Makine öğrenmesi işlem hatlarının sorunlarını giderme
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu makalede, Azure Machine Learning SDK'sında ve Azure Machine Learning tasarımcısında bir makine öğrenmesi işlem hattını çalıştırırken hata aldığınızda nasıl sorun gidereceğinizi öğreneceksiniz.
Sorun giderme ipuçları
Aşağıdaki tablo işlem hattı geliştirmesi sırasındaki yaygın sorunları ve olası çözümleri içerir.
| Sorun | Olası çözüm |
|---|---|
PipelineData dizinine veri geçirilemedi |
Betikte işlem hattınızın adım çıkış verilerini beklediği konuma karşılık gelen bir dizin oluşturduğunuzdan emin olun. Çoğu durumda, giriş bağımsız değişkeni çıkış dizinini tanımlar ve sonra dizini açıkça oluşturursunuz. Çıkış dizinini oluşturmak için os.makedirs(args.output_dir, exist_ok=True) kullanın. Bu tasarım desenini gösteren puanlama betiği örneği için öğreticiye bakın. |
| Bağımlılık hataları | Uzak işlem hattınızda yerel olarak test sırasında gerçekleşmeyen bağımlılık hataları görürseniz, uzak ortam bağımlılıklarınızın ve sürümlerinizin test ortamınızdakilerle eşleşip eşleşmediğini onaylayın. (Bkz. Ortam oluşturma, önbelleğe alma ve yeniden kullanma |
| İşlem hedefleriyle ilgili belirsiz hatalar | İşlem hedeflerini silmeyi ve yeniden oluşturmayı deneyin. İşlem hedefleri hızla yeniden oluşturulabilir ve bu yöntemle bazı geçici sorunlar çözülebilir. |
| İşlem hattı adımları yeniden kullanmıyor | Adımı yeniden kullanma özelliği varsayılan olarak etkinleştirilir ama bir işlem hattı adımında bu özelliği devre dışı bırakmadığınızdan emin olun. Yeniden kullanım devre dışı bırakılırsa, allow_reuse adımdaki parametre olarak Falseayarlanır. |
| İşlem hattı gereksiz şekilde yeniden çalıştırılıyor | Adımların yalnızca temel verileri veya betikleri değiştiğinde yeniden çalıştırılmasını sağlamak için, her adım için kaynak kod dizinlerinizi ayırın. Aynı kaynak dizini birden fazla adımda kullanırsanız gereksiz yeniden çalıştırmalarla karşılaşabilirsiniz. İşlem hattı adımı nesnesinde parametresini source_directory kullanarak bu adım için yalıtılmış dizininize işaret edin ve birden çok adım için aynı source_directory yolu kullanmadığınızdan emin olun. |
| Eğitim dönemlerinde veya diğer döngü davranışlarında adım yavaşlıyor | Günlüğe kaydetme de dahil olmak üzere tüm dosya yazma işlemlerini as_mount() ayarından as_upload() ayarına geçirmeyi deneyin. Bağlama modu bir uzak sanallaştırılmış dosya sistemi kullanır ve her eklenişinde dosyanın tamamını karşıya yükler. |
| İşlem hedefinin başlatılması uzun sürüyor | İşlem hedefleri için Docker görüntüleri Azure Container Registry'den (ACR) yüklenir. Azure Machine Learning varsayılan olarak temel hizmet katmanını kullanan bir ACR oluşturur. Çalışma alanınızın ACR'sini standart veya premium katmana geçirmek, görüntüleri oluşturma ve yükleme süresini kısaltabilir. Daha fazla bilgi için bkz. Azure Container Registry hizmet katmanları. |
Kimlik Doğrulama hataları
Uzak bir işten işlem hedefi üzerinde bir yönetim işlemi gerçekleştirirseniz aşağıdaki hatalardan birini alırsınız:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Örneğin, uzaktan yürütme için gönderilen bir ML İşlem Hattından işlem hedefi oluşturmaya veya eklemeye çalışırsanız bir hata alırsınız.
