Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğretici serisinde Azure Machine Learning özelliklerini keşfetmek, oluşturmak ve kullanıma hazır hale getirmek için yönetilen özellik deposunu kullanmayı öğreneceksiniz. Özellikler makine öğrenmesi yaşam döngüsünün prototip oluşturma, eğitim ve operasyonelleştirme aşamalarını sorunsuz bir şekilde tümleştirir.
Prototip oluşturma aşamasında çeşitli özelliklerle denemeler yapın ve işletimselleştirme aşamasında özellik verilerini aramak için çıkarım adımlarını kullanan modelleri dağıtın. Özellikler yaşam döngüsünde bağ dokusu görevi görür.
Özellik mağazalarındaki özellikleri kullanarak çıkarım modellerini eğitmek için bir Azure Machine Learning proje çalışma alanı kullanırsınız. Birçok proje çalışma alanı aynı özellik depolarını paylaşabilir ve yeniden kullanabilir. Yönetilen özellik deposu hakkında daha fazla bilgi için bkz. Yönetilen özellik deposu nedir ve Yönetilen özellik deposundaki üst düzey varlıkları anlama.
Önkoşullar
- Azure Machine Learning çalışma alanı. Çalışma alanı oluşturma hakkında daha fazla bilgi için bkz . Hızlı Başlangıç: Çalışma alanı kaynakları oluşturma.
- Özellik deposunun oluşturulduğu kaynak grubunda sahip rolü.
SDK + CLI veya yalnızca SDK eğitim izleri
Bu öğretici serisinde geliştirme için bir Azure Machine Learning Spark not defteri kullanılır. İhtiyaçlarınıza bağlı olarak öğretici serisini tamamlamak için iki parça arasından seçim yapabilirsiniz.
SDK + CLI izlemesi özellik kümesi geliştirme ve test için Python SDK'sını ve oluşturma, okuma, güncelleştirme ve silme (CRUD) işlemleri için Azure CLI'yi kullanır. CLI ve YAML kullanan sürekli tümleştirme/teslim (CI/CD) veya GitOps senaryoları için bu yol kullanışlıdır.
Yalnızca SDK izlemesi yalnızca Python SDK'larını kullanır. Bu parça saf, Python tabanlı geliştirme ve dağıtım sunar.
Kopyaladığınız not defterinin cli_and_sdk veya sdk_only klasörlerindeki not defterlerinden birini açarak bir parça seçebilirsiniz. Eğitimlerin ilgili sekmesindeki yönergeleri izleyin.
SDK + CLI izlemesi, CRUD işlemleri için Azure CLI'yi ve özellik kümesi geliştirme ve test için özellik deposu çekirdek SDK'sını kullanır. Bu yaklaşım, CLI ve YAML kullanan GitOps veya CI/CD senaryoları için kullanışlıdır. Karşıya yüklediğiniz conda.yml dosyası bu kaynakları kurar.
- CLI, özellik depolarında, özellik kümelerinde ve özellik deposu varlıklarında CRUD işlemleri için kullanılır.
Özellik deposu temel SDK'sı
azureml-featurestoreözellik kümesi geliştirme ve tüketim içindir. SDK aşağıdaki işlemleri gerçekleştirir:- Kayıtlı bir özellik kümesini listeler veya getirir.
- Özellik getirme belirtimini oluşturur veya çözümler.
- Spark DataFrame oluşturmak için bir özellik kümesi tanımı yürütür.
- "Point-in-time join'ları kullanarak eğitim verileri oluşturur."
Öğretici 1: Özellik kümesi geliştirme ve kaydetme
Bu ilk öğreticide, özel dönüştürmelerle bir özellik kümesi belirtimi oluşturma adımları gösterilir. Ardından bu özellik kümesini eğitim verileri oluşturmak, materyalleştirmeyi etkinleştirmek ve bir geri doldurma işlemi gerçekleştirmek için kullanırsınız. Şunları yapmayı öğreneceksiniz:
- Yeni, en düşük düzeyde bir özellik deposu kaynağı oluşturun.
- Özellik dönüştürme özelliğiyle bir özellik kümesi geliştirin ve yerel olarak test edin.
- Özellik deposu varlığını özellik deposuna kaydedin.
- Geliştirdiğiniz özellik kümesini özellik deposuna kaydedin.
- Oluşturduğunuz özellikleri kullanarak örnek bir eğitim DataFrame oluşturun.
- Özellik kümelerinde çevrimdışı gerçekleştirmeyi etkinleştirin ve özellik verilerini yedekleyin.
Notebook'u kopyala
Azure Machine Learning studio'da sol gezinti menüsünde Not Defterleri'ni seçin ve ardından Not Defterleri sayfasındaki Örnekler sekmesini seçin.
SDK v2>sdk>python klasörlerini genişletin, featurestore_sample klasörüne sağ tıklayın ve Kopyala'yı seçin.
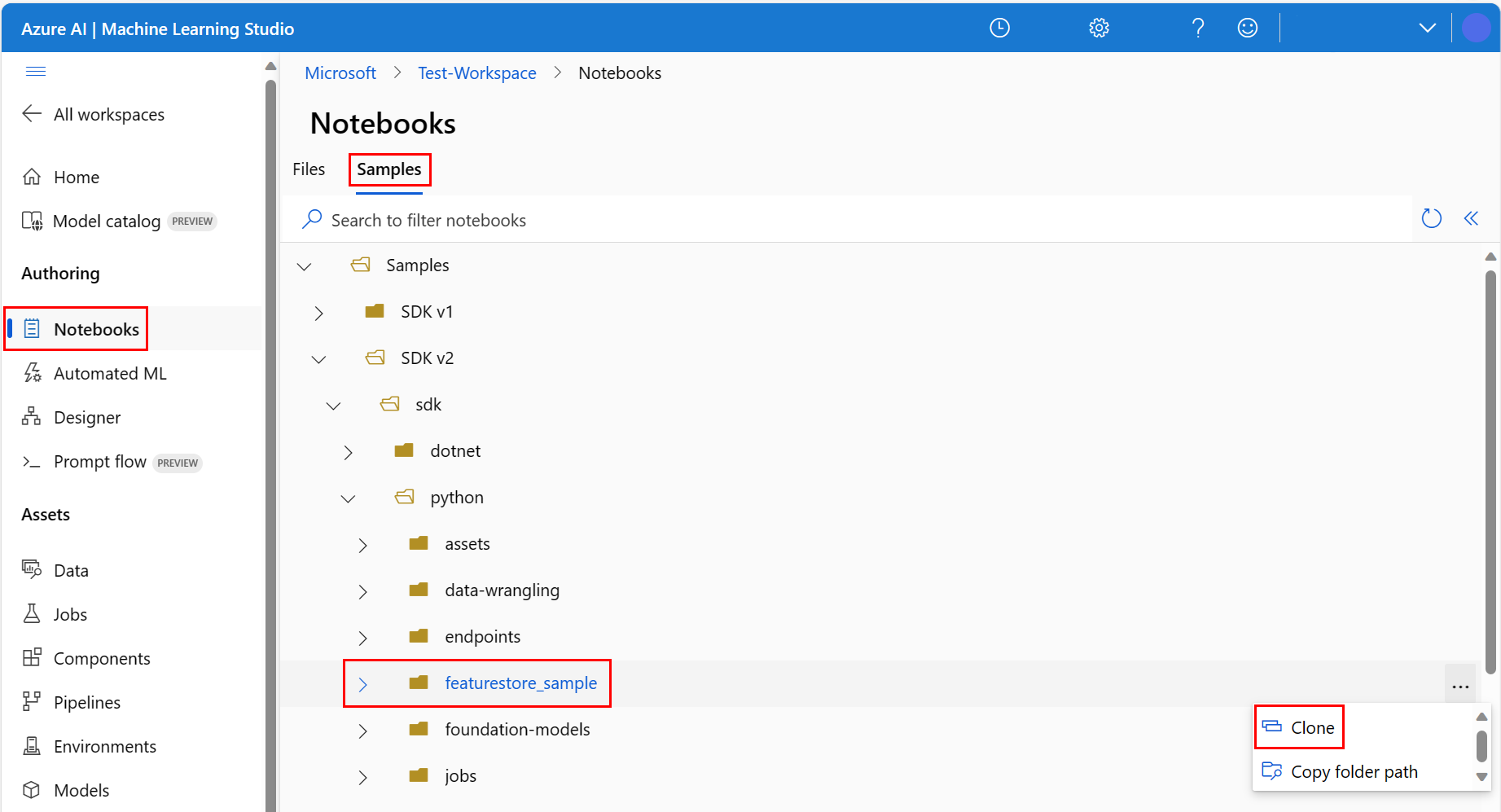
Hedef dizini seçin bölmesinde Kullanıcılar><your_username>>featurestore_sample listelendiğinden emin olun ve Klonla'yı seçin. featurestore_sample çalışma alanı kullanıcı dizininize klonlanır.
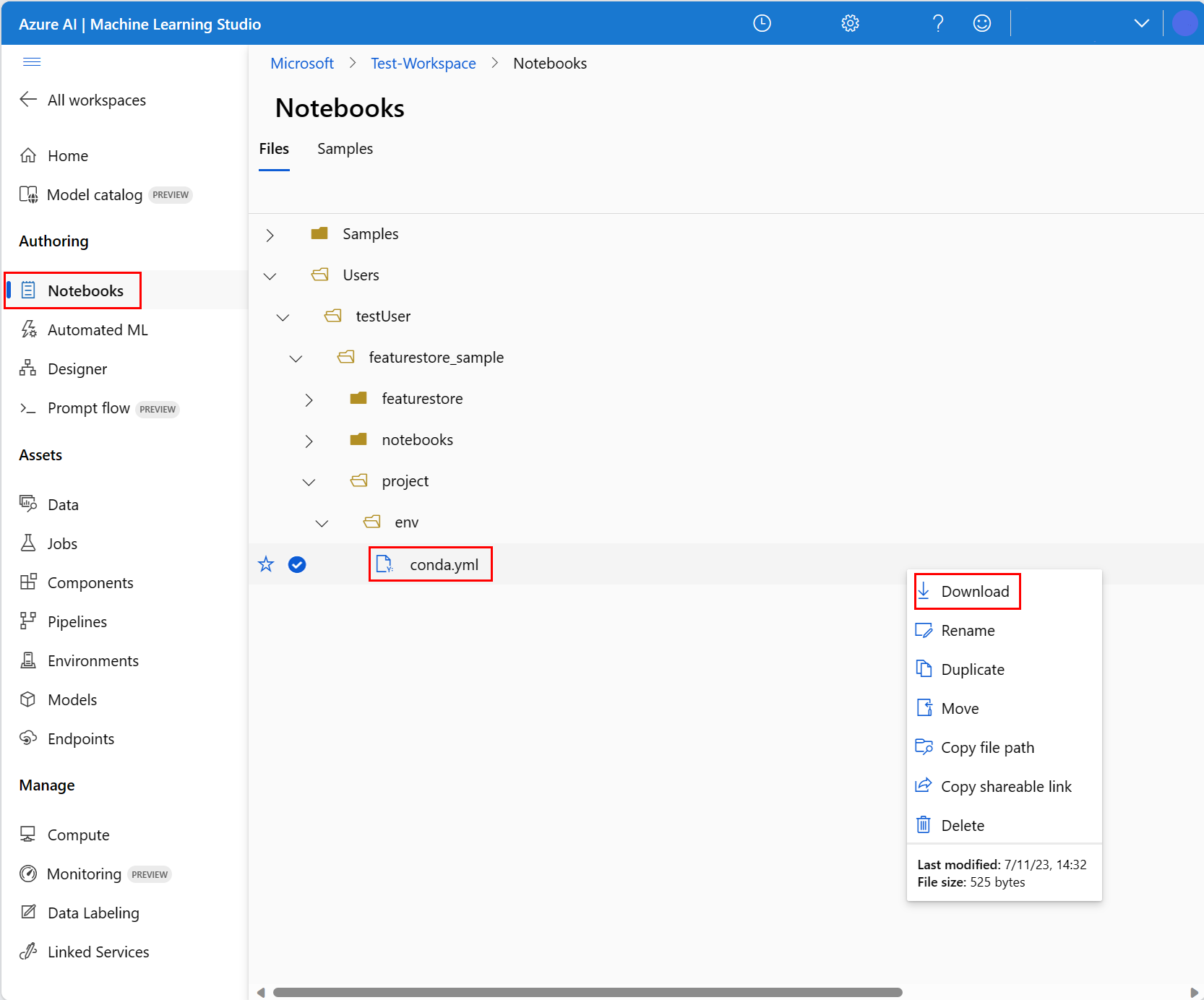
Not Defteri sayfasının Dosyalar sekmesinde kopyalanan not defterinize gidin ve Kullanıcılar><your_username>>featurestore_sample>proje>ortamı genişletin.
conda.yml dosyasına sağ tıklayıp İndir'i seçerek bilgisayarınıza indirin; böylece daha sonra sunucu ortamına yükleyebilirsiniz.
Dizüstü bilgisayarı hazırlayın ve başlatın
Dosyalar sekmesindeki sol bölmede, çalıştırmak istediğiniz yola bağlı olarak featurestore_sample>notebooks bölümünde > veya sdk_only kısmını genişletin.
Eğitimin ilk bölümünü açmak için onu seçin.
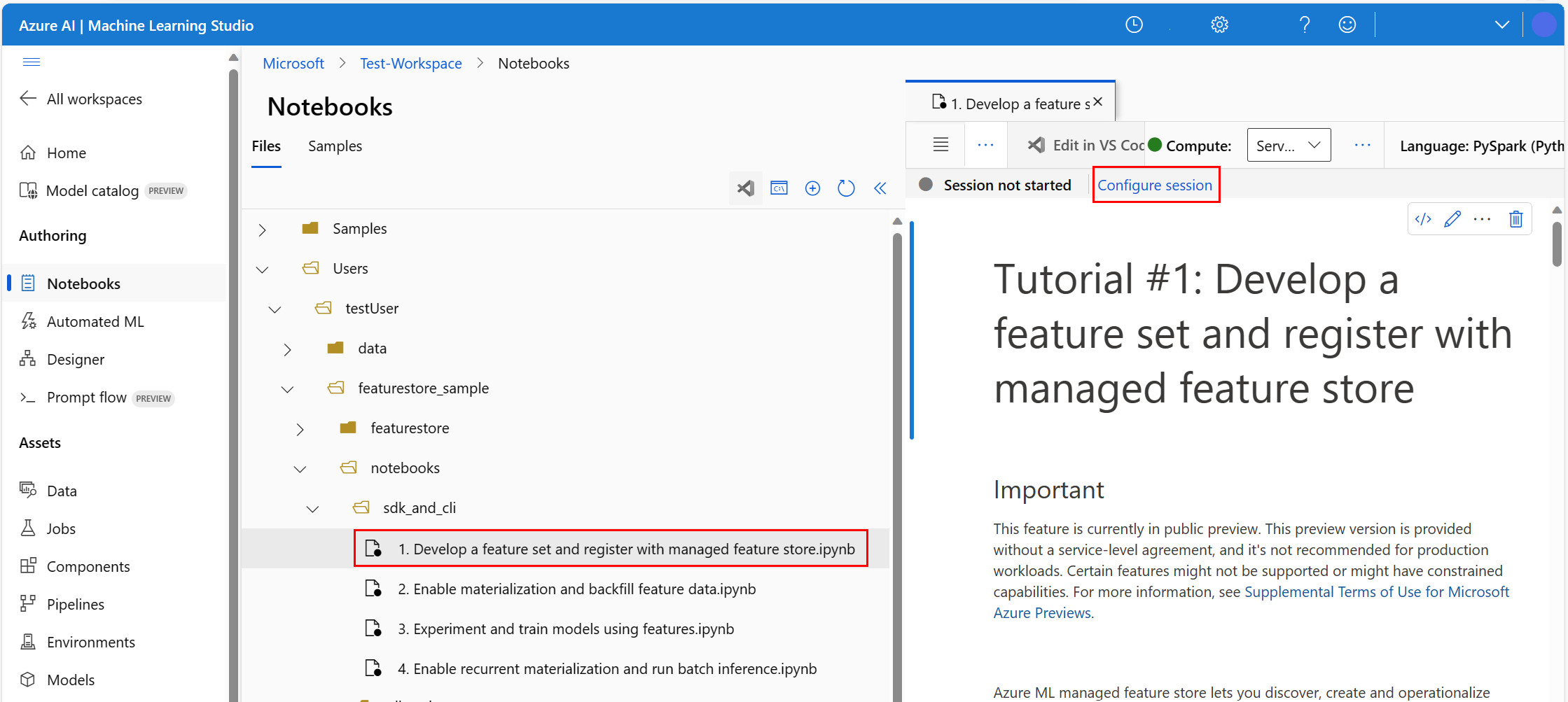
Not Defteri sayfasının sağ üst kısmında İşlem'in yanındaki açılan oku seçin ve Sunucusuz Spark İşlem - Kullanılabilir'i seçin. Hesaplama biriminin bağlanması bir veya iki dakika sürebilir.
Not defteri dosyasının üst çubuğunda Oturumu yapılandır'ı seçin.
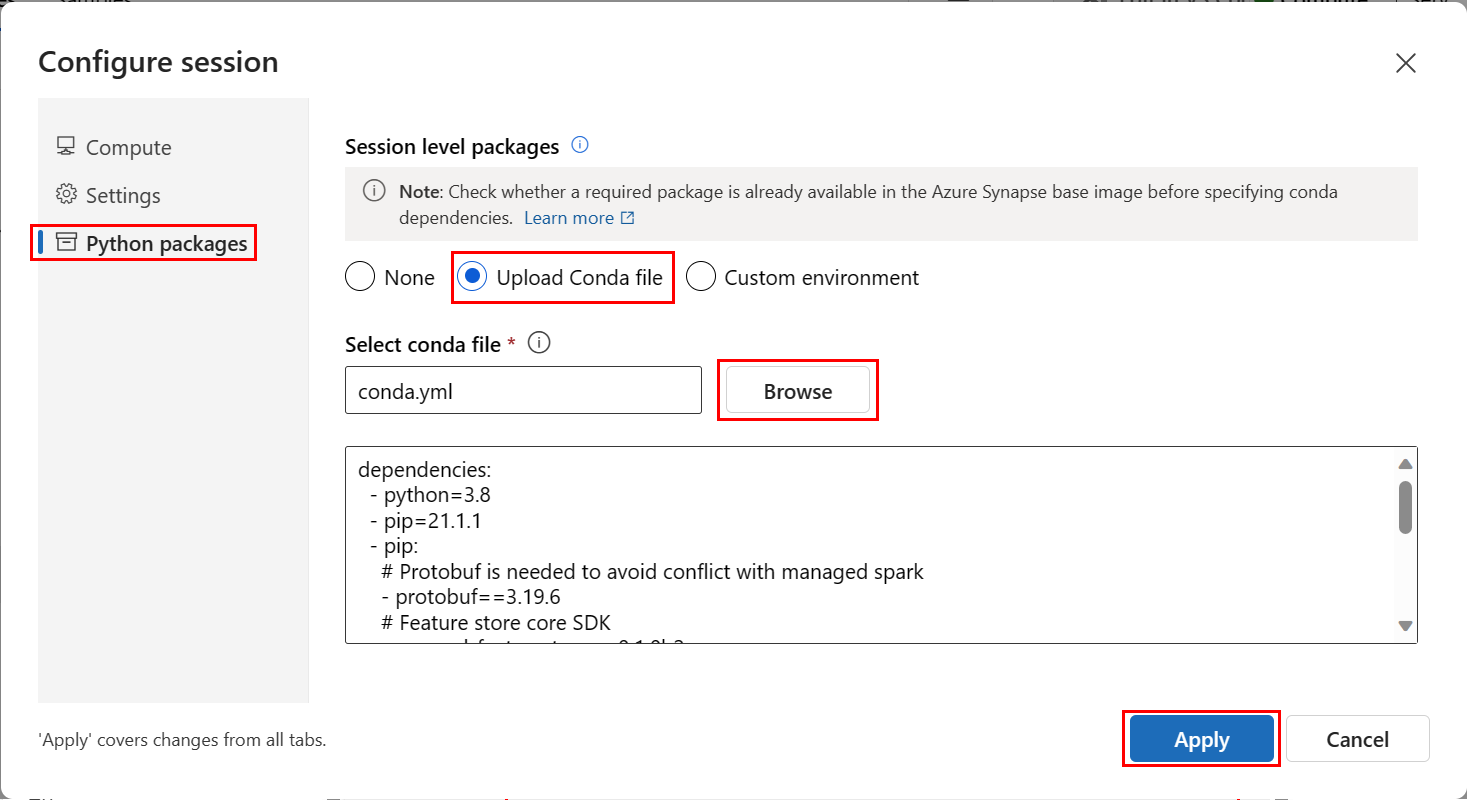
Oturumu yapılandır ekranında, sol bölmede Python paketleri'ni seçin.
Conda dosyasını karşıya yükle'yi seçin ve Conda dosyası seç altında, indirdiğiniz conda.yml dosyasını bulun ve açın.
İsteğe bağlı olarak, sol bölmede Ayarlar'ı seçin ve sunucusuz Spark başlangıç süresinin zaman aşımına uğramasını önlemeye yardımcı olmak için Oturum zaman aşımı uzunluğunu artırın.
Uygula'yı seçin.

Dizüstü bilgisayarı başlat
İlk hücreye ulaşana kadar not defterinde aşağı kaydırın ve oturumu başlatmak için bu hücreyi çalıştırın. Oturumun başlatılması 15 dakika kadar sürebilir.
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins. print("start spark session")İkinci hücrede yer tutucuyu
<your_user_alias>kullanıcı adınızla güncelleştirin. Örnek için kök dizini ayarlamak üzere hücreyi çalıştır.import os # Please update <your_user_alias> below (or any custom directory you uploaded the samples to). # You can find the name from the directory structure in the left navigation panel. root_dir = "./Users/<your_user_alias>/featurestore_sample" if os.path.isdir(root_dir): print("The folder exists.") else: print("The folder does not exist. Please create or fix the path")Azure Machine Learning CLI uzantısını yüklemek için sonraki hücreyi çalıştırın.
# Install AzureML CLI extension !az extension add --name mlAzure CLI'da kimlik doğrulaması yapmak için sonraki hücreyi çalıştırın.
# Authenticate !az loginVarsayılan Azure aboneliğini ayarlamak için sonraki hücreyi çalıştırın.
# Set default subscription import os subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] !az account set -s $subscription_id
En düşük özellik deposu oluşturma
Ad, konum ve diğer değerler de dahil olmak üzere özellik deposu parametrelerini ayarlayın. bir
<FEATURESTORE_NAME>sağlayın ve ardından hücreyi çalıştırın.# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Özellik depoyu oluşturun.
!az ml feature-store create --subscription $featurestore_subscription_id --resource-group $featurestore_resource_group_name --location $featurestore_location --name $featurestore_nameAzure Machine Learning için bir özellik deposu çekirdek SDK istemcisi başlatın. İstemci, özellikleri geliştirme ve kullanma amacıyla kullanılır.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Kullanıcı kimliğinize özellik deposunda AzureML Veri Bilimcisi rolünü verin. Kullanıcı nesne kimliğini bulma bölümünde açıklandığı gibi Azure portalından Microsoft Entra nesne kimliği değerinizi alın.
Özellik deposu çalışma alanında kaynak oluşturabilmesi için kullanıcı kimliğinize AzureML Veri Bilimcisi rolünü atamak için aşağıdaki hücreyi çalıştırın. Yer tutucuyu
<USER_AAD_OBJECTID>Microsoft Entra nesne kimliğiniz ile değiştirin. İzinlerin yayılması için biraz zaman gerekebilir.your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_idErişim denetimi hakkında daha fazla bilgi için bkz. Yönetilen özellik deposu için erişim denetimini yönetme.
Özellik kümesi prototipi oluşturma ve geliştirme
Bu not defteri, genel olarak erişilebilen bir blob kapsayıcısında barındırılan örnek verileri kullanır ve Spark verilerini yalnızca bir wasbs sürücü aracılığıyla okuyabilirsiniz. Kendi kaynak verilerinizi kullanarak özellik kümeleri oluşturursanız, bunları bir Azure Data Lake Storage hesabında barındırın ve veri yolunda bir abfss sürücü kullanın.
İşlemlerin kaynak verilerini keşfetme
Sıralı pencere toplama tabanlı özelliklere sahip adlı transactions bir özellik kümesi oluşturun.
# remove the "." in the roor directory path as we need to generate absolute path to read from spark
transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet"
transactions_src_df = spark.read.parquet(transactions_source_data_path)
display(transactions_src_df.head(5))
# Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueÖzellik kümesini yerel olarak geliştirme
Özellik kümesi belirtimi, yerel olarak geliştirip test edebilirsiniz özellik kümesinin bağımsız tanımıdır. Aşağıdaki kayan pencere toplama özelliklerini oluşturun:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
from azureml.featurestore import create_feature_set_spec
from azureml.featurestore.contracts import (
DateTimeOffset,
TransformationCode,
Column,
ColumnType,
SourceType,
TimestampColumn,
)
from azureml.featurestore.feature_source import ParquetFeatureSource
transactions_featureset_code_path = (
root_dir + "/featurestore/featuresets/transactions/transformation_code"
)
transactions_featureset_spec = create_feature_set_spec(
source=ParquetFeatureSource(
path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet",
timestamp_column=TimestampColumn(name="timestamp"),
source_delay=DateTimeOffset(days=0, hours=0, minutes=20),
),
feature_transformation=TransformationCode(
path=transactions_featureset_code_path,
transformer_class="transaction_transform.TransactionFeatureTransformer",
),
index_columns=[Column(name="accountID", type=ColumnType.string)],
source_lookback=DateTimeOffset(days=7, hours=0, minutes=0),
temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0),
infer_schema=True,
)Özellik dönüştürme kodu dosyasını gözden geçirin: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Özellikler için tanımlanan sıralı toplamaya dikkat edin. Bu dosya bir Spark transformatörüdür. Özellik kümesi ve dönüşümler hakkında daha fazla bilgi için bkz. Yönetilen özellik deposu nedir?
Özellik kümesi belirtimi olarak dışarı aktarma
Özellik kümesi belirtimini özellik deposuna kaydetmek için, bu belirtimi kaynak denetimini destekleyen belirtilen bir konuma ve biçimde kaydedersiniz.
import os
# Create a new folder to dump the feature set specification.
transactions_featureset_spec_folder = (
root_dir + "/featurestore/featuresets/transactions/spec"
)
# Check if the folder exists, create one if it does not exist.
if not os.path.exists(transactions_featureset_spec_folder):
os.makedirs(transactions_featureset_spec_folder)
transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml belirtimini görmek için, dosya ağacından oluşturulan transactions özellik kümesi belirtimini açın. Belirtim şu öğeleri içerir:
-
source: Depolama kaynağına başvuru. Bu durumda, blob depolama kaynağındaki bir parquet dosyasıdır. -
features: Özelliklerin ve bunların veri türlerinin listesi. Dönüştürme kodu sağlarsanız, kodun özelliklere ve veri türlerine eşleyen bir DataFrame döndürmesi gerekir. -
index_columns: Özellik kümesinden değerlere erişmek için gereken birleştirme anahtarları.
Özellik deposu varlığını kaydetme
Varlıklar, aynı mantıksal varlıkları kullanan özellik kümeleri arasında aynı birleştirme anahtarı tanımını kullanmanın en iyi uygulamasının uygulanmasına yardımcı olur. Varlıklara örnek olarak accounts ve customers verilebilir. Varlıklar genellikle bir kez oluşturulur ve ardından özellik kümeleri arasında yeniden kullanılır. Daha fazla bilgi edinmek için bkz. Yönetilen özellik deposundaki üst düzey varlıkları anlama.
türünde accountbirleştirme anahtarına accountID sahip bir string varlık oluşturun.
account Varlığı özellik deposuna kaydedin.
account_entity_path = root_dir + "/featurestore/entities/account.yaml"
!az ml feature-store-entity create --file $account_entity_path --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_nameÖzellik kümesini özellik deposuna kaydetme
Aşağıdaki kod bir özellik kümesi varlığını özellik deposuna kaydeder. Daha sonra bu varlığı yeniden kullanabilir ve kolayca paylaşabilirsiniz. Özellik kümesi varlığının kaydı, sürüm oluşturma ve gerçekleştirme dahil olmak üzere yönetilen özellikler sunar. Bu serinin sonraki eğitimleri yönetilen kabiliyetleri kapsar.
account_featureset_path = (
root_dir + "/featurestore/featuresets/transactions/featureset_asset.yaml"
)
!az ml feature-set create --file $account_featureset_path --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_nameÖzellik deposu kullanıcı arabirimini keşfetme
Özellik deposu varlık oluşturma ve güncelleştirmeler yalnızca SDK ve CLI aracılığıyla gerçeklenebilir. Özellik deposunda arama yapmak veya göz atmak için Machine Learning kullanıcı arabirimini kullanabilirsiniz.
- Azure Machine Learning genel giriş sayfasını açın.
- Sol bölmede Özellik depoları'nı seçin.
- Erişilebilir özellik depoları listesinden bu öğreticinin önceki bölümlerinde oluşturduğunuz özellik deposunu seçin.
Depolama Blobu Veri Okuyucusu rolünü atama
Depolama Blobu Veri Okuyucusu rolü, kullanıcı hesabının çevrimdışı gerçekleştirilmiş özellik deposundan gerçekleştirilmiş özellik verilerini okuyadığından emin olmak için kullanıcı hesabınıza atanmalıdır.
Özellik mağazası arayüzü Genel Bakış sayfasından çevrimdışı materyalizasyon deposu hakkında bilgi edinin. Depolama hesabı <SUBSCRIPTION_ID>, depolama hesabı <RESOURCE_GROUP>ve <STORAGE_ACCOUNT_NAME> çevrimdışı gerçekleştirme deposu için değerler Çevrimdışı gerçekleştirme deposu kartında bulunur.

Rol ataması için aşağıdaki kod hücresini çalıştırın. İzinlerin yayılması için biraz zaman gerekebilir.
storage_subscription_id = "<SUBSCRIPTION_ID>"
storage_resource_group_name = "<RESOURCE_GROUP>"
storage_account_name = "<STORAGE_ACCOUNT_NAME>"
# Set the ADLS Gen2 storage account ARM ID
gen2_storage_arm_id = "/subscriptions/{sub_id}/resourceGroups/{rg}/providers/Microsoft.Storage/storageAccounts/{account}".format(
sub_id=storage_subscription_id,
rg=storage_resource_group_name,
account=storage_account_name,
)
print(gen2_storage_arm_id)
!az role assignment create --role "Storage Blob Data Reader" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $gen2_storage_arm_idErişim denetimi hakkında daha fazla bilgi için bkz. Yönetilen özellik deposu için erişim denetimini yönetme.
Eğitim verileri için bir DataFrame oluşturun
Kayıtlı özellik setini kullanarak bir eğitim veri kümesi DataFrame oluşturun.
Olayın kendisi sırasında yakalanan gözlem verilerini yükleyin.
Gözlem verileri genellikle eğitim ve çıkarım için kullanılan temel verileri içerir ve tam eğitim veri kaynağını oluşturmak için özellik verileriyle birleşir. Aşağıdaki veriler işlem kimliği, hesap kimliği ve işlem tutarı değerleri dahil olmak üzere temel işlem verilerine sahiptir. Verileri eğitim için kullandığınızdan, ekli bir hedef değişkeni
is_fraudde vardır.observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueKayıtlı özellik kümesini alın ve özelliklerini listeleyin.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Eğitim verilerinin parçası olacak özellikleri seçin ve eğitim verilerinin kendisini oluşturmak için özellik deposu SDK'sını kullanın. Belirli bir noktaya birleştirme, özellikleri eğitim verilerine ekler.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value
Çevrimdışı maddeleşmeyi etkinleştirme
Gerçekleştirme, bir özellik penceresi için özellik değerlerini hesaplar ve bu değerleri bir gerçekleştirme deposunda depolar. Ardından tüm özellik sorguları bu değerleri gerçekleştirme deposundan kullanabilir.
Gerçekleştirme olmadan, özellik kümesi sorgusu anında kaynağa dönüştürmeler uygular ve değerleri döndürmeden önce özellikleri hesaplar. Bu işlem prototip oluşturma aşamasında iyi çalışır. Ancak, üretim ortamındaki eğitim ve çıkarım işlemleri için özelliklerin gerçekleştirilmesi daha fazla güvenilirlik ve kullanılabilirlik sağlar.
Özellik deposu için varsayılan blob deposu bir Azure Data Lake Storage (ADLS) kapsayıcısıdır. Özellik deposu her zaman çevrimdışı bir gerçekleştirme deposu ve kullanıcı tarafından atanan yönetilen kimlik (UAI) ile oluşturulur.
Varsayılan parametre değerleri offline_store=None ve materialization_identity=Noneile bir özellik deposu oluşturulursa sistem aşağıdaki kurulumu gerçekleştirir:
- Çevrimdışı depo olarak bir ADLS kapsayıcısı oluşturur.
- Bir UAI oluşturur ve bunu gerçekleştirme kimliği olarak özellik deposuna atar.
- Çevrimdışı depodaki UAI'ye gerekli rol tabanlı erişim denetimi (RBAC) izinlerini atar.
İsteğe bağlı olarak, offline_store parametresini tanımlayarak mevcut bir ADLS kapsayıcısını çevrimdışı depo olarak kullanabilirsiniz. Çevrimdışı malzemeleştirme depoları için yalnızca ADLS kapsayıcıları desteklenmektedir.
İsteğe bağlı olarak, bir parametre tanımlayarak mevcut bir materialization_identity UAI sağlayabilirsiniz. Gerekli RBAC izinleri, özellik deposu oluşturma sırasında çevrimdışı depodaki UAI'ye atanır.
Aşağıdaki kod örneği, kullanıcı tanımlı offline_store ve materialization_identity parametreleri olan bir özellik deposunun oluşturulmasını gösterir.
import os
from azure.ai.ml import MLClient
from azure.ai.ml.identity import AzureMLOnBehalfOfCredential
from azure.ai.ml.entities import (
ManagedIdentityConfiguration,
FeatureStore,
MaterializationStore,
)
from azure.mgmt.msi import ManagedServiceIdentityClient
# Get an existing offline store
storage_subscription_id = "<OFFLINE_STORAGE_SUBSCRIPTION_ID>"
storage_resource_group_name = "<OFFLINE_STORAGE_RESOURCE_GROUP>"
storage_account_name = "<OFFLINE_STORAGE_ACCOUNT_NAME>"
storage_file_system_name = "<OFFLINE_STORAGE_CONTAINER_NAME>"
# Get ADLS container ARM ID
gen2_container_arm_id = "/subscriptions/{sub_id}/resourceGroups/{rg}/providers/Microsoft.Storage/storageAccounts/{account}/blobServices/default/containers/{container}".format(
sub_id=storage_subscription_id,
rg=storage_resource_group_name,
account=storage_account_name,
container=storage_file_system_name,
)
offline_store = MaterializationStore(
type="azure_data_lake_gen2",
target=gen2_container_arm_id,
)
# Get an existing UAI
uai_subscription_id = "<UAI_SUBSCRIPTION_ID>"
uai_resource_group_name = "<UAI_RESOURCE_GROUP>"
uai_name = "<FEATURE_STORE_UAI_NAME>"
msi_client = ManagedServiceIdentityClient(
AzureMLOnBehalfOfCredential(), uai_subscription_id
)
managed_identity = msi_client.user_assigned_identities.get(
uai_resource_group_name, uai_name
)
# Get UAI information
uai_principal_id = managed_identity.principal_id
uai_client_id = managed_identity.client_id
uai_arm_id = managed_identity.id
materialization_identity1 = ManagedIdentityConfiguration(
client_id=uai_client_id, principal_id=uai_principal_id, resource_id=uai_arm_id
)
# Create a feature store
featurestore_name = "<FEATURE_STORE_NAME>"
featurestore_location = "<AZURE_REGION>"
featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"]
featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]
ml_client = MLClient(
AzureMLOnBehalfOfCredential(),
subscription_id=featurestore_subscription_id,
resource_group_name=featurestore_resource_group_name,
)
# Use existing ADLS Gen2 container and UAI
fs = FeatureStore(
name=featurestore_name,
location=featurestore_location,
offline_store=offline_store,
materialization_identity=materialization_identity1,
)
fs_poller = ml_client.feature_stores.begin_update(fs)
print(fs_poller.result())
İşlemler özellik kümesinde özellik kümesinin maddileştirilmesini etkinleştirdikten sonra veri doldurma işlemi gerçekleştirebilirsiniz. Yinelenen gerçekleştirme işleri de zamanlayabilirsiniz. Daha fazla bilgi için bu serinin üçüncü eğitimi olan Yinelenen gerçekleştirmeyi etkinleştirme ve toplu çıkarım çalıştırma eğitimine bakın.
YAML dosyasında spark.sql.shuffle.partitions ayarlama
Spark yapılandırması spark.sql.shuffle.partitions , özellik kümesi çevrimdışı depoda oluşturulduğunda günlük olarak oluşturulan Parquet dosyalarının sayısını etkileyebilecek isteğe bağlı bir parametredir. Bu parametrenin varsayılan değeri 200'dür.
En iyi uygulama olarak, çok sayıda küçük Parquet dosyası oluşturmaktan kaçının. Özellik kümesinin gerçekleştirilmesinden sonra çevrimdışı özellik alma işlemi yavaşlarsa, çevrimdışı depoda ilgili klasörü açın. Sorunun günde çok fazla küçük Parquet dosyası içerip içermediğini denetleyin ve bu parametrenin değerini özellik veri boyutuna göre ayarlayın.
Not
Bu not defterinde kullanılan örnek veriler küçüktür. Bu nedenle, spark.sql.shuffle.partitions parametresi 1 olarak featureset_asset_offline_enabled.yaml dosyasında ayarlanmıştır.
transaction_asset_mat_yaml = (
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)
!az ml feature-set update --file $transaction_asset_mat_yaml --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_nameÖzellik kümesi varlığını YAML kaynağı olarak da kaydedebilirsiniz.
İşlemler özellik kümesi için eksik verileri tamamlama
Gerçekleştirme, bir özellik penceresi için özellik değerlerini hesaplar ve bu hesaplanan değerleri bir gerçekleştirme deposunda depolar. Özellik gerçekleştirme, hesaplanan değerlerin güvenilirliğini ve kullanılabilirliğini artırır. Tüm özellik sorguları artık gerçekleştirme deposundaki değerleri kullanır. Bu adım, 18 aylık bir özellik penceresi için tek seferlik bir geri doldurma gerçekleştirir.
Not
Bir geri doldurma veri penceresi değeri belirlemeniz gerekebilir. Pencere, eğitim verilerinizin penceresiyle eşleşmelidir. Örneğin, eğitim için 18 aylık verileri kullanmak için 18 ay boyunca özellikleri almanız gerekir. Bu, 18 aylık bir süre boyunca geri doldurmanız gerektiği anlamına gelir.
Aşağıdaki kod hücresi verileri geçerli duruma None veya Incomplete tanımlı özellik penceresine göre oluşturur. Birden fazla veri durumunun listesini (örneğin ["None", "Incomplete"], tek bir yedekleme işinde) sağlayabilirsiniz.
feature_window_start_time = "2022-01-01T00:00.000Z"
feature_window_end_time = "2023-06-30T00:00.000Z"
!az ml feature-set backfill --name transactions --version 1 --by-data-status "['None', 'Incomplete']" --feature-window-start-time $feature_window_start_time --feature-window-end-time $feature_window_end_time --feature-store-name $featurestore_name --resource-group $featurestore_resource_group_nameİpucu
- Sütun
timestampbiçime uygunyyyy-MM-ddTHH:mm:ss.fffZolmalıdır. -
feature_window_start_timevefeature_window_end_timetanecikliği saniye ile sınırlıdır. Nesnedekidatetimemilisaniyeler yoksayılır. - Gerçekleştirme işi, özellik penceresindeki veriler işi gönderirken tanımlanan
data_statusile eşleştiğinde yalnızca gönderilir.
Özellik kümesinden örnek verileri yazdırın. Çıkış bilgileri, verilerin gerçekleştirme deposundan alındığını gösterir.
get_offline_features() yöntemi, eğitim ve çıkarım verilerini alır ve ayrıca varsayılan olarak malzemeleşme deposunu kullanır.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Çevrimdışı özellik gerçekleştirmeyi daha fazla keşfedin
Bir özellik kümesinin özellik gerçekleştirme durumunu Gerçekleştirme işleri kullanıcı arabiriminde inceleyebilirsiniz.
Sol bölmede Özellik depoları'nı seçin.
Erişilebilir özellik depoları listesinden, yedekleme gerçekleştirdiğiniz özellik depounu seçin.
Materyalizasyon işleri sekmesini seçin.
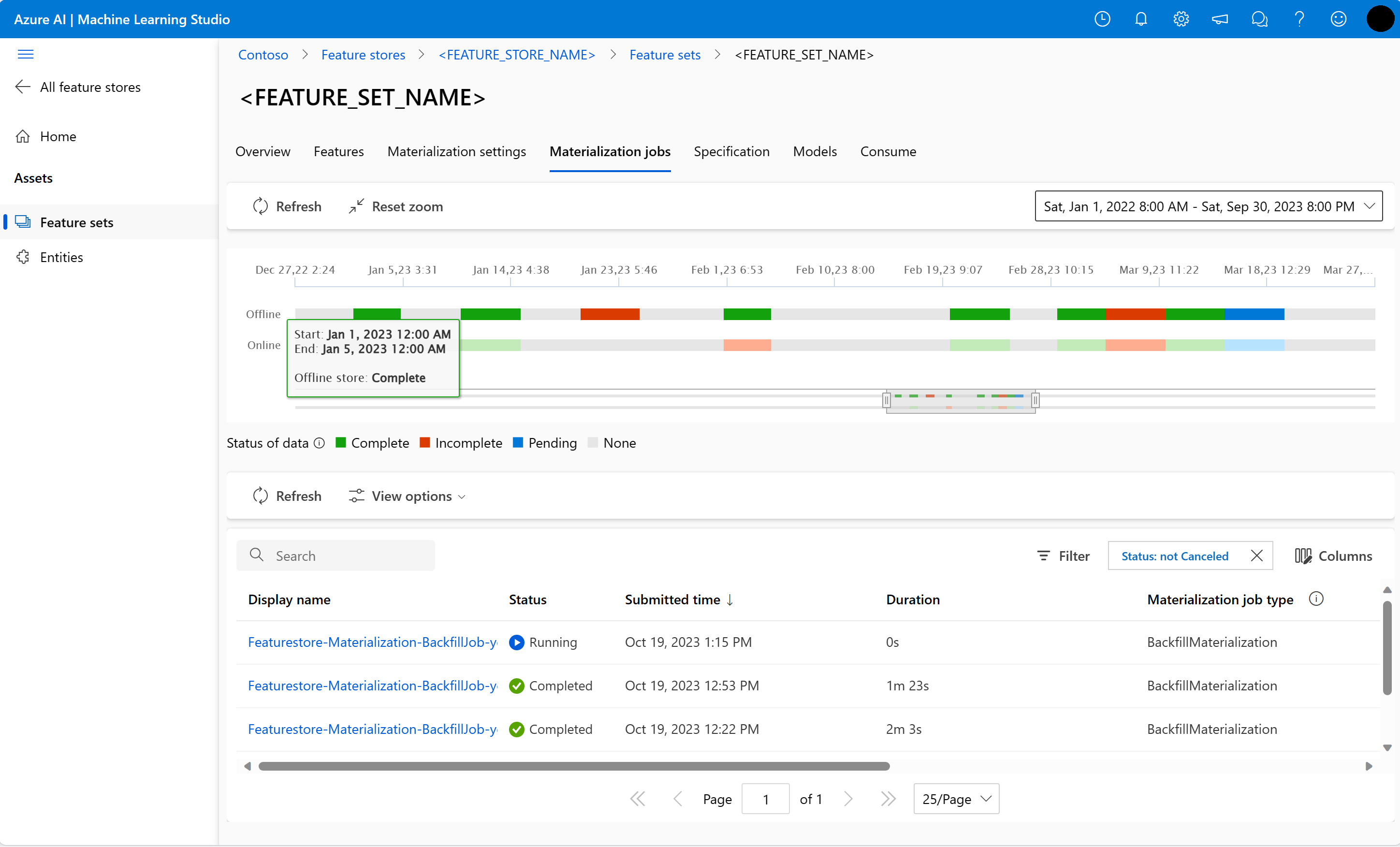

Veri gerçekleştirme durumu şu şekilde olabilir:
- Tamamlandı (yeşil)
- Eksik (kırmızı)
- Beklemede (mavi)
- Hiçbiri (gri)
Veri aralığı, verilerin aynı veri gerçekleştirme durumuna sahip bitişik bir bölümünü temsil eder. Örneğin, önceki anlık görüntünün çevrimdışı malzeme deposunda 16 veri aralığı vardır. Verilerin en fazla 2.000 veri aralığı olabilir. Verileriniz 2.000'den fazla veri aralığı içeriyorsa yeni bir özellik kümesi sürümü oluşturun.
Dolum sırasında, tanımlanan özellik penceresine giren her veri aralığı için yeni bir gerçekleştirme işi gönderilir. Eğer geri doldurulmamış bir veri aralığı için bekleyen veya çalışmakta olan bir malzemeleştirme işi varsa, hiçbir iş gönderilmez.
Başarısız bir gerçekleştirme işini yeniden deneyebilirsiniz.
Not
Başarısız bir gerçekleştirme işinin iş kimliğini almak için:
- Materialization jobs özellikleri kullanıcı arayüzüne gidin.
- DurumuBaşarısız olan belirli bir işin Görünen adını seçin.
-
Ad özelliği altında, Genel Bakış sayfasındaki "
Featurestore-Materialization-" ile başlayan iş kimliğini bulun.
az ml feature-set backfill --by-job-id <JOB_ID_OF_FAILED_MATERIALIZATION_JOB> --name <FEATURE_SET_NAME> --version <VERSION> --feature-store-name <FEATURE_STORE_NAME> --resource-group <RESOURCE_GROUP>
Çevrimdışı bir materyalizasyon deposunu güncelleme
Çevrimdışı bir gerçekleştirme deposunun özellik deposu düzeyinde güncelleştirilmesi gerekiyorsa, özellik deposundaki tüm özellik kümelerinde çevrimdışı gerçekleştirme devre dışı bırakılmalıdır.
Bir özellik kümesinde çevrimdışı gerçekleştirme devre dışı bırakılırsa, çevrimdışı gerçekleştirme deposunda zaten gerçekleştirilmiş verilerin gerçekleştirilmesi durumu sıfırlanır. Sıfırlama, zaten gerçekleştirilmiş olan verileri kullanılamaz hale getirir. Çevrimdışı gerçekleştirmeyi etkinleştirdikten sonra gerçekleştirme işlerini yeniden göndermeniz gerekir.
Temizleme
Bu serinin beşinci öğreticisi olan Özel bir kaynakla özellik kümesi geliştirme, kaynakların nasıl silineceği açıklanmaktadır.
Sonraki adım
Bu öğreticide, eğitim verileri özellik deposundaki özelliklerle oluşturulmuş, çevrimdışı özellik deposuna gerçekleştirilmesi etkinleştirilmiştir ve bir geri doldurma gerçekleştirilmiştir.
Serinin sonraki öğreticisi olan Özellikleri kullanarak modelleri deneyip eğitme, bu özellikleri kullanarak model eğitiminin nasıl yapılacağını gösterir.