Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Apache Cassandra için Azure Yönetilen Örneği, yönetilen açık kaynak Apache Cassandra veri merkezleri için otomatik dağıtım ve ölçeklendirme işlemleri sağlar. Bu özellik hibrit senaryoları hızlandırır ve devam eden bakımı azaltmaya yardımcı olur.
Bu hızlı başlangıçta, Azure portalını kullanarak Apache Cassandra için Azure Yönetilen Örneği kümenizin Azure sanal ağında tam olarak yönetilen bir Apache Spark kümesi oluşturma işlemi gösterilmektedir. Spark kümesini Azure Databricks'te oluşturursunuz. Daha sonra kümeye not defterleri oluşturabilir veya ekleyebilir, farklı veri kaynaklarından verileri okuyabilir ve içgörüleri analiz edebilirsiniz.
Ayrıca Azure sanal ağınızda Azure Databricks'i dağıtma (sanal ağ ekleme) hakkında ayrıntılı yönergelerle daha fazla bilgi edinebilirsiniz.
Önkoşullar
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Azure Databricks kümesi oluşturma
Apache Cassandra için Azure Yönetilen Örneği'ne sahip bir sanal ağda Azure Databricks kümesi oluşturmak için şu adımları izleyin:
Azure Portal’ında oturum açın.
Sol bölmede Kaynak grupları'nı bulun. Kaynak grubunuza gidin, burada yönetilen örneğinizin dağıtıldığı sanal ağ bulunmaktadır.
Sanal ağ kaynağını açın ve Adres alanını not edin.
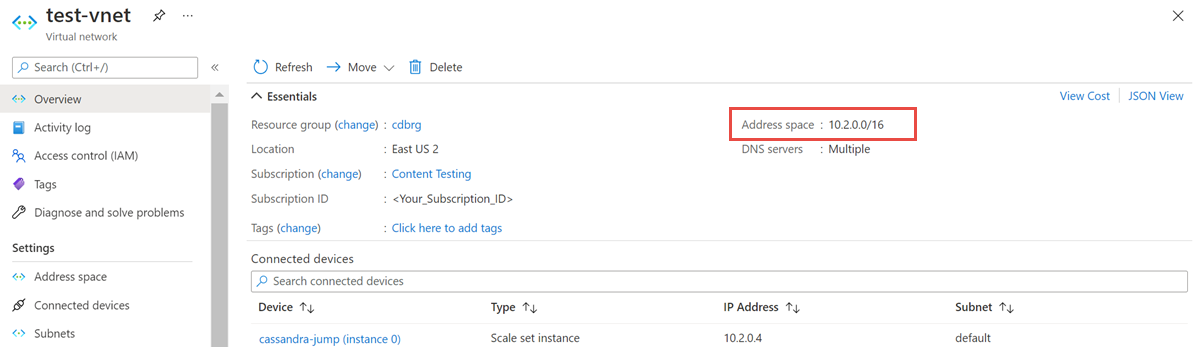
Kaynak grubunda Ekle'yi seçin ve arama alanında Azure Databricks'i arayın.
Azure Databricks hesabı oluşturmak için Oluştur'u seçin.
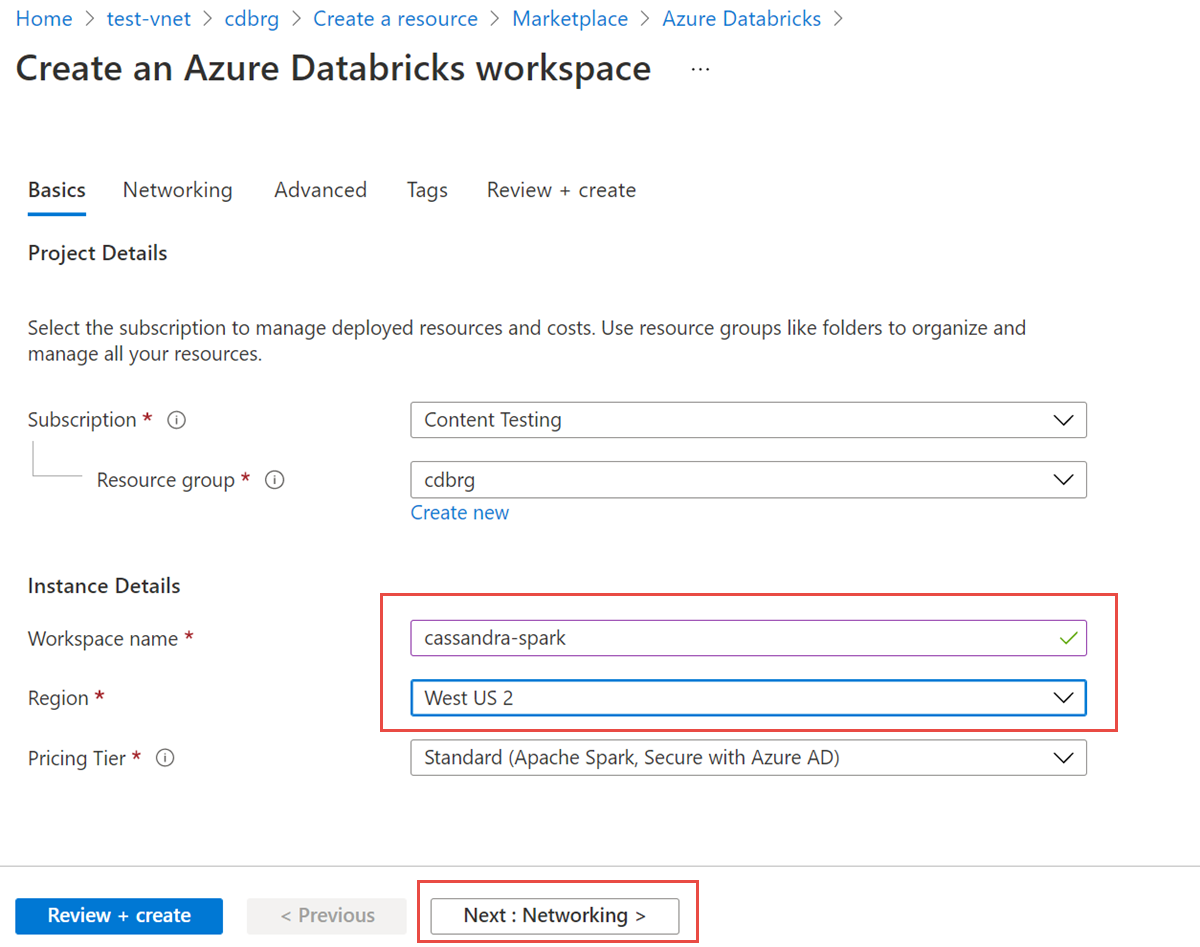
Aşağıdaki değerleri girin:
- Çalışma alanı adı: Azure Databricks çalışma alanınız için bir ad belirtin.
- Bölge: Sanal ağınızla aynı bölgeyi seçtiğinizden emin olun.
- Fiyatlandırma Katmanı: Standart, Premium veya Deneme'yi seçin. Bu katmanlar hakkında daha fazla bilgi için bkz. Azure Databricks fiyatlandırma sayfası.
Ağ Bağlantısı sekmesini seçin ve aşağıdaki ayrıntıları girin:
- Azure Databricks çalışma alanını Sanal Ağınıza (VNet) dağıtın: Evet'i seçin.
- Sanal Ağ: Açılan listeden yönetilen örneğinizin bulunduğu sanal ağı seçin.
- Genel Alt Ağ Adı: Genel alt ağ için bir ad girin.
- Genel Alt Ağ CIDR Aralığı: Genel alt ağ için bir IP aralığı girin.
- Özel Alt Ağ Adı: Özel alt ağ için bir ad girin.
- Özel Alt Ağ CIDR Aralığı: Özel alt ağ için bir IP aralığı girin.
Aralık çakışmalarını önlemek için daha yüksek aralıklar seçtiğinizden emin olun. Gerekirse, aralıkları bölmek için görsel bir alt ağ hesaplayıcısı kullanın.
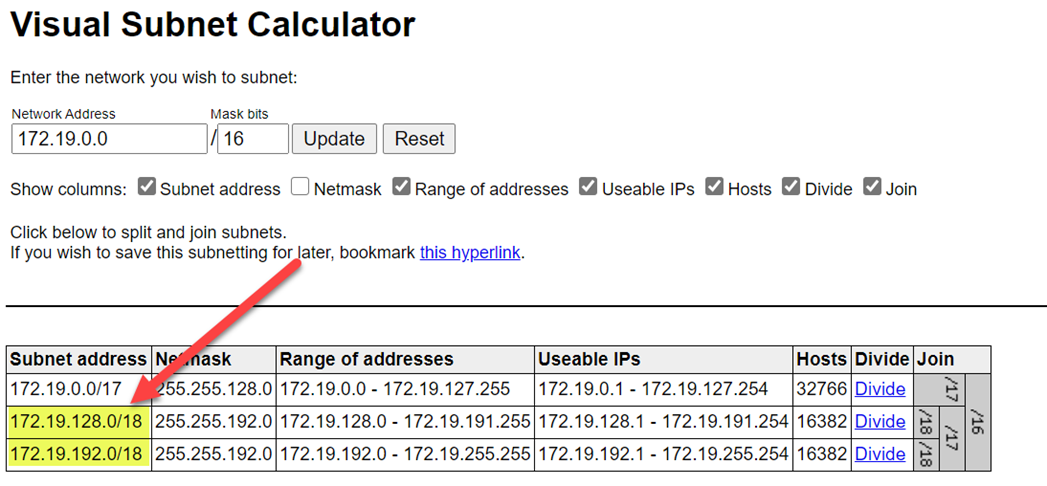
Aşağıdaki ekran görüntüsünde ağ bölmesindeki örnek ayrıntılar gösterilmektedir.
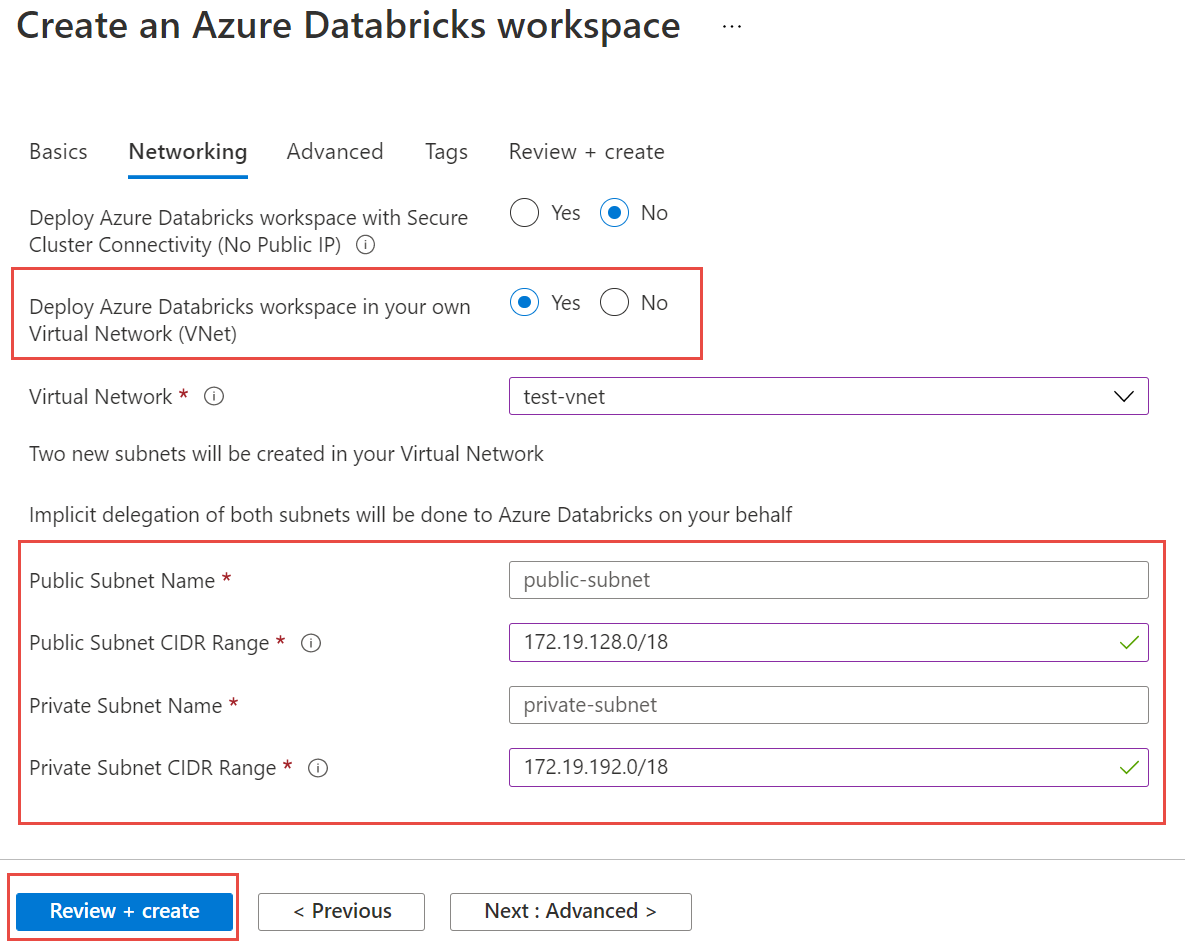
Çalışma alanını dağıtmak için Gözden geçir ve oluştur'u ve ardından Oluştur'u seçin.
Çalışma alanı oluşturulduktan sonra çalışma alanını açın.
Azure Databricks portalına yönlendirilirsiniz. Portaldan Yeni Küme'yi seçin.
Yeni küme bölmesinde, aşağıdaki alanlar dışındaki tüm alanlar için varsayılan değerleri kabul edin:
- Küme Adı: Küme için bir ad girin.
- Databricks Runtime Sürümü: Spark 3.x desteği için Azure Databricks çalışma zamanı sürüm 7.5 veya üzerini seçmenizi öneririz.

Gelişmiş Seçenekler'i genişletin ve aşağıdaki yapılandırmayı ekleyin. Düğüm IP'lerini ve kimlik bilgilerini değiştirdiğinden emin olun.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueHem yerel hem de Azure Cosmos DB Cassandra uç noktalarına bağlanmak için kümenize Apache Spark Cassandra Bağlayıcı kitaplığını ekleyin. Kümenizde Kitaplıklar>Yeni>Maven Yükle'yi seçin ve ardından Maven
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0alanına ekleyin.
Yükle'yi seçin.
Kaynakları temizleme
Bu yönetilen örnek kümesini kullanmaya devam etmeyecekseniz, silmek için şu adımları izleyin:
- Azure portalının sol menüsünde Kaynak grupları'nı seçin.
- Listeden, bu hızlı başlangıç için oluşturduğunuz kaynak grubunu seçin.
- Kaynak grubuna Genel Bakış bölmesinde Kaynak grubunu sil'i seçin.
- Sonraki bölmede, silinecek kaynak grubunun adını girin ve sil'i seçin.
Sonraki adım
Bu hızlı başlangıçta, Apache Cassandra için Azure Yönetilen Örneği kümenizin sanal ağı içinde tam olarak yönetilen bir Apache Spark kümesi oluşturmayı öğrendiniz. Ardından küme ve veri merkezi kaynaklarını yönetmeyi öğrenin.