Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Bu makalede şunları öğreneceksiniz:
- Azure Machine Learning işinde Azure depolamadan veri okuma.
- Azure Machine Learning işinden Azure Depolama'ya nasıl veri yazılır.
- Bağlama ve indirme modları arasındaki fark.
- Verilere erişmek için kullanıcı kimliğini ve yönetilen kimliği kullanma.
- bir işte kullanılabilen bağlama ayarları.
- Yaygın senaryolar için en uygun bağlama ayarları.
- V1 veri varlıklarına erişme.
Önkoşullar
Azure aboneliği. Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun. Azure Machine Learning'in ücretsiz veya ücretli sürümünü deneyin.
azure-identity Python paketi (
pip install azure-identity).Azure CLI ile ml uzantısı v2 (
az extension add -n ml).Azure Machine Learning çalışma alanı.
Azure Machine Learning işlem hedefi (örneğin, adlı
cpu-clusterbir işlem kümesi).
Hızlı Başlangıç
Verilere erişirken kullanabileceğiniz ayrıntılı seçenekleri keşfetmeden önce, önce veri erişimi için ilgili kod parçacıklarını açıklayacağız.
Azure Machine Learning işinde Azure depolamadan veri okuma
Bu örnekte, genel bir blob depolama hesabından verilere erişen bir Azure Machine Learning işi başlatırsınız. Ancak kod parçacığını özel bir Azure Depolama hesabında kendi verilerinize erişmek için uyarlayabilirsiniz. Yolu burada açıklandığı gibi güncelleştirin. Azure Machine Learning, Microsoft Entra geçişi ile bulut depolamada kimlik doğrulamasını sorunsuz bir şekilde işler. Bir iş gönderdiğinizde şunları seçebilirsiniz:
- Kullanıcı kimliği: Microsoft Entra kimliğinizi verilere erişmek için geçirme
- Yönetilen kimlik: Verilere erişmek için işlem hedefinin yönetilen kimliğini kullanma
- Hiçbiri: Verilere erişmek için kimlik belirtmeyin. Kimlik bilgisi tabanlı (anahtar/SAS belirteci) veri depolarını kullanırken veya genel verilere erişirken Hiçbiri'ni kullanma
İpucu
Kimlik doğrulaması için anahtarlar veya SAS belirteçleri kullanıyorsanız Azure Machine Learning veri deposu oluşturmanızı öneririz. Çalışma zamanı, kimlik bilgilerinizi göstermeden depolamaya otomatik olarak bağlanır.
from azure.ai.ml import command, Input, MLClient
from azure.ai.ml.entities import Data, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure Machine Learning işinizden Azure Depolama'ya veri yazma
Bu örnekte, varsayılan Azure Machine Learning Veri Deponuza veri yazan bir Azure Machine Learning işi gönderirsiniz. İsteğe bağlı olarak, çıktıda name bir veri varlığı oluşturmak için veri varlığınızın değerini ayarlayabilirsiniz.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure Machine Learning veri çalışma zamanı
Bir iş gönderdiğinizde Azure Machine Learning veri çalışma zamanı, depolama konumundan işlem hedefine kadar veri yükünü denetler. Azure Machine Learning veri çalışma zamanı, makine öğrenmesi görevleri için hız ve verimlilik için iyileştirilmiştir. Başlıca avantajları şunlardır:
- Yüksek hız ve yüksek bellek verimliliği ile bilinen Rust dilinde yazılmış veri yükleri. Eşzamanlı veri indirmeleri için Rust, Python Genel Yorumlayıcı Kilidi (GIL) sorunlarından kaçınıyor
- Hafif; Rust'ın diğer teknolojilere bağımlılığı yoktur ; örneğin JVM. Sonuç olarak, çalışma zamanı hızla yüklenir ve işlem hedefinde fazladan kaynak (CPU, Bellek) boşaltmaz
- Çok işlemli (paralel) veri yükleme
- Derin öğrenme yaparken GPU'ların daha iyi kullanımını sağlamak için verileri bir veya daha fazla CPU'da arka plan görevi olarak hazırlar
- Bulut depolamaya kimlik doğrulamasının sorunsuz yönetimi
- Verileri bağlama (akış) veya tüm verileri indirme seçenekleri sağlar. Daha fazla bilgi için Bağlama (akış) ve İndirme bölümlerini ziyaret edin.
- fsspec ile sorunsuz tümleştirme- yerel, uzak ve katıştırılmış dosya sistemlerine ve bayt depolamaya yönelik birleşik bir python arabirimi.
İpucu
Eğitim (istemci) kodunuzda kendi bağlama/indirme özelliğinizi oluşturmak yerine Azure Machine Learning veri çalışma zamanını uygulamanızı öneririz. genel yorumlayıcı kilidi (GIL) sorunları nedeniyle istemci kodu depolamadan veri indirmek için Python kullandığında depolama aktarım hızı kısıtlamaları gözlemledik.
Yollar
bir işe veri girişi veya çıkışı sağladığınızda, veri konumuna işaret eden bir path parametre belirtmeniz gerekir. Bu tabloda Azure Machine Learning'in desteklediği farklı veri konumları gösterilir ve parametre örnekleri sağlanır path :
| Konum | Örnekler | Girdi | Çıktı |
|---|---|---|---|
| Yerel bilgisayarınızdaki bir yol | ./home/username/data/my_data |
Y | N |
| Açık HTTP(S) sunucusundaki bir yol | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Azure Depolama'da bir yol | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, yalnızca kimlik tabanlı kimlik doğrulaması için | N |
| Azure Machine Learning veri deposundaki yol | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| Veri varlığına giden yol | azureml:<my_data>:<version> |
Y | Ancak, çıkıştan bir veri varlığı oluşturmak için name ve version kullanabilirsiniz. |
Modlar
Veri girişleri/çıkışları ile bir iş çalıştırdığınızda şu mod seçeneklerinden birini belirleyebilirsiniz:
ro_mount: Depolama konumunu yerel disk (SSD) işlem hedefinde salt okunur olarak bağlayın.rw_mount: Depolama konumunu yerel disk (SSD) işlem hedefinde okuma-yazma olarak bağlayın.download: Verileri depolama konumundan yerel disk (SSD) işlem hedefine indirin.upload: İşlem hedefinden depolama konumuna veri yükleyin.eval_mount/eval_download:Bu modlar MLTable için benzersizdir. Bazı senaryolarda MLTable, MLTable dosyasını barındıran depolama hesabından farklı bir depolama hesabında bulunabilecek dosyaları verebilir. Öte yandan MLTable, depolama kaynağında bulunan verileri alt kümeye alabilir veya karıştırabilir. Alt kümenin/karıştırmanın bu görünümü yalnızca Azure Machine Learning veri çalışma zamanı MLTable dosyasını değerlendirdiğinde görünür hale gelir. Örneğin, bu diyagramda MLTable'ıneval_mountveyaeval_downloadile kullanılarak iki farklı depolama kapsayıcısından ve farklı bir depolama hesabında bulunan bir ek açıklama dosyasından nasıl görüntü alabileceği ve ardından uzak işlem hedefinin dosya sistemine nasıl bağlanıp/indirilebileceği gösterilir.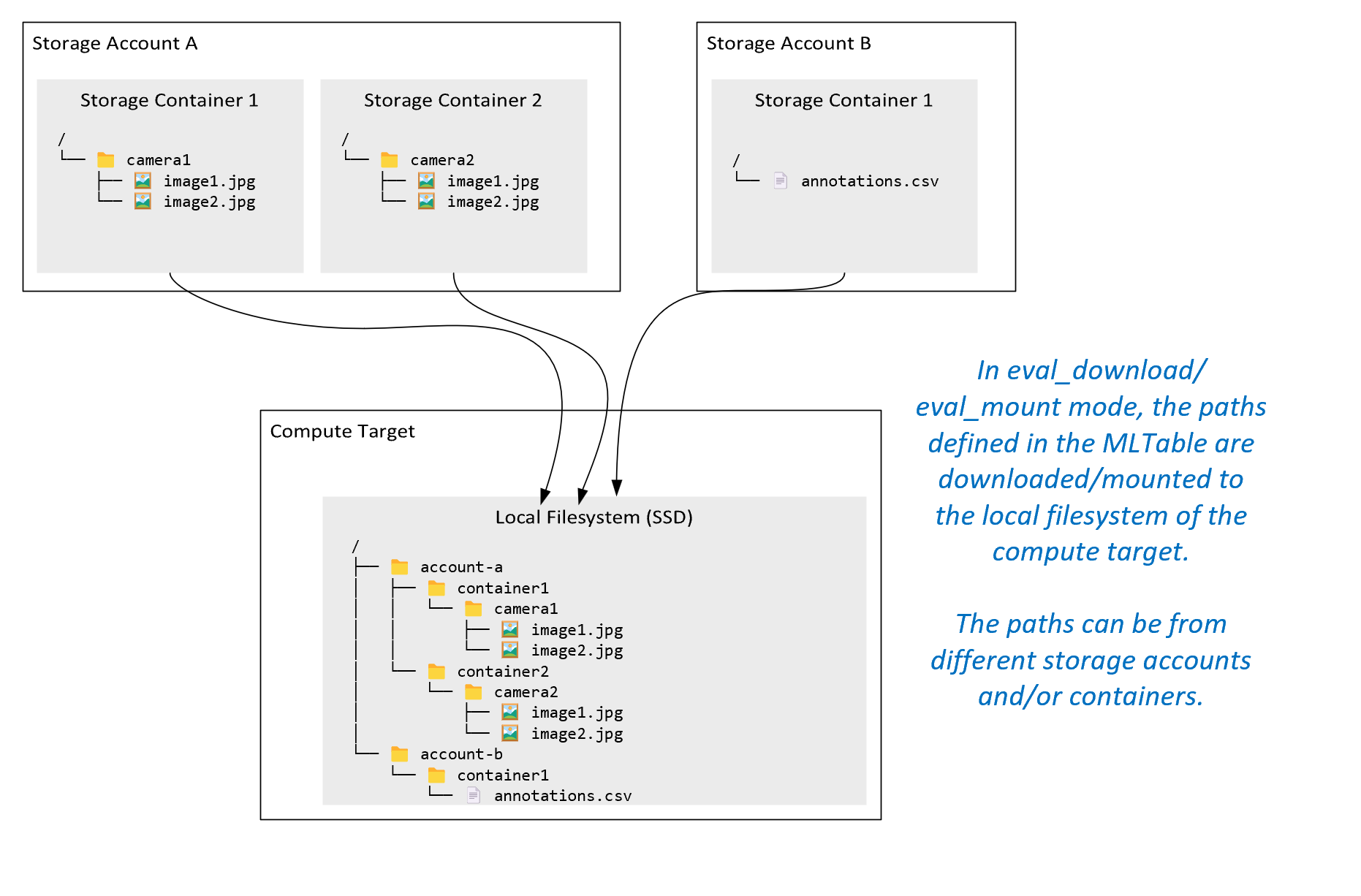
Klasör
camera1,camera2klasör veannotations.csvdosyaya daha sonra işlem hedefinin dosya sisteminden klasör yapısında erişilebilir:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Azure Machine Learning veri çalışma zamanına gitmek yerine diğer API'ler aracılığıyla doğrudan bir URI'den veri okumak isteyebilirsiniz. Örneğin, boto s3 istemcisini kullanarak bir s3 demetinde (sanal barındırılan stil veya yol stilihttpsURL ile) verilere erişmek isteyebilirsiniz. moduyla girişin URI'sini birdirectolarak alabilirsiniz. Yöntemler URI'leri işlemeyi bildiği için Spark İşleri'ndespark.read_*()doğrudan modun kullanıldığını görürsünüz. Spark olmayan işler için erişim kimlik bilgilerini yönetmek sizin sorumluluğunuzdadır. Örneğin, işlem MSI'sini veya başka bir erişim sağlayıcıyı açıkça kullanmanız gerekir.

