Sorgu & denemeleri ve çalıştırmaları MLflow ile karşılaştırma
Azure Machine Learning'deki denemeler ve işler (veya çalıştırmalar) MLflow kullanılarak sorgulanabilir. Buluta özgü bağımlılıkları kaldırarak yerel çalıştırmalar ile bulut arasında daha sorunsuz bir geçiş oluşturarak bir eğitim işinin içinde gerçekleşenleri yönetmek için belirli bir SDK yüklemeniz gerekmez. Bu makalede, Python'da Azure Machine Learning ve MLflow SDK'sını kullanarak çalışma alanınızdaki denemeleri ve çalıştırmaları sorgulamayı ve karşılaştırmayı öğreneceksiniz.
MLflow şunları yapmanızı sağlar:
- Çalışma alanında deneme oluşturma, sorgulama, silme ve arama.
- Çalışma alanında çalıştırmaları sorgulama, silme ve arama.
- Çalıştırmalardan ölçümleri, parametreleri, yapıtları ve modelleri izleyin ve alın.
Azure Machine Learning'e bağlıyken açık kaynak MLflow ile MLflow arasında ayrıntılı bir karşılaştırma için bkz . Azure Machine Learning'de çalıştırmaları ve denemeleri sorgulamaya yönelik destek matrisi.
Not
Azure Machine Learning Python SDK v2 yerel günlük veya izleme özellikleri sağlamaz. Bu yalnızca günlüğe kaydetme için değil, günlüğe kaydedilen ölçümleri sorgulamak için de geçerlidir. Bunun yerine, denemeleri ve çalıştırmaları yönetmek için MLflow kullanın. Bu makalede, Azure Machine Learning'de denemeleri ve çalıştırmaları yönetmek için MLflow'un nasıl kullanılacağı açıklanmaktadır.
Ayrıca MLflow REST API'sini kullanarak denemeleri ve çalıştırmaları sorgulayabilir ve arayabilirsiniz. Nasıl kullanıldığı hakkında bir örnek için bkz . Azure Machine Learning ile MLflow REST kullanma.
Önkoşullar
MLflow SDK paketini
mlflowve MLflow için Azure Machine Learningazureml-mlfloweklentisini yükleyin:pip install mlflow azureml-mlflowİpucu
SQL depolama, sunucu, kullanıcı arabirimi veya veri bilimi bağımlılıkları olmadan basit bir MLflow paketi olan paketini kullanabilirsiniz
mlflow-skinny.mlflow-skinnydağıtımlar dahil olmak üzere tüm özellik paketini içeri aktarmadan öncelikle MLflow izleme ve günlüğe kaydetme özelliklerine ihtiyaç duyan kullanıcılar için önerilir.Azure Machine Learning çalışma alanı. Çalışma alanı oluşturmak için Makine öğrenmesi kaynakları oluşturma öğreticisine bakın. Çalışma alanınızda MLflow işlemlerinizi gerçekleştirmek için ihtiyacınız olan erişim izinlerini gözden geçirin.
Uzaktan izleme gerçekleştirirseniz (yani Azure Machine Learning dışında çalışan denemeleri izleyin), MLflow'ı Azure Machine Learning çalışma alanınızın izleme URI'sine işaret eden şekilde yapılandırın. MLflow'u çalışma alanınıza bağlama hakkında daha fazla bilgi için bkz . Azure Machine Learning için MLflow'u yapılandırma.
Sorgu ve arama denemeleri
Çalışma alanınızın içindeki denemeleri aramak için MLflow kullanın. Aşağıdaki örneklere bakın:
Tüm etkin denemeleri edinin:
mlflow.search_experiments()Not
MLflow'un (<2.0) eski sürümlerinde bunun yerine yöntemini
mlflow.list_experiments()kullanın.Arşivlenmiş de dahil olmak üzere tüm denemeleri alın:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)Belirli bir denemeyi ada göre alın:
mlflow.get_experiment_by_name(experiment_name)Belirli bir denemeyi kimlikle alın:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
Arama denemeleri
search_experiments() Mlflow 2.0'dan bu yana kullanılabilen yöntemi, kullanarak filter_stringölçütlere uyan denemeleri aramanıza olanak tanır.
Kimliklerine göre birden çok deneme alın:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )Belirli bir süreden sonra oluşturulan tüm denemeleri alın:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")Belirli bir etikete sahip tüm denemeleri alın:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
Sorgu ve arama çalıştırmaları
MLflow, aynı anda birden çok deneme dahil olmak üzere tüm denemelerin içindeki çalıştırmaları aramanıza olanak tanır. yöntemi mlflow.search_runs() bağımsız değişkenini experiment_ids kabul eder ve experiment_name hangi denemeleri aramak istediğinizi belirtir. Çalışma alanında tüm denemelerde arama yapmak isteyip istemediğinizi de belirtebilirsiniz search_all_experiments=True :
Deneme adına göre:
mlflow.search_runs(experiment_names=[ "my_experiment" ])Deneme kimliğine göre:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])Çalışma alanında tüm denemelerde arama yapın:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
experiment_ids Gerekirse birden çok denemede arama yapabileceğiniz bir dizi deneme sağlamayı desteklediğine dikkat edin. Bu, farklı denemelerde (örneğin, farklı kişiler veya farklı proje yinelemeleri) oturum açarken aynı modelin çalıştırmalarını karşılaştırmak istediğinizde yararlı olabilir.
Önemli
, experiment_namesveya search_all_experiments belirtilmezseexperiment_ids, MLflow geçerli etkin denemede varsayılan olarak arar. etkin denemeyi kullanarak mlflow.set_experiment()ayarlayabilirsiniz.
Varsayılan olarak, MLflow verileri Pandas Dataframe biçiminde döndürür ve bu da çalıştırmaların analizini daha fazla işlerken kullanışlı olmasını sağlar. Döndürülen veriler şunlara sahip sütunlar içerir:
- Çalıştırma hakkında temel bilgiler.
- Sütunun adına
params.<parameter-name>sahip parametreler. - Sütunun adına
metrics.<metric-name>sahip ölçümler (her birinin son günlüğe kaydedilen değeri).
Sorgu çalıştırılırken tüm ölçümler ve parametreler de döndürülür. Ancak, birden çok değer içeren ölçümler için (örneğin, bir kayıp eğrisi veya çekme isteği eğrisi), yalnızca ölçümün son değeri döndürülür. Belirli bir ölçümün tüm değerlerini almak istiyorsanız yöntemini kullanır mlflow.get_metric_history . Örnek için bkz . Çalıştırmadan parametreleri ve ölçümleri alma.
Sipariş çalıştırmaları
Varsayılan olarak, denemeler tarafından azalan sıradadır start_timeve bu, denemenin Azure Machine Learning'de kuyruğa alındığı zamandır. Ancak parametresini order_bykullanarak bu varsayılanı değiştirebilirsiniz.
Sıralama, gibi
start_timeözniteliklere göre çalışır:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])Çalıştırmaları sıralayın ve sonuçları sınırlayın. Aşağıdaki örnek, denemedeki son tek çalıştırmayı döndürür:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])Order, özniteliğine
durationgöre çalışır:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])İpucu
attributes.durationMLflow OSS'de mevcut değildir, ancak kolaylık sağlamak için Azure Machine Learning'de sağlanır.Sıralama ölçümün değerlerine göre çalışır:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)Uyarı
parametresinde ,
params.*veyatags.*içerenmetrics.*ifadelerle kullanılmasıorder_byşu anda desteklenmemektedir.order_byBunun yerine, örnekte gösterildiği gibi Pandas'tan yöntemini kullanınorder_values.
