Otomatik ML modeli için eğitim kodunu görüntüleme
Bu makalede, otomatik makine öğrenmesi tarafından eğitilen herhangi bir modelden oluşturulan eğitim kodunu görüntülemeyi öğreneceksiniz.
Otomatik ML tarafından eğitilen modeller için kod oluşturma, otomatik ML'nin modeli eğitmek ve belirli bir çalıştırma için derlemek için kullandığı aşağıdaki ayrıntıları görmenize olanak tanır.
- Veri ön işleme
- Algoritma seçimi
- Özellik geliştirme
- Hiper Parametreler
Ml tarafından eğitilen herhangi bir otomatikleştirilmiş modeli seçebilir, önerilen veya alt çalıştırmayı seçebilir ve bu modeli oluşturan oluşturulan Python eğitim kodunu görüntüleyebilirsiniz.
Oluşturulan modelin eğitim koduyla,
- Model algoritmasının hangi özellik kazandırma işlemini ve hiper parametreleri kullandığını öğrenin .
- Eğitilen modelleri izleme/sürüm/denetim . Üretime dağıtılacak modelle hangi eğitim kodunun kullanıldığını izlemek için sürümlenmiş kodu depolayın.
- Hiper parametreleri değiştirerek veya ML ve algoritma becerilerinizi/deneyiminizi uygulayarak eğitim kodunu özelleştirin ve özelleştirilmiş kodunuzla yeni bir modeli yeniden eğitin.
Aşağıdaki diyagramda, tüm görev türleriyle otomatik ML denemeleri için kod oluşturabileceğiniz gösterilmektedir. İlk olarak bir model seçin. Seçtiğiniz model vurgulanır, ardından Azure Machine Learning modeli oluşturmak için kullanılan kod dosyalarını kopyalar ve bunları not defterleri paylaşılan klasörünüzde görüntüler. Buradan kodu gerektiği gibi görüntüleyebilir ve özelleştirebilirsiniz.
Önkoşullar
Azure Machine Learning çalışma alanı. Çalışma alanını oluşturmak için bkz . Çalışma alanı kaynakları oluşturma.
Bu makalede, otomatik makine öğrenmesi denemesi ayarlama konusunda biraz bilgi sahibi olduğunuz varsayılır. Ana otomatik makine öğrenmesi denemesi tasarım desenlerini görmek için öğreticiyi veya nasıl yapılır adımlarını izleyin.
Otomatik ML kod oluşturma yalnızca uzak Azure Machine Learning işlem hedeflerinde çalıştırılacak denemeler için kullanılabilir. Yerel çalıştırmalar için kod oluşturma desteklenmez.
Azure Machine Learning stüdyosu, SDKv2 veya CLIv2 aracılığıyla tetiklenen tüm otomatik ML çalıştırmalarında kod oluşturma etkinleştirilir.
Oluşturulan kod ve model yapıtlarını alma
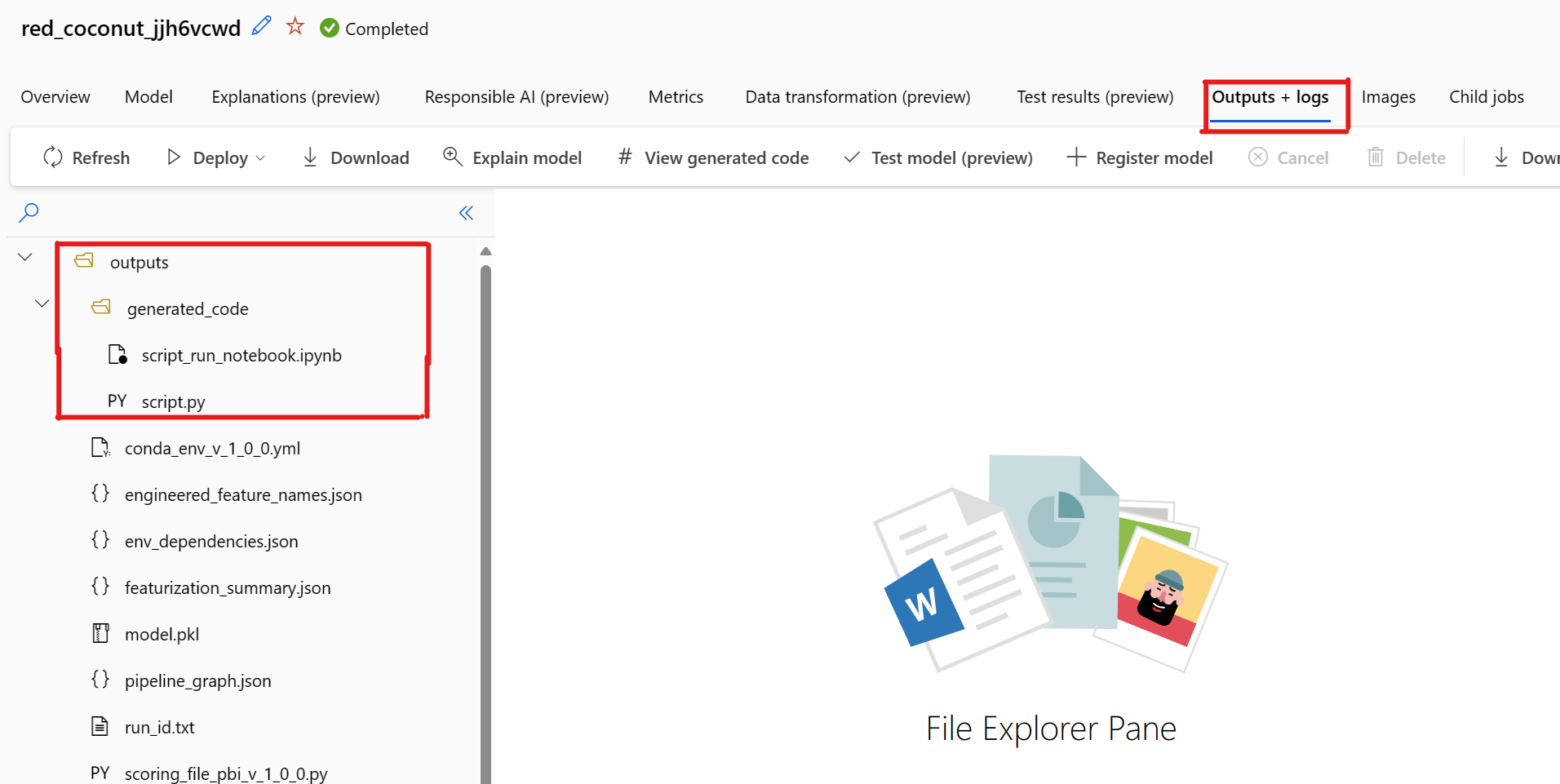
Varsayılan olarak, otomatik ml ile eğitilen her model eğitim tamamlandıktan sonra eğitim kodunu oluşturur. Otomatik ML, bu kodu söz konusu modele yönelik denemelere outputs/generated_code kaydeder. Bunları seçili modelin Çıkışlar + günlükler sekmesindeki Azure Machine Learning stüdyosu kullanıcı arabiriminde görüntüleyebilirsiniz.
script.py Özellik geliştirme adımları, kullanılan belirli algoritma ve hiper parametrelerle analiz etmek isteyebileceğiniz modelin eğitim kodudur.
Modelin eğitim kodunu (script.py) Azure Machine Learning SDKv2 aracılığıyla Azure Machine Learning'de çalıştırmak için kazan plaka koduyla script_run_notebook.ipynb Not Defteri.
Otomatik ML eğitim çalıştırması tamamlandıktan sonra ve dosyalarına script.pyscript_run_notebook.ipynb Azure Machine Learning stüdyosu kullanıcı arabirimi aracılığıyla erişebilirsiniz.
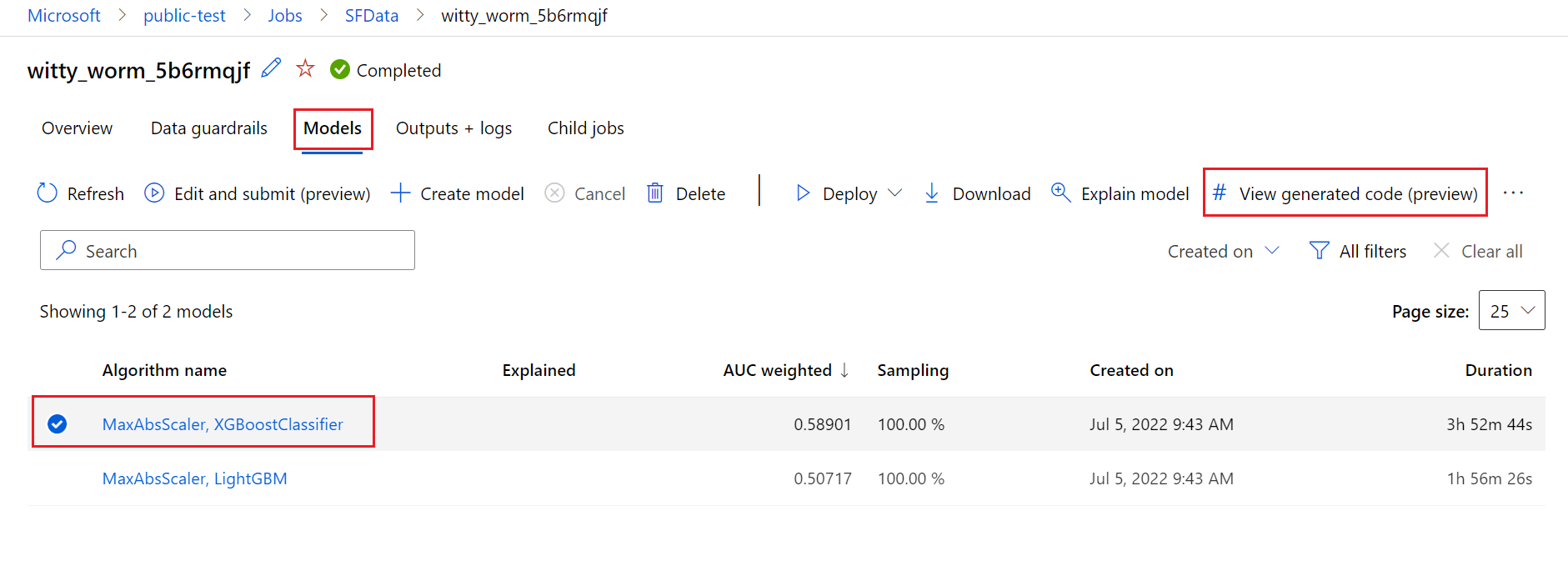
Bunu yapmak için otomatik ML denemesi üst çalıştırmasının sayfasının Modeller sekmesine gidin. Eğitilen modellerden birini seçtikten sonra Oluşturulan kodu görüntüle düğmesini seçebilirsiniz. Bu düğme sizi Not Defterleri portalı uzantısına yönlendirir; burada seçili model için oluşturulan kodu görüntüleyebilir, düzenleyebilir ve çalıştırabilirsiniz.
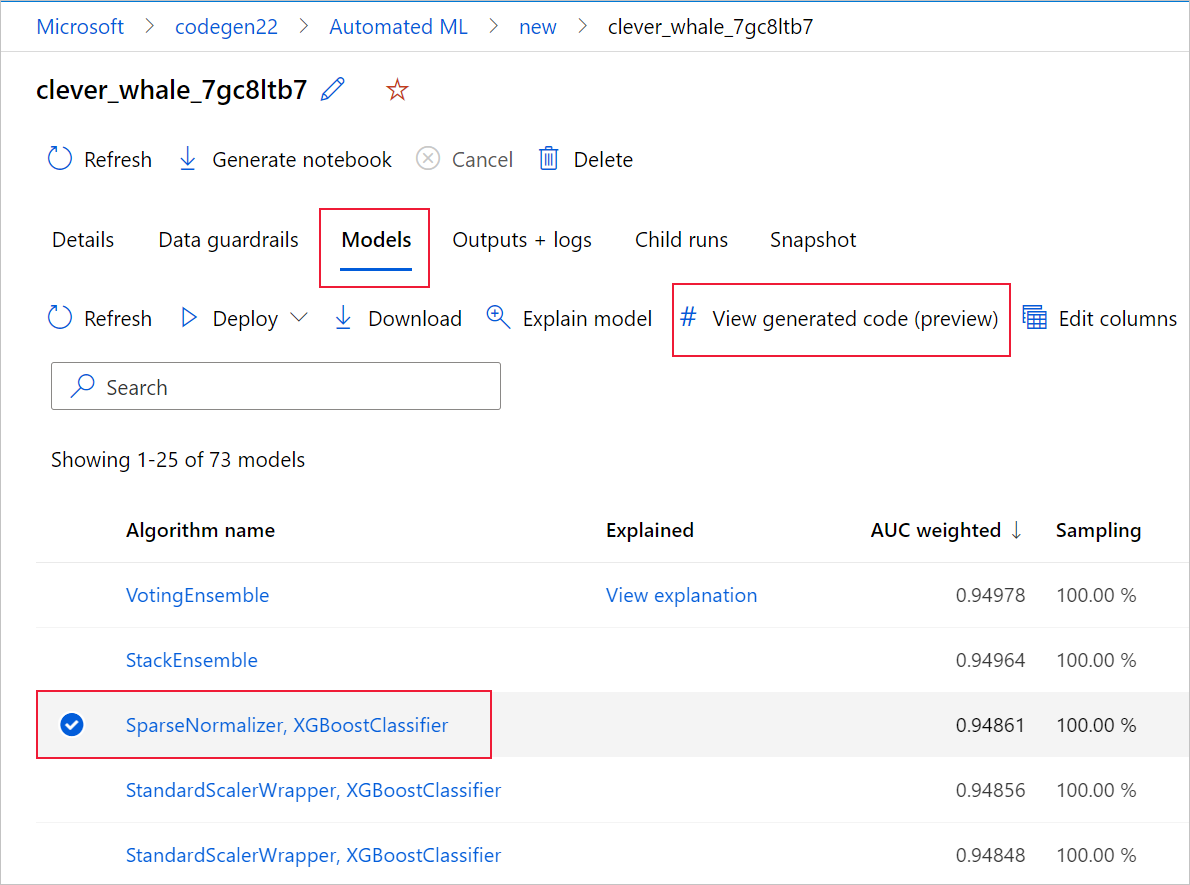
Modelin oluşturduğu koda, belirli bir modelin alt çalıştırmasının sayfasına girdikten sonra alt çalıştırma sayfasının üst kısmından da erişebilirsiniz.
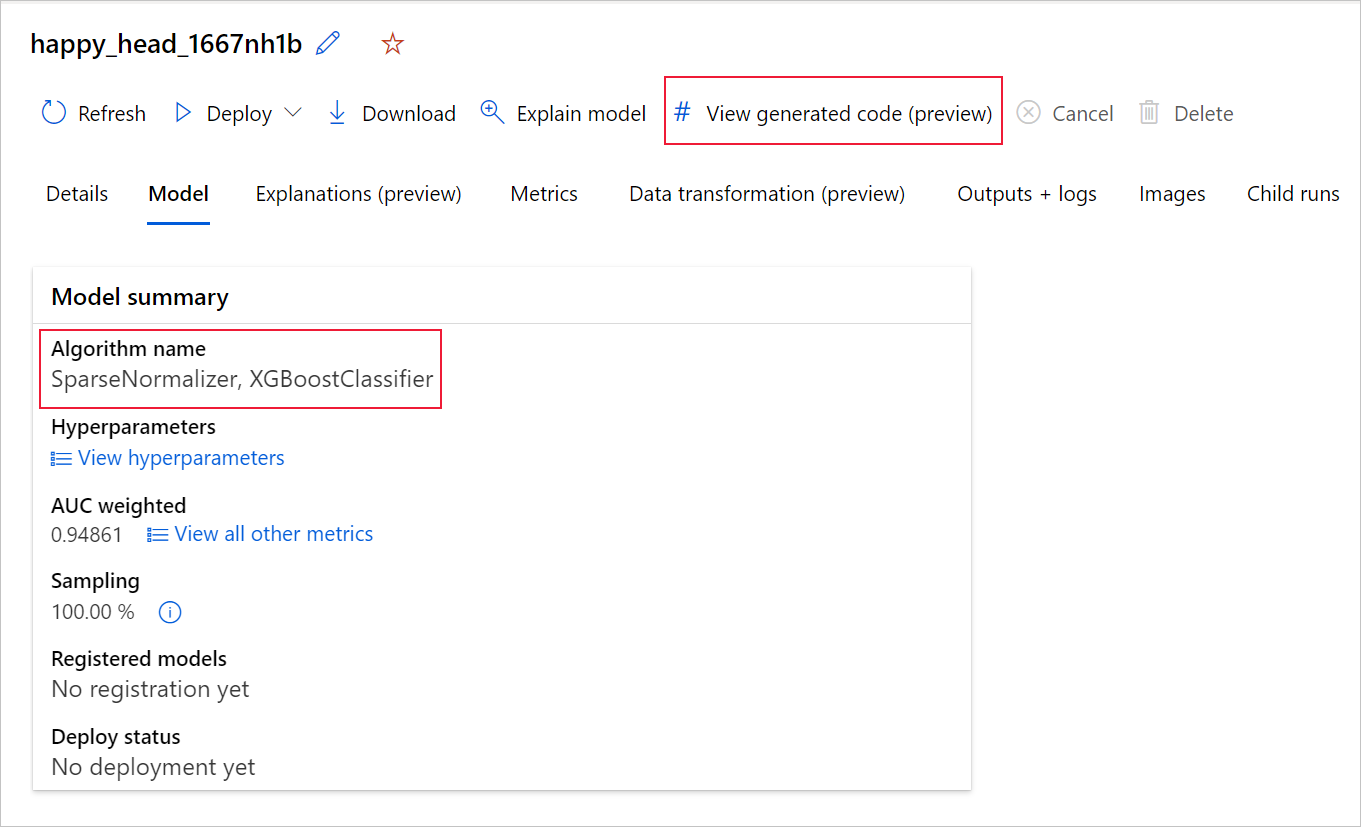
Python SDKv2 kullanıyorsanız MLFlow aracılığıyla en iyi çalıştırmayı alıp elde edilen yapıtları indirerek "script.py" ve "script_run_notebook.ipynb" değerlerini de indirebilirsiniz.
Sınırlamalar
Oluşturulan Kodu Görüntüle'yi seçerken bilinen bir sorun vardır. Depolama bir sanal ağın arkasında olduğunda bu eylem Not Defterleri portalına yeniden yönlendirilemiyor. Geçici bir çözüm olarak, kullanıcı çıkışlar generated_code klasörünün altındaki >Çıkışlar + Günlükler sekmesine giderek script.py ve script_run_notebook.ipynb dosyalarını el ile indirebilir. Bu dosyalar, çalıştırmak veya düzenlemek için not defterleri klasörüne el ile yüklenebilir. Azure Machine Learning'deki sanal ağlar hakkında daha fazla bilgi edinmek için bu bağlantıyı izleyin.
script.py
Dosyası, script.py modeli daha önce kullanılan hiper parametrelerle eğitmek için gereken temel mantığı içerir. Azure Machine Learning betik çalıştırması bağlamında yürütülmesi amaçlanırken, bazı değişikliklerle modelin eğitim kodu kendi şirket içi ortamınızda tek başına da çalıştırılabilir.
Betik kabaca şu bölümlere ayrılabilir: veri yükleme, veri hazırlama, veri özellikleri, önişlemci/algoritma belirtimi ve eğitim.
Veri yükleme
İşlev get_training_dataset() , daha önce kullanılan veri kümesini yükler. Betiğin, özgün denemeyle aynı çalışma alanı altında çalıştırılacak bir Azure Machine Learning betiğinde çalıştırıldığını varsayar.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Betik çalıştırmasının bir parçası olarak çalışırken doğru Run.get_context().experiment.workspace çalışma alanını alır. Ancak, bu betik farklı bir çalışma alanında çalıştırılıyorsa veya yerel olarak çalıştırılıyorsa, betiği uygun çalışma alanını açıkça belirtecek şekilde değiştirmeniz gerekir.
Çalışma alanı alındıktan sonra, özgün veri kümesi kimliğiyle alınır. Tam olarak aynı yapıya sahip başka bir veri kümesi sırasıyla veya get_by_name()ile kimlik veya adla get_by_id() da belirtilebilir. Kimliği daha sonra betikte, aşağıdaki kodla benzer bir bölümde bulabilirsiniz.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Ayrıca bu işlevin tamamını kendi veri yükleme mekanizmanızla değiştirmeyi de tercih edebilirsiniz; tek kısıtlamalar, dönüş değerinin bir Pandas veri çerçevesi olması ve verilerin özgün denemedekiyle aynı şekle sahip olması gerektiğidir.
Veri hazırlama kodu
işlevi prepare_data() verileri temizler, özellik ve örnek ağırlık sütunlarını böler ve verileri eğitimde kullanılmak üzere hazırlar.
Bu işlev, veri kümesinin türüne ve deneme görev türüne bağlı olarak farklılık gösterebilir: sınıflandırma, regresyon, zaman serisi tahmini, görüntüler veya NLP görevleri.
Aşağıdaki örnek, genel olarak veri yükleme adımındaki veri çerçevesinin geçirildiğini gösterir. Başlangıçta belirtilmişse etiket sütunu ve örnek ağırlıkları ayıklanır ve içeren NaN satırlar giriş verilerinden bırakılır.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Daha fazla veri hazırlama işlemi yapmak istiyorsanız, bu adımda özel veri hazırlama kodunuzu ekleyerek gerçekleştirebilirsiniz.
Veri özellik kazandırma kodu
işlevi generate_data_transformation_config() , son scikit-learn işlem hattındaki özellik geliştirme adımını belirtir. Özgün denemenin özellik oluşturucuları, parametreleriyle birlikte burada yeniden oluşturulur.
Örneğin, bu işlevde gerçekleşebilecek olası veri dönüştürme işlemleri ve gibi SimpleImputer() imputer'leri veya ve CatImputer()LabelEncoderTransformer()gibi StringCastTransformer() transformatörleri temel alabilir.
Aşağıda, bir sütun kümesini dönüştürmek için kullanılabilecek türde StringCastTransformer() bir transformatör yer alır. Bu durumda, tarafından column_namesbelirtilen kümedir.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Aynı özellik/dönüştürmenin uygulanması gereken birçok sütun varsa (örneğin, birkaç sütun grubunda 50 sütun), bu sütunlar türe göre gruplandırılarak işlenir.
Aşağıdaki örnekte, her grubun benzersiz bir eşleyici uygulandığına dikkat edin. Bu eşleyici daha sonra söz konusu grubun sütunlarının her birine uygulanır.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Bu yaklaşım, her sütun için bir transformatör kod bloğuna sahip olmayarak daha kolaylaştırılmış bir koda sahip olmanıza olanak tanır. Bu, veri kümenizde onlarca veya yüzlerce sütun olduğunda bile özellikle zahmetli olabilir.
Sınıflandırma ve regresyon görevleriyle, özellik kazandırıcılar için [FeatureUnion] kullanılır.
Zaman serisi tahmin modelleri için, scikit-learn işlem hattında birden çok zaman serisi kullanan özellik oluşturucu toplanır ve ardından içinde TimeSeriesTransformersarmalanmıştır.
Zaman serisi tahmin modelleri için sağlanan tüm kullanıcılar, otomatik ML tarafından sağlananlardan önce gerçekleşir.
Önişlemci belirtim kodu
işlevi generate_preprocessor_config()varsa, son scikit-learn işlem hattında özellik kazandırdıktan sonra gerçekleştirilecek bir ön işleme adımını belirtir.
Normalde, bu ön işleme adımı yalnızca ile sklearn.preprocessinggerçekleştirilir veri standartlaştırma/normalleştirmeden oluşur.
Otomatik ML yalnızca yok sınıflandırması ve regresyon modelleri için ön işleme adımlarını belirtir.
Oluşturulan önişlemci koduna bir örnek aşağıda verilmişti:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Algoritma ve hiper parametre belirtim kodu
Algoritma ve hiper parametre belirtim kodu büyük olasılıkla birçok ML uzmanının en çok ilgilendiği koddur.
işlevi, generate_algorithm_config() scikit-learn işlem hattının son aşaması olarak modeli eğiten gerçek algoritmayı ve hiper parametreleri belirtir.
Aşağıdaki örnek, belirli hiper parametrelere sahip bir XGBoostClassifier algoritması kullanır.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
Çoğu durumda oluşturulan kod, açık kaynak yazılım (OSS) paketlerini ve sınıflarını kullanır. Ara sarmalayıcı sınıflarının daha karmaşık kodu basitleştirmek için kullanıldığı örnekler vardır. Örneğin, XGBoost sınıflandırıcısı ve LightGBM veya Scikit-Learn algoritmaları gibi yaygın olarak kullanılan diğer kitaplıklar uygulanabilir.
ML Professional olarak, bu algoritmanın yapılandırma kodunu, söz konusu algoritmanın becerilerine ve deneyimine ve belirli ML sorununuza göre gerektiğinde hiper parametrelerinde ayarlamalar yaparak özelleştirebilirsiniz.
Grup modelleri generate_preprocessor_config_N() için (gerekirse) ve generate_algorithm_config_N() grup modelindeki her öğrenci için tanımlanır. Burada N , grup modelinin listesindeki her bir öğrenci yerleşimini temsil eder. Yığın grubu modelleri için meta öğrenici generate_algorithm_config_meta() tanımlanır.
Uçtan uca eğitim kodu
Kod oluşturma, sırasıyla scikit-learn işlem hattını tanımlamak ve üzerinde çağırmak fit() için ve yayar build_model_pipeline()train_model().
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
scikit-learn işlem hattı özellik geliştirme adımını, bir önişlemciyi (kullanılıyorsa) ve algoritmayı veya modeli içerir.
Zaman serisi tahmin modellerinde, scikit-learn işlem hattı, uygulanan algoritmaya bağlı olarak zaman serisi verilerini düzgün bir şekilde işlemek için gereken bazı ek mantığa sahip bir içinde sarmalanır ForecastingPipelineWrapper.
Tüm görev türleri için etiket sütununun kodlanması gereken durumlarda kullanırız PipelineWithYTransformer .
scikit-Learn işlem hattına sahip olduktan sonra çağrılacak tek şey modeli eğitme yöntemidir fit() :
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
'den train_model() döndürülen değer, giriş verilerine uydurülen/eğitilen modeldir.
Önceki işlevlerin tümünü çalıştıran ana kod aşağıdaki gibidir:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Eğitilmiş modeli aldıktan sonra predict() yöntemiyle tahmin yapmak için kullanabilirsiniz. Denemeniz bir zaman serisi modeline yönelikse tahminler için forecast() yöntemini kullanın.
y_pred = model.predict(X)
Son olarak, model serileştirilir ve "model.pkl" adlı bir .pkl dosya olarak kaydedilir:
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Not script_run_notebook.ipynb defteri, Azure Machine Learning işlemlerinde yürütmenin script.py kolay bir yoludur.
Bu not defteri, mevcut otomatik ML örnek not defterlerine benzer, ancak aşağıdaki bölümlerde açıklandığı gibi birkaç önemli farklılık vardır.
Ortam
Genellikle, otomatik ml çalıştırması için eğitim ortamı SDK tarafından otomatik olarak ayarlanır. Ancak, oluşturulan kod gibi bir özel betik çalıştırılırken otomatik ML artık işlemi yürütmediğinden, komut işinin başarılı olması için ortamın belirtilmesi gerekir.
Kod oluşturma, mümkünse özgün otomatik ML denemesinde kullanılan ortamı yeniden kullanır. Bunun yapılması, eğitim betiği çalıştırmasının eksik bağımlılıklar nedeniyle başarısız olmamasını garanti eder ve zaman ve işlem kaynaklarından tasarruf sağlayan docker görüntüsü yeniden derlemesine ihtiyaç duymama avantajına sahiptir.
Ek bağımlılıklar gerektiren değişiklikler script.py yaparsanız veya kendi ortamınızı kullanmak istiyorsanız, ortamı uygun şekilde güncelleştirmeniz script_run_notebook.ipynb gerekir.
Denemeyi gönderme
Oluşturulan kod artık otomatik ML tarafından yönlendirilemediğinden, AutoML İşi oluşturup göndermek yerine bir oluşturmanız Command Job ve oluşturulan kodu (script.py) ona sağlamanız gerekir.
Aşağıdaki örnek, işlem, ortam vb. bir Komut İşi çalıştırmak için gereken parametreleri ve normal bağımlılıkları içerir.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
Sonraki adımlar
- Modelin nasıl ve nereye dağıtılacağı hakkında daha fazla bilgi edinin.
- Yorumlanabilirlik özelliklerinin özellikle otomatik ML denemeleri içinde nasıl etkinleştirileceğine bakın.