Sorun giderme ParallelRunStep
için ParallelRunStep betik iki işlev içermelidir :
init(): Bu işlevi, daha sonraki çıkarımlar için herhangi bir maliyetli veya ortak hazırlık için kullanın. Örneğin, modeli genel bir nesneye yüklemek için kullanın. Bu işlev, işlemin başlangıcında yalnızca bir kez çağrılır.run(mini_batch): İşlev hermini_batchörnek için çalışır.mini_batch:ParallelRunSteprun yöntemini çağırır ve yönteme bağımsız değişken olarak bir liste veya pandasDataFramegeçirir. mini_batch'deki her girdi, girişFileDatasetbir ise bir dosya yolu veya giriş iseTabularDatasetbir pandas'dırDataFrame.response: run() yöntemi bir pandasDataFrameveya dizi döndürmelidir. append_row output_action için, döndürülen bu öğeler ortak çıkış dosyasına eklenir. summary_only için öğelerin içeriği yoksayılır. Tüm çıkış eylemleri için, döndürülen her çıkış öğesi giriş mini toplu işleminde başarılı bir giriş öğesi çalıştırmasını gösterir. Çıktı sonucunu çalıştırmak için girişi eşlemek için çalıştırma sonucuna yeterli verinin eklendiğinden emin olun. Çalıştırma çıkışı çıkış dosyasına yazılır ve sıralı olması garanti edilmediğinden, çıkıştaki bir anahtarı kullanarak girişe eşlemeniz gerekir.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Çıkarım betiğinizle aynı dizinde başka bir dosya veya klasörünüz varsa, geçerli çalışma dizinini bularak bu dosyaya başvurabilirsiniz.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
ParallelRunConfig parametreleri
ParallelRunConfig , Azure Machine Learning işlem hattı içindeki temel yapılandırmadır ParallelRunStep . Betiğinizi sarmak ve aşağıdaki girdilerin tümü de dahil olmak üzere gerekli parametreleri yapılandırmak için bunu kullanırsınız:
entry_script: Birden çok düğümde paralel olarak çalıştırılacak yerel dosya yolu olarak bir kullanıcı betiği. Varsasource_directorygöreli bir yol kullanın. Aksi takdirde, makinede erişilebilen herhangi bir yolu kullanın.mini_batch_size: Tekrun()bir çağrıya geçirilen mini toplu iş boyutu. (isteğe bağlı; varsayılan değer ve1MBiçinFileDatasetTabularDatasetdosyalardır10.)- için
FileDataset, en az değerine sahip dosya sayısıdır1. Birden çok dosyayı tek bir mini toplu işlemde birleştirebilirsiniz. - için
TabularDataset, verilerin boyutuna göre belirlenir. Örnek değerler :1024,1024KB,10MBve1GB. Önerilen değerdir1MB. 'denTabularDatasetmini toplu işlem hiçbir zaman dosya sınırlarını aşmaz. Örneğin, çeşitli boyutlarda .csv dosyalarınız varsa, en küçük dosya 100 KB ve en büyük dosya 10 MB'tır. ayarlarsanızmini_batch_size = 1MB, boyutu 1 MB'tan küçük olan dosyalar tek bir mini toplu iş olarak değerlendirilir. Boyutu 1 MB'tan büyük dosyalar birden çok mini toplu işleme ayrılır.
- için
error_threshold: ve için kayıt hatalarınınTabularDatasetFileDatasetsayısı işleme sırasında yoksayılmalıdır. Girişin tamamı için hata sayısı bu değerin üzerine çıkarsa, iş durduruldu. Hata eşiği, yönteme gönderilen tek tek mini toplu iş için değil, girişin tamamına yöneliktirrun(). Aralık şeklindedir[-1, int.max]. bölümü,-1işleme sırasındaki tüm hataları yoksaymayı gösterir.output_action: Aşağıdaki değerlerden biri çıkışın nasıl düzenlendiğinden emin olur:summary_only: Kullanıcı betiği çıkışı depolar.ParallelRunStepçıkışı yalnızca hata eşiği hesaplaması için kullanır.append_row: Tüm girişler için, çıkış klasöründe satırla ayrılmış tüm çıkışları eklemek için yalnızca bir dosya oluşturulur.
append_row_file_name: append_row output_action için çıkış dosyası adını özelleştirmek için (isteğe bağlı; varsayılan değer ).parallel_run_step.txtsource_directory: İşlem hedefinde yürütülecek tüm dosyaları içeren klasörlerin yolları (isteğe bağlı).compute_target: YalnızcaAmlComputedesteklenir.node_count: Kullanıcı betiğini çalıştırmak için kullanılacak işlem düğümlerinin sayısı.process_count_per_node: Düğüm başına işlem sayısı. En iyi yöntem, bir düğümün sahip olduğu GPU veya CPU sayısına ayarlamaktır (isteğe bağlı; varsayılan değer olur1).environment: Python ortam tanımı. Mevcut bir Python ortamını kullanmak veya geçici bir ortam ayarlamak için bunu yapılandırabilirsiniz. Tanım ayrıca gerekli uygulama bağımlılıklarını ayarlamakla da sorumludur (isteğe bağlı).logging_level: Günlük ayrıntı düzeyi. Ayrıntı düzeyini artırma değerleri şunlardır:WARNING,INFOveDEBUG. (isteğe bağlı; varsayılan değer )INFOrun_invocation_timeout: Saniyelerrun()içinde yöntem çağırma zaman aşımı. (isteğe bağlı; varsayılan değer )60run_max_try: Mini toplu iş için deneme sayısı üst sınırırun(). Birrun()özel durum oluşturulursa veya ulaşıldığındarun_invocation_timeouthiçbir şey döndürülmezse başarısız olur (isteğe bağlı; varsayılan değer olur3).
bir logging_levelnode_countprocess_count_per_nodeişlem hattı çalıştırmasını yeniden gönderdiğinizde parametre değerlerine ince ayar yapmak için , , run_invocation_timeout, ve run_max_try olarak PipelineParameterbelirtebilirsiniz.mini_batch_size Bu örnekte, ve için mini_batch_size Process_count_per_node kullanırsınız PipelineParameter ve daha sonra bir çalıştırmayı yeniden gönderdiğinizde bu değerleri değiştirirsiniz.
ParallelRunStep oluşturmak için parametreler
Betiği, ortam yapılandırmasını ve parametreleri kullanarak ParallelRunStep'i oluşturun. Çıkarım betiğinizin yürütme hedefi olarak çalışma alanınıza zaten eklediğiniz işlem hedefini belirtin. Aşağıdaki parametrelerin tümünü alan toplu çıkarım işlem hattı adımını oluşturmak için kullanın ParallelRunStep :
name: Aşağıdaki adlandırma kısıtlamalarıyla adımın adı: benzersiz, 3-32 karakter ve regex ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_configParallelRunConfig: Daha önce tanımlandığı gibi bir nesne.inputs: Paralel işleme için bölümlenecek bir veya daha fazla tek tür Azure Machine Learning veri kümesi.side_inputs: Bölümlemeye gerek kalmadan yan giriş olarak kullanılan bir veya daha fazla başvuru verisi veya veri kümesi.outputOutputFileDatasetConfig: Çıkış dizinine karşılık gelen bir nesne.arguments: Kullanıcı betiğine geçirilen bağımsız değişkenlerin listesi. Bunları giriş betiğinizde almak için unknown_args kullanın (isteğe bağlı).allow_reuse: Aynı ayarlar/girişlerle çalıştırıldığında adımın önceki sonuçları yeniden kullanıp kullanmaması. Bu parametre iseFalse, işlem hattı yürütme sırasında bu adım için yeni bir çalıştırma oluşturulur. (isteğe bağlı; varsayılan değer.True)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Hata ayıklama teknikleri
İşlem hatlarına hataları ayıklamak için kullanılabilecek üç ana teknik vardır:
- Yerel bilgisayarınızda tek tek işlem hattı adımlarının hatalarını ayıklama
- Sorunun kaynağını yalıtmak ve tanılamak için günlük ve Application Insights kullanma
- Azure'da çalışan işlem hattına uzaktan hata ayıklayıcı ekleme
Betiklerde yerel olarak hata ayıklama
İşlem hattındaki en yaygın hatalardan biri, etki alanı betiğinin istendiği gibi çalışmaması veya uzak işlem bağlamında hata ayıklaması zor olan çalışma zamanı hataları içermesidir.
İşlem hatları yerel olarak çalıştırılamaz. Ancak betikleri yerel makinenizde yalıtarak çalıştırmak, işlem ve ortam derleme işlemini beklemenize gerek olmadığından daha hızlı hata ayıklamanıza olanak tanır. Bunu yapmak için bazı geliştirme çalışmaları gereklidir:
- Verileriniz bir bulut veri deposundaysa verileri indirmeniz ve betiğinizin kullanımına sunmalısınız. Verilerinizin küçük bir örneğini kullanmak, çalışma zamanını azaltmanın ve betik davranışı hakkında hızla geri bildirim almak için iyi bir yoldur
- Bir ara işlem hattı adımının benzetimini yapmaya çalışıyorsanız, önceki adımda belirli bir betiğin beklediği nesne türlerini el ile oluşturmanız gerekebilir
- Kendi ortamınızı tanımlamanız ve uzak işlem ortamınızda tanımlanan bağımlılıkları çoğaltmanız gerekir
Yerel ortamınızda çalıştırılacak bir betik kurulumunuz olduğunda, şu gibi hata ayıklama görevlerini yapmak daha kolaydır:
- Özel hata ayıklama yapılandırması ekleme
- Yürütmeyi duraklatma ve nesne durumunu inceleme
- Çalışma zamanına kadar kullanıma sunulmayacak tür veya mantıksal hataları yakalama
İpucu
Betiğinizin beklendiği gibi çalıştığını doğruladıktan sonra, betiği birden çok adımda bir işlem hattında çalıştırmayı denemeden önce betiği tek adımlı işlem hattında çalıştırmak iyi bir sonraki adımdır.
İşlem hattı günlüklerini yapılandırma, yazma ve gözden geçirme
Betikleri yerel olarak test etmek, işlem hattı oluşturmaya başlamadan önce ana kod parçalarında ve karmaşık mantıkta hata ayıklamak için harika bir yoldur. Bir noktada, özellikle işlem hattı adımları arasındaki etkileşim sırasında oluşan davranışı tanılarken gerçek işlem hattı çalıştırması sırasında betiklerin hatalarını ayıklamanız gerekir. JavaScript kodunda hata ayıkladığınıza benzer şekilde, uzaktan yürütme sırasında nesne durumunu ve beklenen değerleri görebilmeniz için adım betiklerinizde deyimlerin liberal bir şekilde kullanılmasını print() öneririz.
Günlüğe kaydetme seçenekleri ve davranışı
Aşağıdaki tabloda, işlem hatları için farklı hata ayıklama seçeneklerine yönelik bilgiler sağlanmaktadır. Burada gösterilen Azure Machine Learning, Python ve OpenCensus seçeneklerinin yanı sıra diğer seçenekler de mevcut olduğundan, bu liste kapsamlı bir liste değildir.
| Kitaplık | Tür | Örnek | Hedef | Kaynaklar |
|---|---|---|---|---|
| Azure Machine Learning SDK’sı | Metric | run.log(name, val) |
Azure Machine Learning Portalı Kullanıcı Arabirimi | Denemeleri izleme azureml.core.Run sınıfı |
| Python yazdırma/günlüğe kaydetme | Günlük | print(val)logging.info(message) |
Sürücü günlükleri, Azure Machine Learning tasarımcısı | Denemeleri izleme Python günlüğü |
| OpenCensus Python | Günlük | logger.addHandler(AzureLogHandler())logging.log(message) |
Application Insights - izlemeler | Application Insights’ta işlem hatlarında hata ayıklama OpenCensus Azure İzleyici Dışarı Aktarıcıları Python günlüğü kılavuzu |
Günlük seçenekleri örneği
import logging
from azureml.core.run import Run
from opencensus.ext.azure.log_exporter import AzureLogHandler
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
# Python logging with OpenCensus AzureLogHandler
logger.warning("I am an OpenCensus warning statement, find me in Application Insights!")
logger.error("I am an OpenCensus error statement with custom dimensions", {'step_id': run.id})
Azure Machine Learning tasarımcısı
Tasarımcıda oluşturulan işlem hatları için, 70_driver_log dosyasını yazma sayfasında veya işlem hattı çalıştırma ayrıntıları sayfasında bulabilirsiniz.
Gerçek zamanlı uç noktalar için günlüğe kaydetmeyi etkinleştirme
Tasarımcıda gerçek zamanlı uç noktaların sorunlarını gidermek ve hata ayıklamak için SDK'yı kullanarak Application Insight günlüğünü etkinleştirmeniz gerekir. Günlüğe kaydetme, model dağıtımı ve kullanım sorunlarını gidermenize ve hatalarını ayıklamanıza olanak tanır. Daha fazla bilgi için bkz . Dağıtılan modeller için günlüğe kaydetme.
Yazma sayfasından günlükleri alma
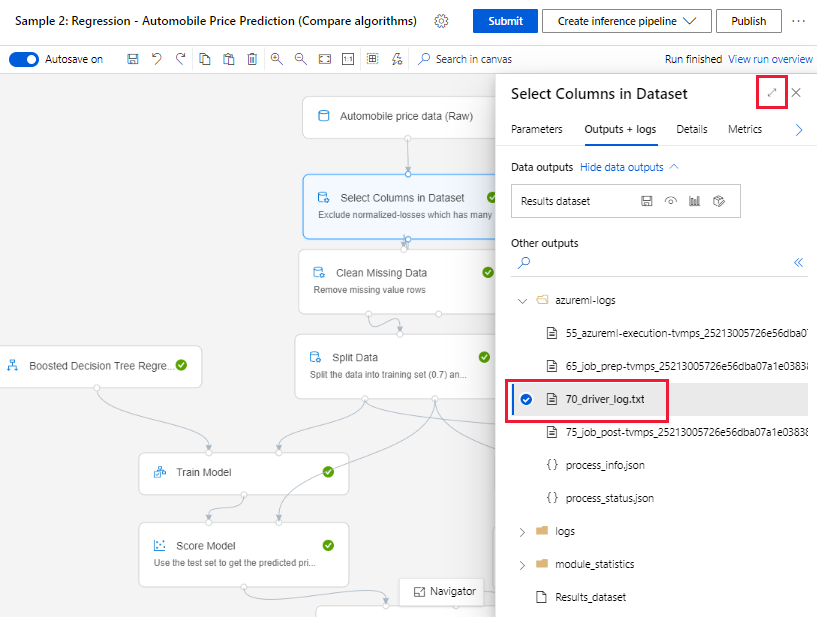
bir işlem hattı çalıştırması gönderdiğinizde ve yazma sayfasında kaldığınızda, her bileşen çalışmaya başladığında her bileşen için oluşturulan günlük dosyalarını bulabilirsiniz.
Yazma tuvalinde çalışması tamamlanmış bir bileşen seçin.
Bileşenin sağ bölmesinde Çıkışlar + günlükler sekmesine gidin.
Sağ bölmeyi genişletin ve dosyayı tarayıcıda görüntülemek için 70_driver_log.txt seçin. Günlükleri yerel olarak da indirebilirsiniz.
İşlem hattı çalıştırmalarından günlükleri alma
Ayrıca, belirli çalıştırmaların günlük dosyalarını, stüdyonun İşlem Hatları veya Denemeler bölümünde bulunan işlem hattı çalıştırma ayrıntıları sayfasında bulabilirsiniz.
Tasarımcıda oluşturulan bir işlem hattı çalıştırmasını seçin.
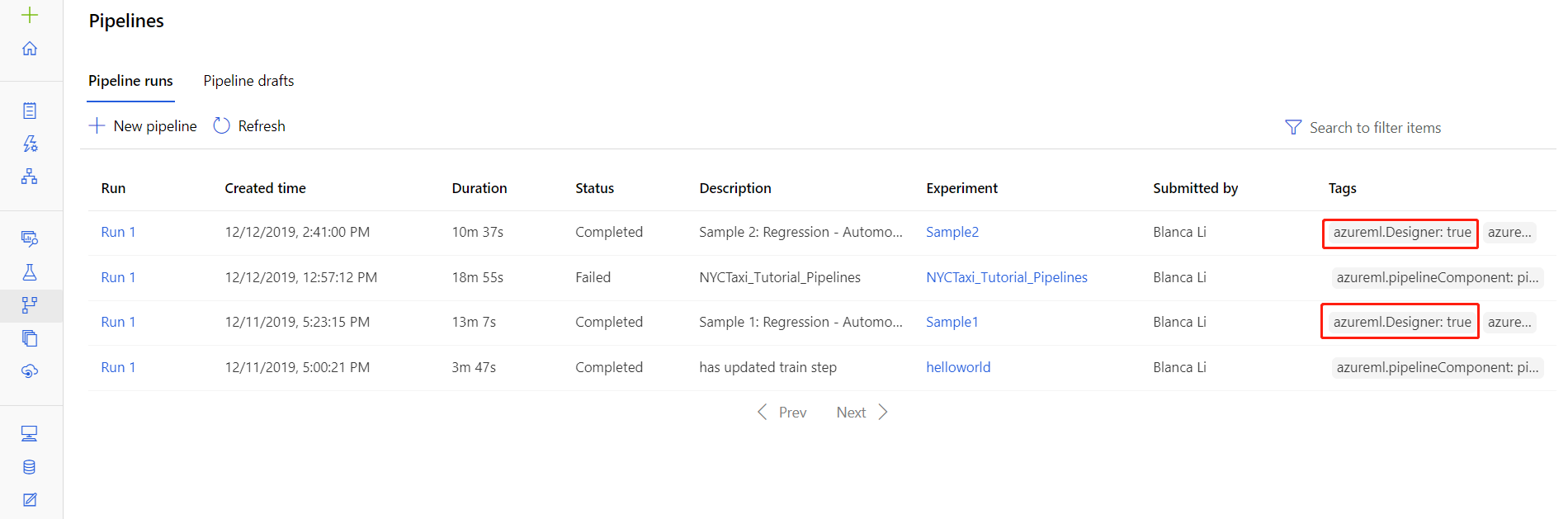
Önizleme bölmesinde bir bileşen seçin.
Bileşenin sağ bölmesinde Çıkışlar + günlükler sekmesine gidin.
std_log.txt dosyasını tarayıcıda görüntülemek için sağ bölmeyi genişletin veya günlükleri yerel olarak indirmek için dosyayı seçin.
Önemli
İşlem hattı çalıştırma ayrıntıları sayfasından bir işlem hattını güncelleştirmek için işlem hattı çalıştırmasını yeni bir işlem hattı taslağına kopyalamanız gerekir. İşlem hattı çalıştırması, işlem hattının anlık görüntüsüdür. Günlük dosyasına benzer ve değiştirilemez.
Application Insights
OpenCensus Python kitaplığını bu şekilde kullanma hakkında daha fazla bilgi için şu kılavuza bakın: Application Insights'ta makine öğrenmesi işlem hatlarında hata ayıklama ve sorun giderme
Visual Studio Code ile etkileşimli hata ayıklama
Bazı durumlarda ML işlem hattınızda kullanılan Python kodunda etkileşimli olarak hata ayıklama işlemi yapmanız gerekebilir. Visual Studio Code (VS Code) ve debugpy kullanarak, eğitim ortamında çalışırken koda ekleyebilirsiniz. Daha fazla bilgi için VS Code'da etkileşimli hata ayıklama kılavuzunu ziyaret edin.
HyperdriveStep ve AutoMLStep ağ yalıtımıyla başarısız oldu
HyperdriveStep ve AutoMLStep'i kullandıktan sonra modeli kaydetmeye çalıştığınızda bir hata alabilirsiniz.
Azure Machine Learning SDK v1 kullanıyorsunuz.
Azure Machine Learning çalışma alanınız ağ yalıtımı (VNet) için yapılandırılmıştır.
İşlem hattınız önceki adım tarafından oluşturulan modeli kaydetmeye çalışır. Örneğin, aşağıdaki örnekte
inputsparametresi Bir HyperdriveStep'ten saved_model:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Geçici çözüm
Önemli
Azure Machine Learning SDK v2 kullanılırken bu davranış oluşmaz.
Bu hataya geçici bir çözüm olarak, HyperdriveStep veya AutoMLStep'ten oluşturulan modeli almak için Run sınıfını kullanın. Aşağıda bir HyperdriveStep'ten çıkış modelini alan örnek bir betik verilmiştir:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Dosya daha sonra PythonScriptStep'ten kullanılabilir:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Sonraki adımlar
kullanarak
ParallelRunStepeksiksiz bir öğretici için bkz . Öğretici: Toplu puanlama için Azure Machine Learning işlem hattı oluşturma.ML işlem hatlarında otomatik makine öğrenmesini gösteren eksiksiz bir örnek için bkz . Python'da Azure Machine Learning işlem hattında otomatik ML kullanma.
azureml-pipelines-core paketi ve azureml-pipelines-steps paketiyle ilgili yardım için SDK başvurusuna bakın.
Tasarımcı özel durumları ve hata kodları listesine bakın.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin