Makine öğrenmesi modellerini Azure'a dağıtma
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v1Python SDK azureml v1
Azure CLI ml uzantısı v1Python SDK azureml v1
Makine öğrenmesi veya derin öğrenme modelinizi Azure bulutunda web hizmeti olarak dağıtmayı öğrenin.
Not
Azure Machine Learning Uç Noktaları (v2), geliştirilmiş, daha basit bir dağıtım deneyimi sağlar. Uç noktalar hem gerçek zamanlı hem de toplu çıkarım senaryolarını destekler. Uç noktalar, işlem türleri arasında model dağıtımlarını çağırmak ve yönetmek için birleşik bir arabirim sağlar. Bkz. Azure Machine Learning uç noktaları nedir?.
Model dağıtmak için iş akışı
Modeli nerede dağıtırsanız dağıtın benzer bir iş akışı kullanılır:
- Modeli kaydedin.
- Giriş betiği hazırlama.
- Çıkarım yapılandırması hazırlayın.
- Her şeyin çalıştığından emin olmak için modeli yerel olarak dağıtın.
- İşlem hedefi seçin.
- Modeli buluta dağıtın.
- Sonuçta elde edilen web hizmetini test edin.
Makine öğrenmesi dağıtım iş akışıyla ilgili kavramlar hakkında daha fazla bilgi için bkz. Azure Machine Learning ile modelleri yönetme, dağıtma ve izleme.
Önkoşullar
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
Önemli
Bu makaledeki Azure CLI komutları, Azure Machine Learning için uzantısını veya v1'i gerektirirazure-cli-ml. v1 uzantısı desteği 30 Eylül 2025'te sona erecektir. Bu tarihe kadar v1 uzantısını yükleyebilecek ve kullanabileceksiniz.
30 Eylül 2025'e kadar uzantısına veya v2 uzantısına geçmenizi mlöneririz. v2 uzantısı hakkında daha fazla bilgi için bkz. Azure ML CLI uzantısı ve Python SDK v2.
- Azure Machine Learning çalışma alanı. Daha fazla bilgi için bkz. Çalışma alanı kaynakları oluşturma.
- Bir model. Bu makaledeki örneklerde önceden eğitilmiş bir model kullanılır.
- İşlem örneği gibi Docker çalıştırabilen bir makine.
Çalışma alanınıza bağlanma
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
Erişiminiz olan çalışma alanlarını görmek için aşağıdaki komutları kullanın:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Modeli kaydetme
Dağıtılan makine öğrenmesi hizmeti için tipik bir durum, aşağıdaki bileşenlere ihtiyacınız olmasıdır:
- Dağıtılmasını istediğiniz modeli temsil eden kaynaklar (örneğin: pytorch model dosyası).
- Belirli bir girişte modeli yürüten hizmette çalıştıracağınız kod.
Azure Machine Learnings, aynı kodu koruyup modeli nadiren güncelleştirmeniz için dağıtım işlemini iki ayrı bileşene bölmenizi sağlar. Bir modeli kodunuzdan ayrı olarak karşıya yüklediğiniz mekanizmayı "modeli kaydetme" olarak tanımlarız.
Siz modeli kaydettiğinizde biz de bu modeli buluta yükleriz (çalışma alanınızın varsayılan depolama hesabında) ve ardından web hizmetinizin çalıştırıldığı işleme bağlarız.
Aşağıdaki örneklerde bir modelin nasıl kaydedilecekleri gösterilmektedir.
Önemli
Yalnızca kendi oluşturduğunuz veya güvenilir bir kaynaktan aldığınız modelleri kullanmalısınız. Seri hale getirilmiş modelleri kod olarak değerlendirmelisiniz çünkü bir dizi popüler biçimde güvenlik açıkları bulunmuştur. Ayrıca modeller taraflı veya yanlış çıkış sağlamak üzere kasten kötü amaçlı olarak eğitilmiş olabilir.
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
Aşağıdaki komutlar bir modeli indirip Azure Machine Learning çalışma alanınıza kaydeder:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Kaydetmek istediğiniz klasörün veya dosyanın yoluna ayarlayın -p .
hakkında az ml model registerdaha fazla bilgi için başvuru belgelerine bakın.
Azure Machine Learning eğitim işinden model kaydetme
Daha önce bir Azure Machine Learning eğitim işi aracılığıyla oluşturulmuş bir modeli kaydetmeniz gerekiyorsa, modelin denemesini, çalıştırmasını ve yolunu belirtebilirsiniz:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
--asset-path parametresi, modelin bulut konumunu ifade eder. Bu örnekte, tek bir dosyanın yolu kullanılır. Model kaydına birden çok dosya eklemek için, dosyaları içeren klasörün yoluna ayarlayın --asset-path .
hakkında az ml model registerdaha fazla bilgi için başvuru belgelerine bakın.
Not
Ayrıca çalışma alanı kullanıcı arabirimi portalı aracılığıyla yerel bir dosyadan model kaydedebilirsiniz.
Şu anda kullanıcı arabiriminde yerel model dosyasını karşıya yüklemek için iki seçenek vardır:
- Bir v2 modelini kaydedecek olan yerel dosyalardan.
- Bir v1 modelini kaydedecek yerel dosyalardan (çerçeveye dayalı) .
SDKv1/CLIv1 kullanılarak yalnızca Yerel dosyalardan (çerçeveye dayalı) girişi (v1 modelleri olarak bilinir) aracılığıyla kaydedilen modellerin web hizmeti olarak dağıtılabildiğini unutmayın.
Sahte giriş betiği tanımlama
Giriş betiği, dağıtılan bir web hizmetine gönderilen verileri alır ve modele geçirir. Ardından modelin istemciye verdiği yanıtı döndürür. Betik modelinize özeldir. Giriş betiği, modelin beklediği ve döndürdüğü verileri anlamalıdır.
Giriş betiğinizde gerçekleştirmeniz gereken iki şey şunlardır:
- Modelinizi yükleme (adlı
init()bir işlev kullanarak) - Modelinizi giriş verileri üzerinde çalıştırma (adlı
run()bir işlev kullanarak)
İlk dağıtımınız için, aldığı verileri yazdıran sahte bir giriş betiği kullanın.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Bu dosyayı adlı source_dirdizinin içinde olarak echo_score.py kaydedin. Bu kukla betik, ona gönderdiğiniz verileri döndürdüğünden modeli kullanmaz. Ancak puanlama betiğinin çalıştığını test etme açısından yararlıdır.
Çıkarım yapılandırması tanımlama
Çıkarım yapılandırması, Web hizmetinizi başlatırken kullanılacak Docker kapsayıcısını ve dosyalarını açıklar. Alt dizinler de dahil olmak üzere kaynak dizininizdeki tüm dosyalar, web hizmetinizi dağıttığınızda sıkıştırılmış ve buluta yüklenir.
Aşağıdaki çıkarım yapılandırması, makine öğrenmesi dağıtımının gelen istekleri işlemek için dizindeki ./source_dir dosyayı echo_score.py kullanacağını ve Docker görüntüsünü ortamda project_environment belirtilen Python paketleriyle birlikte kullanacağını belirtir.
Proje ortamınızı oluştururken temel Docker görüntüsü olarak tüm Azure Machine Learning çıkarımı seçilmiş ortamlarını kullanabilirsiniz. Gerekli bağımlılıkları en üste yükleyecek ve sonuçta elde edilen Docker görüntüsünü çalışma alanınızla ilişkili depoda depolayacağız.
Not
Azure machine learning çıkarımı kaynak dizini karşıya yüklemesi .gitignore veya .amlignore'a saygı göstermez
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
En düşük çıkarım yapılandırması şöyle yazılabilir:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Bu dosyayı adıyla dummyinferenceconfig.jsonkaydedin.
Çıkarım yapılandırmalarının daha kapsamlı bir tartışması için bu makaleye bakın.
Dağıtım yapılandırması tanımlama
Dağıtım yapılandırması, web hizmetinizin çalışması için ihtiyaç duyduğu bellek ve çekirdek miktarını belirtir. Ayrıca, temel alınan web hizmeti yapılandırma ayrıntılarını da sağlar. Örneğin, bir dağıtım yapılandırması hizmetinizin 2 gigabayt belleğe, 2 CPU çekirdeğine, 1 GPU çekirdeğine ihtiyacı olduğunu ve otomatik ölçeklendirmeyi etkinleştirmek istediğinizi belirtmenize olanak tanır.
Dağıtım yapılandırması için kullanılabilen seçenekler, seçtiğiniz işlem hedeflerine bağlı olarak farklılık gösterir. Yerel dağıtımda, web hizmetinizin hangi bağlantı noktasında hizmet edeceğini belirtebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
Belgedeki deploymentconfig.json girdiler , LocalWebservice.deploy_configuration parametreleriyle eşler. Aşağıdaki tabloda JSON belgesindeki varlıklar ile yöntemine yönelik parametreler arasındaki eşleme açıklanmaktadır:
| JSON varlığı | Yöntem parametresi | Açıklama |
|---|---|---|
computeType |
NA | Bilgi işlem hedefi. Yerel hedefler için değeri olmalıdır local. |
port |
port |
Hizmetin HTTP uç noktasının kullanıma açık olduğu yerel bağlantı noktası. |
Bu JSON, CLI ile kullanmak için örnek bir dağıtım yapılandırmasıdır:
{
"computeType": "local",
"port": 32267
}
Bu JSON dosyasını adlı deploymentconfig.jsonbir dosya olarak kaydedin.
Daha fazla bilgi için bkz. dağıtım şeması.
Makine öğrenmesi modelinizi dağıtma
Artık modelinizi dağıtmaya hazırsınız.
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
değerini modelinizin adı ve sürüm numarasıyla değiştirin bidaf_onnx:1 .
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Modelinize çağrı
Şimdi yankı modelinizin başarıyla dağıtıldığını denetleyelim. Hem basit bir canlılık isteği hem de puanlama isteği yapabilmeniz gerekir:
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Giriş betiği tanımlama
Şimdi modelinizi yükleme zamanı geldi. İlk olarak, giriş betiğinizi değiştirin:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Bu dosyayı içinde source_dirolarak score.py kaydedin.
Kayıtlı modelinizi bulmak için ortam değişkeninin AZUREML_MODEL_DIR kullanıldığına dikkat edin. Artık bazı pip paketleri eklediğinize göre.
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Bu dosyayı farklı kaydet inferenceconfig.json
Yeniden dağıtın ve hizmetinizi çağırın
Hizmetinizi yeniden dağıtın:
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
değerini modelinizin adı ve sürüm numarasıyla değiştirin bidaf_onnx:1 .
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Ardından hizmete bir gönderi isteği gönderebildiğinize emin olun:
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
İşlem hedefi seçme
Modelinizi barındırmak için kullandığınız işlem hedefi, dağıtılan uç noktanızın maliyetini ve kullanılabilirliğini etkiler. Uygun işlem hedeflerini seçmek için bu tabloyu kullanın.
| İşlem hedefi | Kullanıldığı yerler | GPU desteği | Açıklama |
|---|---|---|---|
| Yerel web hizmeti | Test/hata ayıklama | Sınırlı test ve sorun giderme için kullanın. Donanım hızlandırma, yerel sistemdeki kitaplıkların kullanımına bağlıdır. | |
| Azure Machine Learning uç noktaları (yalnızca SDK/CLI v2) | Gerçek zamanlı çıkarım Toplu çıkarım |
Yes | Sunucusuz işlemde gerçek zamanlı (yönetilen çevrimiçi uç noktalar) ve toplu puanlama (toplu iş uç noktaları) için tam olarak yönetilen işlemler. |
| Azure Machine Learning Kubernetes | Gerçek zamanlı çıkarım Toplu çıkarım |
Yes | Şirket içi, bulut ve uç Kubernetes kümelerinde çıkarım iş yüklerini çalıştırın. |
| Azure Container Instances (yalnızca SDK/CLI v1) | Gerçek zamanlı çıkarım Yalnızca geliştirme/test amacıyla önerilir. |
48 GB'tan az RAM gerektiren düşük ölçekli CPU tabanlı iş yükleri için kullanın. Kümeyi yönetmenizi gerektirmez. Tasarımcıda desteklenir. |
Not
Bir küme SKU'su seçerken önce ölçeği genişletin ve sonra ölçeği genişletin. Modelinizin gerektirdiği RAM'in %150'sine sahip bir makineyle başlayın, sonucun profilini yapın ve ihtiyacınız olan performansa sahip bir makine bulun. Bunu öğrendikten sonra, eşzamanlı çıkarım ihtiyacınıza uyacak şekilde makine sayısını artırın.
Not
Kapsayıcı örnekleri SDK veya CLI v1 gerektirir ve yalnızca boyutu 1 GB'ın altında olan küçük modeller için uygundur.
Buluta dağıtma
Hizmetinizin yerel olarak çalıştığını onayladıktan ve bir uzak işlem hedefi seçtikten sonra buluta dağıtmaya hazır olursunuz.
Dağıtım yapılandırmanızı seçtiğiniz işlem hedefine karşılık gelen şekilde değiştirin, bu durumda Azure Container Instances:
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
Dağıtım yapılandırması için kullanılabilen seçenekler, seçtiğiniz işlem hedeflerine bağlı olarak farklılık gösterir.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Bu dosyayı olarak re-deploymentconfig.jsonkaydedin.
Daha fazla bilgi için bu başvuruya bakın.
Hizmetinizi yeniden dağıtın:
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
değerini, modelinizin adı ve sürüm numarasıyla değiştirin bidaf_onnx:1 .
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Hizmet günlüklerini görüntülemek için aşağıdaki komutu kullanın:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Uzak web hizmetinizi çağırma
Uzaktan dağıttığınızda anahtar kimlik doğrulaması etkinleştirilmiş olabilir. Aşağıdaki örnekte, çıkarım isteğinde bulunmak için Python ile hizmet anahtarınızın nasıl alıneceği gösterilmektedir.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Diğer dillerde daha fazla örnek istemci için web hizmetlerini kullanmak için istemci uygulamaları makalesine bakın.
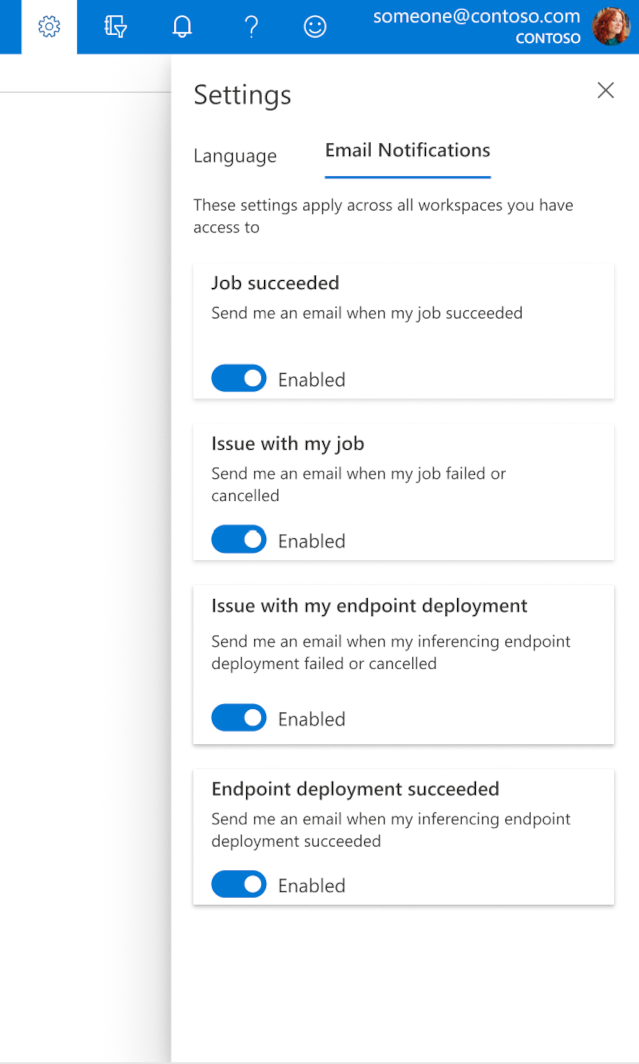
Stüdyoda e-postaları yapılandırma
İşiniz, çevrimiçi uç noktanız veya toplu iş uç noktanız tamamlandığında veya bir sorun olduğunda (başarısız, iptal edildi) e-posta almaya başlamak için aşağıdaki adımları kullanın:
- Azure ML Studio'da dişli simgesini seçerek ayarlara gidin.
- Email bildirimleri sekmesini seçin.
- Belirli bir olay için e-posta bildirimlerini etkinleştirmek veya devre dışı bırakmak için geçiş yapar.
Hizmet durumunu anlama
Model dağıtımı sırasında, tam olarak dağıtılırken hizmet durumu değişikliğini görebilirsiniz.
Aşağıdaki tabloda farklı hizmet durumları açıklanmaktadır:
| Web hizmeti durumu | Açıklama | Son durum mu? |
|---|---|---|
| Geçiş | Hizmet dağıtım sürecindedir. | Hayır |
| Uygun Değil | Hizmet dağıtıldı ancak şu anda ulaşılamıyor. | Hayır |
| Zamanlanamayan | Kaynak yetersizliği nedeniyle hizmet şu anda dağıtılamıyor. | Hayır |
| Başarısız | Hizmet bir hata veya kilitlenme nedeniyle dağıtılamadı. | Yes |
| Sağlam | Hizmet iyi durumda ve uç nokta kullanılabilir. | Yes |
İpucu
Dağıtım sırasında işlem hedefleri için Docker görüntüleri Azure Container Registry (ACR) kullanılarak oluşturulur ve yüklenir. Varsayılan olarak, Azure Machine Learning temel hizmet katmanını kullanan bir ACR oluşturur. Çalışma alanınızın ACR'sini standart veya premium katman olarak değiştirmek, görüntü oluşturma ve işlem hedeflerinize dağıtma süresini kısaltabilir. Daha fazla bilgi için bkz. Azure Container Registry hizmet katmanları.
Not
Azure Kubernetes Service'e (AKS) model dağıtıyorsanız, bu küme için Azure İzleyici'yi etkinleştirmenizi öneririz. Bu genel olarak kümenin durumunu ve kaynak kullanımını anlamanıza yardımcı olur. Ayrıca aşağıdaki kaynakları da yararlı bulabilirsiniz:
İyi durumda olmayan veya aşırı yüklenmiş olan bir kümeye model dağıtmaya çalışıyorsanız sorunlarla karşılaşmanız beklenir. AKS kümesi sorunlarını gidermek için yardıma ihtiyacınız varsa lütfen AKS Desteği'ne başvurun.
Kaynakları silme
ŞUNLAR IÇIN GEÇERLIDIR:Azure CLI ml uzantısı v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Dağıtılan bir web hizmetini silmek için kullanın az ml service delete <name of webservice>.
Kayıtlı modeli çalışma alanınızdan silmek için az ml model delete <model id>
Web hizmetini silme ve modeli silme hakkında daha fazla bilgi edinin.
Sonraki adımlar
- Başarısız bir dağıtımın sorunlarını giderme
- Web hizmetini güncelleştirme
- Azure Machine Learning stüdyosu otomatik ML çalıştırmaları için tek tıklamayla dağıtım
- TLS kullanarak Azure Machine Learning aracılığıyla web hizmetinin güvenliğini sağlama
- Application Insights ile Azure Machine Learning modellerinizi izleme
- Model dağıtımları için olay uyarıları ve tetikleyicileri oluşturma