Toplu dağıtımlar için puanlama betikleri yazma
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Batch uç noktaları, büyük ölçekte uzun süre çalışan çıkarım yapan modelleri dağıtmanıza olanak tanır. Modelleri dağıtırken, tahmin oluşturmak için giriş verileri üzerinden nasıl kullanılacağını belirtmek için bir puanlama betiği (toplu iş sürücüsü betiği olarak da bilinir) oluşturmanız ve belirtmeniz gerekir. Bu makalede, farklı senaryolar için model dağıtımlarında puanlama betiklerini kullanmayı öğreneceksiniz. Toplu iş uç noktaları için en iyi yöntemler hakkında da bilgi edineceksiniz.
İpucu
MLflow modelleri puanlama betiği gerektirmez. Sizin için otomatik olarak oluşturulur. Toplu iş uç noktalarının MLflow modelleriyle nasıl çalıştığı hakkında daha fazla bilgi için Toplu dağıtımlarda MLflow modellerini kullanma ayrılmış öğreticisini ziyaret edin.
Uyarı
Toplu iş uç noktası altında Otomatik ML modeli dağıtmak için, Otomatik ML'nin yalnızca Çevrimiçi Uç Noktalar için çalışan bir puanlama betiği sağladığını unutmayın. Bu puanlama betiği toplu yürütme için tasarlanmamıştır. Modelinizin yaptıklarına göre özelleştirilmiş bir puanlama betiği oluşturma hakkında daha fazla bilgi için lütfen bu yönergeleri izleyin.
Puanlama betiğini anlama
Puanlama betiği, modelin nasıl çalıştırıldığını belirten ve toplu dağıtım yürütücüsunun gönderdiği giriş verilerini okuyan bir Python dosyasıdır (.py). Her model dağıtımı, oluşturma zamanında puanlama betiğini (diğer tüm gerekli bağımlılıklarla birlikte) sağlar. Puanlama betiği genellikle şöyle görünür:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
Puanlama betiği iki yöntem içermelidir:
init yöntemi
init() Herhangi bir maliyetli veya ortak hazırlık için yöntemini kullanın. Örneğin, modeli belleğe yüklemek için kullanın. Toplu işin tamamının başlangıcı bu işlevi bir kez çağırır. Modelinizin dosyaları, ortam değişkeni AZUREML_MODEL_DIRtarafından belirlenen bir yolda kullanılabilir. Modelinizin nasıl kaydedilildiğine bağlı olarak, dosyaları bir klasörde bulunabilir. Sonraki örnekte, model adlı modelbir klasörde birkaç dosya içerir. Daha fazla bilgi için modelinizin kullandığı klasörü nasıl belirleyebileceğinizi ziyaret edin.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
Bu örnekte modeli genel değişkenine modelyerleştireceğiz. Puanlama işlevinizde çıkarım yapmak için gereken varlıkları kullanılabilir hale getirmek için genel değişkenleri kullanın.
run yöntemi
Toplu iş dağıtımının run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] oluşturduğu her mini toplu işin puanlama işlemini işlemek için yöntemini kullanın. Bu yöntem, giriş verileriniz için oluşturulan her mini_batch biri için bir kez çağrılır. Toplu dağıtımlar, dağıtım yapılandırmasına göre verileri toplu olarak okur.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
yöntemi, dosya yollarının listesini parametre (mini_batch) olarak alır. Her dosyayı yinelemek ve ayrı ayrı işlemek veya toplu işlemin tamamını okuyup hepsini tek seferde işlemek için bu listeyi kullanabilirsiniz. En iyi seçenek, işlem belleğinize ve elde etmeniz gereken aktarım hızına bağlıdır. Veri toplu işlemlerinin tamamının aynı anda nasıl okunduğunu açıklayan bir örnek için Yüksek aktarım hızı dağıtımları'nı ziyaret edin.
Not
İş nasıl dağıtılır?
Toplu dağıtımlar, işi dosya düzeyinde dağıtır. Bu, 10 dosyadan oluşan mini toplu işlerle birlikte 10 dosya içeren bir klasörün her biri 10 dosyadan oluşan 10 toplu iş oluşturduğu anlamına gelir. İlgili dosyaların boyutlarının ilgisi olmadığını unutmayın. Büyük mini toplu işlemlerde işlenemeyecek kadar büyük dosyalar için, daha yüksek düzeyde paralellik elde etmek için dosyaları daha küçük dosyalara bölmenizi veya mini toplu iş başına dosya sayısını azaltmanızı öneririz. Şu anda toplu dağıtım, dosyanın boyut dağılımındaki dengesizlikleri hesaba katılamıyor.
run() yöntemi bir Pandas DataFrame veya dizi/liste döndürmelidir. Döndürülen her çıkış öğesi, girişinde mini_batchbir giriş öğesinin başarılı bir çalıştırmasını gösterir. Dosya veya klasör veri varlıkları için, döndürülen her satır/öğe işlenen tek bir dosyayı temsil eder. Tablosal veri varlığı için, döndürülen her satır/öğe işlenen dosyadaki bir satırı temsil eder.
Önemli
Tahminler nasıl yazılır?
İşlevin run() döndürdüğü her şey, toplu işin oluşturduğu çıkış tahminleri dosyasına eklenir. Bu işlevden doğru veri türünü döndürmek önemlidir. Tek bir tahmin çıktısı almanız gerektiğinde dizileri döndürür. Birden çok bilgi parçası döndürmeniz gerektiğinde pandas DataFrames'i döndürebilirsiniz. Örneğin, tablosal veriler için tahminlerinizi özgün kayda eklemek isteyebilirsiniz. Bunu yapmak için pandas DataFrame kullanın. Pandas DataFrame sütun adları içerse de, çıkış dosyası bu adları içermez.
tahminleri farklı bir şekilde yazmak için toplu dağıtımlardaki çıktıları özelleştirebilirsiniz.
Uyarı
işlevinde run yerine karmaşık veri türlerinin (veya karmaşık veri türlerinin listelerinin) çıkışını pandas.DataFrameyapmayın. Bu çıkışlar dizelere dönüştürülür ve okunmaları zorlaşır.
Sonuçta elde edilen DataFrame veya dizi, belirtilen çıkış dosyasına eklenir. Sonuçların kardinalitesi ile ilgili bir gereksinim yoktur. Bir dosya çıktıda 1 veya çok sayıda satır/öğe oluşturabilir. Sonuç DataFrame veya dizideki tüm öğeler çıkış dosyasına olduğu gibi yazılır (değeri dikkate summary_onlyalındığındaoutput_action).
Puanlama için Python paketleri
Puanlama betiğinizin toplu dağıtımınızın çalıştığı ortamda çalıştırılması için gereken tüm kitaplıkları belirtmeniz gerekir. Puanlama betikleri için ortamlar dağıtıma göre belirtilir. Genellikle, gereksinimlerinizi aşağıdaki gibi görünebilecek bir conda.yml bağımlılık dosyası kullanarak belirtirsiniz:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Modelinizin ortamını belirtme hakkında daha fazla bilgi için Toplu dağıtım oluşturma adresini ziyaret edin.
Tahminleri farklı bir şekilde yazma
Varsayılan olarak, toplu dağıtım, modelin tahminlerini dağıtımda gösterildiği gibi tek bir dosyaya yazar. Ancak bazı durumlarda tahminleri birden çok dosyaya yazmanız gerekir. Örneğin, bölümlenmiş giriş verileri için büyük olasılıkla bölümlenmiş çıkış da oluşturmak isteyebilirsiniz. Bu gibi durumlarda, toplu dağıtımlardaki çıktıları özelleştirerek şunları belirtebilirsiniz:
- Tahminleri yazmak için kullanılan dosya biçimi (CSV, parquet, json vb.)
- Verilerin çıkışta bölümlenme şekli
Bunu nasıl gerçekleştirebileceğiniz hakkında daha fazla bilgi için Toplu dağıtımlarda çıktıları özelleştirme'yi ziyaret edin.
Puanlama betiklerinin kaynak denetimi
Puanlama betiklerinin kaynak denetimi altına alınması kesinlikle önerilir.
Puanlama betikleri yazmak için en iyi yöntemler
Büyük miktarda veriyi işleyen puanlama betikleri yazarken, aşağıdakiler dahil olmak üzere çeşitli faktörleri dikkate almanız gerekir:
- Her dosyanın boyutu
- Her dosyadaki veri miktarı
- Her dosyayı okumak için gereken bellek miktarı
- Tüm dosya toplu işlemini okumak için gereken bellek miktarı
- Modelin bellek ayak izi
- Giriş verilerinin üzerinde çalışırken model bellek ayak izi
- İşleminizde kullanılabilir bellek
Toplu dağıtımlar, işi dosya düzeyinde dağıtır. Bu, 10 dosyadan oluşan mini toplu işlemlerle 100 dosya içeren bir klasörün her biri 10 dosyadan oluşan 10 toplu iş oluşturduğu anlamına gelir (ilgili dosyaların boyutundan bağımsız olarak). Büyük mini toplu işlemlerde işlenemeyecek kadar büyük dosyalar için, daha yüksek bir paralellik düzeyi elde etmek için dosyaları daha küçük dosyalara bölmenizi veya mini toplu işlem başına dosya sayısını azaltmanızı öneririz. Şu anda toplu dağıtım, dosyanın boyut dağılımındaki dengesizlikleri hesaba katılamıyor.
Paralellik derecesi ile puanlama betiği arasındaki ilişki
Dağıtım yapılandırmanız hem her mini toplu iş boyutunu hem de her düğümdeki çalışan sayısını denetler. Çıkarım yapmak, çıkarım dosyasını dosyaya göre çalıştırmak veya çıkarım satırını satıra göre çalıştırmak için (tablosal için) mini toplu işleminin tamamını okuyup okumamaya karar verdiğinizde bu önemli hale gelir. Daha fazla bilgi için Mini toplu iş, dosya veya satır düzeyinde Çıkarım çalıştırılıyor'u ziyaret edin.
Aynı örnekte birden çok çalışan çalıştırırken, belleğin tüm çalışanlar arasında paylaşıldığını hesaba katmalısınız. Düğüm başına çalışan sayısındaki artış genellikle mini toplu iş boyutundaki azalmaya veya veri boyutu ile işlem SKU'su aynı kalırsa puanlama stratejisindeki bir değişikliğe eşlik etmelidir.
Mini toplu iş, dosya veya satır düzeyinde çıkarım çalıştırma
Batch uç noktaları, mini toplu iş başına bir kez puanlama betiğinde işlevi çağırır run() . Ancak, çıkarımı toplu iş boyunca, tek seferde bir dosya üzerinde veya tablo verileri için bir kerede bir satır üzerinde çalıştırmak isteyip istemediğinize karar vekleyebilirsiniz.
Mini toplu iş düzeyi
Toplu puanlama işleminizde yüksek aktarım hızı elde etmek için genellikle toplu iş üzerinden çıkarımları tek seferde çalıştırmak istersiniz. Çıkarım cihazının doygunluğunu elde etmek istediğiniz bir GPU üzerinden çıkarım çalıştırırsanız bu durum ortaya çıkar. Ayrıca, veriler gibi TensorFlow PyTorch veya veri yükleyicileri belleğe sığmazsa toplu işlemi işleyebilen bir veri yükleyicisine de güvenebilirsiniz. Bu gibi durumlarda, tüm toplu işlemde çıkarım çalıştırmak isteyebilirsiniz.
Uyarı
Toplu iş düzeyinde çıkarım çalıştırmak, bellek gereksinimlerini doğru şekilde hesaba katıp bellek yetersiz özel durumlarını önlemek için giriş veri boyutu üzerinde yakın denetime ihtiyaç duyabilir. Mini toplu işlemlerin tamamını belleğe yükleyip yükleyemeyeceğiniz mini toplu işlemin boyutuna, kümedeki örneklerin boyutuna, her düğümdeki çalışan sayısına ve mini toplu işlemin boyutuna bağlıdır.
Bunu nasıl başaracağınızı öğrenmek için Yüksek aktarım hızı dağıtımları'na bakın. Bu örnek, bir kerede bir grup dosyayı işler.
Dosya düzeyi
Çıkarım yapmanın en kolay yollarından biri, mini toplu işteki tüm dosyalar üzerinde yineleme yapmak ve ardından modeli bunun üzerinde çalıştırmaktır. Bazı durumlarda, örneğin görüntü işleme, bu iyi bir fikir olabilir. Tablosal veriler için, her dosyadaki satır sayısı hakkında iyi bir tahminde bulunmanız gerekebilir. Bu tahmin, modelinizin hem tüm verileri belleğe yüklemek hem de bunun üzerinde çıkarım yapmak için bellek gereksinimlerini işleyip işleyemeyeceğini gösterebilir. Bazı modeller (özellikle yinelenen sinir ağlarını temel alan modeller) ortaya çıkar ve satır sayısı doğrusal olmayabilecek bir bellek ayak izi sunar. Yüksek bellek gideri olan bir model için çıkarımı satır düzeyinde çalıştırmayı göz önünde bulundurun.
İpucu
Daha iyi paralelleştirmeyi hesaba katmak için dosyaları aynı anda okunamayacak kadar büyük olan birden çok küçük dosyaya ayırmayı göz önünde bulundurun.
Bunun nasıl yapılacağını öğrenmek için Toplu dağıtımlarla görüntü işleme'yi ziyaret edin. Bu örnek bir dosyayı bir kerede işler.
Satır düzeyi (tablosal)
Giriş boyutlarıyla ilgili güçlükler sunan modeller için çıkarımı satır düzeyinde çalıştırmak isteyebilirsiniz. Toplu dağıtımınız yine de puanlama betiğinizi bir dizi dosyayla birlikte sağlar. Ancak, tek seferde bir dosya, bir satır okuyacaksınız. Bu verimsiz görünebilir, ancak bazı derin öğrenme modelleri için donanım kaynaklarınızın ölçeğini artırmadan çıkarım gerçekleştirmenin tek yolu bu olabilir.
Bunun nasıl yapılacağını öğrenmek için Toplu dağıtımlarla metin işleme'yi ziyaret edin. Bu örnek bir kerede bir satırı işler.
Klasör olan modelleri kullanma
Ortam AZUREML_MODEL_DIR değişkeni seçilen model konumunun yolunu içerir ve init() işlev genellikle modeli belleğe yüklemek için bu yolu kullanır. Ancak, bazı modeller dosyalarını bir klasörde içerebilir ve bunları yüklerken bunu hesaba eklemeniz gerekebilir. Modelinizin klasör yapısını burada gösterildiği gibi tanımlayabilirsiniz:
Modeller bölümüne gidin.
Dağıtmak istediğiniz modeli seçin ve Yapıtlar sekmesini seçin.
Görüntülenen klasörü not edin. Bu klasör, model kaydedildiğinde belirtildi.
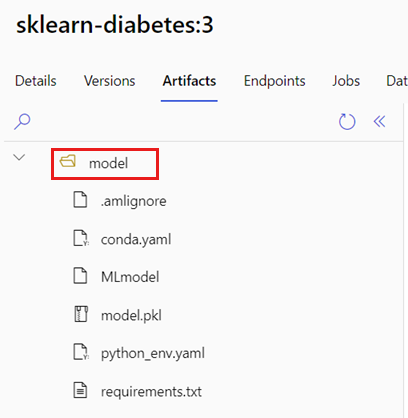

Modeli yüklemek için şu yolu kullanın:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)