MLflow modellerini çevrimiçi uç noktalara dağıtma
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)
Bu makalede, gerçek zamanlı çıkarım için MLflow modelinizi çevrimiçi bir uç noktaya dağıtmayı öğrenin. MLflow modelinizi çevrimiçi bir uç noktaya dağıtırken puanlama betiği veya ortam belirtmeniz gerekmez; bu işlev kod içermeyen dağıtım olarak bilinir.
Kod içermeyen dağıtım için Azure Machine Learning:
- Dosyada
conda.yamlsağlanan Python paketlerini dinamik olarak yükler. Bu nedenle, bağımlılıklar kapsayıcı çalışma zamanı sırasında yüklenir. - Aşağıdaki öğeleri içeren bir MLflow temel görüntüsü/seçilmiş ortam sağlar:
azureml-inference-server-httpmlflow-skinny- Çıkarım için puanlama betiği.
İpucu
Genel ağ erişimi olmayan çalışma alanları: Çıkış bağlantısı olmadan MLflow modellerini çevrimiçi uç noktalara dağıtabilmeniz için önce modelleri paketlemeniz (önizleme) gerekir. Model paketlemeyi kullanarak, Azure Machine Learning'in MLflow modelleri için gerekli Python paketlerini dinamik olarak yüklemesini gerektireceği bir İnternet bağlantısı gereksiniminden kaçınabilirsiniz.
Örnek hakkında
Örnek, tahmin gerçekleştirmek için bir MLflow modelini çevrimiçi uç noktaya nasıl dağıtabileceğinizi gösterir. Örnek, Diabetes veri kümesini temel alan bir MLflow modeli kullanır. Bu veri kümesi 10 temel değişken içerir: yaş, cinsiyet, vücut kitle dizini, ortalama kan basıncı ve 442 diyabet hastasından elde edilen altı kan serumu ölçümü. Ayrıca, temelden bir yıl sonra hastalığın ilerlemesinin nicel bir ölçüsü olan ilginin yanıtını içerir.
Model bir scikit-learn regresör kullanılarak eğitildi ve gerekli tüm ön işleme bir işlem hattı olarak paketlendi ve bu modeli ham verilerden tahminlere giden uçtan uca bir işlem hattı haline getirdi.
Bu makaledeki bilgiler, azureml-examples deposunda yer alan kod örneklerini temel alır. YAML ve diğer dosyaları kopyalamak/yapıştırmak zorunda kalmadan komutları yerel olarak çalıştırmak için depoyu kopyalayın ve ardından Azure CLI kullanıyorsanız dizinleri olarak clideğiştirin. Python için Azure Machine Learning SDK'sını kullanıyorsanız dizinleri olarak sdk/python/endpoints/online/mlflowdeğiştirin.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Jupyter Notebook'ta takip edin
Kopyalanan depoda MLflow modelini çevrimiçi uç noktalara dağıtma not defterini açarak Azure Machine Learning Python SDK'sını kullanma adımlarını izleyebilirsiniz.
Önkoşullar
Bu makaledeki adımları takip etmeden önce aşağıdaki önkoşullara sahip olduğunuzdan emin olun:
Azure aboneliği. Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun. Azure Machine Learning'in ücretsiz veya ücretli sürümünü deneyin.
Azure Machine Learning’deki işlemlere erişim vermek için Azure rol tabanlı erişim denetimleri (Azure RBAC) kullanılır. Bu makaledeki adımları gerçekleştirmek için kullanıcı hesabınıza Azure Machine Learning çalışma alanı için sahip veya katkıda bulunan rolü ya da izin veren
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*özel bir rol atanmalıdır. Roller hakkında daha fazla bilgi için bkz . Azure Machine Learning çalışma alanına erişimi yönetme.Çalışma alanınızda kayıtlı bir MLflow modeli olmalıdır. Bu makalede, çalışma alanındaki Diabetes veri kümesi için eğitilmiş bir model kaydedilir.
Ayrıca şunları yapmanız gerekir:
- Azure CLI'yi ve
mlAzure CLI uzantısını yükleyin. CLI'yı yükleme hakkında daha fazla bilgi için bkz . CLI'yi (v2) yükleme ve ayarlama.
- Azure CLI'yi ve
Çalışma alanınıza bağlanma
İlk olarak, çalışacağınız Azure Machine Learning çalışma alanına bağlanın.
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Modeli kaydedin
Yalnızca kayıtlı modelleri çevrimiçi uç noktalara dağıtabilirsiniz. Bu durumda, depoda modelin yerel bir kopyası zaten vardır, bu nedenle modeli yalnızca çalışma alanında kayıt defterinde yayımlamanız gerekir. Dağıtmaya çalıştığınız model zaten kayıtlıysa bu adımı atlayabilirsiniz.
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

Modeliniz çalıştırmanın içinde günlüğe kaydedildiyse ne olur?
Modeliniz bir çalıştırmanın içinde günlüğe kaydedildiyse doğrudan kaydedebilirsiniz.
Modeli kaydetmek için depolandığı konumu bilmeniz gerekir. MLflow'un autolog özelliğini kullanıyorsanız modelin yolu model türüne ve çerçevesine bağlıdır. Modelin klasörünün adını belirlemek için işlerin çıkışını denetlemeniz gerekir. Bu klasör adlı MLModelbir dosya içerir.
Modellerinizi el ile günlüğe kaydetmek için yöntemini kullanıyorsanız log_model , yöntemin bağımsız değişkeni olarak modelin yolunu geçirin. Örneğin, kullanarak modeli günlüğe kaydederseniz, mlflow.sklearn.log_model(my_model, "classifier")modelin depolandığı yol olarak adlandırılır classifier.
Eğitim işi çıkışından model oluşturmak için Azure Machine Learning CLI v2'yi kullanın. Aşağıdaki örnekte, adlı $MODEL_NAME model kimliğine $RUN_IDsahip bir işin yapıtları kullanılarak kaydedilir. Modelin depolandığı yol şeklindedir $MODEL_PATH.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH
Not
Yol $MODEL_PATH , modelin çalıştırmada depolandığı konumdur.

Çevrimiçi uç noktaya MLflow modeli dağıtma
Modelin dağıtılacağı uç noktayı yapılandırın. Aşağıdaki örnekte uç noktanın adı ve kimlik doğrulama modu yapılandırılır:
Aşağıdaki komutu çalıştırarak bir uç nokta adı ayarlayın (değerini benzersiz bir adla değiştirin
YOUR_ENDPOINT_NAME):export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Uç noktayı yapılandırın:
create-endpoint.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: keyUç noktayı oluşturun:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yamlDağıtımı yapılandırın. Dağıtım, gerçek çıkarım yapan modeli barındırmak için gereken bir kaynak kümesidir.
sklearn-deployment.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 1 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Not
ve
environmentöğesinin otomatik olarak yenilenmesiscoring_scriptyalnızca model aroması içinpyfuncdesteklenir. Farklı bir model türü kullanmak için bkz . MLflow modeli dağıtımlarını özelleştirme.Dağıtımı oluşturun:
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficUç noktanızın çıkış bağlantısı yoksa, bayrağını
--with-packageekleyerek model paketlemeyi (önizleme) kullanın:az ml online-deployment create --with-package --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficTüm trafiği dağıtıma atayın. Şu ana kadar uç noktanın tek bir dağıtımı var, ancak trafiğinden hiçbiri bu dağıtıma atanmadı.
Oluşturma sırasında bayrağını kullandığınızdan
--all-traffic, içinde bu adım Azure CLI'da gerekli değildir. Trafiği değiştirmeniz gerekiyorsa komutunuaz ml online-endpoint update --traffickullanabilirsiniz. Trafiği güncelleştirme hakkında daha fazla bilgi için bkz . Trafiği aşamalı olarak güncelleştirme.Uç nokta yapılandırmasını güncelleştirin:
Oluşturma sırasında bayrağını kullandığınızdan
--all-traffic, içinde bu adım Azure CLI'da gerekli değildir. Trafiği değiştirmeniz gerekiyorsa komutunuaz ml online-endpoint update --traffickullanabilirsiniz. Trafiği güncelleştirme hakkında daha fazla bilgi için bkz . Trafiği aşamalı olarak güncelleştirme.


Uç noktayı çağırma
Dağıtımınız hazır olduktan sonra isteği sunmak için bunu kullanabilirsiniz. Dağıtımı test etmenin bir yolu, kullandığınız dağıtım istemcisindeki yerleşik çağırma özelliğini kullanmaktır. Aşağıdaki JSON, dağıtım için örnek bir istektir.
sample-request-sklearn.json
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Not
input_data , MLflow sunmada bunun yerine inputs bu örnekte kullanılır. Bunun nedeni, Azure Machine Learning'in uç noktalar için swagger sözleşmelerini otomatik olarak oluşturabilmesi için farklı bir giriş biçimi gerektirmesidir. Beklenen giriş biçimleri hakkında daha fazla bilgi için bkz . Azure Machine Learning'de dağıtılan modeller ile MLflow yerleşik sunucusu arasındaki farklar.
Uç noktaya aşağıdaki gibi bir istek gönderin:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
Yanıt aşağıdaki metne benzer olacaktır:
[
11633.100167144921,
8522.117402884991
]
Önemli
MLflow no-code dağıtımı için yerel uç noktalar üzerinden test şu anda desteklenmemektedir.
MLflow modeli dağıtımlarını özelleştirme
MLflow modelinin dağıtım tanımında çevrimiçi uç noktaya puanlama betiği belirtmeniz gerekmez. Ancak bunu yapmayı tercih edebilir ve çıkarımların nasıl yürütüleceğini özelleştirebilirsiniz.
Genellikle aşağıdaki durumlarda MLflow modeli dağıtımınızı özelleştirmek istersiniz:
- Modelin üzerinde bir
PyFuncçeşit yoktur. - Örneğin, kullanarak modeli yüklemek için belirli bir çeşit kullanmak için modelin
mlflow.<flavor>.load_model()çalışma şeklini özelleştirmeniz gerekir. - Modelin kendisi tarafından yapılmadığında puanlama yordamınızda ön/son işlem yapmanız gerekir.
- Modelin çıkışı tablosal verilerde düzgün bir şekilde temsil edilemiyor. Örneğin, bir görüntüyü temsil eden bir tensor.
Önemli
MLflow modeli dağıtımı için puanlama betiği belirtmeyi seçerseniz, dağıtımın çalıştırılacağı ortamı da belirtmeniz gerekir.
Adımlar
Özel puanlama betiğiyle bir MLflow modeli dağıtmak için:
MLflow modelinizin bulunduğu klasörü tanımlayın.
a. Azure Machine Learning stüdyosu gidin.
b. Modeller bölümüne gidin.
c. Dağıtmaya çalıştığınız modeli seçin ve Yapıtlar sekmesine gidin.
d. Görüntülenen klasörü not alın. Model kaydedildiğinde bu klasör belirtildi.
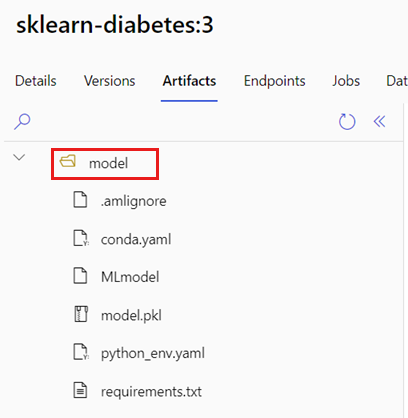
Puanlama betiği oluşturun. Daha önce tanımladığınız klasör adının
modelişleveinit()nasıl dahil olduğuna dikkat edin.İpucu
Aşağıdaki puanlama betiği, MLflow modeliyle çıkarım gerçekleştirme hakkında bir örnek olarak verilmiştir. Bu betiği ihtiyaçlarınıza uyarlayabilir veya senaryonuzu yansıtacak şekilde bölümlerini değiştirebilirsiniz.
score.py
import logging import os import json import mlflow from io import StringIO from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json def init(): global model global input_schema # "model" is the path of the mlflow artifacts when the model was registered. For automl # models, this is generally "mlflow-model". model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model") model = mlflow.pyfunc.load_model(model_path) input_schema = model.metadata.get_input_schema() def run(raw_data): json_data = json.loads(raw_data) if "input_data" not in json_data.keys(): raise Exception("Request must contain a top level key named 'input_data'") serving_input = json.dumps(json_data["input_data"]) data = infer_and_parse_json_input(serving_input, input_schema) predictions = model.predict(data) result = StringIO() predictions_to_json(predictions, result) return result.getvalue()Uyarı
MLflow 2.0 önerisi: Sağlanan puanlama betiği hem MLflow 1.X hem de MLflow 2.X ile çalışır. Ancak, bu sürümlerde beklenen giriş/çıkış biçimlerinin farklılık gösterebileceğini unutmayın. Beklenen MLflow sürümünü kullandığınızdan emin olmak için kullanılan ortam tanımını denetleyin. MLflow 2.0'ın yalnızca Python 3.8+'da desteklendiğine dikkat edin.
Puanlama betiğinin yürütülebileceği bir ortam oluşturun. Model bir MLflow modeli olduğundan, conda gereksinimleri de model paketinde belirtilir. MLflow modelinde yer alan dosyalar hakkında daha fazla ayrıntı için bkz . MLmodel biçimi. Ardından, dosyadaki conda bağımlılıklarını kullanarak ortamı oluşturacaksınız. Ancak, Azure Machine Learning'deki çevrimiçi dağıtımlar için gerekli olan paketini
azureml-inference-server-httpde eklemeniz gerekir.Conda tanım dosyası aşağıdaki gibidir:
conda.yml
channels: - conda-forge dependencies: - python=3.9 - pip - pip: - mlflow - scikit-learn==1.2.2 - cloudpickle==2.2.1 - psutil==5.9.4 - pandas==2.0.0 - azureml-inference-server-http name: mlflow-envNot
Paket
azureml-inference-server-httpözgün conda bağımlılıkları dosyasına eklendi.Ortamı oluşturmak için bu conda bağımlılıkları dosyasını kullanacaksınız:
Ortam, dağıtım yapılandırmasında satır içinde oluşturulur.
Dağıtımı oluşturun:
Deployment.yml bir dağıtım yapılandırma dosyası oluşturun:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-diabetes-custom endpoint_name: my-endpoint model: azureml:sklearn-diabetes@latest environment: image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04 conda_file: sklearn-diabetes/environment/conda.yml code_configuration: code: sklearn-diabetes/src scoring_script: score.py instance_type: Standard_F2s_v2 instance_count: 1Dağıtımı oluşturun:
az ml online-deployment create -f deployment.ymlDağıtımınız tamamlandıktan sonra isteklere hizmet etmeye hazır olur. Dağıtımı test etmenin bir yolu, yöntemiyle birlikte örnek bir istek dosyası kullanmaktır
invoke.sample-request-sklearn.json
{"input_data": { "columns": [ "age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6" ], "data": [ [ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ], [ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0] ], "index": [0,1] }}Uç noktaya aşağıdaki gibi bir istek gönderin:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.jsonYanıt aşağıdaki metne benzer olacaktır:
{ "predictions": [ 11633.100167144921, 8522.117402884991 ] }Uyarı
MLflow 2.0 önerisi: MLflow 1.X'te
predictionsanahtar eksik olacaktır.



Kaynakları temizleme
Uç noktayı kullanmayı bitirdikten sonra ilişkili kaynaklarını silin:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes
İlgili içerik
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin