Apache Spark Yapılandırılmış Akışına Genel Bakış
Apache Spark Yapılandırılmış Akış, veri akışlarını işlemek için ölçeklenebilir, yüksek aktarım hızına sahip, hataya dayanıklı uygulamalar uygulamanıza olanak tanır. Yapılandırılmış Akış, Spark SQL altyapısını temel alır ve Spark SQL Veri Çerçeveleri ve Veri Kümelerindeki yapıları geliştirerek akış sorgularını toplu sorgu yazdığınız gibi yazabilirsiniz.
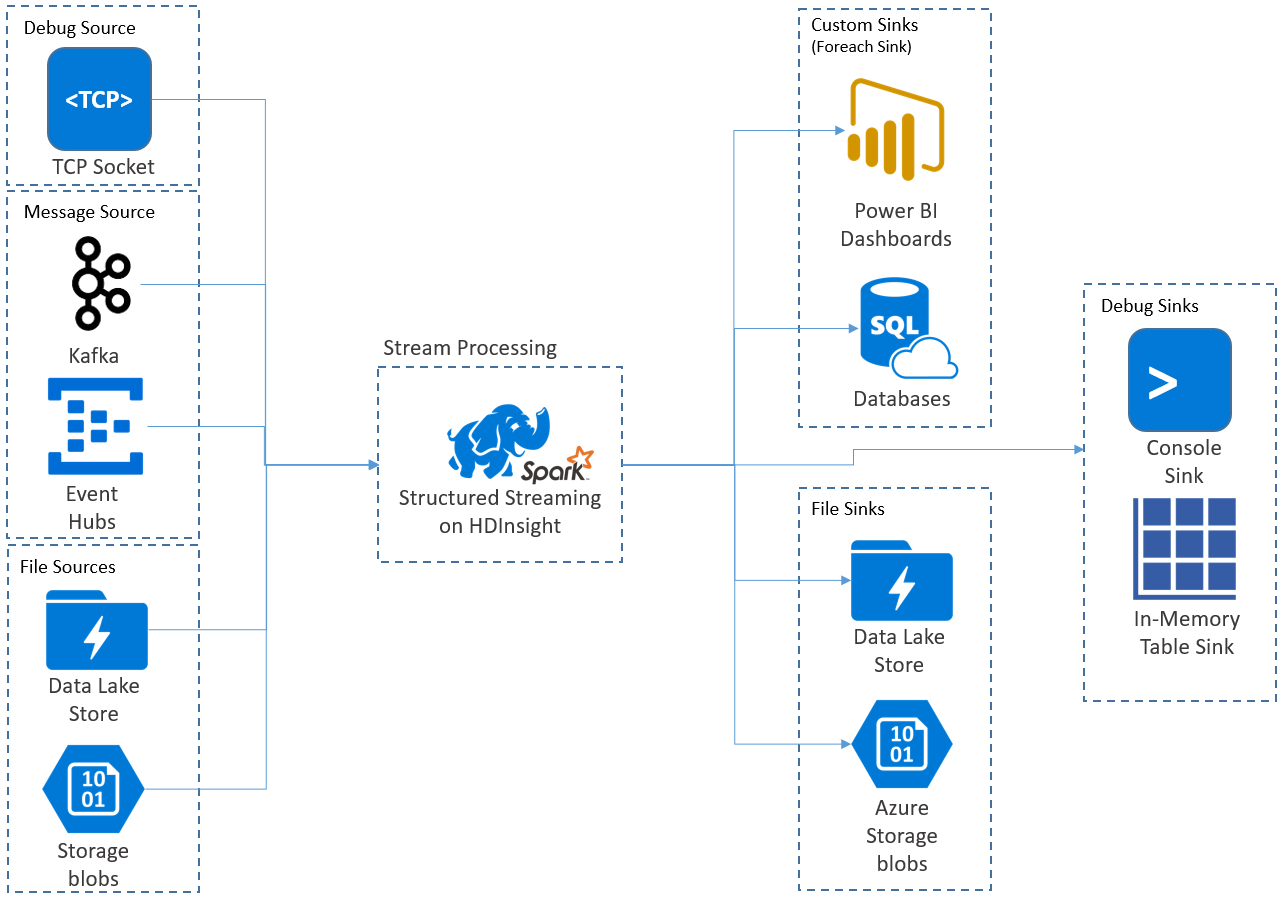
Yapılandırılmış Akış uygulamaları HDInsight Spark kümelerinde çalışır ve Apache Kafka, tcp yuvası (hata ayıklama amacıyla), Azure Depolama veya Azure Data Lake Depolama akış verilerine bağlanır. Dış depolama hizmetlerini kullanan ikinci iki seçenek, depolama alanına eklenen yeni dosyaları izlemenizi ve içeriklerini akışa alınmış gibi işlemenizi sağlar.
Yapılandırılmış Akış, giriş verilerine seçim, yansıtma, toplama, pencereleme ve akış DataFrame'i başvuru DataFrame'leri ile birleştirme gibi işlemleri uyguladığınız uzun süre çalışan bir sorgu oluşturur. Ardından, özel kod (SQL Veritabanı veya Power BI gibi) kullanarak sonuçları dosya depolamaya (Azure Depolama Blobları veya Data Lake Depolama) veya herhangi bir veri deposuna verirsiniz. Yapılandırılmış Akış ayrıca yerel olarak hata ayıklamak için konsola ve HDInsight'ta hata ayıklama için oluşturulan verileri görebilmeniz için bellek içi bir tabloya çıkış sağlar.
Not
Spark Yapılandırılmış Akış, Spark Akışı'nın (D Akışlar) yerini alıyor. Bundan sonra Yapılandırılmış Akış geliştirmeler ve bakım alırken D Akışlar yalnızca bakım modunda olacaktır. Yapılandırılmış Akış şu anda D Akışlar'nin desteklediği kaynaklar ve havuzlar için kullanıma hazır değildir, bu nedenle uygun Spark akışı işleme seçeneğini belirlemek için gereksinimlerinizi değerlendirin.
Tablo olarak Akışlar
Spark Yapılandırılmış Akış, bir veri akışını ayrıntılı olarak ilişkisiz bir tablo olarak temsil eder, yani yeni veriler geldikçe tablo büyümeye devam eder. Bu giriş tablosu uzun süre çalışan bir sorgu tarafından sürekli işlenir ve sonuçlar bir çıkış tablosuna gönderilir:

Yapılandırılmış Akış'ta veriler sisteme ulaşır ve hemen bir giriş tablosuna alınır. Bu giriş tablosunda işlem gerçekleştiren sorgular (DataFrame ve Veri Kümesi API'lerini kullanarak) yazarsınız. Sorgu çıktısı, sonuç tablosu olan başka bir tablo döndürür. Sonuçlar tablosu, ilişkisel veritabanı gibi bir dış veri deposu için veri çizdiğiniz sorgunuzun sonuçlarını içerir. Giriş tablosundan verilerin işlenme zamanlaması tetikleyici aralığı tarafından denetlenir. Varsayılan olarak tetikleyici aralığı sıfırdır, bu nedenle Yapılandırılmış Akış verileri gelir gelmez işlemeye çalışır. Uygulamada bu, Yapılandırılmış Akış önceki sorgunun çalıştırmasını işlemeyi tamamladıktan hemen sonra yeni alınan verilerde başka bir işleme çalıştırması başlattığı anlamına gelir. Tetikleyiciyi belirli bir aralıkta çalışacak şekilde yapılandırarak akış verilerinin zaman tabanlı toplu işlerde işlenmesini sağlayabilirsiniz.
Sonuç tablolarındaki veriler yalnızca sorgunun son işlenme zamanından (ekleme modu) sonra yeni olan verileri içerebilir veya tablo her yeni veri olduğunda yenilenebilir, böylece akış sorgusu başladığından (tam mod) itibaren tablo tüm çıkış verilerini içerir.
Ekleme modu
Ekleme modunda, sonuçlar tablosunda yalnızca son sorgu çalıştırmasının ardından sonuçlar tablosuna eklenen satırlar bulunur ve dış depolama alanına yazılır. Örneğin, en basit sorgu yalnızca giriş tablosundaki tüm verileri değiştirilmeden sonuç tablosuna kopyalar. Tetikleyici aralığı her geçtiğinde, yeni veriler işlenir ve yeni verileri temsil eden satırlar sonuçlar tablosunda görünür.
Termostat gibi sıcaklık algılayıcılarından gelen telemetri verilerini işleyebileceğiniz bir senaryo düşünün. İlk tetikleyicinin 95 derecelik sıcaklık okuması olan cihaz 1 için saat 00:01'de bir olayı işlediğini varsayalım. Sorgunun ilk tetikleyicisinde, sonuçlar tablosunda yalnızca saat 00:01 olan satır görüntülenir. Başka bir olay geldiğinde saat 00:02'de, tek yeni satır 00:02 zamanına sahip satırdır ve sonuç tablosunda yalnızca bir satır yer alır.
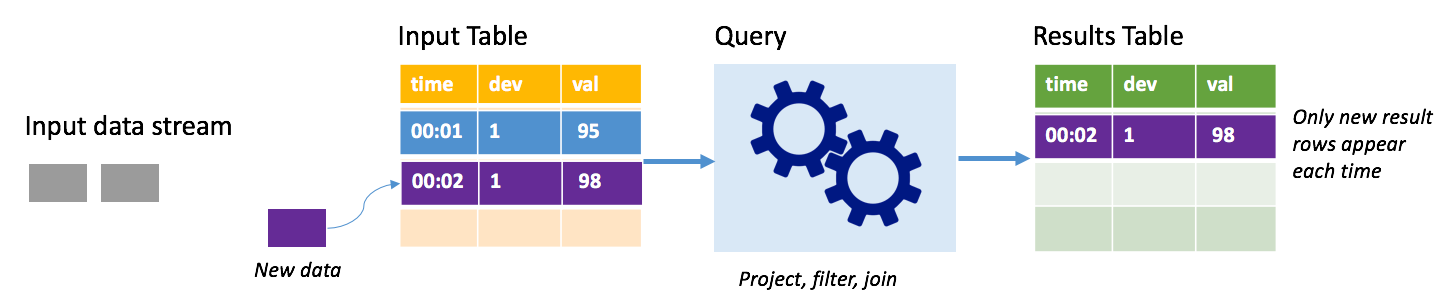
Ekleme modunu kullanırken sorgunuz projeksiyonlar (önem verdiği sütunları seçme), filtreleme (yalnızca belirli koşullarla eşleşen satırları seçme) veya birleştirme (verileri statik arama tablosundaki verilerle artırma) uygular. Ekleme modu, yalnızca ilgili yeni veri noktalarını dış depolama alanına göndermeyi kolaylaştırır.
Tamamlama modu
Bu kez tam modu kullanarak aynı senaryoyu göz önünde bulundurun. Tam modda, çıkış tablosunun tamamı her tetikleyicide yenilenir, böylece tablo yalnızca en son tetikleyici çalıştırmasından değil tüm çalıştırmalardan veriler içerir. Giriş tablosundan sonuçlar tablosuna değiştirilmemiş verileri kopyalamak için tam modu kullanabilirsiniz. Tetiklenen her çalıştırmada, yeni sonuç satırları önceki tüm satırlarla birlikte görünür. Çıktı sonuçları tablosu, sorgu başladıktan sonra toplanan tüm verileri depolar ve sonunda belleğiniz tükenecektir. Tam mod, gelen verileri bir şekilde özetleyen toplama sorgularıyla kullanılmak üzere tasarlanmıştır, bu nedenle her tetikleyicide sonuç tablosu yeni bir özetle güncelleştirilir.
Şu ana kadar işlenmiş beş saniyelik veriler olduğunu ve altıncı saniye için verileri işlemenin zamanı olduğunu varsayalım. Giriş tablosunda saat 00:01 ve saat 00:03 için olaylar bulunur. Bu örnek sorgunun amacı, cihazın ortalama sıcaklığını beş saniyede bir vermektir. Bu sorgunun uygulanması, her 5 saniyelik pencere içinde kalan tüm değerleri alan, sıcaklığın ortalamasını alan ve bu aralıktaki ortalama sıcaklık için bir satır oluşturan bir toplama uygular. İlk 5 saniyelik pencerenin sonunda iki tanımlama grubu vardır: (00:01, 1, 95) ve (00:03, 1, 98). Dolayısıyla 00:00-00:05 penceresi için toplama işlemi, ortalama sıcaklığı 96,5 derece olan bir tanımlama grubu oluşturur. Sonraki 5 saniyelik pencerede, saat 00:06'da yalnızca bir veri noktası vardır, dolayısıyla sonuçta elde edilen ortalama sıcaklık 98 derecedir. Saat 00:10'da, tam modu kullanarak sonuç tablosunda hem windows 00:00-00:05 hem de 00:05-00:10 için satırlar bulunur çünkü sorgu yalnızca yeni satırları değil, tüm toplu satırların çıkışını verir. Bu nedenle, yeni pencereler eklendikçe sonuçlar tablosu büyümeye devam eder.
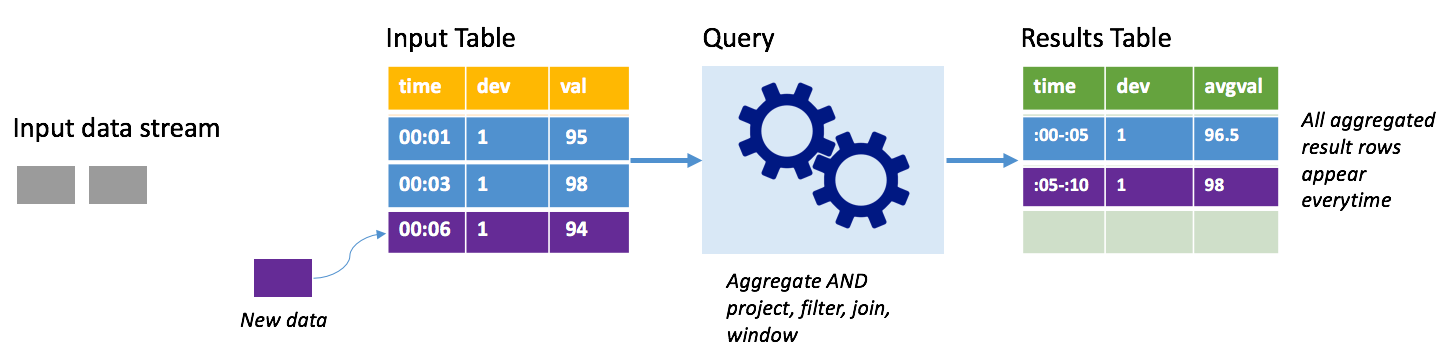
Tam modu kullanan tüm sorgular tablonun sınır olmadan büyümesine neden olmaz. Önceki örnekte, zaman penceresine göre sıcaklığı ortalamasını almak yerine cihaz kimliğine göre ortalaması alındığını düşünün. Sonuç tablosu, bu cihazdan alınan tüm veri noktalarında cihaz için ortalama sıcaklık ile sabit sayıda satır (cihaz başına bir tane) içerir. Yeni sıcaklıklar alındığında, sonuç tablosu tablodaki ortalamaların her zaman güncel olması için güncelleştirilir.
Spark Yapılandırılmış Akış uygulamasının bileşenleri
Basit bir örnek sorgu, sıcaklık okumalarını saat uzunluğundaki pencerelere göre özetleyebilir. Bu durumda veriler Azure Depolama'deki JSON dosyalarında depolanır (HDInsight kümesi için varsayılan depolama alanı olarak eklenir):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Bu JSON dosyaları, HDInsight kümesinin kapsayıcısının altındaki alt klasörde depolanır temps .
Giriş kaynağını tanımlama
İlk olarak, verilerin kaynağını ve bu kaynağın gerektirdiği ayarları açıklayan bir DataFrame yapılandırın. Bu örnek, Azure Depolama'daki JSON dosyalarından çizimler oluşturur ve okuma zamanında bu dosyalara bir şema uygular.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Sorguyu uygulama
Ardından, Streaming DataFrame'e yönelik istenen işlemleri içeren bir sorgu uygulayın. Bu durumda, bir toplama tüm satırları 1 saatlik pencereler halinde gruplandırıp bu 1 saatlik pencerede minimum, ortalama ve maksimum sıcaklıkları hesaplar.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Çıkış havuzu tanımlama
Ardından, her tetikleyici aralığı içinde sonuçlar tablosuna eklenen satırların hedefini tanımlayın. Bu örnek yalnızca tüm satırları daha sonra SparkSQL ile sorgulayabileceğiniz bellek içi bir tabloya temps verir. Tam çıkış modu, tüm pencereler için tüm satırların her seferinde çıkış olmasını sağlar.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Sorguyu başlatma
Akış sorgusunu başlatın ve sonlandırma sinyali alınana kadar çalıştırın.
val query = streamingOutDF.start()
Sonuçları görüntüleme
Sorgu çalışırken, aynı SparkSession'da sorgu sonuçlarının temps depolandığı tabloda bir SparkSQL sorgusu çalıştırabilirsiniz.
select * from temps
Bu sorgu aşağıdakine benzer sonuçlar verir:
| Pencere | min(temp) | ort(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Spark Yapılandırılmış Akış API'sinin yanı sıra desteklediği giriş veri kaynakları, işlemler ve çıkış havuzları hakkında ayrıntılı bilgi için bkz . Apache Spark Yapılandırılmış Akış Programlama Kılavuzu.
Denetim noktası oluşturma ve önceden yazma günlükleri
Dayanıklı ve hataya dayanıklılık sağlamak için Yapılandırılmış Akış , düğüm hatalarında bile akış işlemenin kesintisiz devam etmesini sağlamak için denetim noktalarına dayanır. HDInsight'ta Spark, Azure Depolama veya Data Lake Depolama dayanıklı depolama için denetim noktaları oluşturur. Bu denetim noktaları akış sorgusu hakkındaki ilerleme bilgilerini depolar. Ayrıca, Yapılandırılmış Akış önceden yazma günlüğü (WAL) kullanır. WAL, alınan ancak henüz bir sorgu tarafından işlenmemiş alınan verileri yakalar. Bir hata oluşursa ve WAL'dan işleme yeniden başlatılırsa, kaynaktan alınan olaylar kaybolmaz.
Spark Streaming uygulamalarını dağıtma
Genellikle bir Spark Streaming uygulamasını yerel olarak bir JAR dosyasına derler ve ardından JAR dosyasını HDInsight kümenize bağlı varsayılan depolama alanına kopyalayarak HDInsight üzerinde Spark'a dağıtırsınız. Uygulamanızı post işlemi kullanarak kümenizden edinebileceğiniz Apache Livy REST API'leriyle başlatabilirsiniz. POST'un gövdesi JAR'nizin yolunu, ana yöntemi akış uygulamasını tanımlayıp çalıştıran sınıfın adını ve isteğe bağlı olarak işin kaynak gereksinimlerini (yürütücü sayısı, bellek ve çekirdek sayısı gibi) ve uygulama kodunuzun gerektirdiği tüm yapılandırma ayarlarını sağlayan bir JSON belgesi içerir.
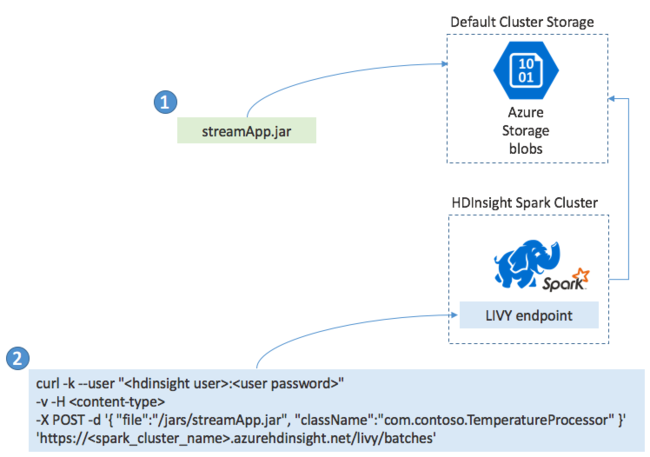
Tüm uygulamaların durumu, LIVY uç noktasına yönelik get isteğiyle de denetlenebilir. Son olarak, LIVY uç noktasına bir DELETE isteği vererek çalışan bir uygulamayı sonlandırabilirsiniz. LIVY API'siyle ilgili ayrıntılar için bkz . Apache LIVY ile uzak işler
Sonraki adımlar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin