Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLAR İÇİN GEÇERLİDİR:  Python SDK azure-ai-ml v2 (güncel)
Python SDK azure-ai-ml v2 (güncel)
Bu eğitimde, siz:
- Verilerinizi bulut depolama alanına yükleme
- Azure Machine Learning veri varlığı oluşturma
- Etkileşimli geliştirme için not defterindeki verilerinize erişme
- Veri varlıklarının yeni sürümlerini oluşturma
Makine öğrenmesi projesi genellikle keşif veri analizi (EDA), veri ön işleme (temizleme, özellik mühendisliği) ve hipotezleri doğrulamak için makine öğrenmesi modeli prototipleri oluşturma ile başlar. Bu prototip oluşturma projesi aşaması yüksek oranda etkileşimlidir ve Python etkileşimli konsolu olan bir IDE veya Jupyter not defterinde geliştirmeye yardımcı olur. Bu öğreticide bu kavramlar açıklanmaktadır.
Önkoşullar
-
Azure Machine Learning'i kullanmak için bir çalışma alanı gerekir. Bir çalışma alanınız yoksa, çalışma alanı oluşturmak ve bunu nasıl kullanacağınız hakkında daha fazla bilgi edinmek için Başlamak için ihtiyaç duyduğunuz kaynakları oluşturun öğesini tamamlayın.
Önemli
Azure Machine Learning çalışma alanınız yönetilen bir sanal ağ ile yapılandırılmışsa, genel Python paket depolarına erişime izin vermek için giden kuralları eklemeniz gerekebilir. Daha fazla bilgi için bkz . Senaryo: Genel makine öğrenmesi paketlerine erişme.
-
Stüdyoda oturum açın ve henüz açık değilse çalışma alanınızı seçin.
-
Çalışma alanınızda bir not defteri açın veya oluşturun:
- Kod kopyalayıp hücrelere yapıştırmak istiyorsanız yeni bir not defteri oluşturun.
- Veya studio'nun Örnekler bölümünden tutorials/get-started-notebooks/explore-data.ipynb dosyasını açın. Ardından, not defterini Dosyalar'ınıza eklemek için Kopyala seçeneğini belirleyin. Örnek not defterlerini bulmak için Örnek not defterlerinden öğrenin bölümüne bakın.
Çekirdeğinizi ayarlayın ve Visual Studio Code'da (VS Code) açın
Açık not defterinizin üzerindeki üst çubukta, henüz bir hesaplama örneğiniz yoksa bir hesaplama örneği oluşturun.

Hesaplama örneği durdurulduysa, Hesaplamayı başlat seçeneğini belirleyin ve çalışır duruma gelene kadar bekleyin.

İşlem örneği çalışana kadar bekleyin. Ardından, sağ üstte bulunan çekirdeğin
Python 3.10 - SDK v2olduğundan emin olun. Aksi takdirde, bu çekirdeği seçmek için açılan listeyi kullanın.
Bu çekirdeği görmüyorsanız işlem örneğinizin çalıştığını doğrulayın. Bu durumda, not defterinin sağ üst kısmındaki Yenile düğmesini seçin.
Kimliğinizin doğrulanması gerektiğini belirten bir başlık görürseniz Kimliği Doğrula'yı seçin.
Not defterini burada çalıştırabilir veya Azure Machine Learning kaynaklarının gücüyle tam tümleşik bir geliştirme ortamı (IDE) için VS Code'da açabilirsiniz. VS Code'da Aç'ı ve ardından web veya masaüstü seçeneğini belirleyin. Bu şekilde başlatıldığında VS Code işlem örneğinize, çekirdeğinize ve çalışma alanı dosya sisteminize eklenir.





Önemli
Bu öğreticinin geri kalanı, öğretici not defterindeki hücrelerden oluşur. Bunları kopyalayıp yeni not defterinize yapıştırın veya kopyaladıysanız şimdi not defterine geçin.
Bu öğreticide kullanılan verileri indirin
Veri alımı için Azure Veri Gezgini ham verileri bu biçimlerde işler. Bu öğreticide CSV biçiminde kredi kartı istemci veri örneği kullanılmaktadır. Adımlar bir Azure Machine Learning kaynağında gerçekleşir. Bu kaynakta, doğrudan bu not defterinin bulunduğu klasörün altında, önerilen veri adıyla bir yerel klasör oluşturursunuz.
Not
Bu öğretici, Azure Machine Learning kaynak klasöründeki verilere dayanır. Bu öğreticide 'yerel', bu Azure Machine Learning kaynağındaki bir klasör konumu anlamına gelir.
Bu görüntüde gösterildiği gibi üç noktanın altındaki Terminali aç'ı seçin:
Terminal penceresi yeni bir sekmede açılır.
Dizini (
cd) bu not defterinin bulunduğu klasörle değiştirdiğinizden emin olun. Örneğin, not defteri get-started-notebooks adlı bir klasördeyse:cd get-started-notebooks # modify this to the path where your notebook is locatedVerileri işlem örneğine kopyalamak için terminal penceresine şu komutları girin:
mkdir data cd data # the subfolder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvArtık terminal penceresini kapatabilirsiniz.
UC Irvine Machine Learning Deposundaki veriler hakkında daha fazla bilgi için bu kaynağı ziyaret edin.
Çalışma alanı için bir kullanıcı adı oluşturun
Kodu keşfetmeden önce çalışma alanınıza başvurmak için bir yönteme ihtiyacınız vardır. Çalışma alanına başvuru olarak ml_client oluşturursunuz. Daha sonra kaynakları ve işleri yönetmek için kullanırsınız ml_client .
Sonraki hücreye Abonelik Kimliğinizi, Kaynak Grubu adınızı ve Çalışma Alanı adınızı girin. Bu değerleri bulmak için:
- Sağ üst Azure Machine Learning stüdyosu araç çubuğunda çalışma alanı adınızı seçin.
- Çalışma alanı, kaynak grubu ve abonelik kimliğinin değerini koda kopyalayın.
- Her değeri birer birer kopyalamanız gerekir. Alanı kapatın, değeri yapıştırın ve sonrakine geçin.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Not
MLClient oluşturmak, çalışma alanına bağlantı kurmaz. İstemci başlatması yavaştır ve ilk kez çağrı yapmasını bekler. Bu, sonraki kod hücresinde gerçekleşir.
Verileri bulut depolama alanına yükleme
Azure Machine Learning, buluttaki depolama konumlarına işaret eden Tekdüzen Kaynak Tanımlayıcıları 'nı (URI) kullanır. URI, not defterlerindeki ve işlerdeki verilere erişmeyi kolaylaştırır. Veri URI biçimleri, web sayfalarına erişmek için web tarayıcınızda kullandığınız web URL'lerine benzer. Örneğin:
- Genel https sunucusundan verilere erişin:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Azure Data Lake 2. Nesil'den verilere erişme:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Azure Machine Learning veri varlığı, web tarayıcısı yer işaretlerine (sık kullanılanlar) benzer. En sık kullandığınız verilere işaret eden uzun depolama yollarını (URI' ler) hatırlamak yerine, bir veri varlığı oluşturabilir ve bu varlığa kolay bir adla erişebilirsiniz.
Veri varlığı oluşturma işlemi, veri kaynağı konumuna bir referans ile birlikte meta verilerinin bir kopyasını da oluşturur. Veriler mevcut konumunda kaldığından ek depolama maliyetine neden olmaz ve veri kaynağı bütünlüğünü riske atmazsınız. Azure Machine Learning veri depolarından, Azure Depolama'dan, genel URL'lerden ve yerel dosyalardan veri varlıkları oluşturabilirsiniz.
İpucu
Daha küçük veri yüklemeleri için Azure Machine Learning veri varlığı oluşturma işlemi, yerel makine kaynaklarından bulut depolama alanına veri yüklemek için iyi bir şekilde çalışır. Bu yaklaşım, ek araçlara veya yardımcı programlara ihtiyaç duymayı önler. Ancak, daha büyük veri yüklemeleri için ayrılmış bir araç veya yardımcı program (örneğin, azcopy) gerekebilir. AzCopy komut satırı aracı, verileri Azure Depolama'ya ve Azure Depolama'dan taşır. azcopy hakkında daha fazla bilgi için bkz. AzCopy'yi kullanmaya başlama.
Sonraki not defteri hücresi veri varlığını oluşturur. Kod örneği, ham veri dosyasını belirlenen bulut depolama kaynağına yükler.
Her veri varlığı oluşturduğunuzda, bunun için benzersiz bir sürüm gerekir. Sürüm zaten mevcutsa bir hata alırsınız. Bu kodda, verilerin ilk okuması için "initial" kullanırsınız. Bu sürüm zaten varsa kod yeniden oluşturmaz.
Sürüm parametresini de atlayabilirsiniz. Bu durumda, 1 ile başlayıp oradan artırılarak sizin için bir sürüm numarası oluşturulur.
Bu öğreticide ilk sürüm olarak "initial" adı kullanılır. Üretim makinesi öğrenmesi işlem hatları oluşturma öğreticisi, verilerin bu sürümünü de kullandığından, bu öğreticide yeniden gördüğünüz bir değeri kullanırsınız.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# Update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# Set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Karşıya yüklenen verileri incelemek için sol gezinti menüsünün Varlıklar bölümünde Veriler'i seçin. Veri yüklenir ve bir veri varlığı oluşturulur:
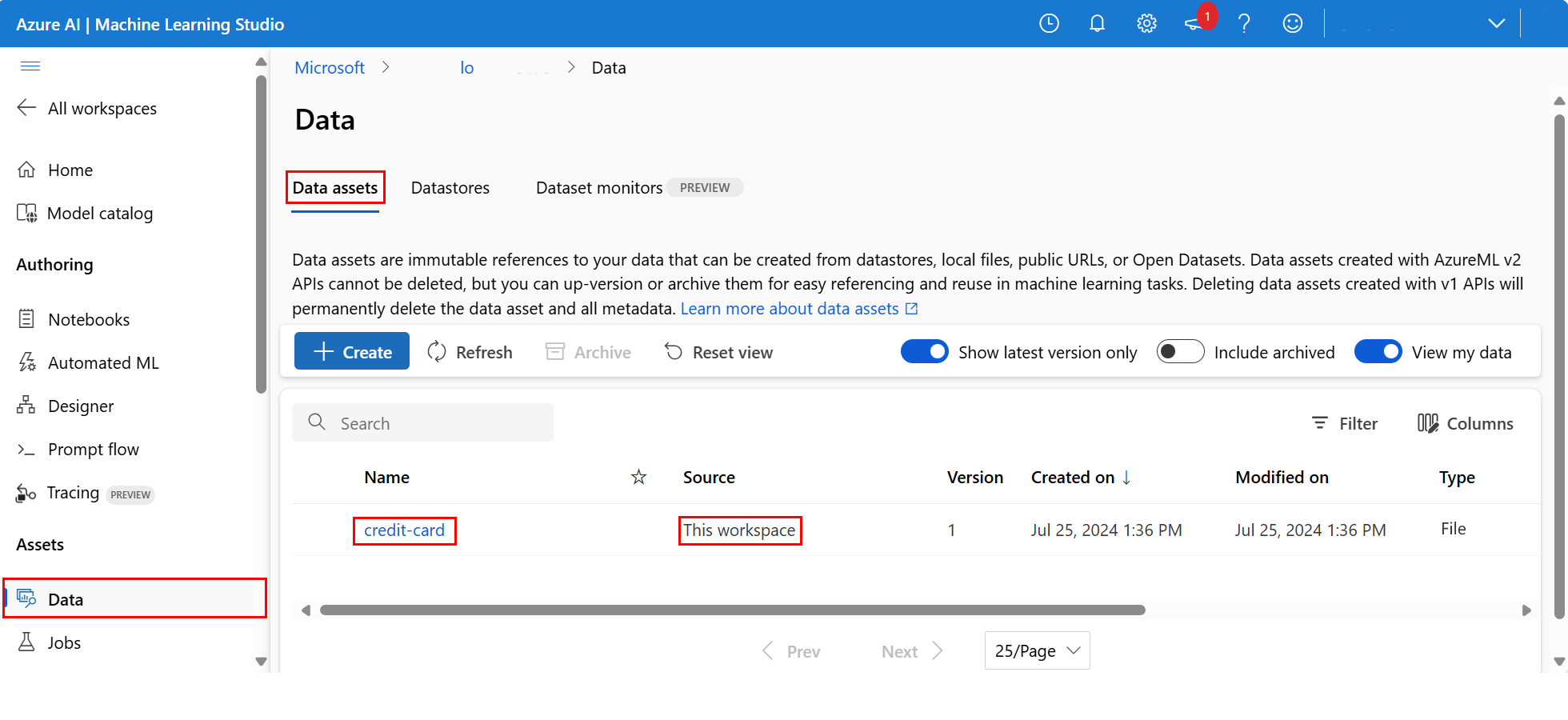
Bu veriler kredi kartı olarak adlandırılır. Veri varlıkları sekmesindeki Ad sütununda onu görebilirsiniz.
Azure Machine Learning veri deposu, Azure'daki mevcut bir depolama hesabına başvurudur. Veri deposu şu avantajları sunar:
Farklı depolama türleriyle etkileşime geçmek için yaygın ve kullanımı kolay bir API:
- Azure Data Lake Storage
- Damlacık
- Dosyalar
ve kimlik doğrulama yöntemleri.
Ekip olarak çalışırken yararlı veri depolarını bulmanın daha kolay bir yolu.
Betiklerinizde, kimlik bilgilerine dayalı veri erişimi (hizmet sorumlusu/SAS/anahtar) için bağlantı bilgilerini gizlemenin bir yolu.
Not defterindeki verilerinize erişme
Sık erişilen veriler için veri varlıkları oluşturmak istiyorsunuz. Veri deposu URI'sinden verilere erişme bölümünde açıklandığı gibi URI'yi kullanarak verilere bir dosya sisteminden erişebilirsiniz. Ancak, daha önce belirtildiği gibi, bu URI'leri hatırlamak zor olabilir.
Alternatif olarak, Azure Machine Learning veri depoları için bir dosya sistemi arabirimi sağlayan kitaplığı kullanabilirsiniz azureml-fsspec . Bu, Pandas'taki CSV dosyasına erişmenin daha kolay bir yoludur:
Önemli
Not defteri hücresinde şu kodu yürüterek Python kitaplığını azureml-fsspec Jupyter çekirdeğinize yükleyin:
%pip install -U azureml-fsspec
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# Read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Not defterindeki veri erişimi hakkında daha fazla bilgi için bkz. Etkileşimli geliştirme sırasında Azure bulut depolama alanından verilere erişme.
Veri varlığının yeni bir sürümünü oluşturma
Verilerin bir makine öğrenmesi modelini eğitmeye uygun hale getirmek için biraz hafif temizlemeye ihtiyacı vardır. Şunlara sahiptir:
- İki başlık
- Makine öğrenmesinde özellik olarak kullanılamayabilecek bir istemci kimliği sütunu
- Yanıt değişkeni adındaki boşluklar
Ayrıca, CSV biçimiyle karşılaştırıldığında, Parquet dosya biçimi bu verileri depolamak için daha iyi bir yoldur. Parquet sıkıştırma sunar ve şemayı korur. Verileri temizlemek ve Parquet biçiminde depolamak için:
# Read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# Rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# Remove ID column
df.drop("ID", axis=1, inplace=True)
# Write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Bu tablo, önceki bir adımda indirilen özgün default_of_credit_card_clients.csv dosyasındaki verilerin yapısını gösterir. Karşıya yüklenen veriler, burada gösterildiği gibi 23 açıklayıcı değişken ve 1 yanıt değişkeni içerir:
| Sütun Adları | Değişken Türü | Açıklama |
|---|---|---|
| X1 | Açıklayıcı | Verilen kredinin miktarı (NT dolar): Hem bireysel tüketici kredisini hem de aile (ek) kredisini içerir. |
| X2 | Açıklayıcı | Cinsiyet (1 = erkek; 2 = kadın). |
| X3 | Açıklayıcı | Eğitim (1 = lisansüstü okul; 2 = üniversite; 3 = lise; 4 = diğerleri). |
| X4 | Açıklayıcı | Medeni durum (1 = evli; 2 = bekar; 3 = diğerleri). |
| X5 | Açıklayıcı | Yaş (yıl). |
| X6-X11 | Açıklayıcı | Ödeme geçmişi Nisan ile Eylül 2005 arasında izlenen geçmiş aylık ödeme kayıtları. -1 = düzgün ödeme; 1 = bir ay boyunca ödeme gecikmesi; 2 = iki ay boyunca ödeme gecikmesi; . . .; 8 = sekiz ay boyunca ödeme gecikmesi; 9 = dokuz ay ve üzeri için ödeme gecikmesi. |
| X12-17 | Açıklayıcı | Nisan ile Eylül 2005 arasında fatura ekstresi (NT dolar) tutarı. |
| X18-23 | Açıklayıcı | Nisan ile Eylül 2005 arasında önceki ödeme tutarı (NT dolar). |
| Y | Yanıt | Varsayılan ödeme (Evet = 1, Hayır = 0) |
Ardından veri varlığının yeni bir sürümünü oluşturun. Veriler otomatik olarak bulut depolama alanına yüklenir. Bu sürüm için, bu kod her çalıştığında farklı bir sürüm numarası oluşturulsun diye bir zaman değeri ekleyin.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new version of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Temizlenen Parquet dosyası en son sürüm veri kaynağıdır. Bu kod önce CSV sürüm sonuç kümesini, ardından Parquet sürümünü gösterir:
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# Print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# Print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Kaynakları temizleme
Şimdi diğer öğreticilere geçmek istiyorsanız Sonraki adımlar bölümüne atlayın.
Hesaplama örneğini durdurun
Şimdi kullanmayı planlamıyorsanız işlem örneğini durdurun:
- Stüdyoda, sol bölmede İşlem'i seçin.
- Üst sekmelerde İşlem örnekleri'ni seçin.
- Listeden işlem örneğini seçin.
- Üst araç çubuğunda Durdur'u seçin.
Tüm kaynakları silme
Önemli
Oluşturduğunuz kaynaklar, diğer Azure Machine Learning öğreticileri ve nasıl yapılır makaleleri için önkoşul olarak kullanılabilir.
Oluşturduğunuz kaynaklardan hiçbirini kullanmayı planlamıyorsanız, ücret ödememek için bunları silin:
Azure portalındaki arama kutusuna Kaynak grupları yazın ve sonuçlardan seçin.
Listeden, oluşturduğunuz kaynak grubunu seçin.
Genel Bakış sayfasında Kaynak grubunu sil'i seçin.
Kaynak grubu adını girin. Ardından Sil'i seçin.
Sonraki adımlar
Veri varlıkları hakkında daha fazla bilgi için bkz. Veri varlıkları oluşturma.
Veri depoları hakkında daha fazla bilgi için bkz. Veri depoları oluşturma.
Eğitim betiği geliştirmeyi öğrenmek için sonraki eğitimle devam edin: