AutoML'de tahmin hakkında sık sorulan sorular
ŞUNLAR IÇIN GEÇERLIDIR:  Python SDK'sı azure-ai-ml v2 (geçerli)
Python SDK'sı azure-ai-ml v2 (geçerli)
Bu makalede, otomatik makine öğrenmesinde (AutoML) tahmin etme hakkında sık sorulan sorular yanıtlar. AutoML'de tahmin metodolojisi hakkında genel bilgi için AutoML'de tahmin yöntemlerine genel bakış makalesine bakın.
AutoML'de tahmin modelleri oluşturmaya Nasıl yaparım? başladı?
Zaman serisi tahmin modelini eğitmek için AutoML'yi ayarlama makalesini okuyarak başlayabilirsiniz. Birkaç Jupyter not defterinde uygulamalı örnekler de bulabilirsiniz:
- Bisiklet paylaşımı örneği
- Derin öğrenme kullanarak tahmin etme
- Birçok Model çözümü
- Tarifleri tahmin etme
- Gelişmiş tahmin senaryoları
AutoML verilerimde neden yavaş?
AutoML'yi her zaman daha hızlı ve daha ölçeklenebilir hale getirmek için çalışıyoruz. Genel bir tahmin platformu olarak çalışmak için AutoML kapsamlı veri doğrulamaları ve karmaşık özellik mühendisliği yapar ve büyük bir model alanı üzerinde arama yapar. Bu karmaşıklık, verilere ve yapılandırmaya bağlı olarak çok fazla zaman gerektirebilir.
Yavaş çalışma zamanının yaygın kaynaklarından biri, AutoML'nin çok sayıda zaman serisi içeren verilerde varsayılan ayarlarla eğitiliyor olmasıdır. Birçok tahmin yönteminin maliyeti, seri sayısıyla ölçeklendirilir. Örneğin Üstel Düzeltme ve Kahin gibi yöntemler, eğitim verilerindeki her zaman serisi için bir model eğitmektedir.
AutoML'nin Çok Modelli özelliği, eğitim işlerini bir işlem kümesine dağıtarak bu senaryolara ölçeklendirilir. Milyonlarca zaman serisine sahip verilere başarıyla uygulandı. Daha fazla bilgi için birçok model makalesi bölümüne bakın. Ayrıca, yüksek profilli bir rekabet veri kümesinde Birçok Modelin başarısı hakkında da bilgi edinebilirsiniz.
AutoML'i nasıl daha hızlı hale getirebilirim?
AutoML'nin sizin durumunuzda neden yavaş olabileceğini anlamak için Bkz. AutoML verilerimde neden yavaş? yanıtı.
İşinizi hızlandırabilecek aşağıdaki yapılandırma değişikliklerini göz önünde bulundurun:
- ARIMA ve Prophet gibi zaman serisi modellerini engelleyin.
- Gecikmeler ve sıralı pencereler gibi arka arkaya bakma özelliklerini kapatın.
- Azaltmak:
- Deneme/yineleme sayısı.
- Deneme/yineleme zaman aşımı.
- Deneme zaman aşımı.
- Çapraz doğrulama katlama sayısı.
- Erken sonlandırmanın etkinleştirildiğinden emin olun.
Hangi modelleme yapılandırmasını kullanmalıyım?
AutoML tahmini dört temel yapılandırmayı destekler:
| Yapılandırma | Senaryo | Avantajlar | Dezavantajlar |
|---|---|---|---|
| Varsayılan AutoML | Veri kümesinin yaklaşık olarak benzer geçmiş davranışlara sahip az sayıda zaman serisi varsa önerilir. | - Koddan/SDK'dan veya Azure Machine Learning stüdyosu yapılandırması kolaydır. - Regresyon modelleri tüm serileri eğitimde bir araya topladığı için AutoML farklı zaman serilerinde bilgi edinebilir. Daha fazla bilgi için bkz . Model gruplandırma. |
- Eğitim verilerindeki zaman serisinde farklı davranışlar varsa regresyon modelleri daha az doğru olabilir. - Eğitim verilerinin çok sayıda serisi varsa zaman serisi modellerinin eğitilmiş olması uzun sürebilir. Daha fazla bilgi için Bkz . AutoML verilerimde neden yavaş? yanıtı. |
| Derin öğrenme ile AutoML | 1.000'den fazla gözleme ve potansiyel olarak karmaşık desenler sergileyen çok sayıda zaman serisine sahip veri kümeleri için önerilir. Etkinleştirildiğinde AutoML, eğitim sırasında zamansal kıvrımlı sinir ağı (TCN) modellerini tarar. Daha fazla bilgi için bkz . Derin öğrenmeyi etkinleştirme. | - Koddan/SDK'dan veya Azure Machine Learning stüdyosu yapılandırması kolaydır. - Çapraz öğrenme fırsatları, çünkü TCN tüm serilerde verileri havuza alır. - Derin sinir ağı (DNN) modellerinin büyük kapasitesi nedeniyle potansiyel olarak daha yüksek doğruluk. Daha fazla bilgi için bkz . AutoML'de modelleri tahmin etme. |
- DNN modellerinin karmaşıklığı nedeniyle eğitim çok daha uzun sürebilir. - Az miktarda geçmişe sahip serilerin bu modellerden yararlanma olasılığı düşüktür. |
| Birçok Model | Çok sayıda tahmin modelini ölçeklenebilir bir şekilde eğitip yönetmeniz gerekiyorsa önerilir. Daha fazla bilgi için birçok model makalesi bölümüne bakın. | -Ölçeklenebilir. - Zaman serisi birbirinden farklı davranışlara sahip olduğunda potansiyel olarak daha yüksek doğruluk. |
- Zaman serisinde öğrenme yok. - Azure Machine Learning stüdyosu Birçok Model işi yapılandıramaz veya çalıştıramazsınız. Şu anda yalnızca kod/SDK deneyimi kullanılabilir. |
| Hiyerarşik zaman serisi (HTS) | Verilerinizdeki serilerin iç içe, hiyerarşik bir yapısı varsa ve hiyerarşinin toplanmış düzeylerinde eğitmek veya tahminde bulunmanız gerekiyorsa önerilir. Daha fazla bilgi için hiyerarşik zaman serisi tahmin makalesi bölümüne bakın. | - Toplanan düzeylerde eğitim, yaprak düğüm zaman serisindeki gürültüyü azaltabilir ve potansiyel olarak daha yüksek doğruluklu modellere yol açabilir. - Eğitim düzeyinden tahminleri toplayarak veya ayırarak hiyerarşinin herhangi bir düzeyi için tahminleri alabilirsiniz. |
- Eğitim için toplama düzeyini sağlamanız gerekir. AutoML şu anda en uygun düzeyi bulmak için bir algoritmaya sahip değildir. |
Not
Yüksek DNN kapasitesinden en iyi şekilde yararlanmak için derin öğrenme etkinleştirildiğinde GPU'larla işlem düğümlerini kullanmanızı öneririz. Eğitim süresi, yalnızca CPU'lara sahip düğümlere kıyasla çok daha hızlı olabilir. Daha fazla bilgi için GPU için iyileştirilmiş sanal makine boyutları makalesine bakın.
Not
HTS, hiyerarşideki toplanmış düzeylerde eğitim veya tahmin gerektiren görevler için tasarlanmıştır. Yalnızca yaprak düğüm eğitimi ve tahmini gerektiren hiyerarşik veriler için bunun yerine birçok model kullanın.
Fazla uygunluk ve veri sızıntısını nasıl önleyebilirim?
AutoML, birçok fazla uygunluk sorununu azaltan çapraz doğrulanmış model seçimi gibi makine öğrenmesi en iyi yöntemlerini kullanır. Ancak, fazla uygunluk için başka olası kaynaklar da vardır:
Giriş verileri, basit bir formülle hedeften türetilen özellik sütunları içerir. Örneğin, hedefin tam katı olan bir özellik neredeyse mükemmel bir eğitim puanına neden olabilir. Ancak model büyük olasılıkla örnek dışı verileri genelleştirmeyecektir. Model eğitimi öncesinde verileri incelemenizi ve hedef bilgileri "sızdıran" sütunları bırakmanızı öneririz.
