Python ile zaman serisi tahmin modelini eğitmek için AutoML'yi ayarlama (SDKv1)
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu makalede, Azure Machine Learning Python SDK'sında Azure Machine Learning otomatik ML ile zaman serisi tahmin modelleri için AutoML eğitimini ayarlamayı öğreneceksiniz.
Bunun için şunları yapın:
- Zaman serisi modellemesi için verileri hazırlama.
- Bir
AutoMLConfignesnede belirli zaman serisi parametrelerini yapılandırın. - Zaman serisi verileriyle tahminleri çalıştırma.
Düşük kod deneyimi için öğretici: Azure Machine Learning stüdyosu otomatik ML kullanarak zaman serisi tahmin örneği için otomatik makine öğrenmesi ile talebi tahmin etme bölümüne bakın.
Klasik zaman serisi yöntemlerinden farklı olarak, otomatik ML'de geçmiş zaman serisi değerleri diğer tahmincilerle birlikte regresör için ek boyutlar haline gelecek şekilde "özetlenir". Bu yaklaşım, eğitim sırasında birden çok bağlamsal değişkeni ve bunların birbiriyle ilişkisini içerir. Birden çok faktör bir tahmini etkileyebileceğinden, bu yöntem gerçek dünya tahmin senaryolarıyla kendini iyi hizalar. Örneğin, satış tahmini yaparken geçmiş eğilimlerin, döviz kurunun ve fiyatın etkileşimleri, satış sonucunu birlikte yönlendirir.
Önkoşullar
Bu makale için,
Azure Machine Learning çalışma alanı. Çalışma alanını oluşturmak için bkz . Çalışma alanı kaynakları oluşturma.
Bu makalede, otomatik makine öğrenmesi denemesi ayarlama konusunda biraz bilgi sahibi olduğunuz varsayılır. Ana otomatik makine öğrenmesi denemesi tasarım desenlerini görmek için nasıl yapılır adımlarını izleyin.
Önemli
Bu makaledeki Python komutları en son
azureml-train-automlpaket sürümünü gerektirir.- En son
azureml-train-automlpaketi yerel ortamınıza yükleyin. - En son
azureml-train-automlpaketle ilgili ayrıntılar için sürüm notlarına bakın.
- En son
Eğitim ve doğrulama verileri
Tahmin regresyon görev türü ile otomatik ML içindeki regresyon görev türü arasındaki en önemli fark, eğitim verilerinize geçerli bir zaman serisini temsil eden bir özellik dahil edilmesidir. Normal zaman serisinin iyi tanımlanmış ve tutarlı bir sıklığı vardır ve sürekli bir zaman aralığındaki her örnek noktada bir değere sahiptir.
Önemli
Gelecekteki değerleri tahmin etme modeli eğitirken, hedeflenen ufukta tahminleri çalıştırırken eğitimde kullanılan tüm özelliklerin kullanılabildiğinden emin olun. Örneğin, mevcut hisse senedi fiyatına yönelik bir özellik de dahil olmak üzere bir talep tahmini oluştururken eğitim doğruluğunu büyük ölçüde artırabilir. Bununla birlikte, uzun bir ufukla tahminde bulunabilmek istiyorsanız, gelecekteki zaman serisi noktalarına karşılık gelen gelecekteki hisse senedi değerlerini doğru tahmin edemeyebilirsiniz ve model doğruluğu zarar görebilir.
Ayrı eğitim verileri ve doğrulama verilerini doğrudan nesnesinde AutoMLConfig belirtebilirsiniz. AutoMLConfig hakkında daha fazla bilgi edinin.
Zaman serisi tahminleri için, varsayılan olarak doğrulama için yalnızca Sıralı Çıkış Noktası Çapraz Doğrulama (ROCV) kullanılır. ROCV, bir kaynak zaman noktası kullanarak seriyi eğitim ve doğrulama verilerine böler. Kaynağın zaman içinde kaydırlanması çapraz doğrulama katlamalarını oluşturur. Bu strateji zaman serisi veri bütünlüğünü korur ve veri sızıntısı riskini ortadan kaldırır.
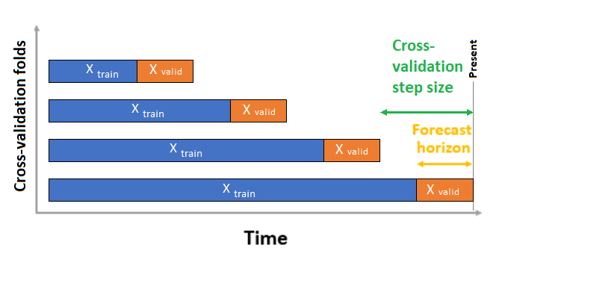
parametresine training_dataeğitim ve doğrulama verilerinizi tek bir veri kümesi olarak geçirin. parametresiyle n_cross_validations çapraz doğrulama katlamalarının sayısını ayarlayın ve ile cv_step_sizeardışık iki çapraz doğrulama katlamaları arasındaki dönem sayısını ayarlayın. Ayrıca ya da her iki parametreyi de boş bırakabilirsiniz ve AutoML bunları otomatik olarak ayarlar.
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Ayrıca kendi doğrulama verilerinizi getirebilir, AutoML'de veri bölmelerini ve çapraz doğrulamayı yapılandırma bölümünde daha fazla bilgi edinebilirsiniz.
AutoML'nin fazla sığdırmayı önlemek için çapraz doğrulamayı nasıl uyguladığı hakkında daha fazla bilgi edinin.
Denemeyi yapılandırma
nesnesi, AutoMLConfig otomatik makine öğrenmesi görevi için gerekli ayarları ve verileri tanımlar. Tahmin modelinin yapılandırması, standart regresyon modelinin kurulumuna benzer, ancak belirli modeller, yapılandırma seçenekleri ve özellik geliştirme adımları özellikle zaman serisi verileri için mevcuttur.
Desteklenen modeller
Otomatik makine öğrenmesi, model oluşturma ve ayarlama işleminin bir parçası olarak farklı modelleri ve algoritmaları otomatik olarak dener. Kullanıcı olarak algoritmayı belirtmenize gerek yoktur. Tahmin denemeleri için hem yerel zaman serisi hem de derin öğrenme modelleri öneri sisteminin bir parçasıdır.
İpucu
Geleneksel regresyon modelleri, deneme tahmini için öneri sisteminin bir parçası olarak da test edilir. SDK başvuru belgelerinde desteklenen modellerin tam listesine bakın.
Yapılandırma ayarları
Regresyon sorununa benzer şekilde, görev türü, yineleme sayısı, eğitim verileri ve çapraz doğrulama sayısı gibi standart eğitim parametrelerini tanımlarsınız. Tahmin görevleri, denemenizi yapılandırmak için ve forecast_horizon parametrelerini gerektirirtime_column_name. Veriler birden çok mağaza için satış verileri veya farklı eyaletlerdeki enerji verileri gibi birden çok zaman serisi içeriyorsa, otomatik ML bunu otomatik olarak algılar ve parametreyi time_series_id_column_names (önizleme) sizin için ayarlar. Çalıştırmanızı daha iyi yapılandırmak için ek parametreler de ekleyebilirsiniz. Ekleyebileceğiniz özellikler hakkında daha fazla ayrıntı için isteğe bağlı yapılandırmalar bölümüne bakın.
Önemli
Otomatik zaman serisi tanımlama şu anda genel önizleme aşamasındadır. Bu önizleme sürümü hizmet düzeyi sözleşmesi olmadan sağlanır. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
| Parametre adı | Açıklama |
|---|---|
time_column_name |
Zaman serisini oluşturmak ve sıklığını çıkarsamak için kullanılan giriş verilerinde datetime sütununu belirtmek için kullanılır. |
forecast_horizon |
Tahmin etmek istediğiniz ileriye dönük dönem sayısını tanımlar. Ufuk, zaman serisi sıklığının birimlerindedir. Birimler, eğitim verilerinizin zaman aralığına (örneğin, tahminde bulunanın tahmin etmesi gereken aylık, haftalık) dayanır. |
Aşağıdaki kod,
ForecastingParametersDeneme eğitiminiz için tahmin parametrelerini tanımlamak için sınıfını kullanırtime_column_namedeğerini veri kümesindekiday_datetimealana ayarlar.forecast_horizonTüm test kümesini tahmin etmek için değerini 50 olarak ayarlar.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Bunlar forecasting_parameters daha sonra görev türü, birincil ölçüm, çıkış ölçütleri ve eğitim verileriyle forecasting birlikte standart AutoMLConfig nesnenize geçirilir.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Otomatik ML ile bir tahmin modelini başarılı bir şekilde eğitmek için gereken veri miktarı, öğesini AutoMLConfigyapılandırırken belirtilen , n_cross_validationsve target_lags veya target_rolling_window_size değerlerinden etkilenirforecast_horizon.
Aşağıdaki formül, zaman serisi özelliklerini oluşturmak için gereken geçmiş veri miktarını hesaplar.
Gereken en düşük geçmiş verileri: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Error exception belirtilen ilgili ayarlar için gerekli geçmiş veri miktarını karşılamayan veri kümesindeki herhangi bir seri için oluşturulur.
Özellik geliştirme adımları
Her otomatik makine öğrenmesi denemesinde, verilerinize varsayılan olarak otomatik ölçeklendirme ve normalleştirme teknikleri uygulanır. Bu teknikler, farklı ölçeklerdeki özelliklere duyarlı olan belirli algoritmalara yardımcı olan özellik geliştirme türleridir. AutoML'de Özellik Kazandırma'da varsayılan özellik geliştirme adımları hakkında daha fazla bilgi edinin
Ancak, aşağıdaki adımlar yalnızca görev türleri için forecasting gerçekleştirilir:
- Zaman serisi örnek sıklığını (örneğin saatlik, günlük, haftalık) algılayın ve devamsızlık zaman noktaları için yeni kayıtlar oluşturarak seriyi sürekli hale getirin.
- Hedefteki eksik değerleri açma/kapatma (ileriye doğru doldurma yoluyla) ve özellik sütunları (ortanca sütun değerleri kullanılarak)
- Farklı serilerde sabit efektleri etkinleştirmek için zaman serisi tanımlayıcılarını temel alan özellikler oluşturma
- Mevsimsel desenleri öğrenmeye yardımcı olmak için zamana dayalı özellikler oluşturma
- Kategorik değişkenleri sayısal miktarlara kodlama
- Birim köklerinin etkisini azaltmak için, nonstationary zaman serisini algılayın ve bunları otomatik olarak farklandırın.
Zaman serisi verilerinden oluşturulan olası mühendislik özelliklerinin tam listesini görüntülemek için bkz . TimeIndexFeaturizer Sınıfı.
Not
Otomatik makine öğrenmesi özellik geliştirme adımları (özellik normalleştirme, eksik verileri işleme, metni sayısala dönüştürme vb.) temel alınan modelin bir parçası haline gelir. Modeli tahminler için kullanırken, eğitim sırasında uygulanan özellik geliştirme adımları giriş verilerinize otomatik olarak uygulanır.
Özellik geliştirmeyi özelleştirme
Ayrıca, ML modelinizi eğitmek için kullanılan verilerin ve özelliklerin ilgili tahminlere neden olduğundan emin olmak için özellik özellikleri ayarlarınızı özelleştirme seçeneğiniz de vardır.
Görevler için forecasting desteklenen özelleştirmeler şunlardır:
| Özelleştirme | Tanım |
|---|---|
| Sütun amaçlı güncelleştirme | Belirtilen sütun için otomatik algılanan özellik türünü geçersiz kılın. |
| Transformer parametre güncelleştirmesi | Belirtilen transformatörün parametrelerini güncelleştirin. Şu anda Imputer (fill_value ve ortanca) desteklemektedir. |
| Sütunları bırakma | Öne çıkarılmaktan kaldırılan sütunları belirtir. |
SDK ile özellik geliştirmelerini özelleştirmek için nesnenizde AutoMLConfig belirtin"featurization": FeaturizationConfig. Özel özellik geliştirmeleri hakkında daha fazla bilgi edinin.
Not
Bırakma sütunları işlevselliği SDK sürüm 1.19 itibariyle kullanım dışıdır. Otomatik ML denemenizde kullanmadan önce veri kümenizden veri temizlemenin bir parçası olarak sütunları bırakın.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Denemeniz için Azure Machine Learning stüdyosu kullanıyorsanız stüdyoda özellik geliştirmeyi özelleştirme bölümüne bakın.
İsteğe bağlı yapılandırmalar
Derin öğrenmeyi etkinleştirme ve hedef sıralı pencere toplamayı belirtme gibi tahmin görevleri için daha fazla isteğe bağlı yapılandırma sağlanır. ForecastingParameters SDK başvuru belgelerinde daha fazla parametrenin tam listesi sağlanır.
Sıklık ve hedef veri toplama
Düzensiz verilerin neden olduğu hataları önlemeye yardımcı olmak için frequency, freq, parametresini kullanın. Düzensiz veriler, saatlik veya günlük veriler gibi belirli bir tempoya uymayan verileri içerir.
Son derece düzensiz veriler veya değişen iş gereksinimleri için kullanıcılar isteğe bağlı olarak istedikleri tahmin sıklığını freqayarlayabilir ve zaman serisinin hedef sütununu toplamak için öğesini belirtebilir target_aggregation_function . Nesnenizde bu iki ayarı kullanmak, veri hazırlamada biraz zaman kazanmanıza AutoMLConfig yardımcı olabilir.
Hedef sütun değerleri için desteklenen toplama işlemleri şunlardır:
| İşlev | Açıklama |
|---|---|
sum |
Hedef değerlerin toplamı |
mean |
Hedef değerlerin ortalaması veya ortalaması |
min |
Hedefin en düşük değeri |
max |
Hedefin en büyük değeri |
Derin öğrenmeyi etkinleştirme
Not
Otomatik Makine Öğrenmesi'nde tahmin için DNN desteği önizleme aşamasındadır ve Databricks'te başlatılan yerel çalıştırmalar veya çalıştırmalar için desteklenmez.
Ayrıca modelinizin puanlarını geliştirmek için derin sinir ağları ve DNN'ler ile derin öğrenme uygulayabilirsiniz. Otomatik ML'nin derin öğrenmesi, tek değişkenli ve çok değişkenli zaman serisi verilerinin tahmin edilmesini sağlar.
Derin öğrenme modellerinin üç iç özelliği vardır:
- Girişlerden çıkışlara rastgele eşlemelerden öğrenebilirler
- Birden çok girişi ve çıkışı destekler
- Giriş verilerinde uzun dizilere yayılan desenleri otomatik olarak ayıklayabilirler.
Derin öğrenmeyi etkinleştirmek için nesnesini ayarlayın enable_dnn=True AutoMLConfig .
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Uyarı
SDK ile oluşturulan denemeler için DNN'yi etkinleştirdiğinizde, en iyi model açıklamaları devre dışı bırakılır.
Azure Machine Learning stüdyosu oluşturulan bir AutoML denemesi için DNN'yi etkinleştirmek için, studio kullanıcı arabirimindeki görev türü ayarlarına bakın.
Hedef sıralı pencere toplama
Tahmin aracı için en iyi bilgiler genellikle hedefin en son değeridir. Hedef sıralı pencere toplamaları, veri değerlerinin sıralı toplamasını özellik olarak eklemenize olanak tanır. Bu özelliklerin ek bağlamsal veriler olarak oluşturulması ve kullanılması, tren modelinin doğruluğuna yardımcı olur.
Örneğin, enerji talebini tahmin etmek istediğinizi varsayalım. Isıtmalı alanların termal değişikliklerini hesaba katmak için üç günlük bir döner pencere özelliği eklemek isteyebilirsiniz. Bu örnekte, oluşturucuda AutoMLConfig ayar target_rolling_window_size= 3 yaparak bu pencereyi oluşturun.
Tablo, pencere toplama uygulandığında ortaya çıkan özellik mühendisliğini gösterir. Minimum, maksimum ve toplam sütunları, tanımlanan ayarlara göre üç kayan pencerede oluşturulur. Her satırın yeni bir hesaplanan özelliği vardır. 8 Eylül 2017 04:00 için zaman damgası söz konusu olduğunda maksimum, minimum ve toplam değerleri 8 Eylül 2017 01:00 - 03:00 arası talep değerleri kullanılarak hesaplanır. Kalan satırların verilerini doldurmak için üç vardiyalık bu pencere.

Hedef sıralı pencere toplama özelliğini uygulayan bir Python kod örneğini görüntüleyin.
Kısa seri işleme
Otomatik ML, model geliştirmenin tren ve doğrulama aşamalarını yürütmek için yeterli veri noktası yoksa zaman serisini kısa bir seri olarak değerlendirir. Veri noktası sayısı her deneme için farklılık gösterir ve max_horizon, çapraz doğrulama bölme sayısına ve model görünümünün uzunluğuna bağlıdır. Bu, zaman serisi özelliklerini oluşturmak için gereken en yüksek geçmiş sayısıdır.
Otomatik ML, nesnesindeki short_series_handling_configuration ForecastingParameters parametresiyle kısa seri işlemeyi varsayılan olarak sunar.
Kısa seri işlemeyi etkinleştirmek için parametresi de freq tanımlanmalıdır. Saatlik sıklık tanımlamak için ayarını freq='H'yapacağız. Pandas Zaman serisi sayfası DataOffset nesneleri bölümünü ziyaret ederek sıklık dizesi seçeneklerini görüntüleyin. Varsayılan davranışı değiştirmek için nesnenizdeki short_series_handling_configuration = 'auto'ForecastingParameter parametresini güncelleştirinshort_series_handling_configuration.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
Aşağıdaki tabloda için short_series_handling_configkullanılabilir ayarlar özetlemektedir.
| Ayar | Açıklama |
|---|---|
auto |
Kısa seri işleme için varsayılan değer. - Tüm seriler kısaysa, verileri doldurma. - Tüm seriler kısa değilse, kısa seriyi bırakın. |
pad |
ise short_series_handling_config = pad, otomatik ML bulunan her kısa seriye rastgele değerler ekler. Aşağıda sütun türleri ve bunların nelerle dolduruldıkları listelenmiştir: - NaN'leri olan nesne sütunları - 0 içeren sayısal sütunlar - False ile Boole/mantıksal sütunlar - Hedef sütun sıfır ortalaması ve standart sapma değeri 1 olan rastgele değerlerle doldurulur. |
drop |
ise short_series_handling_config = drop, otomatik ML kısa seriyi bırakır ve eğitim veya tahmin için kullanılmaz. Bu seriler için tahminler NaN'leri döndürür. |
None |
Hiçbir seri doldurulmamış veya bırakılmamış |
Uyarı
Doldurma sonucunda elde edilen modelin doğruluğu etkilenebilir, çünkü yapay verileri yalnızca arıza olmadan eğitimden geçmek için kullanıma sunuyoruz. Serilerin birçoğu kısaysa, açıklanabilirlik sonuçlarında da bazı etkiler görebilirsiniz
Nonstationary zaman serisi algılama ve işleme
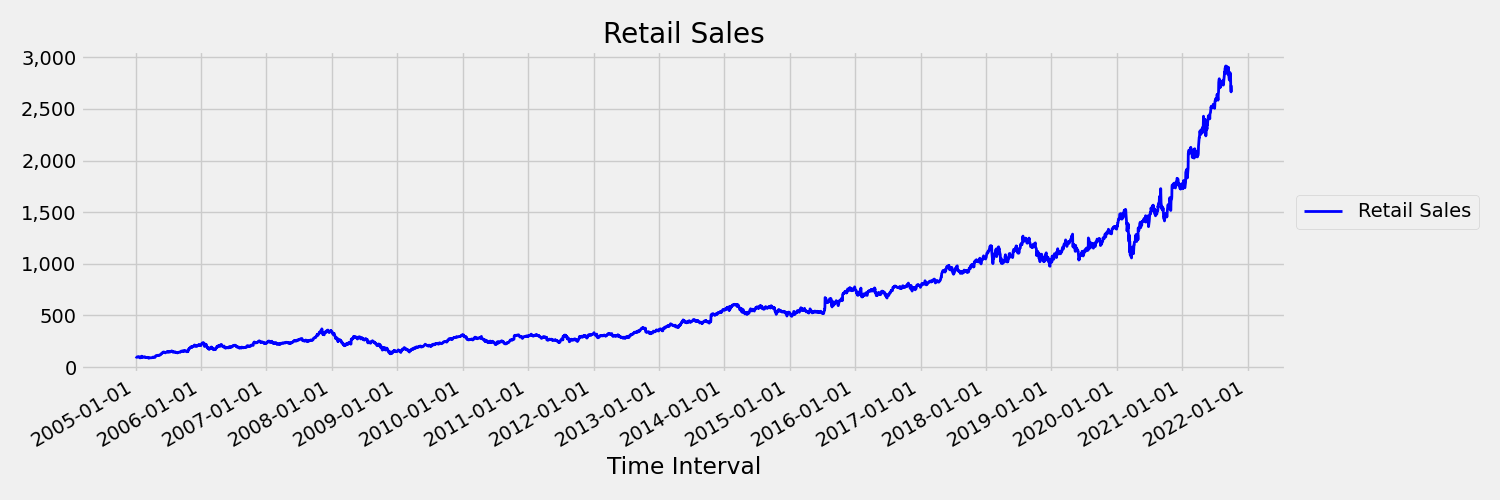
Zaman içinde anları (ortalama ve varyans) değişen bir zaman serisi sabit olmayan olarak adlandırılır. Örneğin, stokastik eğilimler sergileyen zaman serisi doğası gereği sabit değildir. Bunu görselleştirmek için aşağıdaki görüntüde genellikle yukarı doğru eğilim gösteren bir seri çizilir. Şimdi serinin ilk ve ikinci yarısı için ortalama (ortalama) değerleri hesaplayın ve karşılaştırın. Aynı mı? Burada, çizimin ilk yarısındaki serinin ortalaması ikinci yarıya göre daha küçüktür. Serinin ortalamasının, birinin baktığı zaman aralığına bağlı olması, zaman değişen anlara bir örnektir. Burada serinin ortalaması ilk anındır.
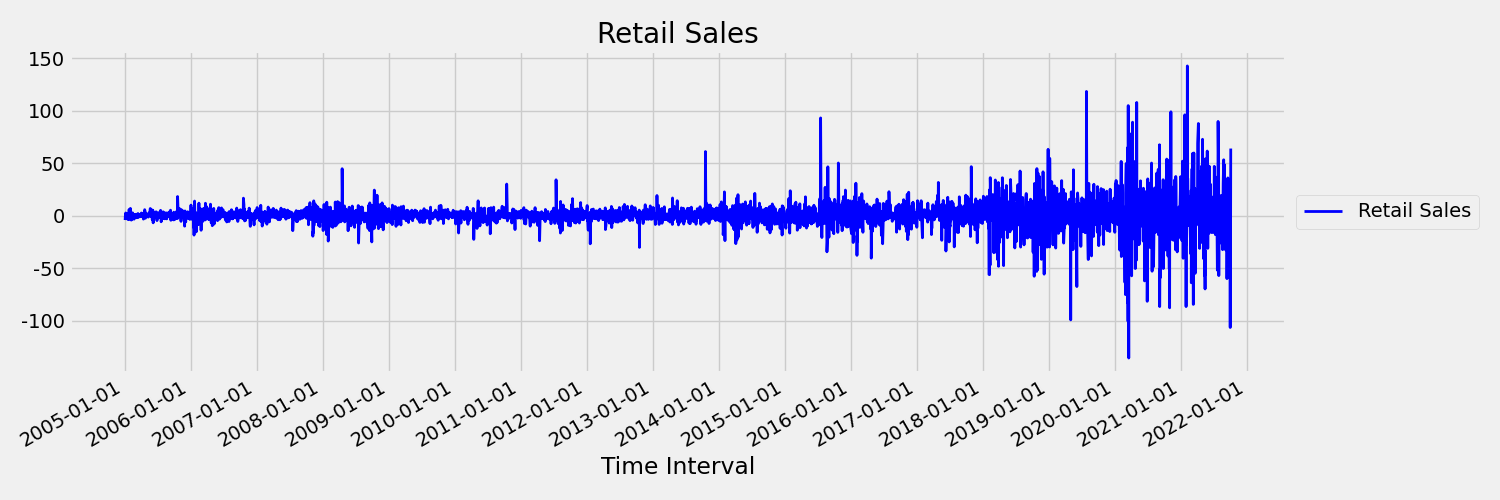
Şimdi özgün seriyi ilk farklarla çizen görüntüyü inceleyelim: $x_t = y_t - y_{t-1}$ burada $x_t$ perakende satışlarındaki değişimdir ve $y_t$ ve $y_{t-1}$ sırasıyla özgün seriyi ve ilk gecikmesini temsil eder. Serinin ortalaması, baktığı zaman diliminden bağımsız olarak kabaca sabittir. Bu, ilk sipariş sabit zaman serisinin bir örneğidir. İlk sipariş terimini ekleme nedenimiz, ilk anın (ortalama) zaman aralığıyla değişmemesidir; aynı şey ikinci bir an olan varyans hakkında söylenemez.
AutoML Machine learning modelleri, stokastik eğilimlerle veya sabit olmayan zaman serisiyle ilişkili diğer iyi bilinen sorunlarla doğal olarak başa çıkamaz. Sonuç olarak, bu eğilimler mevcutsa bunların örnek dışı tahmin doğruluğu "zayıftır".
AutoML, sabit olup olmadığını denetlemek için zaman serisi veri kümesini otomatik olarak analiz eder. Sabit olmayan zaman serisi algılandığında AutoML, sabit olmayan zaman serisinin etkisini azaltmak için otomatik olarak bir fark kayıt dönüşümü uygular.
Denemeyi çalıştırma
Nesneniz AutoMLConfig hazır olduğunda denemeyi gönderebilirsiniz. Model tamamlandıktan sonra en iyi çalıştırma yinelemesini alın.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
En iyi modelle tahmin etme
Modeli eğitmek için kullanılmayan verilerin değerlerini tahmin etmek için en iyi model yinelemesini kullanın.
Sıralı tahminle model doğruluğunu değerlendirme
Bir modeli üretime yerleştirmeden önce, eğitim verilerinden tutulan bir test kümesinde bu modelin doğruluğunu değerlendirmeniz gerekir. En iyi uygulama yordamı, eğitilen tahminciyi test kümesinde zaman içinde ileriye doğru yuvarlayan, seçilen bazı ölçümler için istatistiksel olarak sağlam tahminler elde etmek için hata ölçümlerini çeşitli tahmin pencerelerine ortalamaya alan, sıralı değerlendirmedir. İdeal olan, değerlendirme için test kümesinin modelin tahmin ufkunun uzun olmasıdır. Aksi takdirde tahmin hatası tahminleri istatistiksel olarak gürültülü ve bu nedenle daha az güvenilir olabilir.
Örneğin, gelecekte iki haftaya (14 güne) kadar talebi tahmin etmek için günlük satışlar üzerinde bir model eğitmiş olduğunuzu varsayalım. Yeterli geçmişe dönük veri varsa, test kümesi için verilerin son birkaç ayını bir yıla kadar ayırabilirsiniz. Sıralı değerlendirme, test kümesinin ilk iki haftası için 14 günlük bir tahmin oluşturarak başlar. Ardından, tahmin aracı test kümesine birkaç gün kadar ilerletilir ve yeni konumdan 14 günlük bir tahmin daha oluşturursunuz. Test kümesinin sonuna gelene kadar işlem devam eder.
Sıralı değerlendirme yapmak için yöntemini fitted_modelçağırın rolling_forecast ve ardından sonuç üzerinde istenen ölçümleri hesaplayın. Örneğin, adlı bir pandas DataFrame'de test kümesi özelliklerine ve adlı test_features_df test_targetnumpy dizisinde hedefin gerçek değerlerini ayarladığınızı varsayalım. Ortalama kare hatasını kullanan sıralı değerlendirme aşağıdaki kod örneğinde gösterilmiştir:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
Bu örnekte, sıralı tahmin için adım boyutu bir olarak ayarlanmıştır; bu, tahmin edenin her yinelemede bir dönem veya talep tahmini örneğimizde bir gün gelişmiş olduğu anlamına gelir. Bu nedenle tarafından rolling_forecast döndürülen toplam tahmin sayısı, test kümesinin uzunluğuna ve bu adım boyutuna bağlıdır. Diğer ayrıntılar ve örnekler için rolling_forecast() belgelerine ve Eğitim verilerinden uzakta tahmin etme not defterine bakın.
Geleceğe yönelik tahmin
forecast_quantiles() işlevi, genellikle sınıflandırma ve regresyon görevleri için kullanılan yöntemin predict() aksine tahminlerin ne zaman başlaması gerektiğine ilişkin belirtimlere olanak tanır. forecast_quantiles() yöntemi varsayılan olarak bir nokta tahmini veya etrafında belirsizlik konisi olmayan ortalama/ortanca tahmin oluşturur. Eğitim verilerinden uzakta tahmin etme not defterinde daha fazla bilgi edinin.
Aşağıdaki örnekte, ilk olarak içindeki y_pred tüm değerleri ile NaNdeğiştirirsiniz. Tahmin kaynağı, bu örnekte eğitim verilerinin sonundadır. Ancak, yalnızca ikinci yarısını y_pred ile NaNdeğiştirdiyseniz, işlev ilk yarıdaki sayısal değerleri değiştirilmemiş olarak bırakır, ancak ikinci yarıdaki değerleri tahmin NaN eder. İşlev hem tahmin edilen değerleri hem de hizalanmış özellikleri döndürür.
Belirtilen tarihe forecast_destination kadar olan değerleri tahmin etmek için işlevindeki forecast_quantiles() parametresini de kullanabilirsiniz.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Müşteriler genellikle dağılımın belirli bir nicelindeki tahminleri anlamak ister. Örneğin, bir bulut hizmeti için market ürünleri veya sanal makineler gibi envanteri denetlemek için tahmin kullanıldığında. Bu gibi durumlarda denetim noktası genellikle "öğenin stokta olmasını ve %99 oranında tükenmesini istemiyoruz" gibi bir şeydir. Aşağıda, tahminleriniz için hangi nicel değerlerin (örneğin, 50. veya 95. yüzdebirlik) nasıl belirtileceğini gösterir. Yukarıda belirtilen kod örneğinde olduğu gibi bir nicel belirtmezseniz, yalnızca 50. yüzdebirlik tahminler oluşturulur.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Model performansını tahmin etmeye yardımcı olmak için kök ortalama kare hatası (RMSE) veya ortalama mutlak yüzde hatası (MAPE) gibi model ölçümlerini hesaplayabilirsiniz. Bir örnek için Bisiklet paylaşımı talep not defterinin Değerlendir bölümüne bakın.
Genel model doğruluğu belirlendikten sonra, sonraki en gerçekçi adım bilinmeyen gelecekteki değerleri tahmin etmek için modeli kullanmaktır.
Test kümesiyle aynı biçimde ancak gelecek tarih saatleriyle bir veri kümesi test_dataset sağlayın ve sonuçta elde edilen tahmin kümesi, her zaman serisi adımı için tahmin edilen değerlerdir. Veri kümesindeki son zaman serisi kayıtlarının 31.12.2018 için olduğunu varsayalım. Sonraki günün talebini tahmin etmek için (veya tahmin etmeniz gereken sayıda dönem, <= forecast_horizon), 01.01.2019 için her mağaza için tek bir zaman serisi kaydı oluşturun.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Bu gelecekteki verileri bir veri çerçevesine yüklemek için gerekli adımları tekrarlayın ve ardından gelecekteki değerleri tahmin etmek için komutunu çalıştırın best_run.forecast_quantiles(test_dataset) .
Not
Ve/veya target_rolling_window_size etkinleştirildiğindetarget_lags, örnek içi tahminler otomatik ML ile tahmin için desteklenmez.
Büyük ölçekte tahmin
Tek bir makine öğrenmesi modelinin yetersiz olduğu ve birden çok makine öğrenmesi modeline ihtiyaç duyulduğu senaryolar vardır. Örneğin, bir marka için her bir mağazanın satışlarını tahmin etme veya bir deneyimi tek tek kullanıcılara uyarlama. Her örnek için bir model oluşturmak, birçok makine öğrenmesi sorununda iyileştirilmiş sonuçlara yol açabilir.
Gruplandırma, zaman serisi tahmininde, zaman serisinin grup başına tek bir modeli eğitmek için birleştirilmesine olanak tanıyan bir kavramdır. Bu yaklaşım, düzeltme, doldurma gerektiren zaman serileriniz veya gruptaki geçmiş veya diğer varlıklardaki eğilimlerden yararlanabilecek varlıklara sahipseniz özellikle yararlı olabilir. Birçok model ve hiyerarşik zaman serisi tahmini, bu büyük ölçekli tahmin senaryoları için otomatik makine öğrenmesi tarafından desteklenen çözümlerdir.
Birçok model
Otomatik makine öğrenmesine sahip Azure Machine Learning birçok model çözümü, kullanıcıların milyonlarca modeli paralel olarak eğitmesini ve yönetmesini sağlar. Birçok model Çözüm hızlandırıcısı, modeli eğitmek için Azure Machine Learning işlem hatlarını kullanır. Özellikle, bir Pipeline nesnesi ve ParalleRunStep kullanılır ve ParallelRunConfig aracılığıyla belirli yapılandırma parametrelerinin ayarlanmasını gerektirir.
Aşağıdaki diyagramda birçok model çözümü için iş akışı gösterilmektedir.

Aşağıdaki kod, kullanıcıların çalıştırılacak birçok modeli ayarlaması gereken anahtar parametreleri gösterir. Birçok model tahmin örneği için Bkz. Çok Modelli- Otomatik ML not defteri
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Hiyerarşik zaman serisi tahmini
Çoğu uygulamada müşterilerin tahminlerini işletmenin makro ve mikro düzeyinde anlaması gerekir. Forcast'lar farklı coğrafi konumlardaki ürünlerin satışlarını tahmin edebilir veya bir şirkette farklı kuruluşlar için beklenen iş gücü talebini anlayabilir. Hiyerarşi verilerini akıllı bir şekilde tahmin etmek için makine öğrenmesi modelini eğitmek çok önemlidir.
Hiyerarşik zaman serisi, benzersiz serilerin her birinin coğrafya veya ürün türü gibi boyutlara göre bir hiyerarşi halinde düzenlendiği bir yapıdır. Aşağıdaki örnek, hiyerarşi oluşturan benzersiz özniteliklere sahip verileri gösterir. Hiyerarşimiz şunları tanımlar: kulaklık veya tablet gibi ürün türü, ürün türlerini aksesuarlara ve cihazlara ayıran ürün kategorisi ve ürünlerin satıldığı bölge.

Bunu daha fazla görselleştirmek için, hiyerarşinin yaprak düzeyleri benzersiz öznitelik değerleri birleşimlerine sahip tüm zaman serilerini içerir. Hiyerarşideki her üst düzey, zaman serisini tanımlamak için bir daha az boyut düşünür ve alt düğüm kümelerini alt düzeyden üst düğüme toplar.

Hiyerarşik zaman serisi çözümü, Çok Modelli Çözüm'ün üzerine kurulmuştur ve benzer bir yapılandırma kurulumunu paylaşır.
Aşağıdaki kod, hiyerarşik zaman serisi tahmin çalıştırmalarınızı ayarlamak için anahtar parametreleri gösterir. Uçtan uca örnek için Hiyerarşik zaman serisi- Otomatik ML not defterine bakın.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Örnek not defterleri
Gelişmiş tahmin yapılandırmasının ayrıntılı kod örnekleri için tahmin örneği not defterlerine bakın:
- tatil algılama ve özellik geliştirme
- rolling-origin çapraz doğrulaması
- yapılandırılabilir gecikmeler
- kayan pencere toplama özellikleri
Sonraki adımlar
- AutoML modelini çevrimiçi uç noktaya dağıtma hakkında daha fazla bilgi edinin.
- Yorumlanabilirlik: otomatik makine öğrenmesinde model açıklamaları (önizleme) hakkında bilgi edinin.
- AutoML'nin tahmin modellerini nasıl derleyeceğinizi öğrenin.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin