Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Tam metin arama, dizinde depolanan düz metinle eşleşen bilgi alma yaklaşımıdır. Örneğin, "San Diego'daki plajdaki oteller" sorgu dizesi verüldüğünde, arama motoru bu terimlere göre belirteçli dizeleri arar. Taramaları daha verimli hale getirmek için sorgu dizeleri sözcük temelli analizden geçer: tüm terimlerin küçük harfle yazılması, "the" gibi durdurma sözcüklerinin kaldırılması ve terimlerin temel kök formlara indirilmesi. Eşleşen terimler bulunduğunda, arama altyapısı belgeleri alır, ilgi sırasına göre sıralar ve en iyi sonuçları döndürür.
Sorgu yürütme karmaşık olabilir. Bu makale, Azure AI Search'te tam metin aramanın nasıl çalıştığı hakkında daha ayrıntılı bilgi sahibi olması gereken geliştiricilere yöneliktir. Metin sorguları için Azure AI Search çoğu senaryoda beklenen sonuçları sorunsuz bir şekilde sunar, ancak bazen bir şekilde "kapalı" gibi görünen bir sonuç alabilirsiniz. Bu gibi durumlarda, Lucene sorgu yürütmesinin dört aşamasında (sorgu ayrıştırma, sözcük analizi, belge eşleştirme, puanlama) bir arka plana sahip olmak, sorgu parametrelerinde veya dizin yapılandırmasında istenen sonucu oluşturan belirli değişiklikleri belirlemenize yardımcı olabilir.
Not
Azure AI Search tam metin araması için Apache Lucene kullanır, ancak Lucene tümleştirmesi kapsamlı değildir. Azure AI Search için önemli senaryoları etkinleştirmek için Lucene işlevselliğini seçmeli olarak kullanıma sağlıyoruz ve genişletiyoruz.
Mimariye genel bakış ve diyagram
Sorgu yürütmenin dört aşaması vardır:
- Sorgu ayrıştırma
- Sözcük temelli analiz
- Belge alma
- Puanlama
Tam metin arama sorgusu, arama terimlerini ve işleçlerini ayıklamak için sorgu metnini ayrıştırmayla başlar. Hız ve karmaşıklık arasında seçim yapabileceğiniz iki ayrıştırıcı vardır. Bir analiz aşaması daha sonra, tek tek sorgu terimlerinin bazen bölündüğü ve yeni formlara yeniden eklendiği bir aşama vardır. Bu adım, olası bir eşleşme olarak değerlendirilebilecekler üzerinde daha geniş bir ağ oluşturmanıza yardımcı olur. Arama altyapısı daha sonra eşleşen terimlere sahip belgeleri bulmak için dizini tarar ve her eşleşmeyi puanlar. Sonuç kümesi, eşleşen her bir belgeye atanan bir ilgi puanına göre sıralanır. Dereceli listenin en üstündekiler çağıran uygulamaya döndürülür.
Aşağıdaki diyagramda arama isteğini işlemek için kullanılan bileşenler gösterilmektedir.
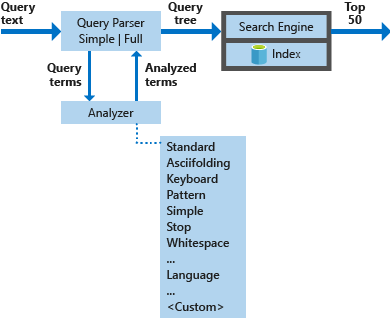
| Anahtar bileşenler | İşlevsel açıklama |
|---|---|
| Sorgu ayrıştırıcıları | Sorgu terimlerini sorgu işleçlerinden ayırın ve arama altyapısına gönderilecek sorgu yapısını (sorgu ağacı) oluşturun. |
| Çözümleyiciler | Sorgu terimleri üzerinde sözcük temelli analiz gerçekleştirin. Bu işlem sorgu terimlerini dönüştürmeyi, kaldırmayı veya genişletmeyi içerebilir. |
| Dizin | Dizine alınan belgelerden ayıklanan aranabilir terimleri depolamak ve düzenlemek için kullanılan verimli bir veri yapısı. |
| Arama motoru | Ters çevrilmiş dizinin içeriğine göre eşleşen belgeleri alır ve puanlar. |
Arama isteğinin anatomisi
Arama isteği, sonuç kümesinde döndürülmesi gerekenlerin tam belirtimidir. En basit biçimde, hiçbir ölçüte sahip olmayan boş bir sorgu olur. Daha gerçekçi bir örnek parametreleri, çeşitli sorgu terimlerini, belki de kapsamı belirli alanlarla belirlenmiş ve muhtemelen bir filtre ifadesi ve sıralama kuralları içerir.
