Öğretici: Azure Machine Learning ve IoT Edge kullanan uçtan uca bir çözüm
Şunlar için geçerlidir: ![]() IoT Edge 1.1
IoT Edge 1.1
Önemli
IoT Edge 1.1 destek sonu tarihi 13 Aralık 2022'ydi. Bu ürünün, hizmetin, teknolojinin veya API’nin nasıl desteklendiği hakkında bilgi edinmek için Microsoft Ürün Yaşam Döngüsü’ne göz atın. IoT Edge'in en son sürümüne güncelleştirme hakkında daha fazla bilgi için bkz . IoT Edge'i güncelleştirme.
IoT uygulamaları genellikle akıllı buluttan ve akıllı kenardan yararlanmak ister. Bu öğreticide, buluttaki IoT cihazlarından toplanan verilerle bir makine öğrenmesi modelini eğitme, bu modeli IoT Edge'e dağıtma ve modeli düzenli aralıklarla bakım ve iyileştirme adımlarında size yol gösteririz.
Not
Bu öğretici kümesindeki kavramlar IoT Edge'in tüm sürümleri için geçerlidir, ancak senaryoyu denemek için oluşturduğunuz örnek cihaz IoT Edge sürüm 1.1'i çalıştırır.
Bu öğreticinin birincil amacı, ioT verilerinin makine öğrenmesi ile işlenmesini özellikle uçta tanıtmaktır. Genel bir makine öğrenmesi iş akışının birçok yönüne değinsek de bu öğretici, makine öğrenmesine ayrıntılı bir giriş olarak tasarlanmamıştır. Bu noktada kullanım örneği için yüksek oranda iyileştirilmiş bir model oluşturmaya çalışmıyoruz. IoT veri işleme için uygun bir model oluşturma ve kullanma sürecini göstermek için yeterli çabayı gösteririz.
Öğreticinin bu bölümünde şu konular ele alınmaktadır:
- Öğreticinin sonraki bölümlerini tamamlamak için önkoşullar.
- Öğreticinin hedef kitlesi.
- Öğreticinin benzetimini yapılan kullanım örneği.
- Kullanım örneğini yerine getirmek için öğreticinin izlediği genel süreç.
Azure aboneliğiniz yoksa başlamadan önce birücretsiz Azure hesabı oluşturun.
Önkoşullar
Öğreticiyi tamamlamak için kaynak oluşturma haklarına sahip olduğunuz bir Azure aboneliğine erişmeniz gerekir. Bu öğreticide kullanılan hizmetlerden birkaçı Için Azure ücretleri uygulanır. Henüz bir Azure aboneliğiniz yoksa Ücretsiz Azure Hesabı kullanmaya başlayabilirsiniz.
Geliştirme makineniz olarak bir Azure Sanal Makinesi ayarlamak için betikleri çalıştırabileceğiniz PowerShell yüklü bir makineye de ihtiyacınız vardır.
Bu belgede aşağıdaki araç kümesini kullanacağız:
Veri yakalama için Azure IoT hub'ı
Veri hazırlama ve makine öğrenmesi denemeleri için ana ön uç olarak Azure Notebooks. Örnek verilerin bir alt kümesindeki bir not defterinde Python kodu çalıştırmak, veri hazırlama sırasında hızlı yinelemeli ve etkileşimli bir dönüş elde etmenin harika bir yoludur. Jupyter not defterleri, betikleri bir işlem arka uçta büyük ölçekte çalışacak şekilde hazırlamak için de kullanılabilir.
Büyük ölçekte makine öğrenmesi ve makine öğrenmesi görüntü oluşturma için arka uç olarak Azure Machine Learning. Jupyter not defterlerinde hazırlanmış ve test edilmiş betikleri kullanarak Azure Machine Learning arka ucuna yönlendiriyoruz.
Makine öğrenmesi görüntüsünün bulut dışı uygulaması için Azure IoT Edge
Açıkçası, başka seçenekler de var. Örneğin bazı senaryolarda IoT Central, IoT cihazlarından ilk eğitim verilerini yakalamak için kod içermeyen bir alternatif olarak kullanılabilir.
Hedef kitle ve roller
Bu makale kümesi, IoT geliştirme veya makine öğrenmesi konusunda daha önce deneyime sahip olmayan geliştiricilere yöneliktir. Uçta makine öğrenmesi dağıtmak için çok çeşitli teknolojilerin nasıl bağlanılacağı hakkında bilgi sahibi olmak gerekir. Bu nedenle, bu öğreticide bir IoT çözümü için bu teknolojileri birleştirmenin bir yolunu gösteren uçtan uca senaryonun tamamı ele alınır. Gerçek dünyadaki bir ortamda, bu görevler farklı uzmanlıklara sahip birkaç kişi arasında dağıtılabilir. Örneğin geliştiriciler cihaz veya bulut koduna odaklanırken, veri bilimcileri analiz modellerini tasarlar. Tek bir geliştiricinin bu öğreticiyi başarıyla tamamlayabilmesi için içgörüler ve yapılanları ve neden yapıldığını anlamak için yeterli olduğunu umdığımız daha fazla bilgi içeren bağlantılar içeren ek yönergeler sağladık.
Alternatif olarak, öğreticiyi birlikte takip etmek için farklı rollere sahip iş arkadaşlarınızla işbirliği yapabilir, tüm uzmanlığınızı benimseyebilir ve işlerin nasıl bir araya getireceğini bir ekip olarak öğrenebilirsiniz.
Her iki durumda da okuyucuları yönlendirmeye yardımcı olmak için bu öğreticideki her makale kullanıcının rolünü gösterir. Bu roller şunlardır:
- Bulut geliştirme (DevOps kapasitesinde çalışan bir bulut geliştirici dahil)
- Veri analizi
Kullanım örneği: Tahmine dayalı bakım
Bu senaryoyu 2008'de Prognostics and Health Management Konferansı'nda (PHM08) sunulan bir kullanım örneğine dayandırdık. Amaç, bir dizi turbofan uçak motorunun kalan yararlı ömrünü (RUL) tahmin etmektir. Bu veriler MAPSS (Modüler Aero-Propulsion System Simulation) yazılımının ticari sürümü olan C-MAPSS kullanılarak oluşturulmuştur. Bu yazılım, sistem durumu, kontrol ve motor parametrelerini rahatça simüle etmek için esnek bir turbofan motor simülasyon ortamı sağlar.
Bu öğreticide kullanılan veriler Turbofan altyapısı düşüş simülasyonu veri kümesinden alınır.
Benioku dosyasından:
Deneysel Senaryo
Veri kümeleri birden çok değişkenli zaman serisinden oluşur. Her veri kümesi eğitim ve test alt kümelerine daha da ayrılır. Seriler her zaman farklı bir altyapıdandır; örneğin, veriler aynı türde bir motor filosundan olduğu düşünülebilir. Her motor, kullanıcı tarafından bilinmeyen farklı başlangıç yıpranma ve üretim varyasyonu dereceleriyle başlar. Bu yıpranma ve değişim normal kabul edilir, yani hata durumu olarak kabul edilmez. Altyapı performansı üzerinde önemli bir etkiye sahip olan üç işlem ayarı vardır. Bu ayarlar da verilere dahil edilir. Veriler sensör gürültüsüyle kirlenmiş.
Altyapı her zaman serisinin başında normal şekilde çalışır ve seri sırasında bir noktada hata geliştirir. Eğitim kümesinde hata, sistem hatasına kadar büyük bir büyüme gösterir. Test kümesinde, zaman serisi sistem hatasından bir süre önce sona erer. Rekabetin amacı, test kümesindeki arızadan önce kalan operasyonel döngülerin sayısını tahmin etmek, yani motorun çalışmaya devam edeceği son döngüden sonraki operasyonel döngülerin sayısını tahmin etmektir. Ayrıca test verileri için true Remaining Useful Life (RUL) değerlerini içeren bir vektör sağladı.
Veriler bir yarışma için yayımlandığından, makine öğrenmesi modellerini türetmeye yönelik çeşitli yaklaşımlar bağımsız olarak yayımlanmıştır. Örneklerin incelenmesinin, belirli bir makine öğrenmesi modelinin oluşturulmasında yer alan süreci ve mantığı anlamada yararlı olduğunu bulduk. Örneğin bkz:
GitHub kullanıcısı jancervenka tarafından uçak motoru arıza tahmin modeli .
GitHub kullanıcısı hankroark tarafından turbofan altyapısının bozulması .
İşlem
Aşağıdaki resimde bu öğreticide izlediğimiz kaba adımlar gösterilmektedir:
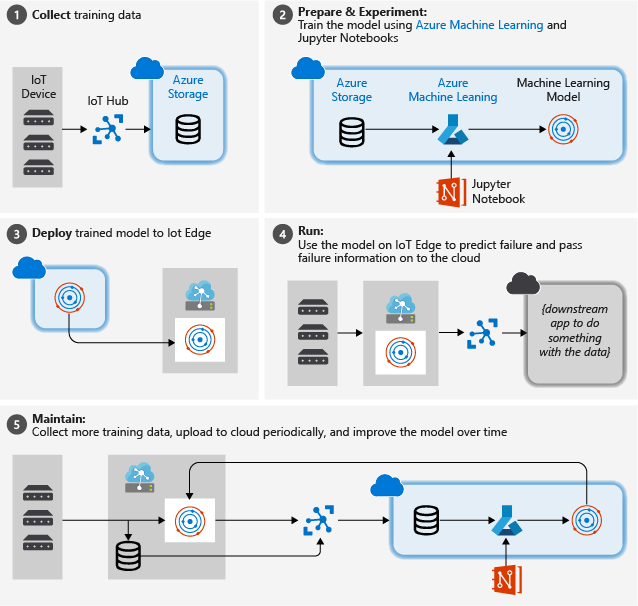
Eğitim verilerini toplama: süreç, eğitim verilerini toplayarak başlar. Bazı durumlarda veriler zaten toplanmıştır ve bir veritabanında veya veri dosyaları biçiminde kullanılabilir. Diğer durumlarda, özellikle IoT senaryolarında verilerin IoT cihazlarından ve algılayıcılarından toplanması ve bulutta depolanması gerekir.
Bir turbofan motor koleksiyonunuz olmadığını varsayıyoruz, bu nedenle proje dosyaları NASA cihaz verilerini buluta gönderen basit bir cihaz simülatörü içeriyor.
Verileri hazırlayın. Çoğu durumda, cihazlardan ve algılayıcılardan toplanan ham veriler makine öğrenmesi için hazırlık gerektirir. Bu adım, makine öğrenmesi tarafından anahtarlanabilir ek bilgiler eklemek için veri temizlemeyi, verileri yeniden biçimlendirmeyi veya ön işlemeyi içerebilir.
Uçak motoru makine verilerimiz için veri hazırlama işlemi, verilerdeki gerçek gözlemlere göre örnekteki her veri noktası için açık hata zamanı sürelerinin hesaplanmasıdır. Bu bilgiler, makine öğrenmesi algoritmasının gerçek algılayıcı veri desenleri ile motorun beklenen kalan yaşam süresi arasındaki bağıntıları bulmasını sağlar. Bu adım, etki alanına son derece özeldir.
Makine öğrenmesi modeli oluşturma. Hazırlanan verilere dayanarak artık modelleri eğitmek ve sonuçları birbiriyle karşılaştırmak için farklı makine öğrenmesi algoritmaları ve parametreleştirmeleri deneyebiliriz.
Bu durumda test için model tarafından hesaplanan tahmini sonucu bir dizi motorda gözlemlenen gerçek sonuçla karşılaştırıyoruz. Azure Machine Learning'de, model kayıt defterinde oluşturduğumuz farklı model yinelemelerini yönetebiliriz.
Modeli dağıtın. Başarı ölçütlerimizi karşılayan bir modele sahip olduktan sonra dağıtıma geçebiliriz. Bu, modeli REST çağrıları kullanılarak verilerle besleyebileceğiniz bir web hizmeti uygulamasına sarmalama ve analiz sonuçlarını döndürmeyi içerir. Web hizmeti uygulaması daha sonra bir docker kapsayıcısında paketlenmiş olur ve bu kapsayıcı buluta veya IoT Edge modülü olarak dağıtılabilir. Bu örnekte IoT Edge'e dağıtıma odaklanacağız.
Modeli koruyun ve geliştirin. Model dağıtıldıktan sonra işimiz yapılmaz. Çoğu durumda veri toplamaya devam etmek ve bu verileri düzenli aralıklarla buluta yüklemek istiyoruz. Daha sonra modelimizi yeniden eğitmek ve iyileştirmek için bu verileri kullanabiliriz ve bu verileri IoT Edge'e yeniden dağıtabiliriz.
Kaynakları temizleme
Bu öğretici, her makalenin öncekilerde yapılan işlere göre derlendiği bir kümenin parçasıdır. Son öğreticiyi tamamlayana kadar lütfen tüm kaynakları temizlemeyi bekleyin.
Sonraki adımlar
Bu öğretici aşağıdaki bölümlere ayrılmıştır:
- Geliştirme makinenizi ve Azure hizmetlerinizi ayarlayın.
- Makine öğrenmesi modülü için eğitim verilerini oluşturun.
- Makine öğrenmesi modülünü eğitin ve dağıtın.
- Bir IoT Edge cihazını saydam ağ geçidi olarak davranacak şekilde yapılandırın.
- IoT Edge modülleri oluşturun ve dağıtın.
- IoT Edge cihazınıza veri gönderin.
Geliştirme makinesi ayarlamak ve Azure kaynaklarını sağlamak için sonraki makaleye geçin.