Veri bileşenini normalleştirme
Bu makalede Azure Machine Learning tasarımcısındaki bir bileşen açıklanmaktadır.
Bir veri kümesini normalleştirme yoluyla dönüştürmek için bu bileşeni kullanın.
Normalleştirme genellikle makine öğrenmesi için veri hazırlamanın bir parçası olarak uygulanan bir tekniktir. Normalleştirmenin amacı, veri kümesindeki sayısal sütunların değerlerini, değer aralıklarındaki farkları bozmadan veya bilgileri kaybetmeden ortak bir ölçek kullanacak şekilde değiştirmektir. Bazı algoritmaların verileri doğru modellemesi için de normalleştirme gerekir.
Örneğin, giriş veri kümenizin 0 ile 1 arasında değerler içeren bir sütun ve 10.000 ile 100.000 arasında değerler içeren başka bir sütun içerdiğini varsayalım. Sayıların ölçeğindeki büyük fark, modelleme sırasında değerleri özellik olarak birleştirmeye çalıştığınızda sorunlara neden olabilir.
Normalleştirme , kaynak verilerdeki genel dağılımı ve oranları koruyan yeni değerler oluştururken, değerleri modelde kullanılan tüm sayısal sütunlara uygulanan bir ölçek içinde tutarak bu sorunları önler.
Bu bileşen, sayısal verileri dönüştürmek için çeşitli seçenekler sunar:
- Tüm değerleri 0-1 ölçeğine değiştirebilir veya değerleri mutlak değerler yerine yüzdebirlik dereceler olarak temsil ederek dönüştürebilirsiniz.
- Normalleştirmeyi tek bir sütuna veya aynı veri kümesindeki birden çok sütuna uygulayabilirsiniz.
- İşlem hattını yinelemeniz veya diğer verilere aynı normalleştirme adımlarını uygulamanız gerekiyorsa, adımları normalleştirme dönüşümü olarak kaydedebilir ve aynı şemaya sahip diğer veri kümelerine uygulayabilirsiniz.
Uyarı
Bazı algoritmalar, modeli eğitmeden önce verilerin normalleştirilmesini gerektirir. Diğer algoritmalar kendi veri ölçeklendirme veya normalleştirme işlemlerini gerçekleştirir. Bu nedenle, tahmine dayalı model oluştururken kullanmak üzere bir makine öğrenmesi algoritması seçtiğinizde, eğitim verilerine normalleştirme uygulamadan önce algoritmanın veri gereksinimlerini gözden geçirmeyi unutmayın.
Verileri Normalleştirmeyi Yapılandırma
Bu bileşeni kullanarak aynı anda yalnızca bir normalleştirme yöntemi uygulayabilirsiniz. Bu nedenle, seçtiğiniz tüm sütunlara aynı normalleştirme yöntemi uygulanır. Farklı normalleştirme yöntemleri kullanmak için Verileri Normalleştirme'nin ikinci bir örneğini kullanın.
Verileri Normalleştir bileşenini işlem hattınıza ekleyin. Bileşeni Azure Machine Learning'de , Veri Dönüştürme'nin altında Ölçek ve Azaltma kategorisinde bulabilirsiniz.
Tüm sayılardan en az bir sütun içeren bir veri kümesini bağlayın.
Normalleştirileceği sayısal sütunları seçmek için Sütun Seçici'yi kullanın. Tek tek sütunları seçmezseniz, varsayılan olarak girişteki tüm sayısal tür sütunları dahil edilir ve aynı normalleştirme işlemi seçilen tüm sütunlara uygulanır.
Normalleştirilmemesi gereken sayısal sütunlar eklerseniz bu garip sonuçlara yol açabilir! Sütunları her zaman dikkatli bir şekilde denetleyin.
Hiçbir sayısal sütun algılanırsa, sütunun veri türünün desteklenen bir sayısal tür olduğunu doğrulamak için sütun meta verilerini denetleyin.
İpucu
Belirli bir türdeki sütunların giriş olarak sağlandığından emin olmak için Verileri Normalleştirmeden önce Veri Kümesindeki Sütunları Seçin bileşenini kullanmayı deneyin.
İşaretlendiğinde sabit sütunlar için 0 kullanın: Herhangi bir sayısal sütun tek bir değişmeyen değer içerdiğinde bu seçeneği belirleyin. Bu, bu tür sütunların normalleştirme işlemlerinde kullanılmamasını sağlar.
Dönüştürme yöntemi açılan listesinden, tüm seçili sütunlara uygulanacak tek bir matematik işlevi seçin.
Zscore: Tüm değerleri z puanına dönüştürür.
Sütundaki değerler aşağıdaki formül kullanılarak dönüştürülür:
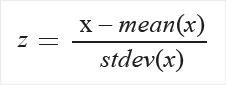
Ortalama ve standart sapma her sütun için ayrı ayrı hesaplanır. Popülasyon standart sapması kullanılır.
MinMax: Min-max normalizer her özelliği doğrusal olarak [0,1] aralığına göre yeniden ölçekler.
[0,1] aralığına yeniden ölçeklendirme, her özelliğin değerleri en düşük değer 0 olacak şekilde kaydırılarak ve ardından yeni en büyük değere (özgün en büyük ve en düşük değerler arasındaki fark) bölünerek gerçekleştirilir.
Sütundaki değerler aşağıdaki formül kullanılarak dönüştürülür:

Lojistik: Sütundaki değerler aşağıdaki formül kullanılarak dönüştürülür:
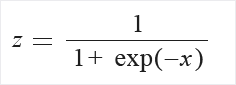
LogNormal: Bu seçenek tüm değerleri logaritmik normal ölçeğe dönüştürür.
Sütundaki değerler aşağıdaki formül kullanılarak dönüştürülür:

Burada μ ve σ, her sütun için ayrı ayrı tahmin edilen maksimum olasılık tahmini olarak verilerden ampirik olarak hesaplanan dağılımın parametreleridir.
TanH: Tüm değerler hiperbolik tanjanta dönüştürülür.
Sütundaki değerler aşağıdaki formül kullanılarak dönüştürülür:

İşlem hattını gönderin veya Verileri Normalleştir bileşenine çift tıklayıp Seçili Çalıştır'ı seçin.
Sonuçlar
Verileri Normalleştir bileşeni iki çıkış oluşturur:
Dönüştürülmüş değerleri görüntülemek için bileşene sağ tıklayın ve Görselleştir'i seçin.
Varsayılan olarak, değerler yerinde dönüştürülür. Dönüştürülen değerleri özgün değerlerle karşılaştırmak istiyorsanız, veri kümelerini yeniden birleştirip sütunları yan yana görüntülemek için Sütun Ekle bileşenini kullanın.
Aynı normalleştirme yöntemini başka bir veri kümesine uygulayabilmek için dönüştürmeyi kaydetmek için bileşeni seçin ve sağ paneldeki Çıkışlar sekmesinin altından Veri kümesini kaydet'i seçin.
Ardından sol gezinti bölmesinin Dönüşümler grubundan kaydedilen dönüştürmeleri yükleyebilir ve DönüştürmeYi Uygula'yı kullanarak aynı şemaya sahip bir veri kümesine uygulayabilirsiniz.
Sonraki adımlar
Azure Machine Learning'in kullanabileceği bileşenler kümesine bakın.