Azure bölgelerinde SAP HANA kullanılabilirliği
Bu makalede, farklı Azure bölgelerinde SAP HANA kullanılabilirliği ile ilgili senaryolar açıklanmaktadır. Azure bölgeleri arasındaki uzaklık nedeniyle, birden çok Azure bölgesinde SAP HANA kullanılabilirliğini ayarlamak için dikkat edilmesi gereken özel noktalar vardır.
Neden birden çok Azure bölgesine dağıtılır?
Azure bölgeleri genellikle büyük mesafelerle ayrılır. Jeopolitik bölgeye bağlı olarak Azure bölgeleri arasındaki mesafe yüzlerce mil, hatta Birleşik Devletler gibi birkaç bin mil olabilir. Uzaklık nedeniyle, iki farklı Azure bölgesinde dağıtılan varlıklar arasındaki ağ trafiği önemli ağ gidiş dönüş gecikmesi yaşar. Gecikme süresi, tipik SAP iş yükleri altında iki SAP HANA örneği arasındaki zaman uyumlu veri alışverişini dışlamak için yeterlidir.
Öte yandan, kuruluşlar genellikle birincil veri merkezinin konumu ile ikincil bir veri merkezinin konumu arasında mesafe gereksinimine sahiptir. Mesafe gereksinimi, daha geniş bir coğrafi konumda doğal afet yaşanması durumunda kullanılabilirlik sağlamaya yardımcı olur. Eylül ve Ekim 2017'de Karayipler ve Florida'ya çarpan kasırgalar buna örnek olarak verilebilir. Kuruluşunuzun en az minimum mesafe gereksinimi olabilir. Çoğu Azure müşterisi için minimum uzaklık tanımı, Azure bölgelerinde kullanılabilirlik için tasarlamanızı gerektirir. İki Azure bölgesi arasındaki uzaklık HANA zaman uyumlu çoğaltma modunu kullanamayacak kadar büyük olduğundan, RTO ve RPO gereksinimleri sizi kullanılabilirlik yapılandırmalarını tek bir bölgeye dağıtmaya ve ardından ikinci bir bölgede ek dağıtımlar yapmaya zorlayabilir.
Bu senaryoda dikkate alınması gereken bir diğer özellik de yük devretme ve istemci yeniden yönlendirmedir. Varsayım, iki farklı Azure bölgesinde SAP HANA örnekleri arasında yük devretmenin her zaman el ile yük devretme olduğudur. SAP HANA sistem çoğaltmasının çoğaltma modu zaman uyumsuz olarak ayarlandığından, birincil HANA örneğinde işlenen verilerin henüz ikincil HANA örneğine ulaşmamış olma olasılığı vardır. Bu nedenle, otomatik yük devretme, çoğaltmanın zaman uyumsuz olduğu yapılandırmalar için bir seçenek değildir. Yük devretme alıştırmasında olduğu gibi el ile denetlenen yük devretmede bile, diğer Azure bölgesine el ile geçmeden önce birincil taraftaki tüm işlenen verilerin ikincil örneğe yapıldığından emin olmak için gerekli önlemleri almanız gerekir.
Azure Sanal Ağ farklı bir IP adresi aralığı kullanır. IP adresleri ikinci Azure bölgesine dağıtılır. Bu nedenle, SAP HANA istemci yapılandırmasını değiştirmeniz veya tercihen ad çözümlemesini değiştirmek için adımlar oluşturmanız gerekir. Bu şekilde, istemciler yeni ikincil sitenin sunucu IP adresine yönlendirilir. Daha fazla bilgi için devralma sonrasında istemci bağlantısı kurtarma sap makalesine bakın.
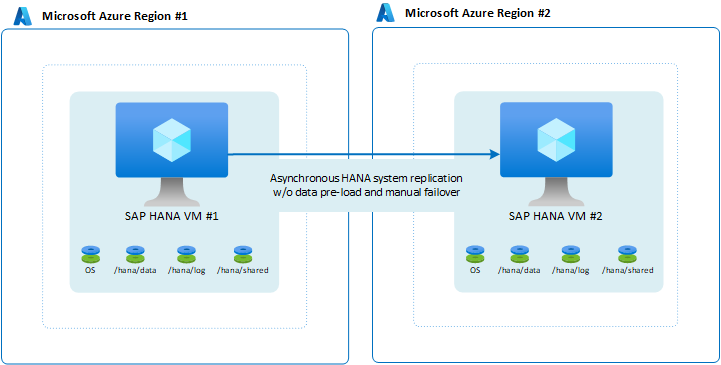
İki Azure bölgesi arasında basit kullanılabilirlik
Kullanılabilirlik yapılandırmasını tek bir bölgeye yerleştirmemeyi seçebilirsiniz, ancak olağanüstü durum oluşursa iş yükünün hizmet verme talebini yine de karşılayabilirsiniz. Bu tür senaryolar için tipik durumlar üretim dışı sistemlerdir. Sistemin yarım gün, hatta bir gün boyunca devre dışı bırakılabilmesi sürdürülebilir olsa da, sistemin 48 saat veya daha uzun süre kullanılamaz durumda olmasına izin veremezsiniz. Kurulumu daha az maliyetli hale getirmek için VM'de daha da az önemli olan başka bir sistem çalıştırın. Diğer sistem hedef olarak çalışır. Ayrıca, ikincil bölgedeki VM'yi daha küçük olacak şekilde boyutlandırabilir ve verileri önceden yüklememeyi seçebilirsiniz. Yük devretme el ile olduğundan ve tam uygulama yığınına yük devretmek için daha birçok adım gerektirdiğinden, VM'yi kapatmak, yeniden boyutlandırmak ve ardından VM'yi yeniden başlatmak için ek süre kabul edilebilir.
DR hedefini tek bir VM'de bir Soru-Cevap sistemiyle paylaşma senaryolarını kullanıyorsanız şu noktaları dikkate almanız gerekir:
- delta_datashipping ve logreplay içeren iki işlem modu vardır ve bu tür bir senaryo için kullanılabilir
- Her iki işlem modu da verileri önceden yüklemeden farklı bellek gereksinimlerine sahiptir
- Delta_datashipping, logreplay'in gerektirebileceğinden daha önceden yükleme seçeneği olmadan önemli ölçüde daha az bellek gerektirebilir. SAP HANA için Sistem Çoğaltması Gerçekleştirme sap belgesinin 4.3. bölümüne bakın
- Önceden yükleme olmadan logreplay işlem modunun bellek gereksinimi belirlenimci değildir ve yüklenen columnstore yapılarına bağlıdır. Aşırı durumlarda, birincil örneğin belleğinin %50'sine ihtiyacınız olabilir. Logreplay işlem modunun belleği, verilerin önceden yüklenmiş olup olmadığına göre bağımsızdır.
Dekont
HANA sistem çoğaltma modunuz zaman uyumsuz olduğundan bu yapılandırmada RPO=0 sağlayamazsınız. RPO=0 sağlamanız gerekiyorsa, bu yapılandırma tercih ettiğiniz yapılandırma değildir.
Yapılandırmada yapabileceğiniz küçük bir değişiklik, verileri önceden yükleme olarak yapılandırmak olabilir. Ancak, yük devretmenin el ile yapısı ve uygulama katmanlarının ikinci bölgeye de taşınması gerektiği göz önüne alındığında, verilerin önceden yüklenmesi mantıklı olmayabilir.
Kullanılabilirliği tek bir bölgede ve bölgeler arasında birleştirme
Bölgeler içinde ve bölgeler arasında kullanılabilirlik birleşimi şu faktörler tarafından yönlendirilebilir:
- Azure bölgesinde RPO=0 gereksinimi.
- Kuruluş, daha büyük bir bölgeyi etkileyen büyük bir doğal felaketten etkilenen küresel operasyonlara sahip olmaya istekli veya mümkün değildir. Son birkaç yılda Karayipler'i vuran bazı kasırgalar için bu durum geçerliydi.
- Birincil ve ikincil siteler arasındaki mesafeleri gerektiren ve Azure kullanılabilirlik alanlarının sağlayabileceklerinin ötesinde olan düzenlemeler.
Bu gibi durumlarda, HANA sistem çoğaltmasını kullanarak SAP'nin SAP HANA çok katmanlı sistem çoğaltma yapılandırmasını çağırdığı ayarları yapabilirsiniz. Mimari şöyle görünür:
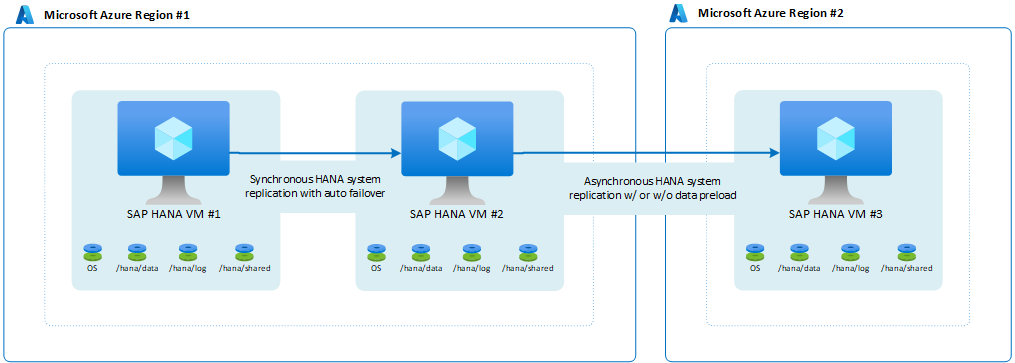
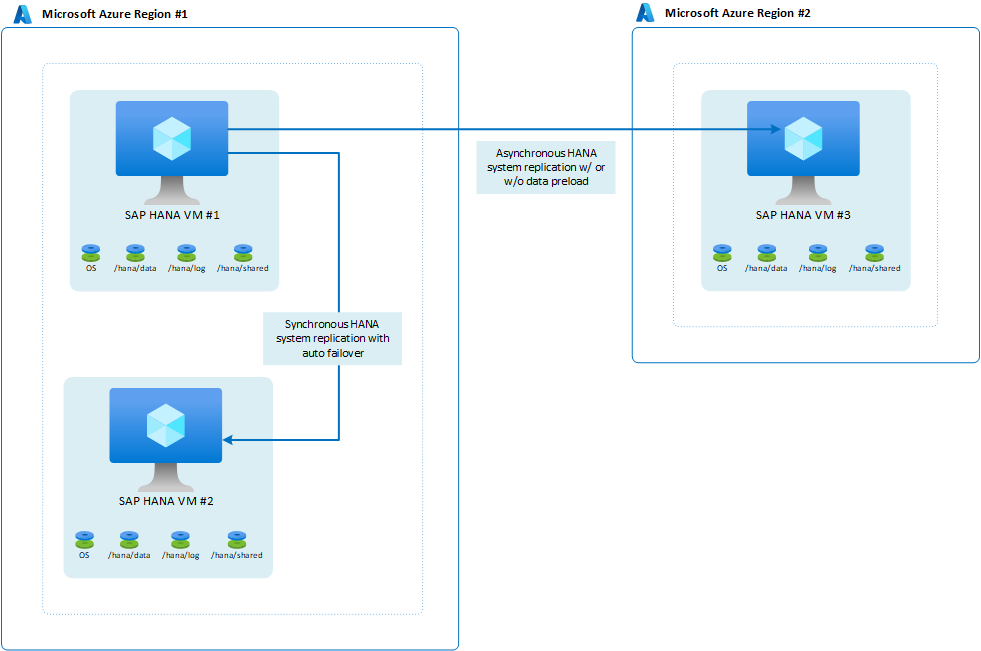
SAP, HANA 2.0 SPS3 ile çok hedefli sistem çoğaltması kullanıma sunulmuştur. Çok hedefli sistem çoğaltması, güncelleştirme senaryolarında bazı avantajlar sağlar. Örneğin, ikincil HA sitesi bakım veya güncelleştirme için kapatıldığında DR sitesi (Bölge 2) etkilenmez. SAP Yardım Portalı'nda HANA çok hedefli sistem çoğaltması hakkında daha fazla bilgi edinebilirsiniz. Çok hedefli çoğaltma ile olası mimari şöyle görünür:
Kuruluşun ikinci (DR) Azure bölgesinde yüksek kullanılabilirliğe hazır olma gereksinimleri varsa mimari şöyle görünür:
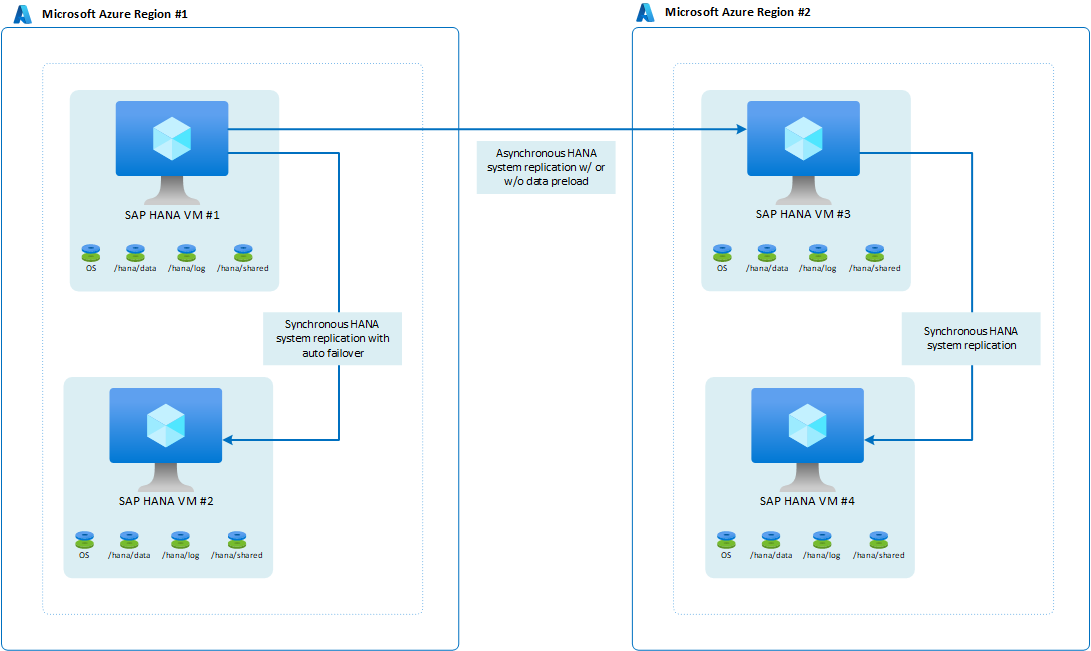
Logreplay'i işlem modu olarak kullanan bu yapılandırma, birincil bölge içinde düşük RTO'ya sahip bir RPO=0 sağlar. İkinci bölgeye bir taşıma söz konusu olduğunda yapılandırma iyi bir RPO da sağlar. İkinci bölgedeki RTO süreleri, verilerin önceden yüklenip yüklenmediğine bağlıdır. Birçok müşteri, bir test sistemi çalıştırmak için ikincil bölgedeki VM'yi kullanır. Bu kullanım örneğinde veriler önceden yüklenemez.
Önemli
Farklı katmanlar arasındaki işlem modlarının homojen olması gerekir. Katman 3 sağlamak için logreplay'i katman 1 ile katman 2 ile delta_datashipping arasında işlem modu olarak kullanamazsınız. Yalnızca tüm katmanlar için tutarlı olması gereken bir veya diğer işlem modunu seçebilirsiniz. delta_datashipping size RPO=0 vermek için uygun olmadığından, bu çok katmanlı yapılandırma için tek makul işlem modu logreplay olarak kalır. İşlem modları ve bazı kısıtlamalar hakkında ayrıntılı bilgi için SAP HANA sistem çoğaltması için işlem modları başlıklı SAP makalesine bakın.
Sonraki adımlar
Azure'da bu yapılandırmaları ayarlama konusunda adım adım yönergeler için bkz: