Kurumsal Güvenlik Paketi ile HDInsight'ta Spark SQL için Apache Ranger ilkelerini yapılandırma
Bu makalede, HDInsight'ta Enterprise Security Package ile Spark SQL için Apache Ranger ilkelerinin nasıl yapılandırıldığı açıklanır.
Bu makalede şunları öğreneceksiniz:
- Apache Ranger ilkeleri oluşturun.
- Uygulanan Ranger ilkelerini doğrulayın.
- Spark SQL için Apache Ranger'ı ayarlama yönergelerini uygulayın.
Önkoşullar
- Kurumsal Güvenlik Paketi ile HDInsight sürüm 5.1'de Apache Spark kümesi
Apache Ranger yönetici kullanıcı arabirimine Bağlan
Tarayıcıdan, URL'sini
https://ClusterName.azurehdinsight.net/Ranger/kullanarak Ranger yönetici kullanıcı arabirimine bağlanın.Spark kümenizin adına geçin
ClusterName.Microsoft Entra yönetici kimlik bilgilerinizi kullanarak oturum açın. Microsoft Entra yönetici kimlik bilgileri HDInsight kümesi kimlik bilgileri veya Linux HDInsight düğümü Secure Shell (SSH) kimlik bilgileriyle aynı değildir.
Etki alanı kullanıcılarını oluşturma
Etki alanı kullanıcıları oluşturma sparkuser hakkında bilgi için bkz . ESP ile HDInsight kümesi oluşturma. Üretim senaryosunda, etki alanı kullanıcıları Microsoft Entra kiracınızdan gelir.
Ranger ilkesi oluşturma
Bu bölümde iki Ranger ilkesi oluşturacaksınız:
- Spark SQL'den erişim için bir erişim
hivesampletableilkesi - içindeki sütunları karartma için bir maskeleme ilkesi
hivesampletable
Ranger erişim ilkesi oluşturma
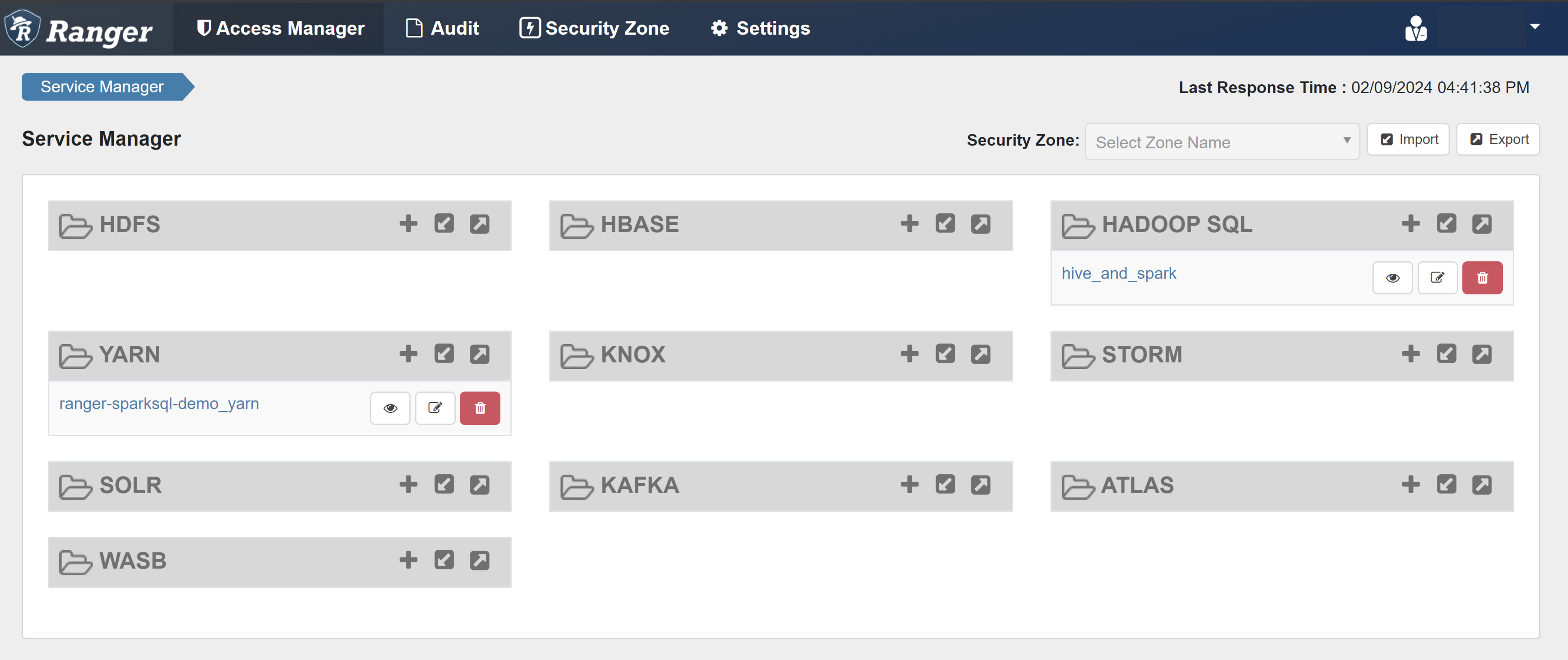
Ranger yönetici kullanıcı arabirimini açın.
HADOOP SQL'in altında hive_and_spark'ı seçin.
Erişim sekmesinde Yeni İlke Ekle'yi seçin.
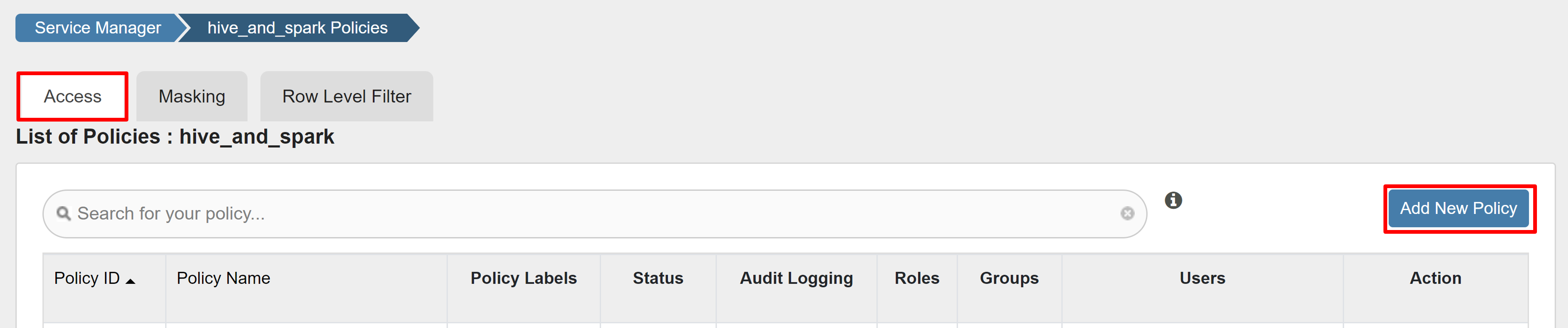
Aşağıdaki değerleri girin:
Özellik Değer İlke Adı read-hivesampletable-all database varsayılan table hivesampletable sütun * Kullanıcı Seçin sparkuserİzinler select 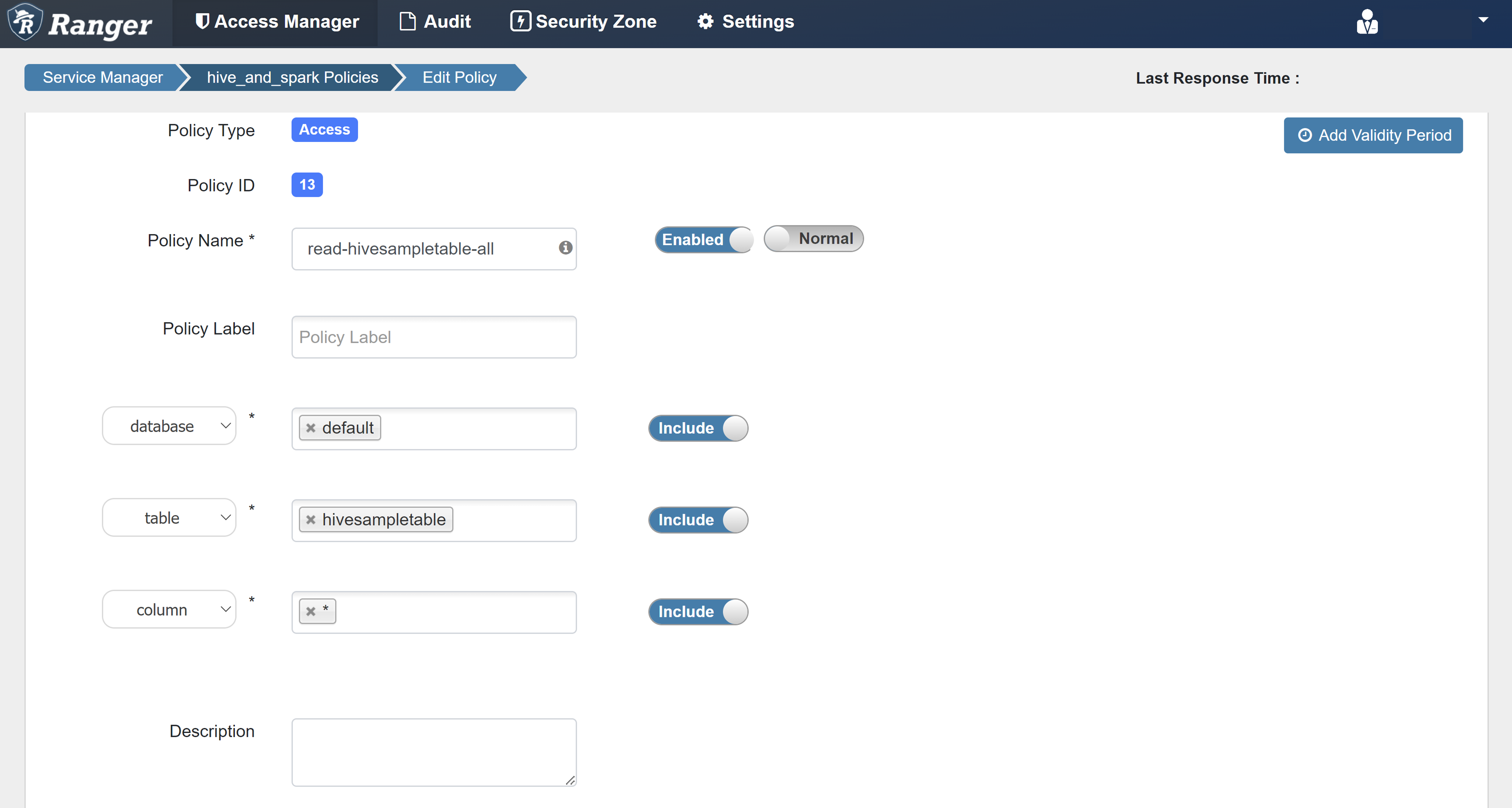
Kullanıcı Seç için bir etki alanı kullanıcısı otomatik olarak doldurulmazsa Ranger'ın Microsoft Entra Id ile eşitlenmesi için birkaç dakika bekleyin.
İlkeyi kaydetmek için Ekle'yi seçin.
Zeppelin not defterini açın ve ilkeyi doğrulamak için aşağıdaki komutu çalıştırın:
%sql select * from hivesampletable limit 10;İlke uygulanmadan önce elde edilen sonuç aşağıdadır:

İlke uygulandıktan sonra elde edilen sonuç aşağıdadır:





Ranger maskeleme ilkesi oluşturma
Aşağıdaki örnekte, sütunu maskeleyen bir ilkenin nasıl oluşturulacağı gösterilmektedir:
Maskeleme sekmesinde Yeni İlke Ekle'yi seçin.

Aşağıdaki değerleri girin:
Özellik Değer İlke Adı mask-hivesampletable Hive Veritabanı varsayılan Hive Tablosu hivesampletable Hive Sütunu devicemake Kullanıcı Seçin sparkuserErişim Türleri select Maskeleme Seçeneğini Belirleme Karma 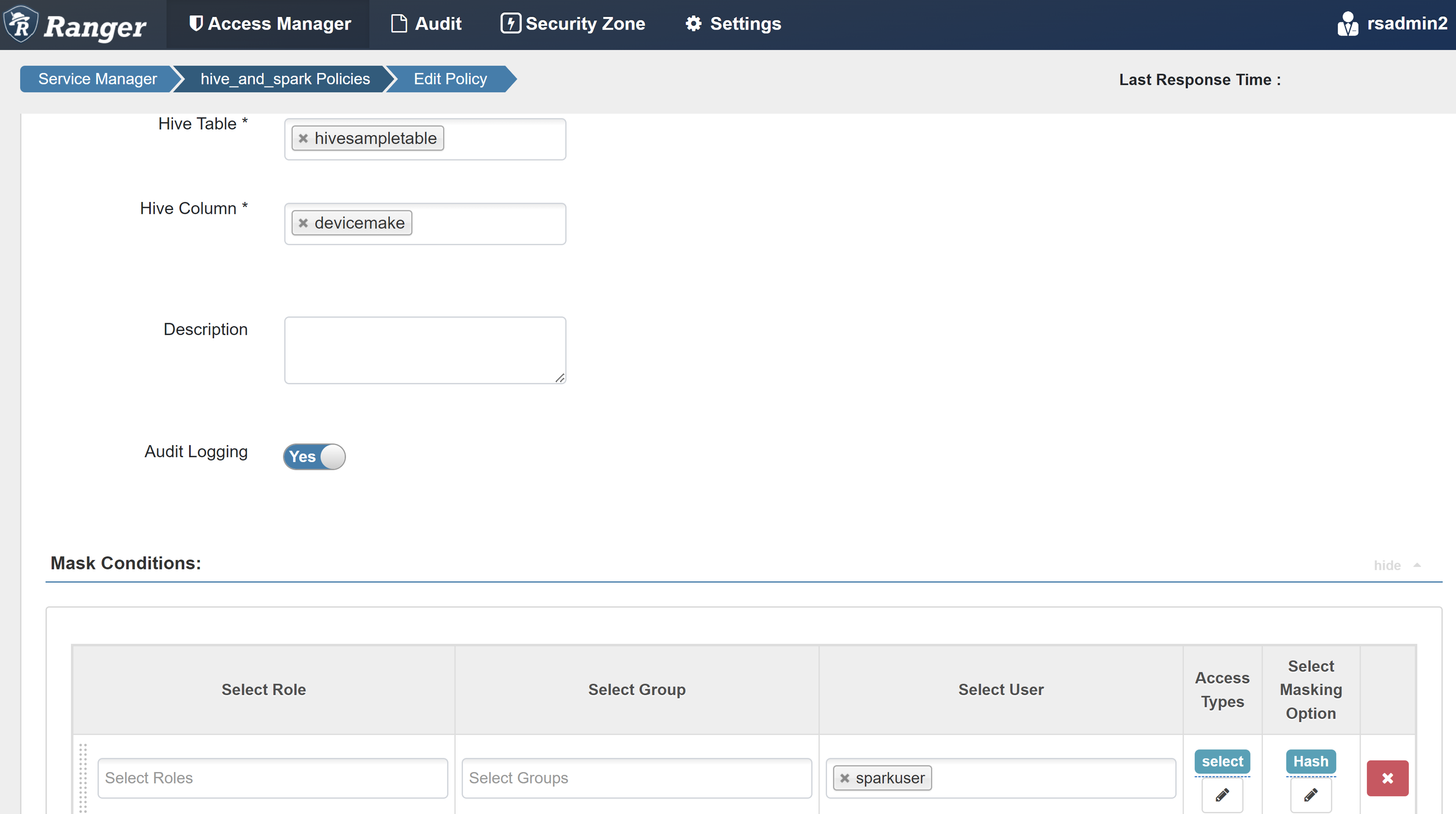
İlkeyi kaydetmek için Kaydet'i seçin.
Zeppelin not defterini açın ve ilkeyi doğrulamak için aşağıdaki komutu çalıştırın:
%sql select clientId, deviceMake from hivesampletable;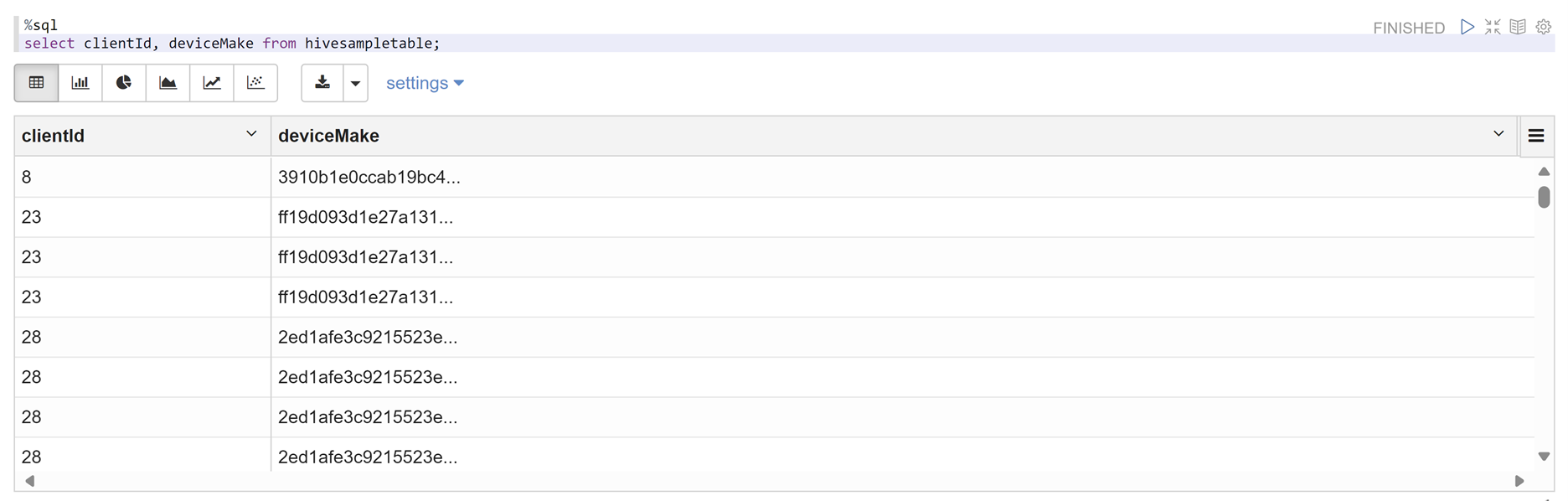



Not
Varsayılan olarak, Hive ve Spark SQL ilkeleri Ranger'da yaygındır.
Spark SQL için Apache Ranger'ı ayarlama yönergelerini uygulama
Aşağıdaki senaryolarda, yeni bir Ranger veritabanı kullanarak ve mevcut ranger veritabanını kullanarak HDInsight 5.1 Spark kümesi oluşturma yönergeleri araştırilmektedir.
Senaryo 1: HDInsight 5.1 Spark kümesi oluştururken yeni ranger veritabanı kullanma
Küme oluşturmak için yeni bir Ranger veritabanı kullandığınızda Hive ve Spark için Ranger ilkelerini içeren ilgili Ranger deposu Ranger veritabanındaki Hadoop SQL hizmetinde hive_and_spark adı altında oluşturulur.

İlkeleri düzenlerseniz, bunlar hem Hive hem de Spark'a uygulanır.
Şu noktaları göz önünde bulundurun:
Hem Hive (örneğin, DB1) hem de Spark (örneğin, DB1) katalogları için kullanılan aynı ada sahip iki meta veri deposu veritabanınız varsa:
- Spark Spark kataloğunu ()
metastore.catalog.default=sparkkullanıyorsa, ilkeler Spark kataloğunun DB1 veritabanına uygulanır. - Spark Hive kataloğunu ()
metastore.catalog.default=hivekullanıyorsa, ilkeler Hive kataloğunun DB1 veritabanına uygulanır.
Ranger'ın perspektifinden bakıldığında, Hive ve Spark kataloglarının DB1'i arasında ayrım yapmak için hiçbir yol yoktur.
Bu gibi durumlarda şunları yapmanızı öneririz:
- Hem Hive hem de Spark için Hive kataloğunu kullanın.
- İlkelerin kataloglar genelindeki veritabanlarına uygulanmaması için hem Hive hem de Spark katalogları için farklı veritabanı, tablo ve sütun adlarını koruyun.
- Spark Spark kataloğunu ()
Hive kataloğunu hem Hive hem de Spark için kullanıyorsanız aşağıdaki örneği göz önünde bulundurun.
Geçerli xyz kullanıcısıyla Hive aracılığıyla table1 adlı bir tablo oluşturduğunuzu varsayalım. Sahibi xyz kullanıcısı olan table1.db adlı bir Hadoop Dağıtılmış Dosya Sistemi (HDFS) dosyası oluşturur.
Şimdi Spark SQL oturumunu başlatmak için abc kullanıcısını kullandığınızı düşünün. abc kullanıcısının bu oturumunda, tablo1'e herhangi bir şey yazmaya çalışırsanız, tablo sahibi xyz olduğundan başarısız olmaya bağlıdır.
Böyle bir durumda, tabloyu güncelleştirmek için Hive ve Spark SQL'de aynı kullanıcıyı kullanmanızı öneririz. Bu kullanıcının güncelleştirme işlemlerini gerçekleştirmek için yeterli ayrıcalıklara sahip olması gerekir.
Senaryo 2: HDInsight 5.1 Spark kümesi oluştururken mevcut ranger veritabanını (mevcut ilkelerle) kullanma
Mevcut bir Ranger veritabanını kullanarak HDInsight 5.1 kümesi oluşturduğunuzda, bu veritabanında yeni kümenin adı şu biçimde yeni bir Ranger deposu yeniden oluşturulur: hive_and_spark.

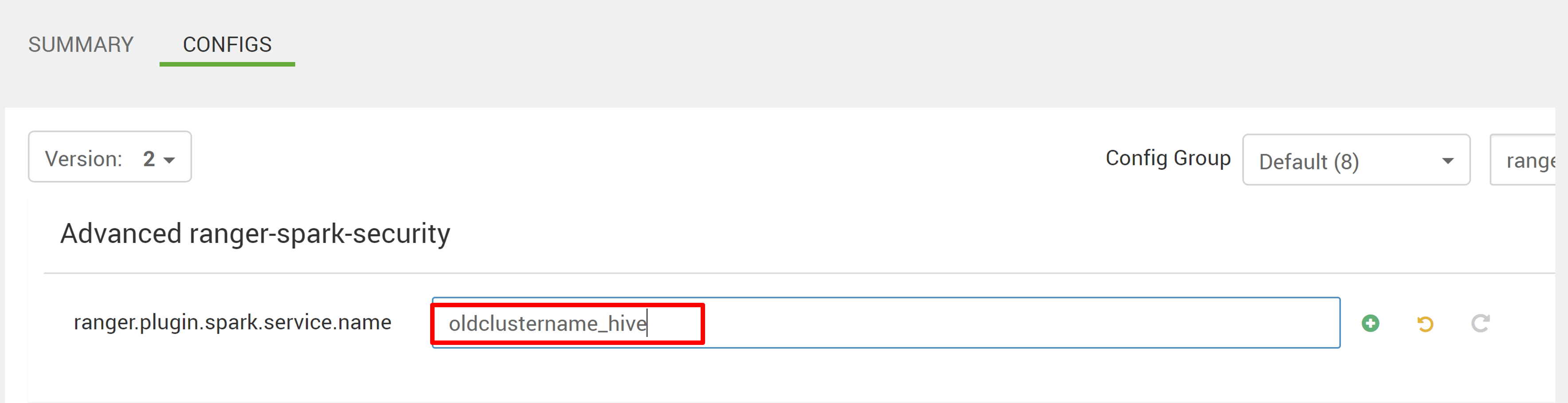
Ranger deposunda tanımlanan ilkelerin Hadoop SQL hizmetindeki mevcut Ranger veritabanında oldclustername_hive adı altında zaten olduğunu varsayalım. Yeni HDInsight 5.1 Spark kümesinde aynı ilkeleri paylaşmak istiyorsunuz. Bu hedefe ulaşmak için aşağıdaki adımları kullanın.
