki menüden + Kaynak oluştur'u seçin.
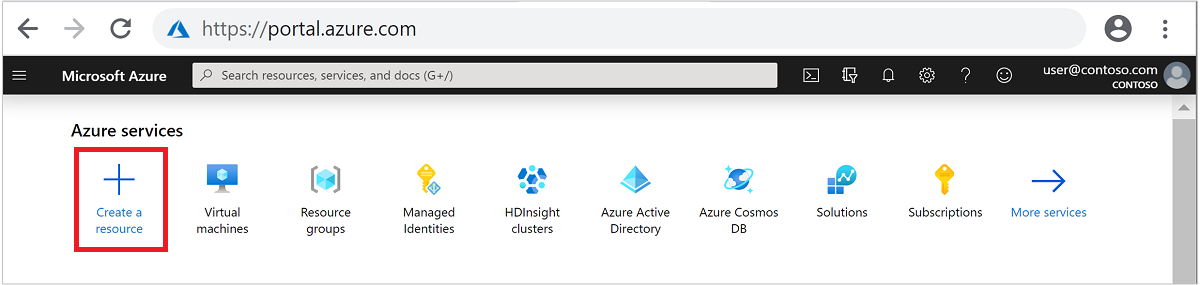
Analytics>Azure HDInsight seçerek HDInsight kümesi oluşturma sayfasına gidin.
Temel Bilgiler sekmesinden aşağıdaki bilgileri sağlayın:
Mülkiyet Description Subscription Açılan listeden küme için kullanılan Azure aboneliğini seçin. Kaynak grubu Açılan listeden mevcut kaynak grubunuzu seçin veya Yeni oluştur'u seçin. Küme adı Genel olarak benzersiz bir ad girin. Bölge Açılan listeden kümenin oluşturulduğu bölgeyi seçin. Erişilebilirlik bölgesi İsteğe bağlı - kümenizin dağıtılacağı bir kullanılabilirlik alanı belirtin Küme türü Liste açmak için küme türünü seçin. Listeden Spark'ı seçin. Küme sürümü Küme türü seçildikten sonra bu alan varsayılan sürümle otomatik olarak doldurulur. Küme oturum açma kullanıcı adı Küme oturum açma kullanıcı adını girin. Varsayılan ad yöneticidir. Bu hesabı, hızlı başlangıcın ilerleyen bölümlerinde Jupyter Not Defteri'nde oturum açmak için kullanırsınız. Küme oturum açma parolası Küme oturum açma parolasını girin. Secure Shell (SSH) kullanıcı adı SSH kullanıcı adını girin. Bu hızlı başlangıç için kullanılan SSH kullanıcı adı sshuser'dır. Varsayılan olarak, bu hesap Küme Oturum Açma kullanıcı adı hesabıyla aynı parolayı paylaşır. 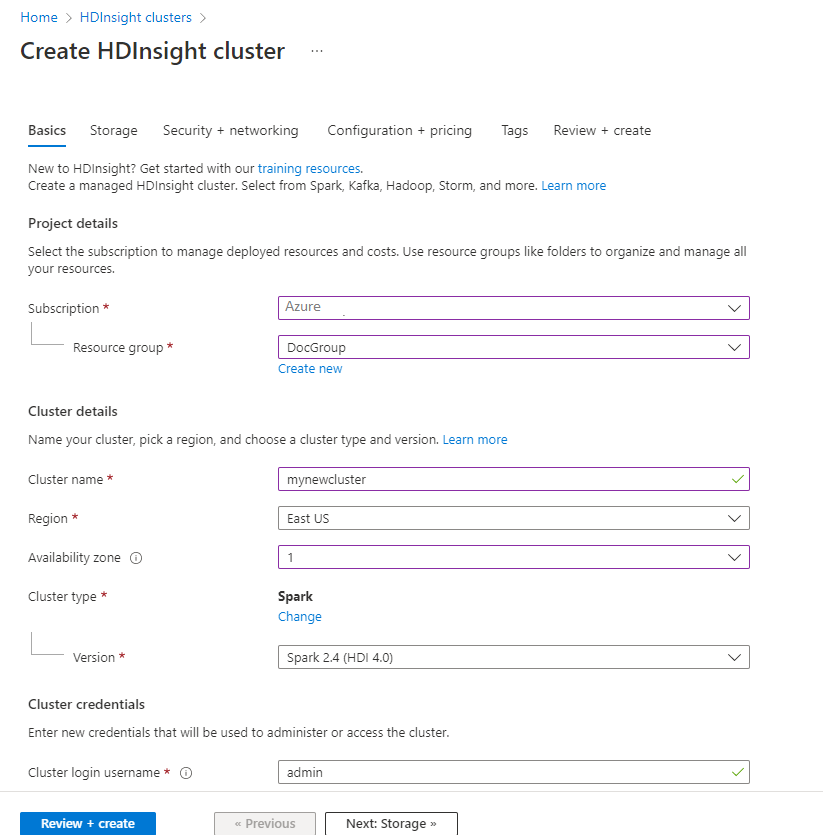
Depolama sayfasına devam etmek için İleri: Depolama'yı >> seçin.
Depolama bölümünde aşağıdaki değerleri sağlayın:
Mülkiyet Description Birincil depolama türü Azure Depolama varsayılan değerini kullanın. Seçim yöntemi Listeden seç varsayılan değerini kullanın. Birincil depolama hesabı Otomatik doldurulan değeri kullanın. Container Otomatik doldurulan değeri kullanın. 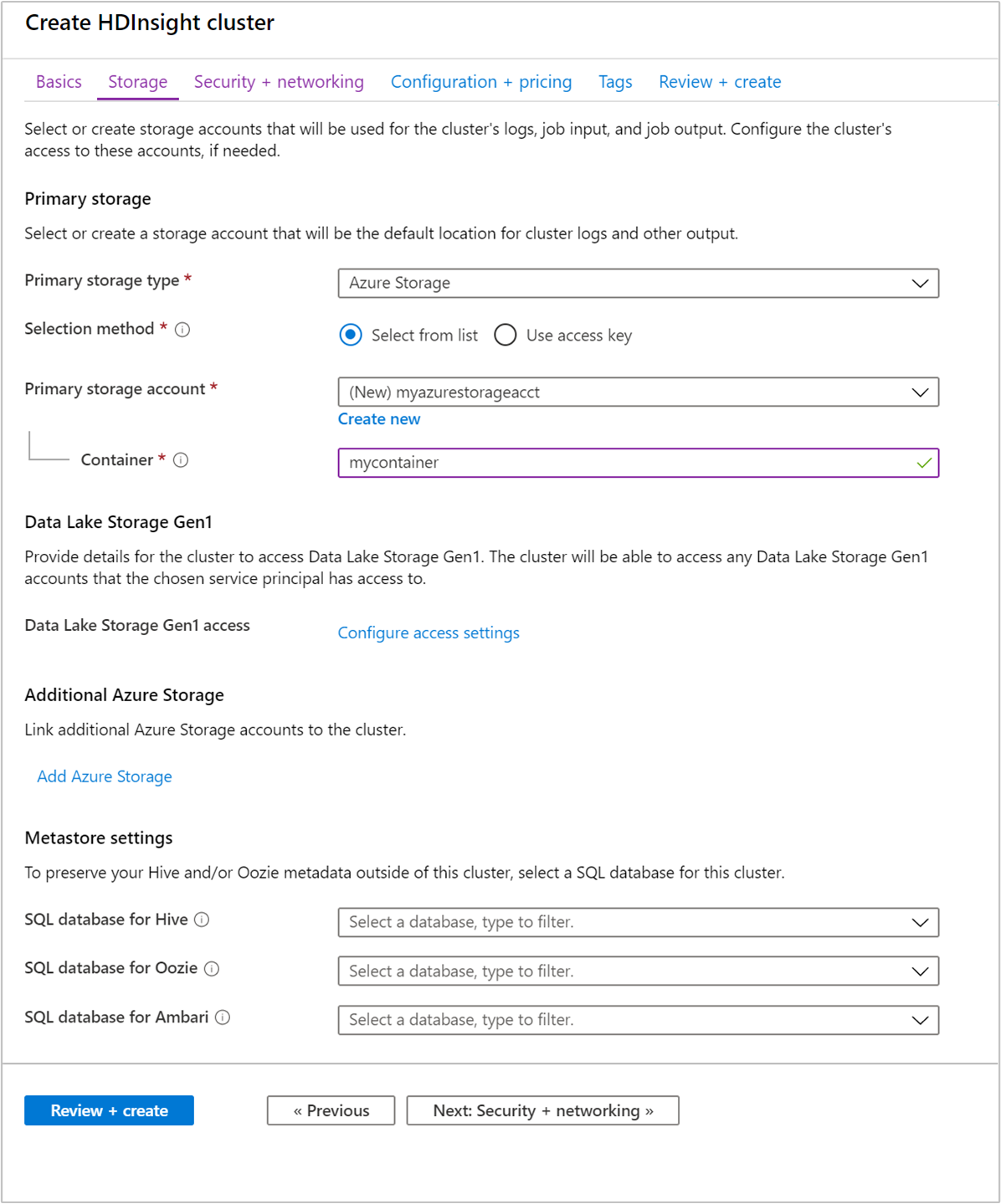
Devam etmek için Gözden Geçir ve Oluştur'u seçin.
Gözden geçir ve oluştur'un altında Oluştur'u seçin. Kümenin oluşturulması yaklaşık 20 dakika sürer. Sonraki oturumuna devam etmeden önce küme oluşturulması gerekir.
HDInsight kümeleri oluştururken bir sorunla karşılaşırsanız, bunu yapmak için doğru izinlere sahip olmayabilirsiniz. Daha fazla bilgi için bkz. Erişim denetimi gereksinimleri.
Jupyter Not Defteri oluşturma
Jupyter Notebook, çeşitli programlama dillerini destekleyen etkileşimli bir not defteri ortamıdır. Not defteri verilerinizle etkileşim kurmanıza, kodu markdown metniyle birleştirmenize ve basit görselleştirmeler gerçekleştirmenize olanak tanır.
Bir web tarayıcısından
https://CLUSTERNAME.azurehdinsight.net/jupyteradresine gidin, buradaCLUSTERNAMEkümenizin adıdır. İstenirse, küme oturum bilgilerini girin.Not defteri oluşturmak için Yeni>PySpark'ı seçin.
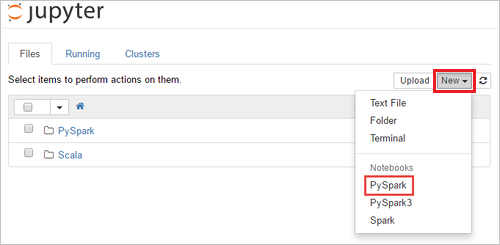
Yeni bir not defteri oluşturulur ve Untitled(Untitled.pynb) adıyla açılır.
Apache Spark SQL deyimlerini çalıştırma
SQL (Yapılandırılmış Sorgu Dili), verileri sorgulamak ve tanımlamak için en yaygın ve yaygın olarak kullanılan dildir. Spark SQL, tanıdık SQL söz dizimini kullanarak yapılandırılmış verileri işlemek için Apache Spark uzantısı olarak çalışır.
Çekirdeğin hazır olduğunu doğrulayın. Not defterinde çekirdek adının yanında boş bir daire gördüğünüzde çekirdek hazır olur. Düz daire çekirdeğin meşgul olduğunu belirtir.

Not defterini ilk kez başlattığınızda, çekirdek arka planda bazı görevler gerçekleştirir. Çekirdeğin hazır olmasını bekleyin.
Aşağıdaki kodu boş bir hücreye yapıştırın ve kodu çalıştırmak için SHIFT + ENTER tuşlarına basın. komutu, kümedeki Hive tablolarını listeler:
%%sql SHOW TABLESHDInsight kümenizle Jupyter Notebook kullandığınızda, Spark SQL kullanarak Hive sorguları çalıştırmak için kullanabileceğiniz bir ön ayar
sqlContextelde edersiniz.%%sqlJupyter Notebook'a Hive sorgusunu çalıştırmak için ön ayarısqlContextkullanmasını söyler. Sorgu, varsayılan olarak tüm HDInsight kümeleriyle birlikte gelen hive tablosundan (hivesampletable) ilk 10 satırı alır. Sonuçları almak yaklaşık 30 saniye sürer. Çıktı şuna benzer: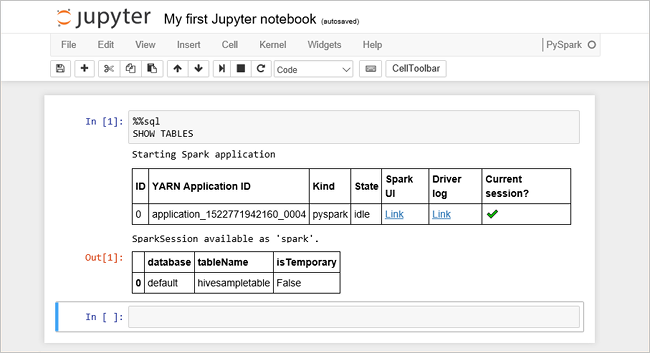 is quickstart." border="true":::
is quickstart." border="true":::Jupyter'da her sorgu çalıştırdığınızda, web tarayıcısı pencere başlığınızda not defteri başlığıyla birlikte bir (Meşgul) durumu gösterilir. Ayrıca sağ üst köşedeki PySpark metninin yanında düz bir daire görürsünüz.
içindeki
hivesampletableverileri görmek için başka bir sorgu çalıştırın.%%sql SELECT * FROM hivesampletable LIMIT 10Ekran, sorgu çıkışını gösterecek şekilde yenilenir.
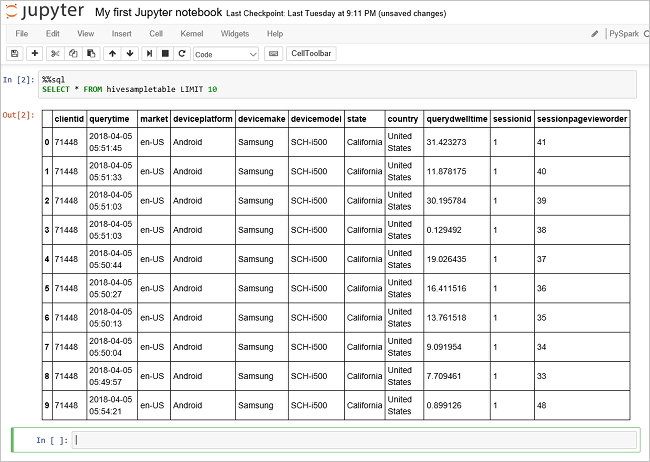 Insight" border="true":::
Insight" border="true":::Not defterindeki Dosya menüsünde Kapat ve Durdur'u seçin. Not defterinin kapatılması küme kaynaklarını serbest bırakır.
Kaynakları temizle
HDInsight verilerinizi Azure Depolama'ya veya Azure Data Lake Storage'a kaydeder, böylece kullanılmadığında kümeyi güvenle silebilirsiniz. Kullanımda olmasa bile HDInsight kümesi için de ücretlendirilirsiniz. Küme ücretleri depolama ücretlerinden çok daha fazla olduğundan, kullanımda olmayan kümeleri silmek ekonomik bir anlam ifade eder. Sonraki adımlarda listelenen öğretici üzerinde hemen çalışmayı planlıyorsanız kümeyi korumak isteyebilirsiniz.
Azure portalına dönün ve Sil'i seçin.
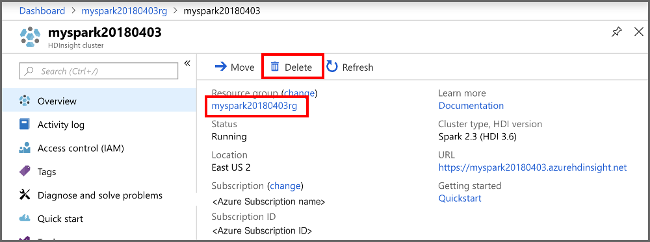 sight cluster" border="true":::
sight cluster" border="true":::
Ayrıca kaynak grubu adını seçerek kaynak grubu sayfasını açabilir ve ardından Kaynak grubunu sil'i seçebilirsiniz. Kaynak grubunu silerek hem HDInsight kümesini hem de varsayılan depolama hesabını silersiniz.
Sonraki Adımlar
Bu hızlı başlangıçta HDInsight'ta Apache Spark kümesi oluşturmayı ve temel bir Spark SQL sorgusu çalıştırmayı öğrendiniz. Örnek veriler üzerinde etkileşimli sorgular çalıştırmak için HDInsight kümesi kullanmayı öğrenmek için sonraki öğreticiye ilerleyin.