Aşağıdaki örnek, REST API kullanarak Azure AI Search'e gönderebilecekleri bir arama isteğidir.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Bu istek için arama altyapısı aşağıdaki işlemleri yapar:
Fiyatın en az 60 TL ve 300 TL'den düşük olduğu belgeleri bulur.
Sorguyu yürütür. Bu örnekte, arama sorgusu tümceciklerden ve terimlerden oluşur:
"Spacious, air-condition* +\"Ocean view\""(kullanıcılar genellikle noktalama işaretleri girmez, ancak örneği dahil etmek çözümleyicilerin bunu nasıl işlediğini açıklamamıza olanak tanır).Bu sorgu için, arama altyapısı "searchFields" içinde belirtilen açıklama ve başlık alanlarını içeren
"Ocean view"belgeler için ve ayrıca terimiyle"spacious"veya ön ekiyle"air-condition"başlayan terimlerle tarar. "searchMode" parametresi, bir terimin açıkça gerekli+olmadığı () durumlarda herhangi bir terimle (varsayılan) veya tümüyle eşleştirmek için kullanılır.Elde edilen otel kümesini belirli bir coğrafya konumuna yakınlığıyla sıralar ve ardından sonuçları çağıran uygulamaya döndürür.
Bu makalenin çoğu arama sorgusunun işlenmesiyle ilgili: "Spacious, air-condition* +\"Ocean view\"". Filtreleme ve sıralama kapsamın dışında. Daha fazla bilgi için Arama API'si başvuru belgelerine bakın.
1. Aşama: Sorgu ayrıştırma
Belirtildiği gibi sorgu dizesi isteğin ilk satırıdır:
"search": "Spacious, air-condition* +\"Ocean view\"",
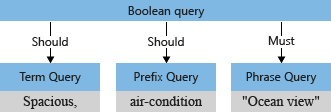
Sorgu ayrıştırıcısı, işleçleri (örneğin * ve + örnekte) arama terimlerinden ayırır ve arama sorgusunu desteklenen türde alt sorgulara ayırır:
- tek başına terimler için terim sorgusu (geniş gibi)
- tırnak içine alınmış terimler için tümcecik sorgusu (okyanus görünümü gibi)
-
terimler için ön ek sorgusu ve ardından bir ön ek işleci
*(klima gibi)
Desteklenen sorgu türlerinin tam listesi için bkz. Lucene sorgu söz dizimi
Bir alt sorguyla ilişkili işleçler, bir belgenin eşleşme olarak kabul edilmesi için sorgunun "olması" veya "yerine getirilmesi" gerektiğini belirler. Örneğin, +"Ocean view" işlecinden + dolayı "must" olur.
Sorgu ayrıştırıcısı, alt sorguları arama altyapısına geçirdiği bir sorgu ağacına (sorguyu temsil eden bir iç yapı) yeniden yapılandırıyor. Sorgu ayrıştırma işleminin ilk aşamasında, sorgu ağacı şöyle görünür.
Desteklenen ayrıştırıcılar: Basit ve Tam Lucene
Azure AI Search, (varsayılan) ve fullolmak üzere simple iki farklı sorgu dilini kullanıma sunar. Arama isteğinizle parametreyi queryType ayarlayarak, işleçleri ve söz dizimini yorumlamayı bilmesi için sorgu ayrıştırıcısına hangi sorgu dilini seçtiğinizi söylersiniz.
Basit sorgu dili sezgisel ve sağlamdır; genellikle kullanıcı girişini istemci tarafı işleme olmadan olduğu gibi yorumlamaya uygundur. Web arama motorlarından tanıdık sorgu işleçlerini destekler.
ayarlayarak
queryType=fullelde ettiğiniz Tam Lucene sorgu dili, joker karakter, belirsiz, regex ve alan kapsamlı sorgular gibi daha fazla işleç ve sorgu türü için destek ekleyerek varsayılan Basit sorgu dilini genişletir. Örneğin, Basit sorgu söz diziminde gönderilen normal ifade, ifade olarak değil sorgu dizesi olarak yorumlanır. Bu makaledeki örnek istek, Tam Lucene sorgu dilini kullanır.
searchMode'un ayrıştırıcı üzerindeki etkisi
Ayrıştırma işlemini etkileyen bir diğer arama isteği parametresi de "searchMode" parametresidir. Boole sorguları için varsayılan işleci denetler: tümü (varsayılan) veya tümü.
Varsayılan değer olan "searchMode=any" olduğunda, geniş ve klima arasındaki boşluk sınırlayıcısı OR ()|| olur ve örnek sorgu metni şunun eşdeğeri olur:
Spacious,||air-condition*+"Ocean view"
gibi +"Ocean view"açık işleçler boole + sorgu yapısında kesin değildir (terimin eşleşmesi gerekir). Daha az belirgin olan, kalan terimleri yorumlamaktır: geniş ve klima. Arama motoru okyanus görünümünde ve geniş ve klimada eşleşmeler bulmalı mı? Yoksa okyanus görünümünün yanı sıra kalan terimlerden birini mi bulmalıdır?
Varsayılan olarak ("searchMode=any"), arama altyapısı daha geniş bir yorum olduğunu varsayar. Her iki alan da "veya" semantiğini yansıtarak eşleştirilmelidir . Daha önce gösterilen ilk sorgu ağacı, iki "should" işlemiyle birlikte varsayılanı gösterir.
Şimdi "searchMode=all" ayarlayacağımızı varsayalım. Bu durumda, boşluk bir "ve" işlemi olarak yorumlanır. Eşleşme olarak nitelenecek kalan terimlerin her ikisi de belgede bulunmalıdır. Sonuçta elde edilen örnek sorgu aşağıdaki gibi yorumlanabilir:
+Spacious,+air-condition*+"Ocean view"
Bu sorgu için değiştirilmiş bir sorgu ağacı aşağıdaki gibi olur ve eşleşen bir belge üç alt sorgunun da kesişimidir:

Not
"searchMode=all" yerine "searchMode=any" öğesinin seçilmesi en iyi sonucu temsili sorgular çalıştırarak alırsınız. "searchMode=all" boole sorgu yapılarını bilgilendirirse, işleçleri dahil etme olasılığı yüksek kullanıcılar (belge depolarında arama yaparken yaygın olan) sonuçları daha sezgisel bulabilir. "searchMode" ile işleçler arasındaki etkileşim hakkında daha fazla bilgi için bkz . Basit sorgu söz dizimi.
2. Aşama: Sözcük temelli analiz
Sözcük temelli çözümleyiciler, sorgu ağacı yapılandırıldıktan sonra terim sorgularını ve tümcecik sorgularını işler. Çözümleyici ayrıştırıcı tarafından ona verilen metin girişlerini kabul eder, metni işler ve ardından sorgu ağacına dahil edilecek belirteçli terimleri geri gönderir.
Sözcük temelli analizin en yaygın biçimi, belirli bir dile özgü kurallara göre sorgu terimlerini dönüştüren *dil analizidir:
- Sorgu terimini bir sözcüğün kök biçimine küçültme
- Temel olmayan sözcükleri kaldırma (İngilizcede "the" veya "and" gibi stopwords)
- Bileşik sözcüğü bileşen parçalarına ayırma
- Büyük harf sözcüğünü küçük harfle yazma
Bu işlemlerin tümü, kullanıcı tarafından sağlanan metin girişi ile dizinde depolanan terimler arasındaki farkları silme eğilimindedir. Bu tür işlemler metin işlemenin ötesine geçer ve dilin kendisi hakkında ayrıntılı bilgi gerektirir. Azure AI Search, bu dil farkındalığı katmanını eklemek için hem Lucene hem de Microsoft'tan uzun bir dil çözümleyicisi listesini destekler.
Not
Analiz gereksinimleri, senaryonuza bağlı olarak minimalden ayrıntılıya kadar değişebilir. Önceden tanımlanmış çözümleyicilerden birini seçerek veya kendi özel çözümleyicinizi oluşturarak sözcük analizinin karmaşıklığını denetleyebilirsiniz. Çözümleyicilerin kapsamı aranabilir alanlara göre belirlenir ve alan tanımının bir parçası olarak belirtilir. Bu, sözcük temelli analizi alan bazında değişiklik yapmanızı sağlar. Belirtilmemiş, standart Lucene çözümleyicisi kullanılır.
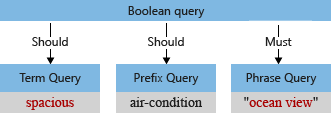
Örneğimizde, analizden önce ilk sorgu ağacının "Geniş" terimi, büyük harf "S" ve sorgu ayrıştırıcısının sorgu teriminin bir parçası olarak yorumlayan virgül (virgül sorgu dili işleci olarak kabul edilmez) vardır.
Varsayılan çözümleyici terimi işlediğinde, "okyanus görünümü" ve "geniş" terimlerini küçük harfe dönüştürür ve virgül karakterini kaldırır. Değiştirilen sorgu ağacı şöyle görünür:
Çözümleyici davranışlarını test etme
Çözümleyicinin davranışı Çözümle API'sini kullanarak test edilebilir. Verilen çözümleyicinin hangi terimleri oluşturacaklarını görmek için analiz etmek istediğiniz metni sağlayın. Örneğin, standart çözümleyicinin "air-condition" metnini nasıl işlediğini görmek için aşağıdaki isteği gönderebilirsiniz:
{
"text": "air-condition",
"analyzer": "standard"
}
Standart çözümleyici giriş metnini aşağıdaki iki belirtece böler ve bunlara başlangıç ve bitiş uzaklıkları (isabet vurgulama için kullanılır) ve konumları (tümcecik eşleştirme için kullanılır) gibi özniteliklerle açıklama ekler:
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Sözcük temelli çözümlemeye yönelik özel durumlar
Sözcük temelli analiz yalnızca terim sorgusu veya tümcecik sorgusu gibi tam terimler gerektiren sorgu türleri için geçerlidir. Tamamlanmamış terimlere (ön ek sorgusu, joker karakter sorgusu, regex sorgusu) veya benzer bir sorguya sahip sorgu türleri için geçerli değildir. Örneğimizde terim air-condition* içeren ön ek sorgusu da dahil olmak üzere bu sorgu türleri, analiz aşaması atlayarak doğrudan sorgu ağacına eklenir. Bu türlerin sorgu terimlerinde gerçekleştirilen tek dönüştürme küçük harf kullanımıdır.
3. Aşama: Belge alma
Belge alma, dizinde eşleşen terimlere sahip belgeleri bulmayı ifade eder. Bu aşama bir örnekle en iyi şekilde anlaşılır. Aşağıdaki basit şemaya sahip bir oteller diziniyle başlayalım:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Bu dizinin aşağıdaki dört belgeyi içerdiğini de varsayalım:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Terimler nasıl dizinlenir?
Alma işlemini anlamak için dizin oluşturma hakkında birkaç temel bilgi edinmeye yardımcı olur. Depolama birimi, her aranabilir alan için bir tane olan ters dizindir. Ters çevrilmiş bir dizinde, tüm belgelerdeki tüm terimlerin sıralanmış listesi yer alır. Her terim, aşağıdaki örnekte gösterildiği gibi, içinde bulunduğu belgelerin listesiyle eşler.
Terimleri ters dizinde oluşturmak için arama altyapısı, sorgu işleme sırasında gerçekleşenlere benzer şekilde belgelerin içeriği üzerinde sözcük temelli analiz gerçekleştirir:
- Metin girişleri çözümleyici yapılandırmasına bağlı olarak bir çözümleyiciye geçirilir, küçük harfe dönüştürülür, noktalama işaretleri çıkarılır vb.
- Belirteçler , sözcük temelli analizin çıkışıdır.
- Terimler dizine eklenir.
Sorgu terimlerinin dizin içindeki terimlere daha çok benzemesi için arama ve dizin oluşturma işlemleri için aynı çözümleyicilerin kullanılması yaygın bir durumdur ancak gerekli değildir.
Not
Azure AI Search, ek indexAnalyzer ve searchAnalyzer alan parametreleri aracılığıyla dizin oluşturma ve arama için farklı çözümleyiciler belirtmenize olanak tanır. Belirtilmezse, özelliğiyle analyzer ayarlanan çözümleyici hem dizin oluşturma hem de arama için kullanılır.
Örnek belgeler için ters dizin
Örneğimize dönerken, başlık alanı için ters dizin şöyle görünür:
| Süre | Belge listesi |
|---|---|
| atman | 1 |
| plaj | 2 |
| otel | 1, 3 |
| okyanus | 4 |
| Playa | 3 |
| Resort | 3 |
| geri çekilmek | 4 |
Başlık alanında yalnızca otel iki belgede gösterilir: 1, 3.
Açıklama alanı için dizin aşağıdaki gibidir:
| Süre | Belge listesi |
|---|---|
| hava | 3 |
| ile | 4 |
| plaj | 1 |
| Şartlı | 3 |
| rahat | 3 |
| uzaklık | 1 |
| ada | 2 |
| kauaʻi | 2 |
| Yer almaktadır | 2 |
| north | 2 |
| okyanus | 1, 2, 3 |
| / | 2 |
| on | 2 |
| sessiz | 4 |
| Oda -larında | 1, 3 |
| ayrılmış | 4 |
| sahil | 2 |
| geniş | 1 |
| şunu | 1, 2 |
| kullanıcısı | 1 |
| görünüm | 1, 2, 3 |
| Yürüyüş | 1 |
| örneklerini şununla değiştirin: | 3 |
Sorgu terimlerini dizinlenmiş terimlerle eşleştirme
Yukarıdaki ters dizinleri göz önünde bulundurarak örnek sorguya geri dönelim ve örnek sorgumuz için eşleşen belgelerin nasıl bulunduğunu görelim. Son sorgu ağacının şöyle göründüğünü hatırlayın:
Sorgu yürütme sırasında, tek tek sorgular aranabilir alanlarda bağımsız olarak yürütülür.
TermQuery, "ferah", belge 1 (Hotel Atman) ile eşleşir.
PrefixQuery , "air-condition*", hiçbir belgeyle eşleşmiyor.
Bu, bazen geliştiricilerin kafasını karıştıran bir davranıştır. Belgede klima terimi mevcut olsa da, varsayılan çözümleyici tarafından iki terime ayrılır. Kısmi terimler içeren ön ek sorgularının analiz olmadığını hatırlayın. Bu nedenle ön eki "air-condition" olan terimler ters dizinde aranıp bulunamaz.
"Okyanus görünümü" olan PhraseQuery, "okyanus" ve "görünüm" terimlerini arar ve özgün belgedeki terimlerin yakınlıklarını denetler. 1, 2 ve 3 belgeleri, açıklama alanındaki bu sorguyla eşleşmektedir. 4. belgenin başlığında okyanus teriminin yer aldığına ancak tek tek sözcükler yerine "okyanus görünümü" tümceciği aradığımız için eşleşme olarak kabul edilmediğini görebilirsiniz.
Not
Örnek arama isteğinde gösterildiği gibi, parametreyle searchFields ayarlanan alanları sınırlamadığınız sürece, arama sorgusu Azure AI Search dizinindeki tüm aranabilir alanlara karşı bağımsız olarak yürütülür. Seçili alanlardan herhangi birinde eşleşen belgeler döndürülür.
Söz konusu sorgunun tamamında, eşleşen belgeler 1, 2, 3'lerdir.
4. Aşama: Puanlama
Arama sonucu kümesindeki her belgeye bir ilgi puanı atanır. İlgi puanının işlevi, arama sorgusu tarafından ifade edilen bir kullanıcı sorusuna en iyi yanıt veren belgelerin daha yüksek derecesini almaktır. Puan, eşleşen terimlerin istatistiksel özelliklerine göre hesaplanır. Puanlama formülünün merkezinde TF/IDF (sıklık ters belge sıklığı terimi) bulunur. Nadir ve yaygın terimler içeren sorgularda, TF/IDF nadir terimi içeren sonuçları yükseltmektedir. Örneğin, tüm Wikipedia makalelerinin olduğu varsayımsal bir dizinde, başkanın sorgusuyla eşleşen belgelerden, başkanlaeşleşen belgeler, ile eşleşen belgelerden daha ilgili kabul edilir.
Puanlama örneği
Örnek sorgumuzla eşleşen üç belgeyi hatırlayın:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Hem geniş terimi hem de gerekli tümcecik okyanus görünümü açıklama alanında gerçekleştiğinden, belge 1 sorguyla en iyi şekilde eşleşmiş. Sonraki iki belge yalnızca okyanus görünümü tümceciğiyle eşleşecek. 2. ve 3. belgenin ilgi puanının sorguyla aynı şekilde eşleşmesine rağmen farklı olması şaşırtıcı olabilir. Bunun nedeni, puanlama formülünde TF/IDF'den daha fazla bileşen olmasıdır. Bu durumda, açıklaması daha kısa olduğundan belge 3'e biraz daha yüksek bir puan atanmıştır. Alan uzunluğunun ve diğer faktörlerin ilgi puanını nasıl etkileyebileceğinizi anlamak için Lucene'in Pratik Puanlama Formülü hakkında bilgi edinin.
Bazı sorgu türleri (joker karakter, ön ek, regex) her zaman genel belge puanına sabit bir puan ekler. Bu, sorgu genişletmesi aracılığıyla bulunan eşleşmelerin sonuçlara dahil edilmesini sağlar, ancak derecelendirmeyi etkilemeden.
Bunun neden önemli olduğunu gösteren bir örnek. Ön ek aramaları da dahil olmak üzere joker karakter aramaları tanım gereği belirsizdir çünkü giriş çok fazla sayıda farklı terimde olası eşleşmeleri olan kısmi bir dizedir ("turlar", "turnettes" ve "tourmaline" üzerinde eşleşmeler bulunan "tur*" girişini göz önünde bulundurun). Bu sonuçların doğası gereği, hangi terimlerin diğerlerinden daha değerli olduğunu makul bir şekilde çıkarmanın bir yolu yoktur. Bu nedenle, puanlama joker karakter, ön ek ve regex türünde sorgulara neden olurken terim sıklıklarını yoksayarız. Kısmi ve eksiksiz terimler içeren çok parçalı arama isteğinde, beklenmedik olabilecek eşleşmelere karşı sapma olmaması için kısmi giriş sonuçları sabit bir puanla birleştirilmiştir.
İlgi düzeyini ayarlama
Azure AI Search'te ilgi puanlarını ayarlamanın iki yolu vardır:
Puanlama profilleri , bir dizi kurala göre dereceli sonuç listesinde belgeleri yükseltiyor. Örneğimizde, başlık alanında eşleşen belgeler, açıklama alanında eşleşen belgelerden daha ilgili olabilir. Ayrıca, dizinimizde her otel için bir fiyat alanı varsa, belgeleri daha düşük fiyatla tanıtabiliriz. Arama dizinine puanlama profilleri ekleme hakkında daha fazla bilgi edinin.
Terim artırma (yalnızca Full Lucene sorgu söz diziminde kullanılabilir), sorgu ağacının herhangi bir bölümüne uygulanabilen bir artırma işleci
^sağlar. Örneğimizde, klima* ön ekinde arama yapmak yerine, tam olarak klima terimini veya ön eki arayabilirsiniz, ancak tam terimle eşleşen belgeler sorgu terimine yükseltme uygulanarak daha yüksek sıralanır: klima^2||klima*. Sorguda terim artırma hakkında daha fazla bilgi edinin.
Dağıtılmış dizinde puanlama
Azure AI Search'teki tüm dizinler otomatik olarak birden çok parçaya bölünerek hizmetin ölçeğini artırma veya azaltma sırasında dizini birden çok düğüm arasında hızla dağıtmamıza olanak sağlar. Bir arama isteği verildiğinde, her parçaya bağımsız olarak verilir. Her parçanın sonuçları puana göre birleştirilir ve sıralanır (başka bir sıralama tanımlanmadıysa). Puanlama işlevinin sorgu terimi sıklığını, tüm parçalar genelinde değil, parça içindeki tüm belgelerde ters belge sıklığına göre ağırlıkta tutduğunu bilmeniz önemlidir!
Başka bir deyişle, farklı parçalarda bulunan aynı belgeler için ilgi puanı farklı olabilir . Neyse ki, daha eşit bir terim dağılımı nedeniyle dizindeki belge sayısı arttıkça bu tür farklılıklar ortadan kalkma eğilimindedir. Belirli bir belgenin hangi parçaya yerleştirileceğini varsaymak mümkün değildir. Ancak, bir belge anahtarının değişmediği varsayıldığında, her zaman aynı parçaya atanır.
Genel olarak, sipariş kararlılığı önemliyse belge puanı belgeleri sıralamak için en iyi öznitelik değildir. Örneğin, aynı puana sahip iki belge göz önüne alındığında, bir belgenin aynı sorgunun sonraki çalıştırmalarında ilk kez görünmesi garanti edilmez. Belge puanı, yalnızca sonuç kümesindeki diğer belgelere göre belgeyle ilgili genel bir ilgi hissi vermelidir.
Sonuç
Ticari arama motorlarının başarısı, özel veriler üzerinde tam metin arama beklentilerine neden oldu. Neredeyse her tür arama deneyimi için, terimler yanlış yazılmış veya eksik olsa bile altyapının amacımızı anlamasını bekliyoruz. Hatta hiç belirtmediğimiz neredeyse eşdeğer terimlere veya eş anlamlılara göre eşleşmeler beklenebilir.
Teknik açıdan tam metin araması son derece karmaşıktır ve ilgili bir sonuç elde etmek için sorgu terimlerini damıtacak, genişletecek ve dönüştürecek şekilde karmaşık dil analizi ve işlemeye sistematik bir yaklaşım gerektirir. Doğası gereği karmaşıklıklar göz önünde bulundurulduğunda, sorgunun sonucunu etkileyebilecek birçok faktör vardır. Bu nedenle, tam metin aramanın mekaniğinin anlaşılması için zaman ayırarak beklenmeyen sonuçlara ulaşmaya çalışırken somut avantajlar sunar.
Bu makalede Azure AI Search bağlamında tam metin araması keşfedildi. Yaygın sorgu sorunlarını gidermeye yönelik olası nedenleri ve çözümleri tanımak için size yeterli arka plan sağladığını umuyoruz.
Sonraki adımlar
Örnek dizini oluşturun, farklı sorguları deneyin ve sonuçları gözden geçirin. Yönergeler için bkz . Azure portalında dizin oluşturma ve sorgulama.
Belgeleri Ara örnek bölümünden veya Azure portalındaki Arama gezginindeki Basit sorgu söz diziminden diğer sorgu söz dizimini deneyin.
Arama uygulamanızda derecelendirmeyi ayarlamak istiyorsanız puanlama profillerini gözden geçirin.
Dile özgü sözcük temelli çözümleyicileri uygulamayı öğrenin.
Belirli alanlarda en az işlem veya özel işleme için özel çözümleyiciler yapılandırın.