Filtre çalıştırmaları
parametresini filter_stringkullanarak hiper parametrelerde belirli bir bileşime sahip bir çalıştırma da arayabilirsiniz. Çalıştırmanın parametrelerine erişmek, metrics çalıştırmada günlüğe kaydedilen ölçümlere erişmek ve attributes çalıştırma bilgilerine erişmek için kullanınparams. MLflow, AND anahtar sözcüğüyle birleştirilen ifadeleri destekler (söz dizimi OR'yi desteklemez):
Arama, bir parametrenin değerine göre çalışır:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")Uyarı
Yalnızca ,
likeve!=işleçleri=filtrelemeparametersiçin desteklenir.Arama, ölçümün değerine göre çalışır:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")Arama, belirli bir etiketle çalışır:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")Belirli bir kullanıcı tarafından oluşturulan arama çalıştırmaları:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")Başarısız olan arama çalıştırmaları. Olası değerler için bkz . Çalıştırmaları duruma göre filtreleme:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")Belirli bir süreden sonra oluşturulan arama çalıştırmaları:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")İpucu
anahtarı
attributesiçin değerler her zaman dize olmalı ve bu nedenle tırnak işaretleri arasında kodlanmalıdır.Arama çalıştırmaları bir saatten uzun sürer:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")İpucu
attributes.durationMLflow OSS'de mevcut değildir, ancak kolaylık sağlamak için Azure Machine Learning'de sağlanır.Kimliği belirli bir kümede olan arama çalıştırmaları:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
Duruma göre filtre çalıştırmaları
Çalıştırmaları duruma göre filtrelediğinizde MLflow, Azure Machine Learning ile karşılaştırıldığında çalıştırmanın farklı olası durumunu adlandırmak için farklı bir kural kullanır. Aşağıdaki tabloda olası değerler gösterilmektedir:
| Azure Machine Learning iş durumu | MLFlow'un attributes.status |
Anlamı |
|---|---|---|
| Başlatılmadı | Scheduled |
İş/çalıştırma Azure Machine Learning tarafından alındı. |
| Sıra | Scheduled |
İş/çalıştırma çalıştırılacak şekilde zamanlandı, ancak henüz başlamadı. |
| Hazırlanıyor | Scheduled |
İş/çalıştırma henüz başlatılmadı, ancak yürütmesi için bir işlem ayrıldı ve ortamı ve girişlerini hazırlıyor. |
| Çalışıyor | Running |
İş/çalıştırma şu anda etkin yürütme aşamasındadır. |
| Tamamlandı | Finished |
İş/çalıştırma hatasız tamamlandı. |
| Başarısız | Failed |
İş/çalıştırma hatalarla tamamlandı. |
| İptal edildi | Killed |
İş/çalıştırma kullanıcı tarafından iptal edildi veya sistem tarafından sonlandırıldı. |
Örnek:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
Ölçümleri, parametreleri, yapıtları ve modelleri alma
yöntemi search_runs , varsayılan olarak sınırlı miktarda bilgi içeren bir Pandas Dataframe döndürür. Gerekirse Python nesnelerini alabilirsiniz. Bu, bunlar hakkındaki ayrıntıları almak için yararlı olabilir. Çıkışın output_format nasıl döndürülür denetlemek için parametresini kullanın:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
Ardından ayrıntılara üyeden info erişilebilir. Aşağıdaki örnekte, nasıl alınacak gösterilmektedir run_id:
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
Çalıştırmadan parametreleri ve ölçümleri alma
çalıştırmaları kullanılarak output_format="list"döndürülürse, anahtarını datakullanarak parametrelere kolayca erişebilirsiniz:
last_run.data.params
Aynı şekilde ölçümleri sorgulayabilirsiniz:
last_run.data.metrics
Birden çok değer içeren ölçümler için (örneğin, bir kayıp eğrisi veya çekme isteği eğrisi), ölçümün yalnızca son günlüğe kaydedilen değeri döndürülür. Belirli bir ölçümün tüm değerlerini almak istiyorsanız yöntemini kullanır mlflow.get_metric_history . Bu yöntem için komutunu kullanmanız MlflowClientgerekir:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
Bir çalıştırmadan yapıt alma
MLflow, bir çalıştırma tarafından günlüğe kaydedilen tüm yapıtları sorgulayabilir. Yapıtlara çalıştırma nesnesinin kendisi kullanılarak erişilemiyor ve bunun yerine MLflow istemcisi kullanılmalıdır:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
Yukarıdaki yöntem, çalıştırmada günlüğe kaydedilen tüm yapıtları listeler, ancak yapıt deposunda (Azure Machine Learning depolaması) depolanır. Bunlardan herhangi birini indirmek için yöntemini download_artifactkullanın:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
Not
MLflow'un (<2.0) eski sürümlerinde bunun yerine yöntemini MlflowClient.download_artifacts() kullanın.
Çalıştırmadan model alma
Modeller de çalıştırmada günlüğe kaydedilebilir ve doğrudan ondan alınabilir. Modeli almak için, depolandığı yapıtın yolunu bilmeniz gerekir. yöntemi list_artifacts , MLflow modelleri her zaman klasör olduğundan modeli temsil eden yapıtları bulmak için kullanılabilir. Yöntemini kullanarak download_artifact modelin depolandığı yolu belirterek modeli indirebilirsiniz:
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
Ardından, flavor'a özgü ad alanında tipik işlevi load_model kullanarak modeli indirilen yapıtlardan geri yükleyebilirsiniz. Aşağıdaki örnek şunu kullanır xgboost:
model = mlflow.xgboost.load_model(model_local_path)
MLflow aynı anda her iki işlemi de gerçekleştirmenize ve modeli tek bir yönergeyle indirip yüklemenize de olanak tanır. MLflow modeli geçici bir klasöre indirir ve oradan yükler. yöntemi load_model , modelin alınması gereken yeri belirtmek için bir URI biçimi kullanır. Bir çalıştırmadan model yükleme durumunda URI yapısı aşağıdaki gibidir:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
İpucu
Model kayıt defterine kayıtlı modelleri sorgulamak ve yüklemek için bkz . MLflow ile Azure Machine Learning'de model kayıt defterlerini yönetme.
Alt (iç içe) çalıştırmaları alma
MLflow, alt (iç içe) çalıştırmalar kavramını destekler. Bu çalıştırmalar, ana eğitim sürecinden bağımsız olarak izlenmesi gereken eğitim yordamlarını çalıştırmanız gerektiğinde kullanışlıdır. Hiper parametre ayarlama iyileştirme işlemleri veya Azure Machine Learning işlem hatları, birden çok alt çalıştırma oluşturan işlere örnek olarak verilebilir. Üst çalıştırmanın çalıştırma kimliğini içeren özellik etiketini mlflow.parentRunIdkullanarak belirli bir çalıştırmanın tüm alt çalıştırmalarını sorgulayabilirsiniz.
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
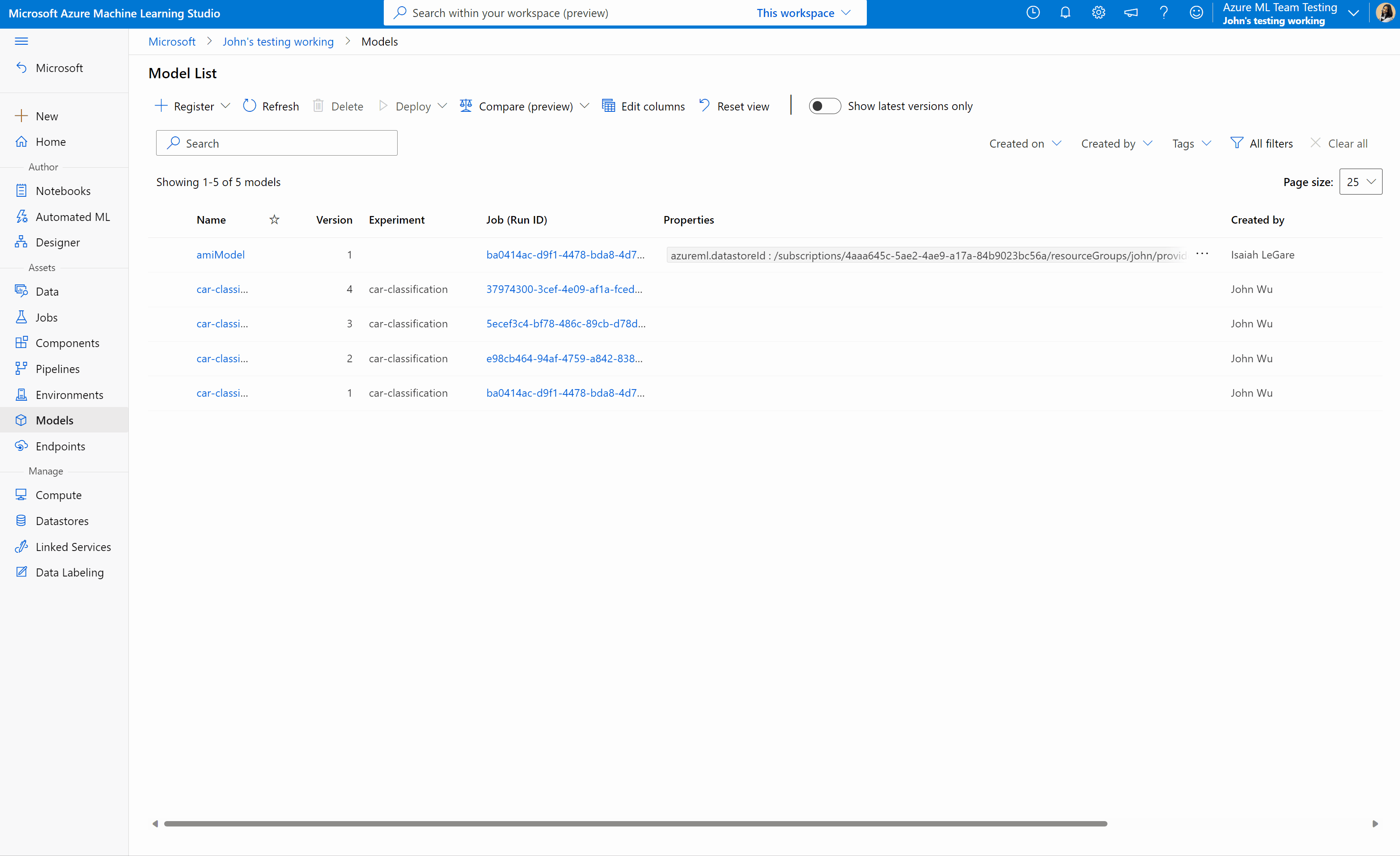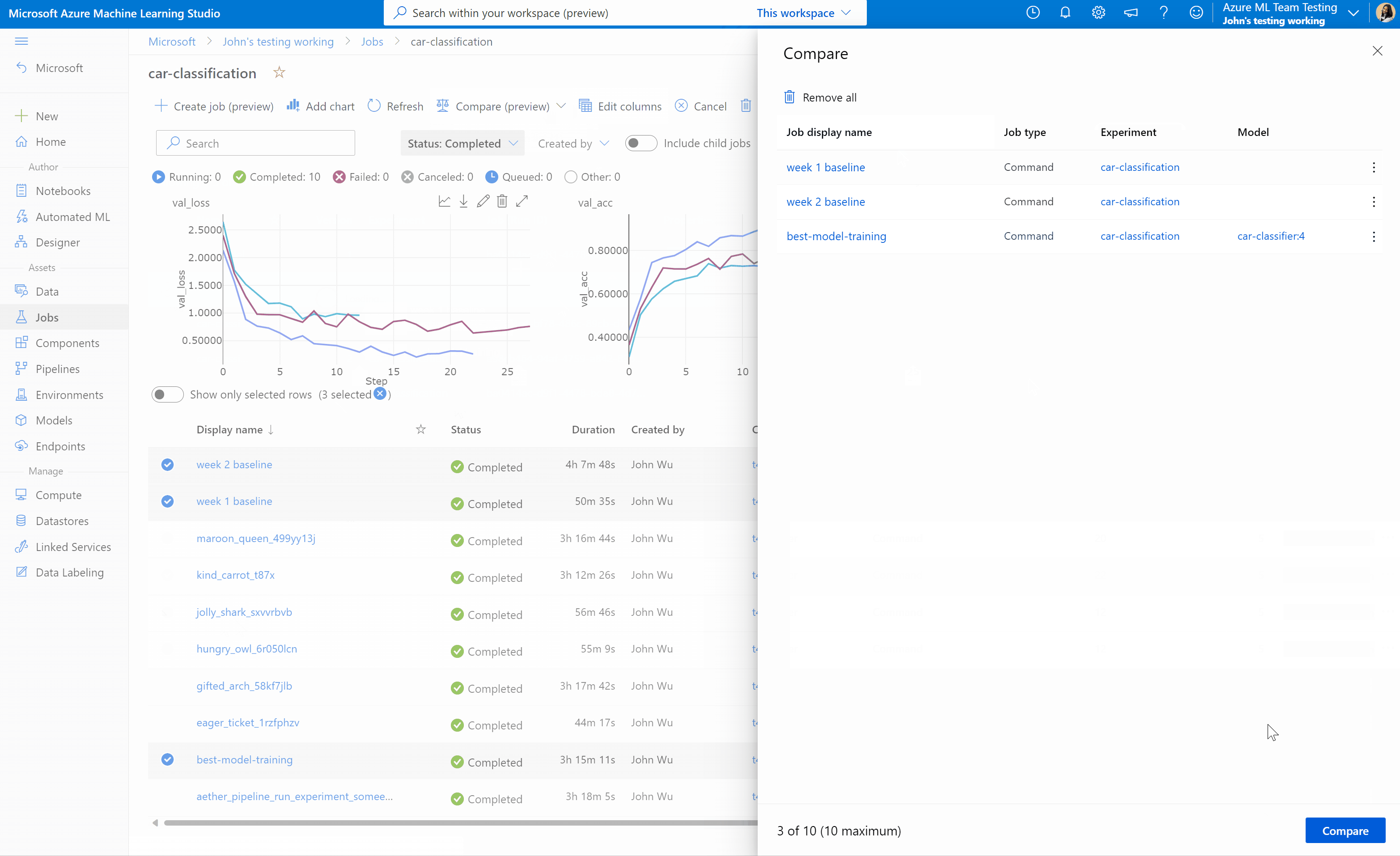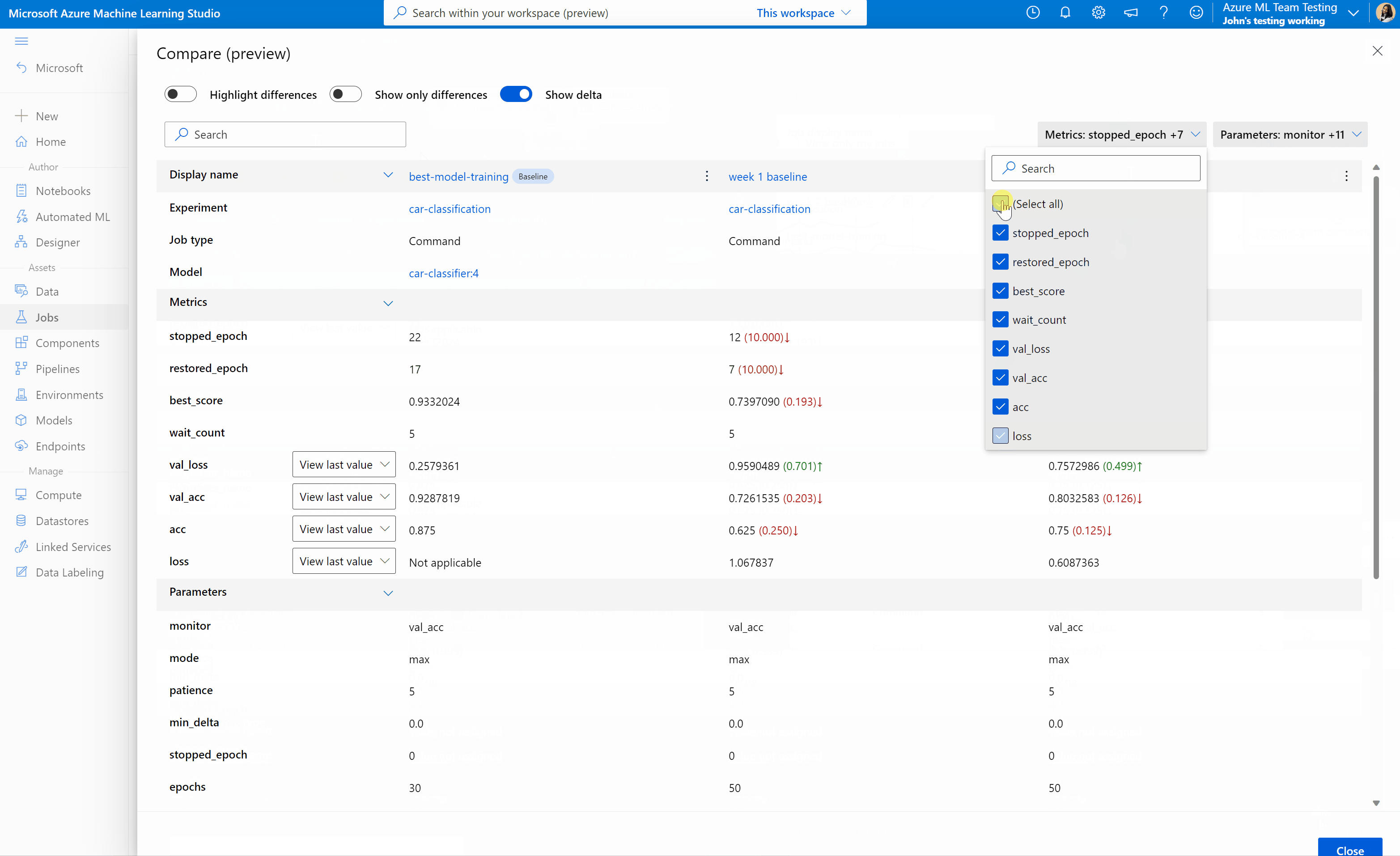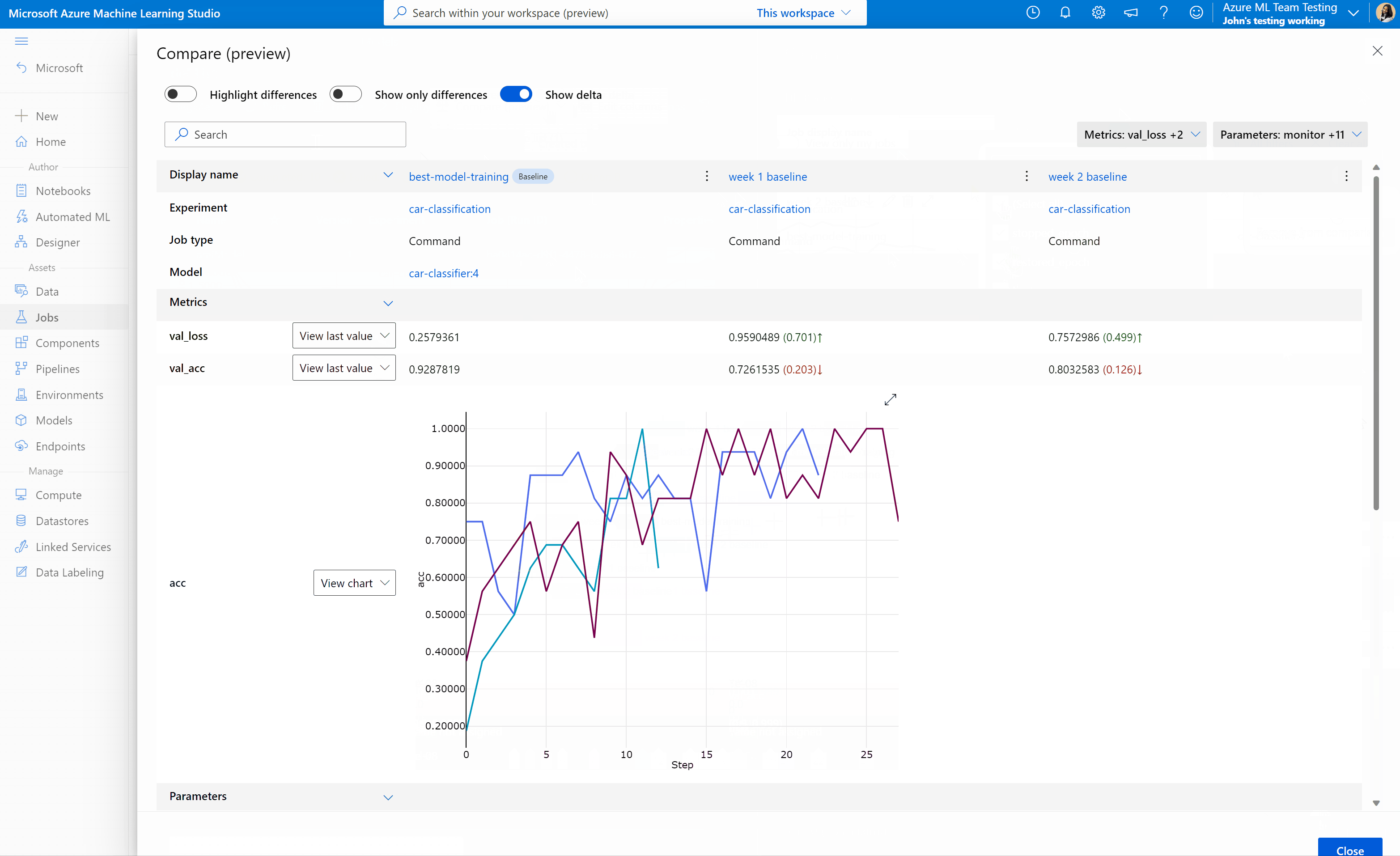
Azure Machine Learning stüdyosu işleri ve modelleri karşılaştırma (önizleme)
Azure Machine Learning stüdyosu'da işlerinizin ve modellerinizin kalitesini karşılaştırmak ve değerlendirmek için önizleme panelini kullanarak özelliği etkinleştirin. Etkinleştirildikten sonra, seçtiğiniz işler ve/veya modeller arasındaki parametreleri, ölçümleri ve etiketleri karşılaştırabilirsiniz.
Önemli
Bu makalede işaretlenen (önizleme) öğeler şu anda genel önizleme aşamasındadır. Önizleme sürümü bir hizmet düzeyi sözleşmesi olmadan sağlanır ve üretim iş yükleri için önerilmez. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
Azure Machine Learning not defterleri ile MLflow, bu makalede sunulan kavramları gösterir ve genişletir.
- MLflow ile bir sınıflandırıcıyı eğitme ve izleme: MLflow kullanarak denemeleri izlemeyi, modelleri günlüğe kaydetmeyi ve birden çok özelliği işlem hattında birleştirmeyi gösterir.
- MLflow ile denemeleri ve çalıştırmaları yönetme: MLflow kullanarak Azure Machine Learning'den denemeleri, çalıştırmaları, ölçümleri, parametreleri ve yapıtları sorgulamayı gösterir.
Çalıştırmaları ve denemeleri sorgulamaya yönelik destek matrisi
MLflow SDK'sı, döndürülenleri ve nasıl döndürüleceklerini denetleme seçenekleri de dahil olmak üzere çalıştırmaları almak için çeşitli yöntemler sunar. Azure Machine Learning'e bağlanıldığında bu yöntemlerden hangilerinin şu anda MLflow'da desteklendiği hakkında bilgi edinmek için aşağıdaki tabloyu kullanın:
| Özellik | MLflow tarafından desteklenir | Azure Machine Learning tarafından desteklenir |
|---|---|---|
| Özniteliklere göre çalıştırmaları sıralama | ✓ | ✓ |
| Ölçümlere göre çalıştırmaları sıralama | ✓ | 1 |
| Parametrelere göre sıralama çalıştırmaları | ✓ | 1 |
| Çalıştırmaları etiketlere göre sıralama | ✓ | 1 |
| Filtreleme özniteliklere göre çalışır | ✓ | ✓ |
| Filtreleme ölçümlere göre çalışır | ✓ | ✓ |
| Filtreleme, özel karakterler içeren ölçümlere göre çalışır (kaçış) | ✓ | |
| Filtreleme parametrelere göre çalışır | ✓ | ✓ |
| Filtreleme etiketlere göre çalışır | ✓ | ✓ |
Filtreleme , , , >=!=>, <, ve gibi =sayısal karşılaştırıcılarla (ölçümler) çalışır<= |
✓ | ✓ |
Filtreleme, dize karşılaştırıcılarıyla (parametreler, etiketler ve öznitelikler) çalışır: = ve != |
✓ | ✓2 |
Filtreleme, dize karşılaştırıcılarıyla (parametreler, etiketler ve öznitelikler) çalışır: LIKE/ILIKE |
✓ | ✓ |
Filtreleme, karşılaştırıcılarla çalışır AND |
✓ | ✓ |
Filtreleme, karşılaştırıcılarla çalışır OR |
||
| Denemeleri yeniden adlandırma | ✓ |
Not
- 1 Azure Machine Learning'de aynı işlevselliği elde etme yönergeleri ve örnekleri için Sıralama çalıştırmaları bölümünü gözden geçirin.
- Desteklenmeyen etiketler için 2
!=.