Eğitim verileri, tahmin ufkuna kadar gelecekte bilinmeyen özellikleri kullanır. AutoML'nin regresyon modelleri şu anda tüm özelliklerin tahmin ufku tarafından bilindiğini varsayar. Eğitimden önce verilerinizi incelemenizi ve yalnızca geçmişe dönük olarak bilinen özellik sütunlarını kaldırmanızı öneririz.
Verilerin eğitim, doğrulama veya test bölümleri arasında önemli yapısal farklılıklar (rejim değişiklikleri) vardır. Örneğin, COVID-19 pandemisinin 2020 ve 2021 boyunca neredeyse her türlü iyi durum için isteğe bağlı etkisini göz önünde bulundurun. Bu, bir rejim değişikliğinin klasik bir örneğidir. Son derece senaryoya bağımlı olduğundan ve tanımlamak için derin bilgi gerektirebileceğinden, rejim değişikliği nedeniyle fazla uygunluk sorunu en zorlu çözümdür.
İlk savunma hattı olarak, doğrulama verileri veya çapraz doğrulama verileri için toplam geçmişin yüzde 10-20'sini ayırmayı deneyin. Eğitim geçmişi kısaysa bu miktarda doğrulama verilerini ayırmak her zaman mümkün değildir, ancak en iyi yöntemdir. Daha fazla bilgi için bkz . Eğitim ve doğrulama verileri.
Eğitim işimin mükemmel doğrulama puanlarına ulaşması ne anlama gelir?
Bir eğitim işinden doğrulama ölçümlerini görüntülerken mükemmel puanlar görebilirsiniz. Mükemmel bir puan, doğrulama kümesindeki tahminin ve fiili değerlerin aynı veya neredeyse aynı olduğu anlamına gelir. Örneğin, 0,0'a eşit bir kök ortalama kare hatanız veya 1,0 R2 puanınız vardır.
Mükemmel bir doğrulama puanı genellikle modelin büyük olasılıkla veri sızıntısı nedeniyle aşırı uygun olduğunu gösterir. En iyi eylem, verileri sızıntılara karşı incelemek ve sızıntıya neden olan sütunları bırakmaktır.
Zaman serisi verilerimde düzenli aralıklı gözlemler yoksa ne olur?
AutoML'nin tahmin modellerinin tümü, eğitim verilerinin takvime göre düzenli aralıklı gözlemler olmasını gerektirir. Bu gereksinim, gözlemler arasındaki gün sayısının değişebileceği aylık veya yıllık gözlemler gibi durumları içerir. Zamana bağlı veriler iki durumda bu gereksinimi karşılamayabilir:
Verilerin iyi tanımlanmış bir sıklığı vardır, ancak eksik gözlemler seride boşluklar oluşturur. Bu durumda AutoML sıklığı algılamaya, boşluklar için yeni gözlemleri doldurmaya ve eksik hedef ve özellik değerlerini açma/kapatmaya çalışır. İsteğe bağlı olarak kullanıcı, kimlik doğrulama yöntemlerini SDK ayarları veya Web kullanıcı arabirimi aracılığıyla yapılandırabilir. Daha fazla bilgi için bkz . Özel özellik geliştirme.
Verilerin iyi tanımlanmış bir sıklığı yoktur. Başka bir ifadeyle, gözlemler arasındaki sürenin ayırt edilebilir bir deseni yoktur. Satış noktası sisteminden alınan işlemsel veriler buna örnek olarak gösteriliyor. Bu durumda, AutoML'yi verilerinizi seçilen sıklıkta topacak şekilde ayarlayabilirsiniz. Verilere ve modelleme hedeflerine en uygun düzenli sıklığı seçebilirsiniz. Daha fazla bilgi için bkz . Veri toplama.
Birincil ölçümü Nasıl yaparım? seçin?
Birincil ölçüm önemlidir çünkü doğrulama verilerindeki değeri süpürme ve seçim sırasında en iyi modeli belirler. Normalleştirilmiş kök ortalama kare hatası (NRMSE) ve normalleştirilmiş ortalama mutlak hata (NMAE) genellikle tahmin görevlerinde birincil ölçüm için en iyi seçeneklerdir.
Aralarından seçim yapmak için, NRMSE'nin hatanın karesini kullandığından, eğitim verilerindeki aykırı değerleri NMAE'den daha fazla cezalandırdığını unutmayın. Modelin aykırı değerlere karşı daha az duyarlı olmasını istiyorsanız NMAE daha iyi bir seçim olabilir. Daha fazla bilgi için bkz . Regresyon ve tahmin ölçümleri.
Not
Tahmin için birincil ölçüm olarak R2 puanını veya R2'yi kullanmanızı önermiyoruz.
Not
AutoML, birincil ölçüm için özel veya kullanıcı tarafından sağlanan işlevleri desteklemez. AutoML'nin desteklediği önceden tanımlanmış birincil ölçümlerden birini seçmeniz gerekir.
Modelimin doğruluğunu nasıl geliştirebilirim?
- AutoML'yi verileriniz için en iyi şekilde yapılandırdığınızdan emin olun. Daha fazla bilgi için bkz . Hangi modelleme yapılandırmasını kullanmalıyım? yanıtı.
- Tahmin modellerini oluşturma ve geliştirme hakkında adım adım kılavuzlar için tahmin tarifleri not defterine göz atın.
- Birkaç tahmin döngüsünde geri testlerini kullanarak modeli değerlendirin. Bu yordam, tahmin hatasıyla ilgili daha sağlam bir tahmin sağlar ve iyileştirmeleri ölçmek için size bir temel sağlar. Bir örnek için geri test not defterine bakın.
- Veriler gürültülüyse sinyal-gürültü oranını artırmak için bir kabarıcı frekansına toplamayı göz önünde bulundurun. Daha fazla bilgi için bkz . Sıklık ve hedef veri toplama.
- Hedefi tahmin etmenize yardımcı olabilecek yeni özellikler ekleyin. Konu uzmanlığı, eğitim verilerini seçerken büyük ölçüde yardımcı olabilir.
- Doğrulama ve test ölçüm değerlerini karşılaştırın ve seçilen modelin verilerin yetersiz mi yoksa fazla uygun mu olduğunu belirleyin. Bu bilgi, daha iyi bir eğitim yapılandırması için size yol gösterebilir. Örneğin, fazla uygunluk için daha fazla çapraz doğrulama katlama kullanmanız gerektiğini belirleyebilirsiniz.
AutoML her zaman aynı eğitim verilerinden ve yapılandırmasından aynı en iyi modeli mi seçer?
AutoML'nin model arama işlemi belirleyici olmadığından her zaman aynı veri ve yapılandırmadan aynı modeli seçmez.
Bellek yetersiz hatası Nasıl yaparım? düzeltilir?
İki tür bellek hatası vardır:
- RAM yetersiz bellek
- Disk yetersiz bellek
İlk olarak, AutoML'yi verileriniz için en iyi şekilde yapılandırdığınızdan emin olun. Daha fazla bilgi için bkz . Hangi modelleme yapılandırmasını kullanmalıyım? yanıtı.
Varsayılan AutoML ayarları için, daha fazla RAM'e sahip işlem düğümlerini kullanarak RAM yetersiz bellek hatalarını düzeltebilirsiniz. Genel bir kural, AutoML'yi varsayılan ayarlarla çalıştırmak için boş RAM miktarının ham veri boyutundan en az 10 kat daha büyük olması gerektiğidir.
İşlem kümesini silip yeni bir tane oluşturarak disk yetersiz bellek hatalarını çözebilirsiniz.
AutoML hangi gelişmiş tahmin senaryolarını destekler?
AutoML aşağıdaki gelişmiş tahmin senaryolarını destekler:
- Nicelik tahminleri
- Sıralı tahminler aracılığıyla sağlam model değerlendirmesi
- Tahmin ufkunun ötesinde tahmin
- Eğitim ve tahmin dönemleri arasında zaman aralığı olup olmadığını tahmin etme
Örnekler ve ayrıntılar için gelişmiş tahmin senaryoları için not defterine bakın.
Eğitim işlerini tahmin etme ölçümlerini Nasıl yaparım? görüntüleyebilirsiniz?
Eğitim ve doğrulama ölçüm değerlerini bulmak için bkz . Stüdyodaki işler veya çalıştırmalar hakkındaki bilgileri görüntüleme. Studio'daki AutoML iş kullanıcı arabiriminden bir modele gidip Ölçümler sekmesini seçerek AutoML'de eğitilen herhangi bir tahmin modelinin ölçümlerini görüntüleyebilirsiniz.
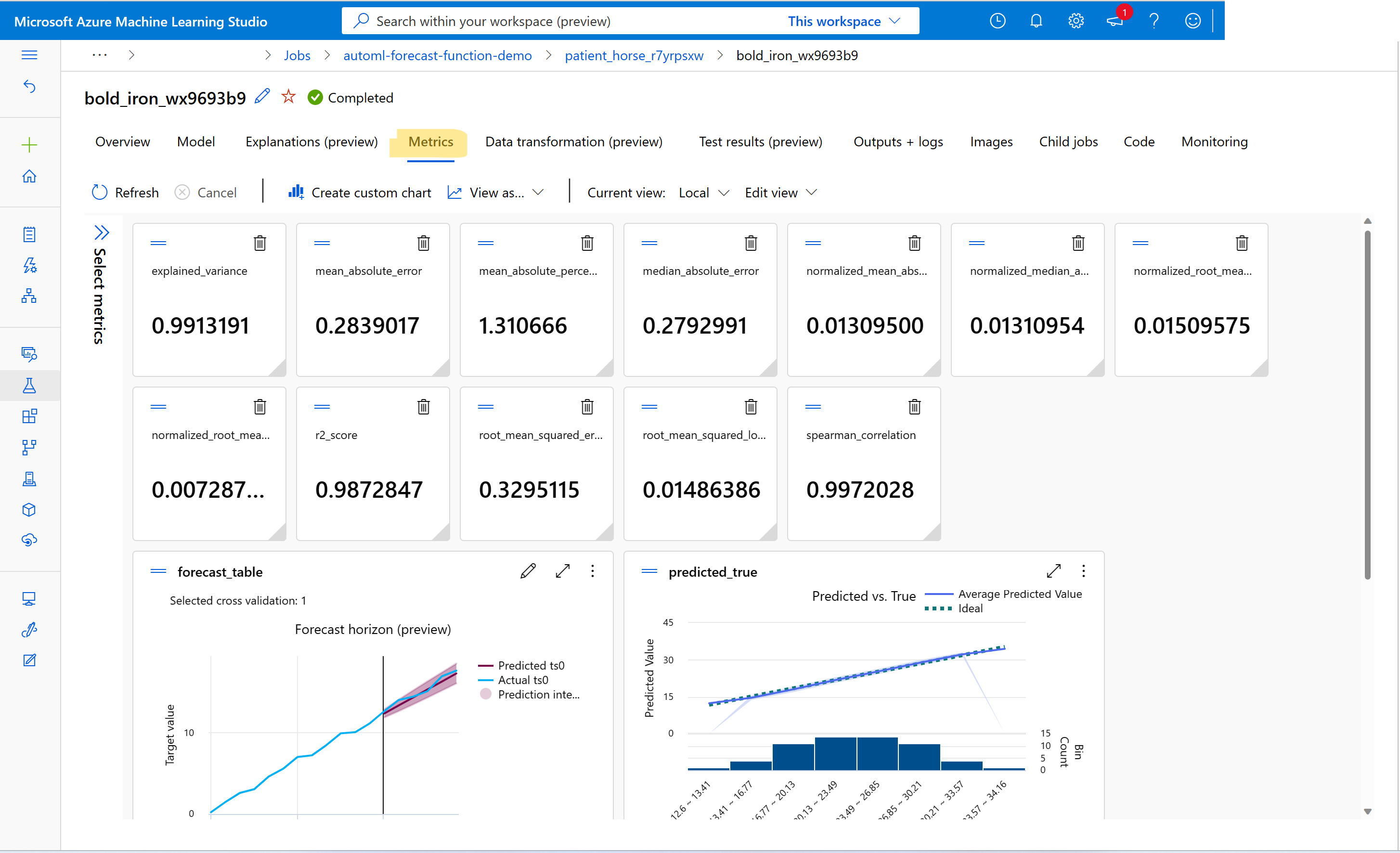
Eğitim işlerini tahmin etmeyle ilgili hatalarda hata ayıklama Nasıl yaparım??
AutoML tahmin işiniz başarısız olursa, studio kullanıcı arabirimindeki bir hata iletisi sorunu tanılamanıza ve çözmenize yardımcı olabilir. Hata iletisinin ötesinde hatayla ilgili en iyi bilgi kaynağı, işin sürücü günlüğüdür. Sürücü günlüklerini bulma yönergeleri için bkz . MLflow ile işleri/çalıştırma bilgilerini görüntüleme.
Not
Birçok Model veya HTS işi için eğitim genellikle birden çok düğümlü işlem kümelerinde yapılır. Bu işlerin günlükleri her düğüm IP adresi için mevcuttur. Bu durumda, her düğümde hata günlüklerini aramanız gerekir. Hata günlükleri ve sürücü günlükleri, her düğüm IP'sinin user_logs klasöründedir.
Eğitim işlerini tahmin ederek model dağıtma Nasıl yaparım??
Eğitim işlerini tahmin ederek modeli şu yollardan biriyle dağıtabilirsiniz:
- Çevrimiçi uç nokta: Dağıtımın beklediği girişin yapısını anlamak için dağıtımda kullanılan puanlama dosyasını denetleyin veya stüdyodaki uç nokta sayfasında Test sekmesini seçin. Bir örnek için bu not defterine bakın. Çevrimiçi dağıtım hakkında daha fazla bilgi için bkz . Çevrimiçi uç noktaya AutoML modeli dağıtma.
- Batch uç noktası: Bu dağıtım yöntemi, özel bir puanlama betiği geliştirmenizi gerektirir. Bir örnek için bu not defterine bakın. Toplu dağıtım hakkında daha fazla bilgi için bkz . Toplu puanlama için toplu iş uç noktalarını kullanma.
Kullanıcı arabirimi dağıtımları için şu seçeneklerden birini kullanmanızı öneririz:
- Gerçek zamanlı uç nokta
- Batch uç noktası
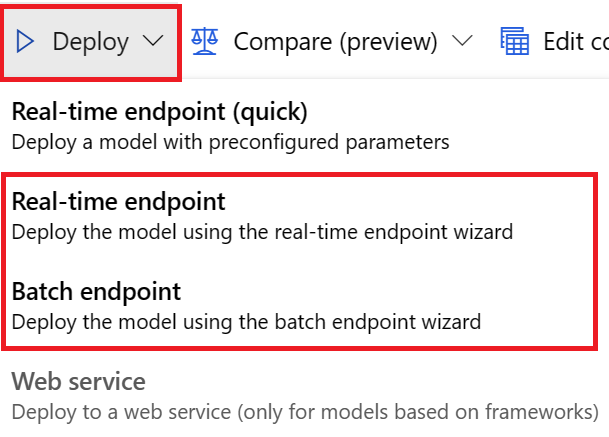
İlk seçenek olan Gerçek zamanlı uç nokta (hızlı) seçeneğini kullanmayın.
Not
Şu andan itibaren SDK, CLI veya kullanıcı arabirimi aracılığıyla eğitim işlerini tahmin ederek MLflow modelini dağıtmayı desteklemiyoruz. Denerseniz hata alırsınız.
Çalışma alanı, ortam, deneme, işlem örneği veya işlem hedefi nedir?
Azure Machine Learning kavramlarını bilmiyorsanız Azure Machine Learning nedir? ve Azure Machine Learning çalışma alanı nedir? makaleleriyle başlayın.
Sonraki adımlar
- Zaman serisi tahmin modelini eğitmek için AutoML'yi ayarlama hakkında daha fazla bilgi edinin.
- AutoML'de zaman serisi tahmini için takvim özellikleri hakkında bilgi edinin.
- AutoML'nin tahmin modelleri oluşturmak için makine öğrenmesini nasıl kullandığı hakkında bilgi edinin.
- Gecikmiş özellikler için AutoML tahmini hakkında bilgi edinin.