Bu tabloda farklı tür/mod/giriş/çıkış bileşimleri için olası modlar gösterilmektedir:
| Tür | Giriş/Çıkış | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Girdi | ✓ | ✓ | ✓ | ||||
uri_file |
Girdi | ✓ | ✓ | ✓ | ||||
mltable |
Girdi | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Çıktı | ✓ | ✓ | |||||
uri_file |
Çıktı | ✓ | ✓ | |||||
mltable |
Çıktı | ✓ | ✓ | ✓ |
İndir
İndirme modunda, tüm giriş verileri işlem hedefinin yerel diskine (SSD) kopyalanır. Azure Machine Learning veri çalışma zamanı, tüm veriler kopyalandıktan sonra kullanıcı eğitim betiğini başlatır. Kullanıcı betiği başlatıldığında, diğer dosyalar gibi yerel diskten verileri okur. İş tamamlandığında veriler işlem hedefinin diskinden kaldırılır.
| Avantajlar | Dezavantajlar |
|---|---|
| Eğitim başladığında, tüm veriler eğitim betiği için işlem hedefinin yerel diskinde (SSD) kullanılabilir. Azure depolama /ağ etkileşimi gerekmez. | Veri kümesinin bir işlem hedef diskinde tamamen sığması gerekir. |
| Kullanıcı betiği başlatıldıktan sonra depolama veya ağ güvenilirliğine bağımlılık olmaz. | Veri kümesinin tamamı indirilir (eğitimin verilerin yalnızca küçük bir kısmını rastgele seçmesi gerekiyorsa indirme işleminin büyük bölümü boşa gider). |
| Azure Machine Learning veri çalışma zamanı, indirmeyi paralelleştirebilir (birçok küçük dosya üzerinde önemli bir fark yaratır) ve maksimum ağ/depolama aktarım hızına ulaşabilir. | İş, tüm veriler işlem hedefinin yerel diskine indirilene kadar bekler. Gönderilen derin öğrenme işi için, veriler hazır olana kadar GPU'lar boşta olur. |
| FUSE katmanı tarafından kaçınılmaz bir ek yük eklenmedi (gidiş dönüş: kullanıcı alanındaki bir betikten çağrı → çekirdek → kullanıcı alanındaki FUSE hizmeti → çekirdek → kullanıcı alanındaki betiğe yanıt) | İndirme tamamlandıktan sonra depolama değişiklikleri verilere yansıtılamaz. |
İndirme ne zaman kullanılır?
- Veriler, diğer eğitime müdahale etmeden işlem hedefinin diskine sığacak kadar küçüktür
- Eğitim, veri kümesinin çoğunu veya tümünü kullanır
- Eğitim, bir veri kümesindeki dosyaları birden çok kez okur
- Büyük bir dosyanın rastgele noktalara atlamak için eğitim yapılmalıdır.
- Eğitim başlamadan önce tüm veriler indirilene kadar beklemeniz sorun değil
Kullanılabilir indirme ayarları
İndirme ayarlarını işinizdeki şu ortam değişkenleriyle ayarlayabilirsiniz:
| Ortam Değişkeni Adı | Tür | Varsayılan Değer | Açıklama |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
İndirme işleminin kullanabileceği eşzamanlı iş parçacığı sayısı |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Geçici hatalardan kurtarmak için ayrı ayrı depolama / http istek yeniden deneme denemelerinin sayısı. |
İşinizde, ortam değişkenlerini ayarlayarak yukarıdaki varsayılan değerleri değiştirebilirsiniz. Örneğin:
Kısa olması için, yalnızca işteki ortam değişkenlerini tanımlamayı gösteririz.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Performans ölçümlerini indirme
İşlem hedefinizin VM boyutu, verilerinizin indirme süresini etkiler. Özellikle:
- Çekirdek sayısı. Ne kadar çok çekirdek varsa o kadar eşzamanlılık ve dolayısıyla indirme hızı da o kadar hızlı olur.
- Beklenen ağ bant genişliği. Azure'daki her vm, Ağ Arabirim Kartı'ndan (NIC) maksimum aktarım hızına sahiptir.
Not
A100 GPU VM'leri için Azure Machine Learning veri çalışma zamanı, işlem hedefine (yaklaşık 24 Gbit/sn) veri indirirken NIC'yi (Ağ Arabirimi Kartı) doygun hale getirebilir: Mümkün olan teorik maksimum aktarım hızı.
Bu tabloda, Azure Machine Learning veri çalışma zamanının VM'deki Standard_D15_v2 100 GB'lık bir dosya için işleyebileceği indirme performansı gösterilmektedir (20cores, 25 Gbit/sn Ağ aktarım hızı):
| Veri yapısı | Yalnızca indirme (sn) | MD5'i indirme ve hesaplama (sn) | Elde Edilen Aktarım Hızı (Gbit/sn) |
|---|---|---|---|
| 10 x 10 GB Dosyalar | 55.74 | 260.97 | 14,35 Gbit/sn |
| 100 x 1 GB Dosyalar | 58.09 | 259.47 | 13,77 Gbit/s |
| 1 x 100 GB Dosya | 96.13 | 300.61 | 8,32 Gbit/sn |
Daha küçük dosyalara ayrılmış daha büyük bir dosyanın paralellik nedeniyle indirme performansını geliştirebileceğini görebiliriz. Depolama isteği gönderimleri için gereken süre, yükü indirmeye harcanan zamana göre arttığı için çok küçük (4 MB'tan az) olan dosyalardan kaçınmanızı öneririz. Daha fazla bilgi için Bkz . Birçok küçük dosya sorunu.
Montaj (yayın)
Bağlama modunda, Azure Machine Learning veri yeteneği, Linux'un FUSE (kullanıcı alanında dosya sistemi) özelliğini kullanarak öykünülmüş bir dosya sistemi oluşturur. Çalışma zamanı, tüm verileri işlem hedefinin yerel diskine (SSD) indirmek yerine kullanıcının betik eylemlerine gerçek zamanlı olarak tepki verebilir. Örneğin, "dosya aç", "konum X'ten 2 KB'lik bir parça oku", "dizin içeriğini listele".
| Avantajlar | Dezavantajlar |
|---|---|
| İşlem hedefi yerel disk kapasitesini aşan veriler kullanılabilir (işlem donanımıyla sınırlı değildir) | Linux FUSE modülünün ek yükü eklendi. |
| Eğitimin başlangıcında gecikme olmaz (indirme modundan farklı olarak). | Kullanıcının kod davranışına bağımlılık (tek bir iş parçacığı bağlamasında küçük dosyaları sıralı olarak okuyan eğitim kodu da depolama alanından veri isterse, ağ veya depolama aktarım hızını en üst düzeye çıkarmayabilir). |
| Kullanım senaryosuna göre ayarlanacak daha fazla ayar mevcut. | Windows desteği yok. |
| Depolama alanından yalnızca eğitim için gereken veriler okunur. |
Ne zaman monte etme kullanılmalıdır?
- Veriler büyük ve işlem hedefi yerel diske sığmıyor.
- Bir kümedeki her bir işlem düğümlerinin veri kümesinin tamamını (csv dosya seçimindeki rastgele dosya veya satırlar vb.) okuması gerekmez.
- Eğitim başlamadan önce tüm verilerin indirilmesini bekleyen gecikmeler bir sorun haline gelebilir (boşta GPU süresi).
Kullanılabilir bağlama ayarları
Bağlama ayarlarını işinizde şu ortam değişkenleriyle ayarlayabilirsiniz:
| Env değişken adı | Tür | Varsayılan değer | Açıklama |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Ayarlanmadı (önbelleğin süresi hiç dolmaz) |
getattr çağrı sonuçlarının önbellekte saklanması ve bu bilgi için depodan ardıl isteklerin önlenmesi amacıyla gereken süre, milisaniye cinsindendir. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Bilişimin iyi durumda kalmasını sağlamak için bir sistem yapılandırmasına yöneliktir. Diğer ayarlar hangi değerlere sahip olursa olsun, Azure Machine Learning veri çalışma zamanı disk alanının son RESERVED_FREE_DISK_SPACE baytlarını kullanmaz. |
DATASET_MOUNT_CACHE_SIZE |
usize | Sınırsız | Bağlama işleminin ne kadar disk alanı kullanabileceğini denetler. Pozitif bir değer, mutlak değeri bayt cinsinden ayarlar. Negatif değer, disk alanının ne kadarının boş bırakılası olduğunu ayarlar. Bu tablo daha fazla disk önbelleği seçeneği sağlar. Kolaylık sağlamak için KB, MB ve GB değiştiricilerini destekler. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Birim bağlama, önbellek belirli bir kapasiteye ulaştığında önbellek temizleme işlemini başlatır AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. 0 ile 1 arasında olmalıdır. Bunu 1 olarak < ayarlamak, daha önce arka plan önbelleği ayıklamayı tetikler.
AVAILABLE_CACHE_SIZE değiştirebileceğiniz veya doğrudan görüntüleyebileceğiniz bir ortam değişkeni değildir. Bu bağlamda, "sistemin önbelleğe alma için kullanılabilir olarak hesaplayan bayt sayısı" anlamına gelir. Bu değer, disk boyutu, sistem durumu için gereken disk alanı miktarı ve ortam değişkenlerinde (ve gibi DATASET_RESERVED_FREE_DISK_SPACEDATASET_MOUNT_CACHE_SIZE) ayarlanan yapılandırmalar gibi faktörlere bağlıdır. |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Ayıklama önbelleği en az (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) önbellek alanı boşaltmaya çalışır. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Akış okuma bloğu boyutu. Dosya yeterince büyük olduğunda, depolama alanından en az DATASET_MOUNT_READ_BLOCK_SIZE veri isteyin ve fuse bir okuma işlemi için daha azını talep etse bile önbelleğe alın. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Önceden getirilecek blok sayısı (okuma bloğu k arka planda k+1, ..., k+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT bloklarının önceden yüklenmesini tetikler) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Önbellekleme iş parçacıklarının arka plandaki sayısı. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
boole | yanlış | Blok tabanlı önbelleğe almayı etkinleştirin. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128MB | Yalnızca blok tabanlı önbelleğe alma için geçerlidir. RAM blok tabanlı önbelleğe alma işleminin kullanabileceği boyut. 0 değeri, bellek önbelleğe almayı tamamen devre dışı bırakır. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
boole | doğru | Yalnızca blok tabanlı önbelleğe alma için geçerlidir. True olarak ayarlandığında, blok tabanlı önbelleğe alma blokları önbelleğe almak için yerel sabit sürücüyü kullanır. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512MB | Yalnızca blok tabanlı önbelleğe alma için geçerlidir. Blok tabanlı önbelleğe alma, önbelleğe alınmış bloğu arka planda yerel bir diske yazar. Bu ayar, yerel disk önbelleğine boşaltılmayı bekleyen blokları depolamak için monte işleminin ne kadar bellek kullanabileceğini denetler. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Yalnızca blok tabanlı önbelleğe alma için geçerlidir. İndirilen blokları işlem hedefinin yerel diskine yazmak için blok tabanlı önbelleğe alma tarafından kullanılan arka plan iş parçacıklarının sayısı. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Bağlama iletisi döngüsünü zorla sonlandırmadan önce bekleyen tüm işlemlerin (örneğin, boşaltma çağrıları) bitebilmesi için unmount saniye cinsinden süre. |
İşinizde, ortam değişkenlerini ayarlayarak yukarıdaki varsayılan değerleri değiştirebilirsiniz, örneğin:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Blok tabanlı açık mod
Blok tabanlı açık mod, her dosyayı önceden tanımlanmış boyuttaki bloklara böler (son blok hariç). Belirtilen konumdan gelen bir okuma isteği, depolama alanından ilgili bir blok istiyor ve istenen verileri hemen döndürür. Okuma, birden çok iş parçacığı kullanılarak (sıralı okuma için en iyi duruma getirilmiş) arka planda N sonraki blokların önceden getirilmesini de tetikler. İndirilen bloklar iki katmanlı önbellekte (RAM ve yerel disk) önbelleğe alınır.
| Avantajlar | Dezavantajlar |
|---|---|
| Eğitim betiğine hızlı veri teslimi (henüz talep edilmemiş öbekler için daha az engelleme). | Rastgele okumalar ileriye dönük önceden oluşturulmuş blokları boşa harcayabilir. |
| Arka plan iş parçacıklarına daha fazla iş yükü boşaltılır, (ön yükleme / önbelleğe alma). Daha sonra eğitim devam edebilir. | Yerel disk önbelleğindeki bir dosyadan (örneğin, tam dosya önbelleği modunda) doğrudan okuma işlemlerine kıyasla önbellekler arasında gezinmek için ek yük eklendi. |
| Depolama alanından yalnızca istenen veriler (artı ön işlem) okunur. | |
| Yeterince küçük veriler için hızlı RAM tabanlı önbellek kullanılır. |
Blok tabanlı açık modu ne zaman kullanılır?
Rastgele dosya konumlarından hızlı okuma işlemlerine ihtiyaç duymanız dışında çoğu senaryo için önerilir. Böyle durumlarda Tüm dosya önbelleği açma modunu kullanın.
Tüm dosya önbelleği açma modu
Bağlama klasörünün altındaki bir dosya (örneğin, f = open(path, args)) tüm dosya modunda açıldığında, tüm dosya diskteki bir işlem hedef önbellek klasörüne indirilene kadar çağrı engellenir. Sonraki tüm okuma çağrıları önbelleğe alınmış dosyaya yönlendirilir, bu nedenle depolama etkileşimi gerekmez. Önbellekte geçerli dosyaya sığacak kadar kullanılabilir alan yoksa, bağlama önbellekten en son kullanılan dosyayı silerek ayıklamayı dener. Dosyanın diske sığmadığı durumlarda (önbellek ayarlarıyla ilgili olarak), veri çalışma zamanı akış moduna geri döner.
| Avantajlar | Dezavantajlar |
|---|---|
| Dosya açıldıktan sonra depolama güvenilirliği / aktarım hızı bağımlılıkları yoktur. | Dosyanın tamamı indirilene kadar açık arama engellenir. |
| Hızlı rastgele okumalar (dosyanın rastgele yerlerinden gelen öbekleri okuma). | Dosyanın bazı bölümleri gerekmese bile dosyanın tamamı depolama alanından okunur. |
Kullanılması gereken durumlar
128 MB'ı aşan nispeten büyük dosyalar için rastgele okuma gerektiğinde.
Kullanım
İşinizde ortam değişkenini DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED olarak false ayarlayın:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Montaj: Dosyaları listeleme
Milyonlarca dosyayla çalışırken, özyinelemeli listelemeden kaçının - örneğin . Özyinelemeli bir liste, üst dizinin dizin içeriğini listelemek için birçok çağrı tetikler. Ardından, içindeki her dizin için tüm alt düzeylerde ayrı bir özyinelemeli çağrı gerektirir. Azure Depolama genellikle tek bir liste isteği başına yalnızca 5.000 öğe döndürülmesini sağlar. Sonuç olarak, her biri 10 dosya içeren 1M sayıda klasörün özyinelemeli bir listelemesi depolama için 1,000,000 / 5000 + 1,000,000 = 1,000,200 isteği gerektirir. Buna karşılık, 10.000 dosya içeren 1.000 klasör, özyinelemeli bir liste için yalnızca 1.001 istek depolama isteğine ihtiyaç duyar.
Azure Machine Learning bağlaması, listelemeyi yavaş bir şekilde işler. Bu nedenle, birçok küçük dosyayı listelemek için, tam listeyi döndüren bir istemci kitaplığı çağrısı yerine yinelemeli bir istemci kitaplığı çağrısı (örneğin Python'da os.scandir() ) kullanmak daha iyidir (örneğin, os.listdir() Python'da). Yinelemeli bir istemci kitaplığı çağrısı bir oluşturucu döndürür, yani listenin tamamı yüklenene kadar beklemesi gerekmez. Daha sonra daha hızlı ilerleyebilir.
Bu tablo, Python os.scandir() ve os.listdir() işlevlerin düz bir yapıda ~4M dosyaları içeren bir klasörü listelemesi için gereken süreyi karşılaştırır:
| Ölçü birimi | os.scandir() |
os.listdir() |
|---|---|---|
| İlk girişi alma süresi (sn) | 0.67 | 553.79 |
| İlk 50 bin girdiyi alma süresi (sn) | 9.56 | 562.73 |
| Tüm girişleri alma süresi (sn) | 558.35 | 582.14 |
Yaygın senaryolar için en uygun bağlama ayarları
Bazı yaygın senaryolar için Azure Machine Learning işinizde ayarlamanız gereken en uygun bağlama ayarlarını gösteririz.
Büyük dosyayı bir kez sırayla okuma (csv dosyasındaki satırları işleme)
Bu bağlama ayarlarını environment_variables Azure Machine Learning işinizin bölümüne ekleyin:
Not
Sunucusuz işlem kullanmak için, bu kodda compute="cpu-cluster", silin.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Birden çok iş parçacığından büyük dosyayı bir kez okuma (bölümlenmiş csv dosyasını birden çok iş parçacığında işleme)
Bu bağlama ayarlarını environment_variables Azure Machine Learning işinizin bölümüne ekleyin:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Bir kerede birden çok iş parçacığından milyonlarca küçük dosya (görüntü) okuma (görüntüler üzerinde tek dönem eğitimi)
Bu bağlama ayarlarını environment_variables Azure Machine Learning işinizin bölümüne ekleyin:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Birden çok iş parçacığından milyonlarca küçük dosyayı (görüntü) birden çok kez okuma (görüntüler üzerinde birden çok dönem eğitimi)
Bu bağlama ayarlarını environment_variables Azure Machine Learning işinizin bölümüne ekleyin:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Rastgele aramalarla büyük dosyaları okuma (bağlı klasörden dosya veritabanı sunma gibi)
Bu bağlama ayarlarını environment_variables Azure Machine Learning işinizin bölümüne ekleyin:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Veri yükleme performans sorunlarını tanılama ve çözme
Azure Machine Learning işi verilerle yürütülürken, bir girişin mode baytların depolamadan nasıl okunacağını ve işlem hedefi yerel SSD diskinde nasıl önbelleğe alınacağını belirler. İndirme modu için, kullanıcı kodu yürütmeyi başlatmadan önce diskteki tüm veriler önbelleğe alınır. En yüksek indirme hızlarını etkileyen çeşitli faktörler:
- Paralel iş parçacığı sayısı
- Dosya sayısı
- Dosya boyutu
Bağlama modu için, veriler önbelleğe alınmaya başlamadan önce kullanıcı kodunun dosyaları açmaya başlaması gerekir. Farklı bağlama ayarları farklı okuma ve önbelleğe alma davranışına neden olabilir. Verilerin depolama alanından yüklenme hızını çeşitli faktörler etkiler:
- İşlem için veri konumu: Depolama ve işlem hedef konumlarınız aynı olmalıdır. Depolama ve işlem hedefiniz farklı bölgelerde bulunuyorsa, verilerin bölgeler arasında aktarılması gerektiğinden performans düşer. Verilerinizin işlemle birlikte konumlandırılmasını sağlama hakkında daha fazla bilgi için Verileri işlemle konumlandırın adresini ziyaret edin.
-
İşlem hedef boyutu: Küçük işlemler daha büyük işlem boyutlarına kıyasla daha düşük çekirdek sayılarına (daha az paralellik) ve beklenen ağ bant genişliğine sahiptir; her iki faktör de veri yükleme performansını etkiler.
- Örneğin, (2 çekirdek, 1.500 Mb/sn NIC) gibi
Standard_D2_v2küçük bir VM boyutu kullanıyorsanız ve 50.000 MB (50 GB) veri yüklemeye çalışırsanız, en iyi ulaşılabilir veri yükleme süresi yaklaşık 270 saniye olur (NIC'yi 187,5 MB/sn aktarım hızında doyduğunuz varsayılır). Buna karşılık, birStandard_D5_v2(16 çekirdek, 12.000 Mb/sn) aynı verileri yaklaşık 33 saniye içinde yükler (NIC'yi 1500 MB/sn aktarım hızında doyduğunuz varsayılır).
- Örneğin, (2 çekirdek, 1.500 Mb/sn NIC) gibi
- Depolama katmanı: Büyük Dil Modelleri (LLM) dahil olmak üzere çoğu senaryo için standart depolama en iyi maliyet/performans profilini sağlar. Ancak, çok sayıda küçük dosyanız varsa premium depolama daha iyi bir maliyet/performans profili sunar. Daha fazla bilgi için Bkz . Azure Depolama seçenekleri.
- Depolama yükü: Depolama hesabı yüksek yük altındaysa (örneğin, veri isteyen bir kümedeki birçok GPU düğümü) depolamanın çıkış kapasitesine erişme riskiyle karşı karşıyasınız demektir. Daha fazla bilgi için bkz . Depolama yükü. Paralel erişim gerektiren çok sayıda küçük dosyanız varsa, depolamanın istek sınırlarına ulaşabilirsiniz. Standart depolama hesapları için hedefleri ölçeklendirme bölümünde hem çıkış kapasitesi hem de depolama isteklerinin sınırlarıyla ilgili güncel bilgileri okuyun.
- Kullanıcı kodunda veri erişim düzeni: Bağlama modunu kullandığınızda, kodunuzdaki açma/okuma eylemlerine göre veriler getirilir. Örneğin, büyük bir dosyanın rastgele bölümlerini okurken, bağlama noktalarının varsayılan veri ön getirme ayarları okunmayacak blokların indirilmesine yol açabilir. En yüksek aktarım hızına ulaşmak için bazı ayarları ayarlamanız gerekebilir. Daha fazla bilgi için Yaygın senaryolar için optimum bağlama ayarları bölümünü okuyun.
Sorunları tanılamak için günlükleri kullanma
İşinizden veri çalışma zamanının günlüklerine erişmek için:
- İş sayfasından Çıkışlar+Günlükler sekmesini seçin.
- system_logs klasörünü ve ardından data_capability klasörünü seçin.
- İki günlük dosyası görmeniz gerekir:
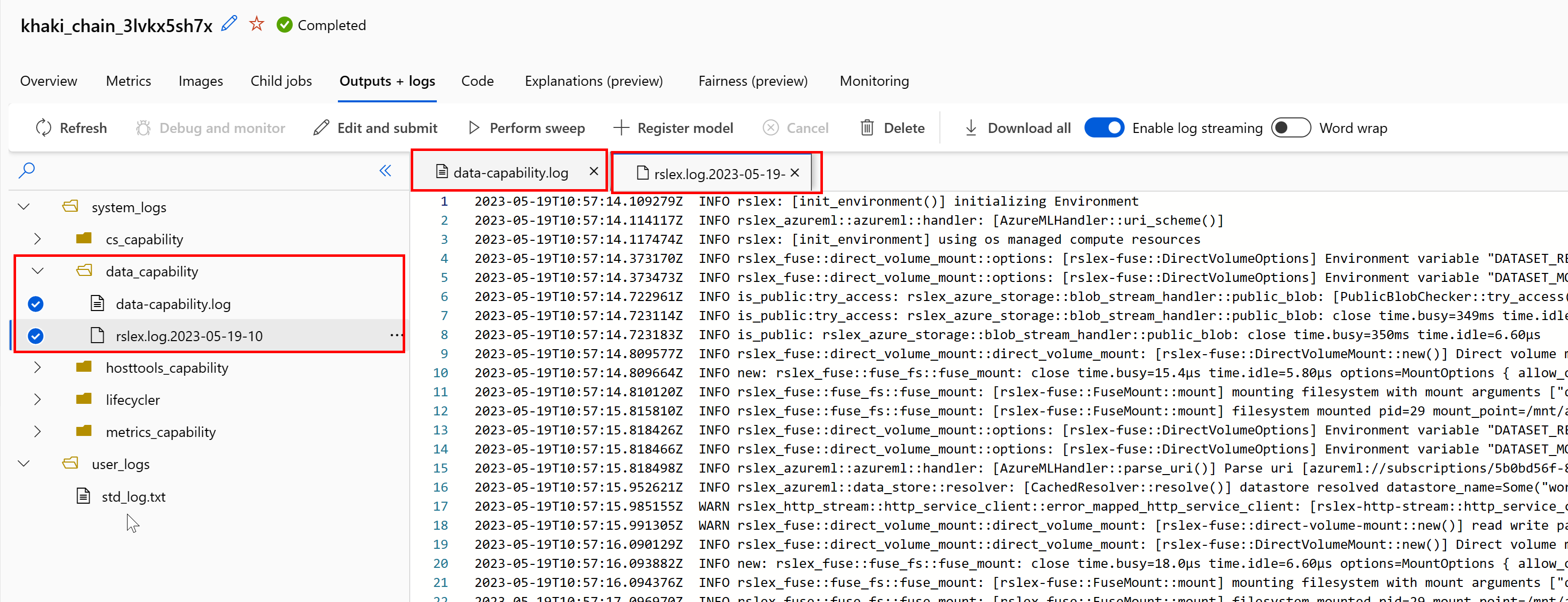

Günlük dosyası data-capability.log , önemli veri yükleme görevleri için harcanan süreyle ilgili üst düzey bilgileri gösterir. Örneğin, verileri indirdiğinizde, çalışma süresi indirme işleminin başlangıç ve bitiş saatlerini günlüğe kaydeder.
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
İndirme aktarım hızı, VM boyutu için beklenen ağ bant genişliğinin bir kısmıysa, günlük dosyasını
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
rslex.log dosyası, bağlama veya indirme modlarını seçip seçmediğinize bakılmaksızın tüm dosya kopyalamayla ilgili ayrıntıları sağlar. Ayrıca kullanılan Ayarlar (ortam değişkenleri) açıklanır. Hata ayıklamayı başlatmak için, yaygın senaryolar için En uygun bağlama ayarlarını yapıp yapmadığınızı kontrol edin.
Azure depolamayı izleme
Azure portalında Depolama hesabınızı ve ardından Ölçümler'i seçerek depolama ölçümlerini görebilirsiniz:

Ardından SuccessE2ELatency değerini SuccessServerLatency ile çizersiniz. Ölçümler yüksek SuccessE2ELatency ve düşük SuccessServerLatency gösteriyorsa, kullanılabilir iş parçacıklarınız sınırlıysa veya CPU, bellek veya ağ bant genişliği gibi kaynaklar yetersizse şunları yapmalısınız:
- İşinizin CPU ve bellek kullanımını denetlemek için Azure Machine Learning stüdyosu izleme görünümünü kullanın. CPU ve bellek yetersizse işlem hedefi VM boyutunu artırmayı göz önünde bulundurun.
- İndirme yapıyor ancak CPU ve belleği kullanmıyorsanız,
RSLEX_DOWNLOADER_THREADSartırmayı göz önünde bulundurun. Bağlama kullanıyorsanız, daha fazla önceden getirme yapmak içinDATASET_MOUNT_READ_BUFFER_BLOCK_COUNT'yi artırmalı ve daha fazla okuma iş parçacığı içinDATASET_MOUNT_READ_THREADS'yi artırmalısınız.
Ölçümler düşük SuccessE2ELatency ve düşük SuccessServerLatency gösteriyorsa, ancak istemci yüksek gecikme süresiyle karşılaşıyorsa, hizmete ulaşan depolama isteğinde gecikme yaşarsınız. Şunu kontrol etmelisiniz:
- Bağlama/indirme (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) için kullanılan iş parçacığı sayısının, işlem hedefinde kullanılabilir çekirdek sayısına göre çok düşük ayarlanıp ayarlanmadığı kontrol ediliyor. Ayar çok düşükse, iş parçacığı sayısını artırın. - İndirme (
AZUREML_DATASET_HTTP_RETRY_COUNT) için yeniden deneme sayısının çok yüksek ayarlanıp ayarlanmadığı. Öyleyse, yeniden deneme sayısını azaltın.
İş sırasında disk kullanımını izleme
Azure Machine Learning Stüdyosu'ndan, çalışmanız sırasında hesaplama hedefi disk giriş/çıkışını ve kullanımını da izleyebilirsiniz. İşinize gidin ve İzleme sekmesini seçin. Bu sekme, 30 günlük sıralı olarak işinizin kaynakları hakkında içgörüler sağlar. Örneğin:

Not
İş izleme yalnızca Azure Machine Learning'in yönettiği işlem kaynaklarını destekler. Çalışma zamanı 5 dakikadan kısa olan işler bu görünümü doldurmak için yeterli veriye sahip olmayacaktır.
Azure Machine Learning veri çalışma zamanı, işlemi iyi durumda tutmak için disk alanının son RESERVED_FREE_DISK_SPACE baytlarını kullanmaz (varsayılan değerdir 150MB). Diskiniz doluysa kodunuz dosyaları çıkış olarak bildirmeden diske yazıyordur. Bu nedenle, verilerin yanlışlıkla geçici diske yazılmadığından emin olmak için kodunuzu denetleyin. Geçici diske dosya yazmanız gerekiyorsa ve bu kaynak dolmaya başlıyorsa şunları göz önünde bulundurun:
- VM Boyutunu daha büyük bir geçici diske sahip olacak şekilde artırma
- Verilerinizi diskten temizlemek için önbelleğe alınan verilerde (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) bir TTL ayarlama
Hesaplama ile verileri aynı konuma yerleştirme
Dikkat
Depolama ve işlem farklı bölgelerdeyse, verilerin bölgeler arasında aktarılması gerektiğinden performansınız düşer. Bu, maliyetleri artırır. Depolama hesabınızın ve işlem kaynaklarınızın aynı bölgede olduğundan emin olun.
Verileriniz ve Azure Machine Learning Çalışma Alanı farklı bölgelerde depolanıyorsa, azcopy yardımcı programıyla verileri aynı bölgedeki bir depolama hesabına kopyalamanızı öneririz. AzCopy sunucudan sunucuya API'leri kullanır, böylece veriler doğrudan depolama sunucuları arasında kopyalanır. Bu kopyalama işlemleri bilgisayarınızın ağ bant genişliğini kullanmaz. Ortam değişkeniyle bu işlemlerin AZCOPY_CONCURRENCY_VALUE aktarım hızını artırabilirsiniz. Daha fazla bilgi edinmek için bkz . Eşzamanlılığı artırma.
Depolama yükü
Aşağıdaki durumlarda tek bir depolama hesabı yüksek yük altında olduğunda kısıtlanabilir:
- İşiniz birçok GPU düğümü kullanıyor
- Depolama hesabınızda işinizi çalıştırırken verilere erişen birçok eşzamanlı kullanıcı/uygulama var
Bu bölümde, iş yükünüz için kısıtlamanın bir sorun haline gelip gelemeyeceğini belirlemek ve kısıtlamanın azaltılmasına nasıl yaklaşılacağını değerlendiren hesaplamalar gösterilir.
Bant genişliği sınırlarını hesaplama
Azure Depolama hesabının varsayılan çıkış sınırı 120 Gbit/sn'dir. Azure VM'lerinin farklı ağ bant genişlikleri vardır ve bu da depolamanın varsayılan çıkış kapasitesi üst sınırına ulaşmada gereken teorik işlem düğümlerinin sayısını etkiler:
| Boyut | GPU Kartı | Sanal işlemci (vCPU) | Bellek: GiB | Geçici depolama (SSD) GiB | GPU Kartı Sayısı | GPU belleği: GiB | Beklenen ağ bant genişliği (Gbit/sn) | Depolama Hesabı Çıkış Varsayılan Maksimum (Gbit/sn)* | Varsayılan çıkış kapasitesine ulaşan düğüm sayısı |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | yirmi dört | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | yirmi dört | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | yirmi dört | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | yirmi dört | 120 | 5 |
| Standard_NC24s_v3 | V100 | yirmi dört | 448 | 2948 | 4 | 64 | yirmi dört | 120 | 5 |
| Standard_NC24rs_v3 | V100 | yirmi dört | 448 | 2948 | 4 | 64 | yirmi dört | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
A100/V100 SKU'larının her ikisi de 24 Gbit/sn düğüm başına en yüksek ağ bant genişliğine sahiptir. Tek bir hesaptan veri okuyan her düğüm teorik en fazla 24 Gbit/sn'ye yakın okuma gerçekleştirebiliyorsa, çıkış kapasitesi beş düğümle gerçekleşir. Altı veya daha fazla işlem düğümünün kullanılması tüm düğümlerde veri aktarım hızını düşürmeye başlar.
Önemli
İş yükünüz altıdan fazla A100/V100 düğümüne ihtiyaç duyuyorsa veya varsayılan depolama çıkış kapasitesini (120Gbit/sn) aşacağınıza inanıyorsanız destek birimine başvurun (Azure portalı aracılığıyla) ve depolama çıkış sınırı artışı isteyin.
Birden çok depolama hesabı arasında ölçeklendirme
Maksimum depolama çıkış kapasitesini aşabilir ve/veya istek oranı sınırlarına basabilirsiniz. Bu sorunlar oluşursa, depolama hesabındaki bu sınırları artırmak için önce desteğe başvurmanızı öneririz.
En yüksek çıkış kapasitesini veya istek hızı sınırını artıramıyorsanız, verileri birden çok depolama hesabına çoğaltmayı düşünmelisiniz. Azure Data Factory, Azure Depolama Gezgini veya azcopyile verileri birden çok bilgisayarınızda kopyalayın ve eğitim işinizdeki tüm hesapları bağlayın. Yalnızca monte edilen konumda erişilen veriler indirilir. Bu nedenle, eğitim kodunuz ortam değişkeninden RANK okuyarak birden çok girişten hangisinin okunacağını seçebilir. İş tanımınız bir depolama hesabı listesinden geçer:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Eğitim python kodunuz, bu düğüme özgü depolama hesabını almak için RANK kullanabilir.
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Birçok küçük dosya sorunu
Depolamadan dosya okumak, her dosya için istekte bulunmayı içerir. Dosya başına istek sayısı, dosya boyutlarına ve dosya okumalarını işleyen yazılımın ayarlarına göre değişir.
Dosyalar 1-4 MB boyutunda bloklar halinde okunur. Bloktan küçük dosyalar tek bir istekle okunur (GET file.jpg 0-4 MB) ve bloktan büyük dosyalar blok başına bir istekte bulunur (GET file.jpg 0-4 MB, GET file.jpg 4-8 MB). Bu tabloda, 4 MB'lık bloktan küçük dosyaların daha büyük dosyalara kıyasla daha fazla depolama isteğine neden olduğu gösterilmektedir:
| # Dosyalar | Dosya Boyutu | Toplam veri boyutu | Blok boyutu | # Depolama istekleri |
|---|---|---|---|---|
| 2,000,000 | 500 KB | 1 Terabayt (TB) | 4 MB | 2,000,000 |
| 1.000 | 1GB | 1 Terabayt (TB) | 4 MB | 256,000 |
Küçük dosyalar için gecikme süresi aralığı çoğunlukla veri aktarımları yerine depolamaya yönelik isteklerin işlenmesini içerir. Bu nedenle, dosya boyutunu artırmak için şu önerileri sunuyoruz:
- Yapılandırılmamış veriler (görüntüler, video vb.) için, küçük dosyaları birden çok öbek halinde okunabilen daha büyük bir dosya olarak depolamak için birlikte arşivleyin (zip/tar). Bu büyük arşivlenmiş dosyalar işlem kaynağında açılabilir ve PyTorch Archive DataPipes daha küçük dosyaları ayıklayabilir.
- Yapılandırılmış veriler (CSV, parquet vb.) için, boyutu artırmak için dosyaları birleştirdiğinden emin olmak için ETL işleminizi inceleyin. Spark,dosya boyutlarını artırmaya yardımcı olacak yöntemlere
repartition()sahiptircoalesce().
Dosya boyutlarınızı artıramıyorsanız Azure Depolama seçeneklerinizi keşfedin.
Azure Depolama seçenekleri
Azure Depolama iki katman sunar: standart ve premium:
| Depolama | Senaryo |
|---|---|
| Azure Blob - Standart (HDD) | Verileriniz daha büyük bloblarda (görüntüler, video vb.) yapılandırılmıştır. |
| Azure Blob - Premium (SSD) | Yüksek işlem hızları, daha küçük nesneler veya tutarlı olarak düşük depolama gecikme süresi gereksinimleri |
İpucu
"Çok" küçük dosyalar (KB boyutu) için, depolama maliyeti GPU işlemini çalıştırma maliyetlerinden daha düşük olduğundan premium (SSD) kullanmanızı öneririz.
V1 veri varlıklarını okuma
Bu bölümde, bir V2 işinde V1 FileDataset ve TabularDataset veri varlıklarının nasıl okunduğu açıklanmaktadır.
FileDataset oku
Input nesnesinde, type'yi AssetTypes.MLTABLE olarak ve mode'yi InputOutputModes.EVAL_MOUNT olarak belirtin.
Not
Sunucusuz işlem kullanmak için, bu kodda compute="cpu-cluster", silin.
MLClient nesnesi, MLClient nesnesi başlatma seçenekleri ve çalışma alanına bağlanma hakkında daha fazla bilgi için Çalışma alanına bağlanma'yı ziyaret edin.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
TabularDataset oku
Input nesnesinde, type öğesini AssetTypes.MLTABLE olarak ve mode öğesini InputOutputModes.DIRECT olarak belirtin.
Not
Sunucusuz işlem kullanmak için, bu kodda compute="cpu-cluster", silin.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint
Cleanup
Bu öğretici için artık ihtiyacınız olmayan Azure kaynakları oluşturduysanız maliyetlerin oluşmasını önlemek için bunları kaldırın:
İşlem kümenizi sıfır düğüme ölçeklendirin veya artık ihtiyacınız yoksa silin:
az ml compute update --name cpu-cluster --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME> --min-instances 0Test sırasında oluşturduğunuz çıktı veri varlıklarını veya depolama kapsayıcılarını silin.
Sonraki adımlar
- Modelleri eğit
- Öğretici: Python SDK v2 ile üretim ML işlem hatları oluşturma
- Azure Machine Learning'deki Veriler hakkında daha fazla bilgi edinin