Not
Ambari yönetici ayrıcalıklarına sahip bir kullanıcı yapılandırma güncelleştirmeleri gerçekleştirebilir.
Yeni HDInsight 5.1 kümenizden Ambari kullanıcı arabirimini açın.
Spark3 hizmetine ve ardından Yapılandırmalar'a gidin.
Gelişmiş ranger-spark-security yapılandırmasını açın.
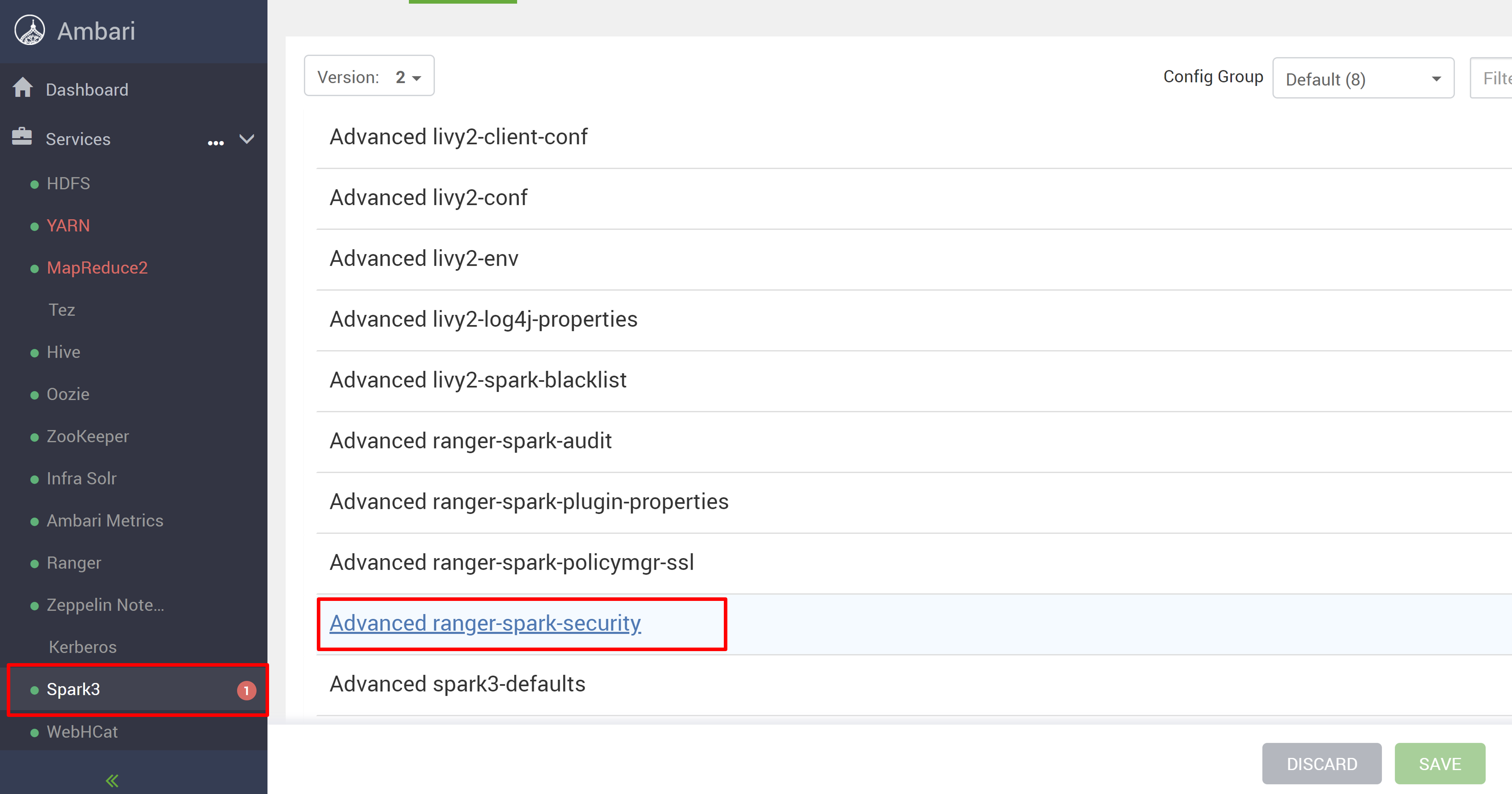
veya SSH kullanarak bu yapılandırmayı /etc/spark3/conf içinde de açabilirsiniz.
eski ilke deposu oldclustername_hive işaret etmek için iki yapılandırmayı (ranger.plugin.spark.service.name ve ranger.plugin.spark.policy.cache.dir) düzenleyin ve ardından yapılandırmaları kaydedin.
Ambari:
XML dosyası:

Ambari'den Ranger ve Spark hizmetlerini yeniden başlatın.
Ranger yönetici kullanıcı arabirimini açın ve HADOOP SQL hizmeti altındaki düzenle düğmesine tıklayın.

oldclustername_hive hizmeti için policy.download.auth.users ve tag.download.auth.users listesine rangersparklookup kullanıcısını ekleyin ve kaydet'e tıklayın.






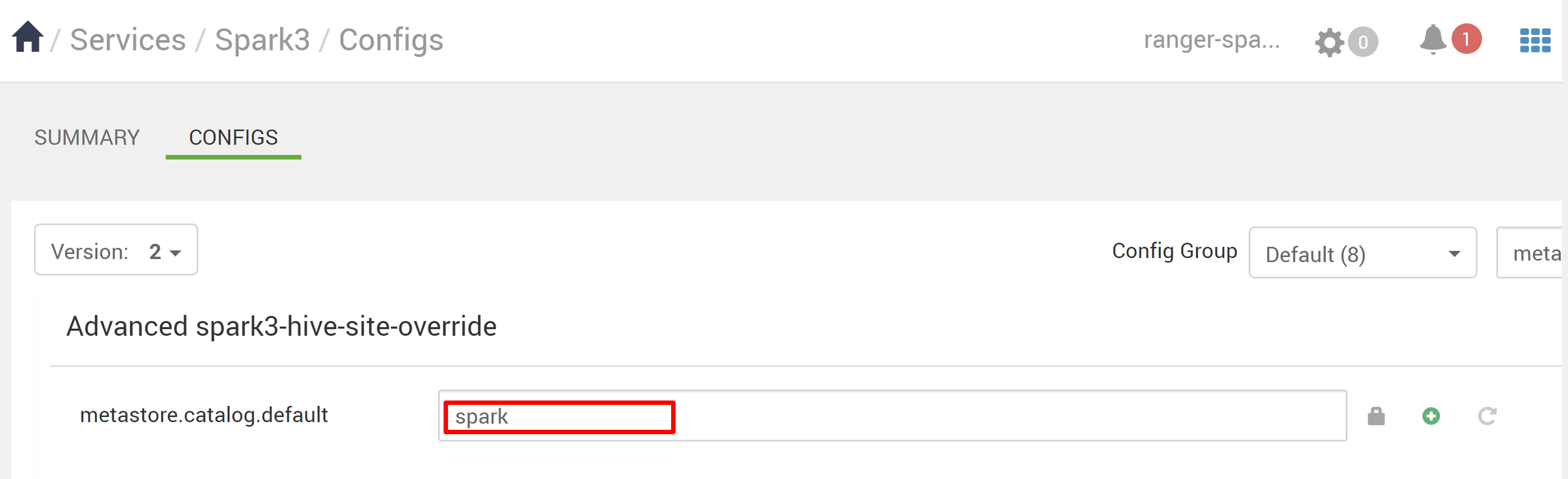
İlkeler Spark kataloğundaki veritabanlarına uygulanır. Hive kataloğundaki veritabanlarına erişmek istiyorsanız:
Ambari'de Spark3>Yapılandırmaları'na gidin.
metastore.catalog.default dosyasını spark'tan hive'a değiştirin.

Bilinen sorunlar
- Ranger yöneticisi çalışmıyorsa Spark SQL ile Apache Ranger tümleştirmesi çalışmaz.
- Ranger denetim günlüklerinde Kaynak sütununun üzerine geldiğinizde çalıştırdığınız sorgunun tamamını gösteremez.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin