Öğretici: Örnek bir Jupyter Notebook ile görüntü sınıflandırma modelini eğitme ve dağıtma
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu öğreticide, uzak işlem kaynakları üzerinde bir makine öğrenmesi modeli eğitmiş olacaksınız. Python Jupyter Notebook'ta Azure Machine Learning için eğitim ve dağıtım iş akışını kullanırsınız. Ardından not defterini şablon olarak kullanıp kendi verilerinizle kendi makine öğrenmesi modelinizi eğitebilirsiniz.
Bu öğretici, Azure Machine Learning ile MNIST veri kümesini ve scikit-learn'i kullanarak basit bir lojistik regresyon eğitmektedir. MNIST, 70.000 gri tonlamalı resimden oluşan popüler bir veri kümesidir. Her resim, sıfırdan dokuza kadar bir sayıyı temsil eden 28 x 28 piksellik el yazısı bir basamaktır. Amaç, belirli bir resim temsil ettiği rakamı tanımlamak için çok sınıflı bir sınıflandırıcı oluşturmaktır.
Aşağıdaki eylemleri gerçekleştirmeyi öğrenin:
- Bir veri kümesi indirin ve verilere bakın.
- MLflow kullanarak görüntü sınıflandırma modelini ve günlük ölçümlerini eğitin.
- Gerçek zamanlı çıkarım yapmak için modeli dağıtın.
Önkoşullar
- Hızlı Başlangıcı tamamlayın: Azure Machine Learning'i kullanmaya başlamak için:
- Çalışma alanı oluşturun.
- Geliştirme ortamınızda kullanmak üzere bulut tabanlı bir işlem örneği oluşturun.
Çalışma alanınızdan not defteri çalıştırma
Azure Machine Learning, ücretsiz ve önceden yapılandırılmış bir deneyim için çalışma alanınızda bir bulut not defteri sunucusu içerir. Ortamınız, paketleriniz ve bağımlılıklarınız üzerinde denetim sahibi olmak istiyorsanız kendi ortamınızı kullanın.
Not defteri klasörünü kopyalama
Aşağıdaki deneme kurulumunu tamamlar ve Azure Machine Learning stüdyosu adımlarını çalıştırırsınız. Bu birleştirilmiş arabirim, tüm beceri düzeylerindeki veri bilimi uygulayıcıları için veri bilimi senaryoları gerçekleştirmek için makine öğrenmesi araçlarını içerir.
Azure Machine Learning stüdyosu oturum açın.
Aboneliğinizi ve oluşturduğunuz çalışma alanını seçin.
Sol tarafta Not Defterleri'ni seçin.
Üst kısımda Örnekler sekmesini seçin.
SDK v1 klasörünü açın.
Öğreticiler klasörünün sağ tarafındaki ... düğmesini ve ardından Kopyala'yı seçin.
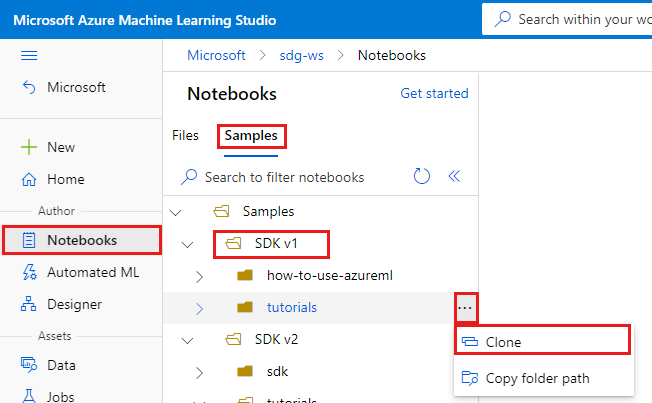
Klasör listesi, çalışma alanına erişen her kullanıcıyı gösterir. Öğreticiler klasörünü orada kopyalamak için klasörünüzü seçin.
Kopyalanan not defterini açma
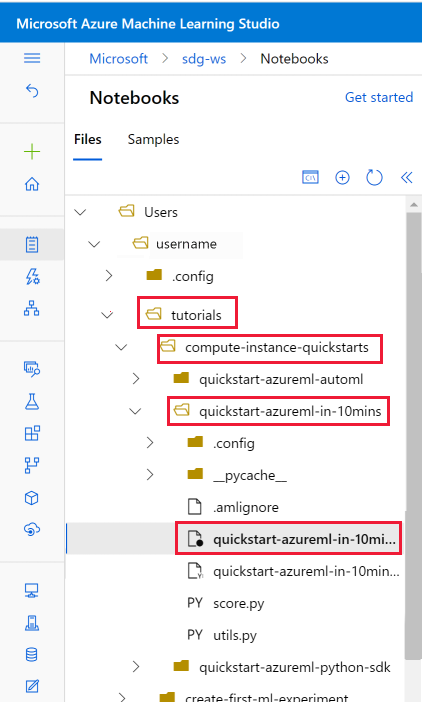
Kullanıcı dosyaları bölümünüzde kopyalanan öğreticiler klasörünü açın.
Tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins klasörünüzden quickstart-azureml-in-10mins.ipynb dosyasını seçin.
Paketleri yükleme
İşlem örneği çalıştırıldıktan ve çekirdek görüntülendiğinde, bu öğretici için gerekli paketleri yüklemek için yeni bir kod hücresi ekleyin.
Not defterinin en üstüne bir kod hücresi ekleyin.
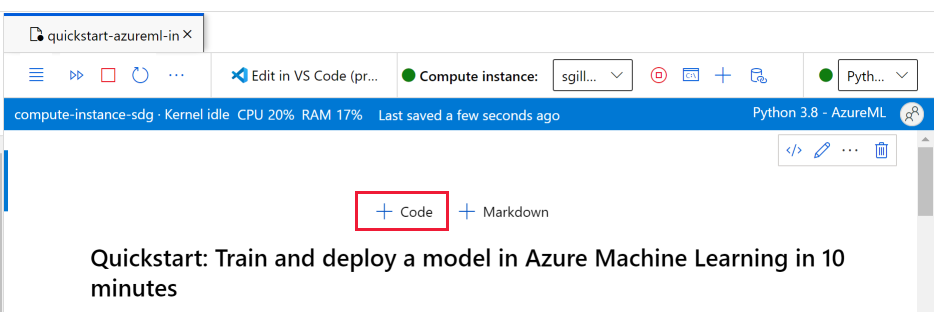
Aşağıdakini hücreye ekleyin ve ardından Çalıştır aracını veya Shift+Enter tuşlarını kullanarak hücreyi çalıştırın.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Birkaç yükleme uyarısı görebilirsiniz. Bunlar güvenle yoksayılabilir.
Not defterini çalıştırma
Bu öğretici ve eşlik eden utils.py dosyası, kendi yerel ortamınızda kullanmak istiyorsanız GitHub'da da kullanılabilir. İşlem örneğini kullanmıyorsanız yukarıdaki yüklemeye ekleyin %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib .
Önemli
Bu makalenin geri kalanı, not defterinde gördüğünüz içerikle aynı içeriği içerir.
Birlikte okurken kodu çalıştırmak istiyorsanız şimdi Jupyter Not Defteri'ne geçin. Not defterinde tek bir kod hücresi çalıştırmak için kod hücresine tıklayın ve Shift+Enter tuşlarına basın. Veya üst araç çubuğundan Tümünü çalıştır'ı seçerek not defterinin tamamını çalıştırın.
Verileri içeri aktarma
Modeli eğitmeden önce eğitmek için kullandığınız verileri anlamanız gerekir. Bu bölümde şunların nasıl yapılacağını öğrenin:
- MNIST veri kümesini indirme
- Bazı örnek görüntüleri gösterme
Ham MNIST veri dosyalarını almak için Azure Açık Veri Kümeleri'ni kullanırsınız. Azure Açık Veri Kümeleri, daha iyi modeller için makine öğrenmesi çözümlerine senaryoya özgü özellikler eklemek için kullanabileceğiniz genel veri kümeleridir. Her veri kümesinin, MNIST verileri farklı şekillerde almak için karşılık gelen bir sınıfı vardır.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Verilere göz atın
Sıkıştırılmış dosyaları numpy dizilerine yükleyin. Ardından matplotlib kullanarak, üst kısımlarında etiketleriyle veri kümesinden 30 rastgele görüntü çizin.
Bu adımın bir dosyaya dahil edilen bir load_data işlev gerektirdiğini utils.py unutmayın. Bu dosya, bu not defteriyle aynı klasöre yerleştirilir. İşlev, load_data sıkıştırılmış dosyaları basit dizilere ayrıştırır.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
Kod, etiketleriyle birlikte aşağıdakine benzer rastgele bir görüntü kümesi görüntüler:

MLflow ile model ve günlük ölçümlerini eğitin
Aşağıdaki kodu kullanarak modeli eğitin. Bu kod ölçümleri ve günlük modeli yapıtlarını izlemek için MLflow otomatik kaydetme özelliğini kullanır.
Verileri sınıflandırmak için SciKit Learn çerçevesinin LogisticRegression sınıflandırıcısını kullanacaksınız.
Not
Model eğitiminin tamamlanması yaklaşık 2 dakika sürer.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Denemeyi görüntüleme
Azure Machine Learning stüdyosu sol taraftaki menüde İşler'i ve ardından işinizi seçin (azure-ml-in10-mins-tutorial). İş, belirtilen bir betikten veya kod parçasından çok sayıda çalıştırmanın gruplandırılmasıdır. Deneme olarak birden çok iş birlikte gruplandırılabilir.
Çalıştırma bilgileri bu işin altında depolanır. bir iş gönderdiğinizde ad yoksa, çalıştırmanızı seçerseniz ölçümler, günlükler, açıklamalar vb. içeren çeşitli sekmeler görürsünüz.
Model kayıt defteriyle modellerinizi sürüm denetimi
Modellerinizi çalışma alanınızda depolamak ve sürüme eklemek için model kaydını kullanabilirsiniz. Kayıtlı modeller ad ve sürümle tanımlanır. Modeli var olan bir adla her kaydettiğinizde, kayıt defteri sürümü bir artırır. Aşağıdaki kod, yukarıda eğitmiş olduğunuz modeli kaydeder ve sürümler. Aşağıdaki kod hücresini yürüttüğünizde, Azure Machine Learning stüdyosu sol taraftaki menüden Modeller'i seçerek modeli kayıt defterinde görürsünüz.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Modeli gerçek zamanlı çıkarım için dağıtma
Bu bölümde, bir uygulamanın REST üzerinden modeli kullanabilmesi (çıkarım) için modeli dağıtmayı öğrenin.
Dağıtım yapılandırması oluşturma
Kod hücresi, modeli barındırmak için gereken tüm bağımlılıkları (örneğin, scikit-learn gibi paketler) belirten, seçilmiş bir ortam alır. Ayrıca, modeli barındırmak için gereken işlem miktarını belirten bir dağıtım yapılandırması oluşturursunuz. Bu durumda işlem 1CPU ve 1 GB belleğe sahiptir.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Model dağıtma
Bu sonraki kod hücresi modeli Azure Container Instance'a dağıtır.
Not
Dağıtımın tamamlanması yaklaşık 3 dakika sürer. Ancak, 15 dakika kadar kullanım için kullanılabilir olana kadar daha uzun olabilir.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Yukarıdaki kodda başvurulan puanlama betik dosyası bu not defteriyle aynı klasörde bulunabilir ve iki işleve sahiptir:
initHizmet başlatıldığında bir kez yürütülen bir işlev - bu işlevde normalde modeli kayıt defterinden alır ve genel değişkenleri ayarlarsınızrun(data)Hizmete her çağrı yapıldığında yürütülen bir işlev. Bu işlevde normalde giriş verilerini biçimlendirebilir, bir tahmin çalıştırabilir ve tahmin edilen sonucun çıktısını alırsınız.
Uç noktayı görüntüleme
Model başarıyla dağıtıldıktan sonra, Azure Machine Learning stüdyosu sol taraftaki menüde Uç Noktalar'a giderek uç noktayı görüntüleyebilirsiniz. Uç noktanın durumunu (iyi durumda/iyi durumda değil), günlükleri ve kullanımı (uygulamaların modeli nasıl kullanabileceğini) görürsünüz.
Model hizmetini test etme
Web hizmetini test etmek için ham bir HTTP isteği göndererek modeli test edebilirsiniz.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Kaynakları temizleme
Bu modeli kullanmaya devam etmeyecekseniz, aşağıdakini kullanarak Model hizmetini silin:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Maliyeti daha fazla denetlemek istiyorsanız İşlem açılan listesinin yanındaki "İşlemi durdur" düğmesini seçerek işlem örneğini durdurun. Ardından bir sonraki ihtiyacınız olduğunda işlem örneğini yeniden başlatın.
Her şeyi sil
Azure Machine Learning çalışma alanınızı ve tüm işlem kaynaklarını silmek için bu adımları kullanın.
Önemli
Oluşturduğunuz kaynaklar, diğer Azure Machine Learning öğreticileri ve nasıl yapılır makaleleri için önkoşul olarak kullanılabilir.
Oluşturduğunuz kaynaklardan hiçbirini kullanmayı planlamıyorsanız, ücret ödememek için bunları silin:
Azure portalının en sol tarafındaki Kaynak gruplarını seçin.
Listeden, oluşturduğunuz kaynak grubunu seçin.
Kaynak grubunu sil'i seçin.
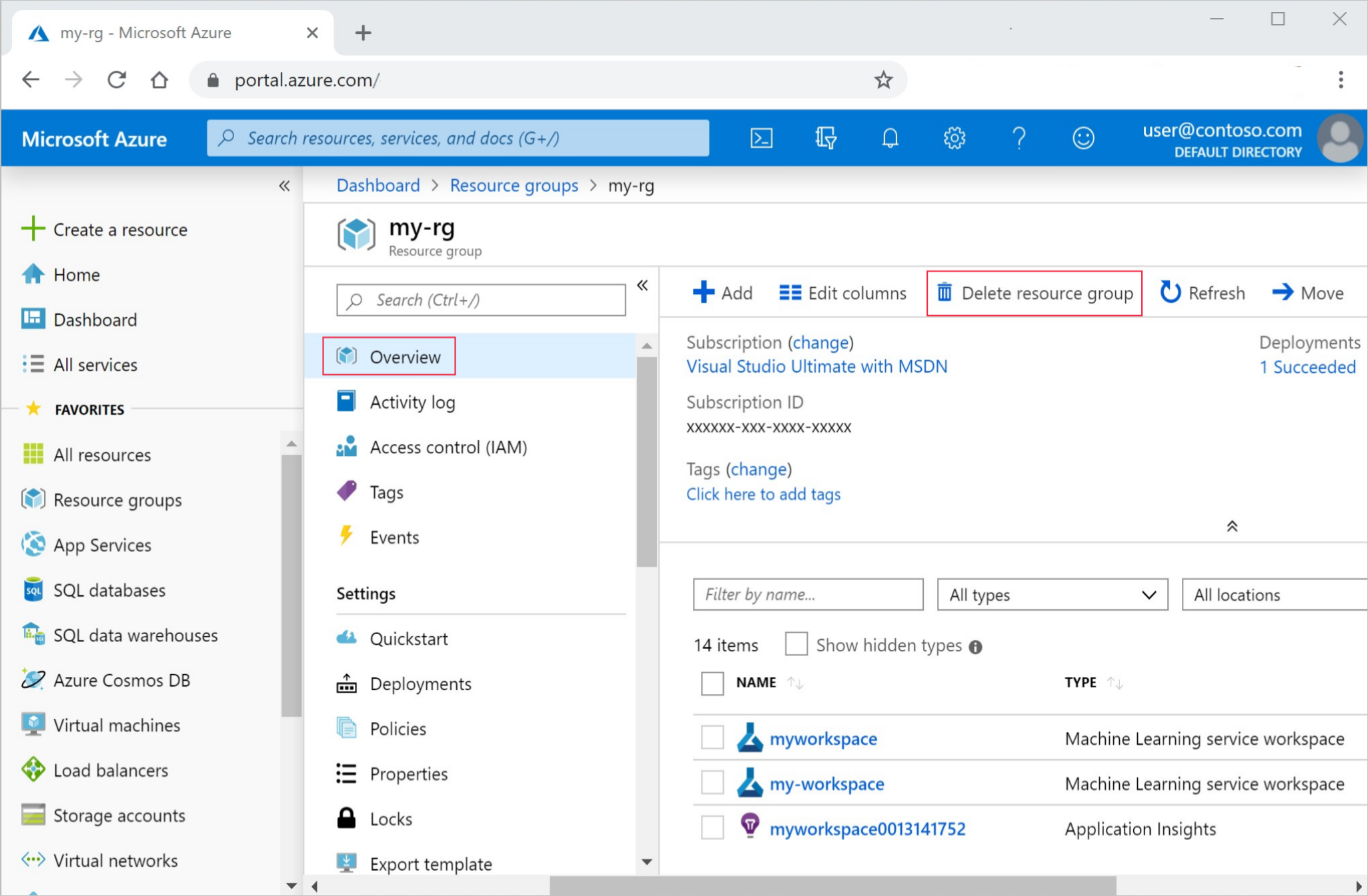
Kaynak grubu adını girin. Ardından Sil'i seçin.
İlgili kaynaklar
- Azure Machine Learning için tüm dağıtım seçenekleri hakkında bilgi edinin.
- Dağıtılan modelde kimlik doğrulaması yapmayı öğrenin.
- Büyük miktarlardaki veriler üzerinde zaman uyumsuz olarak tahminde bulunun.
- Application Insights ile Azure Machine Learning modellerinizi izleyin.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin