Azure AI Search'te vektör arama çözümleri için büyük belgeleri öbekleme
Büyük belgeleri daha küçük öbeklere bölmek, katıştırma modellerinin en yüksek belirteç giriş sınırları altında kalmanıza yardımcı olabilir. Örneğin, Azure OpenAI ekleme modelleri için en fazla giriş metni uzunluğu 8.191 belirteçtir. Her belirtecin yaygın OpenAI modelleri için dört karakter uzunluğunda olduğu düşünüldüğünde, bu üst sınır yaklaşık 6.000 sözcük metinle eşdeğerdir. Eklemeler oluşturmak için bu modelleri kullanıyorsanız, giriş metninin sınırın altında kalması kritik önem taşır. İçeriğinizi öbeklere bölmek, verilerinizin vektör depolarını ve metinden vektöre sorgu dönüşümlerini doldurmak için kullanılan ekleme modelleri tarafından işlenebilmesini sağlar.
Bu makalede, veri öbekleme için çeşitli yaklaşımlar açıklanmaktadır. Öbekleme yalnızca kaynak belgeler modeller tarafından uygulanan maksimum giriş boyutu için çok büyükse gereklidir.
Not
Vektör aramasının genel kullanıma açık sürümünü kullanıyorsanız, veri öbekleme ve ekleme için kitaplık veya özel beceri gibi dış kod gerekir. Şu anda önizleme aşamasında olan tümleşik vektörleştirme adlı yeni bir özellik, iç veri öbekleme ve ekleme özellikleri sunar. Tümleşik vektörleştirme dizin oluşturuculara, beceri kümelerine, Metin Bölme becerisine ve AzureOpenAiEmbedding becerisine (veya özel beceriye) bağımlıdır. Önizleme özelliklerini kullanamıyorsanız, bu makaledeki örnekler ileriye doğru alternatif bir yol sağlar.
Yaygın öbekleme teknikleri
En yaygın kullanılan yöntemden başlayarak bazı yaygın öbekleme teknikleri şunlardır:
Sabit boyutlu öbekler: Anlamsal olarak anlamlı paragraflar (örneğin, 200 sözcük) için yeterli olan ve bazı çakışmalara (örneğin, içeriğin %10-15'i) izin veren sabit bir boyut tanımlayın, vektör oluşturucuları eklemek için giriş olarak iyi öbekler üretebilir.
İçeriği temel alan değişken boyutlu öbekler: Verilerinizi tümce sonu noktalama işaretleri, satır sonu işaretçileri veya Doğal Dil İşleme (NLP) kitaplıklarındaki özellikleri kullanma gibi içerik özelliklerine göre bölümleme. Markdown dil yapısı verileri bölmek için de kullanılabilir.
Yukarıdaki tekniklerden birini özelleştirin veya yineleyin. Örneğin, büyük belgelerle ilgilenirken değişken boyutlu öbekler kullanabilir, ancak bağlam kaybını önlemek için belge başlığını belgenin ortasındaki öbeklere de ekleyebilirsiniz.
İçerik çakışması ile ilgili dikkat edilmesi gerekenler
Verileri öbeklediğinizde, öbekler arasında az miktarda metnin çakışması bağlamın korunmasına yardımcı olabilir. Yaklaşık %10 örtüşme ile başlamanızı öneririz. Örneğin, 256 belirteç içeren sabit bir öbek boyutu göz önüne alındığında, 25 belirtecin çakışmasıyla teste başlarsınız. Gerçek örtüşme miktarı, veri türüne ve belirli kullanım örneğine bağlı olarak değişir, ancak %10-15'in birçok senaryo için çalıştığını bulduk.
Verileri öbekleme faktörleri
Verileri öbekleme söz konusu olduğunda şu faktörleri düşünün:
Belgelerinizin şekli ve yoğunluğu. Sağlam metin veya pasajlara ihtiyacınız varsa, cümle yapısını koruyan daha büyük öbekler ve değişken öbekler daha iyi sonuçlar verebilir.
Kullanıcı sorguları: Daha büyük öbekler ve çakışan stratejiler, belirli bilgileri hedefleyen sorgular için bağlam ve anlam zenginliğini korumaya yardımcı olur.
Büyük Dil Modelleri 'nin (LLM) öbek boyutu için performans yönergeleri vardır. kullandığınız tüm modeller için en uygun öbek boyutunu ayarlamanız gerekir. Örneğin, özetleme ve ekleme için modeller kullanıyorsanız, her ikisi için de uygun olan en uygun öbek boyutunu seçin.
Öbekleme iş akışına nasıl uyum sağlar?
Büyük belgeleriniz varsa, büyük metinleri bölen dizin oluşturma ve sorgu iş akışlarına bir öbekleme adımı eklemeniz gerekir. Tümleşik vektörleştirme (önizleme) kullanılırken, metin bölme becerisini kullanan varsayılan bir öbekleme stratejisi uygulanır. Özel bir beceri kullanarak özel bir öbekleme stratejisi de uygulayabilirsiniz. Öbekleme sağlayan bazı kitaplıklar şunlardır:
Çoğu kitaplık, sabit boyut, değişken boyut veya bir birleşim için yaygın öbekleme teknikleri sağlar. Bağlam koruması için her öbekteki az miktarda içeriği çoğaltan bir çakışma da belirtebilirsiniz.
Öbekleme örnekleri
Aşağıdaki örneklerde öbekleme stratejilerinin GECE NASA'nın Dünya'sına nasıl uygulandığı gösterilmektedir e-kitap PDF dosyası:
Metin Bölme beceri örneği
Metin Bölme özelliğiyle tümleşik veri öbekleme genel önizleme aşamasındadır. Bu senaryo için önizleme REST API'sini veya Azure SDK beta paketini kullanın.
Bu bölümde, beceri temelli bir yaklaşım ve Metin Bölme beceri parametreleri kullanılarak yerleşik veri öbekleme açıklanmaktadır.
Bu örnek için örnek bir not defteri azure-search-vector-samples deposunda bulunabilir.
İçeriği daha küçük parçalara ayırmak için ayarlayın textSplitMode :
pages(varsayılan). Öbekler birden çok cümleden oluşur.sentences. Öbekler tek cümleden oluşur. "Cümle" oluşturan dil bağımlıdır. İngilizcede, veya!gibi.standart cümle bitiş noktalama işaretleri kullanılır. Dil parametresi tarafındandefaultLanguageCodedenetlendi.
pages parametresi ek parametreler ekler:
maximumPageLengthher öbekteki en fazla 1 karakter sayısını tanımlar. Metin bölücü tümceleri bölmekten kaçındığından, gerçek karakter sayısı içeriğe bağlıdır.pageOverlapLength, bir sonraki sayfanın başında önceki sayfanın sonundan kaç karakterin dahil olduğunu tanımlar. Ayarlanırsa, bu en fazla sayfa uzunluğunun yarısından az olmalıdır.maximumPagesToTakebir belgeden kaç sayfa / öbek alınacak olduğunu tanımlar. Varsayılan değer 0'dır ve bu da belgedeki tüm sayfaları veya öbekleri almak anlamına gelir.
1 Karakterler belirtecin tanımına hizalanır. LLM tarafından ölçülen belirteç sayısı, Metin Bölme becerisi tarafından ölçülen karakter boyutundan farklı olabilir.
Aşağıdaki tabloda, parametre seçiminin Gece e-kitabındaki Dünya'dan toplam öbek sayısını nasıl etkilediği gösterilmektedir:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Toplam Öbek Sayısı |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
Kategori 2000 | 500 | 113 |
pages |
Kategori 5000 | 0 | 34 |
pages |
Kategori 5000 | 500 | 38 |
sentences |
Yok | Yok | 13361 |
Toplam karakter sayısının yakın maximumPageLengtholduğu öbeklerin çoğunluğunda bir textSplitModepages sonuç kullanılır. Öbek karakter sayısı, tümce sınırlarının öbek içinde yer aldığı farklara bağlı olarak değişir. Öbek belirteci uzunluğu, öbek içeriğindeki farklılıklara bağlı olarak değişir.
Aşağıdaki histogramlar, gece e-kitabındaki bir , 2000 ve pageOverlapLength Dünya'da 500'ün bir textSplitModepagesdeğeri kullanılırken öbek karakter uzunluğunun gpt-35-turbo için öbek belirteci uzunluğuyla karşılaştırmasını göstermektedir:maximumPageLength
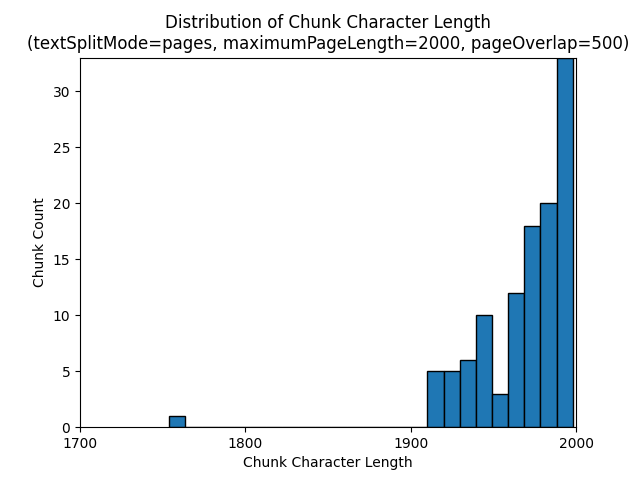
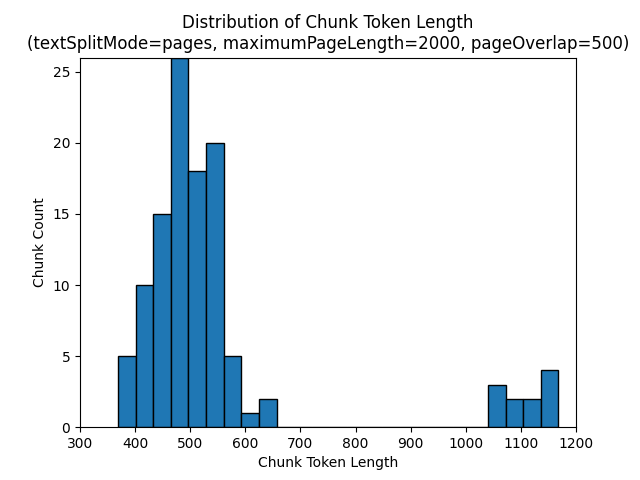
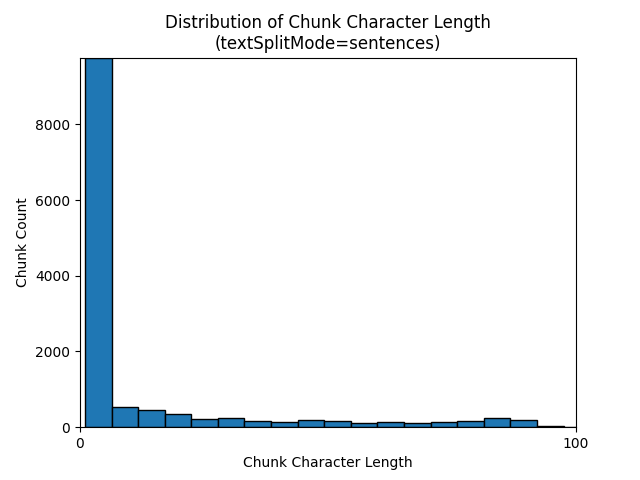
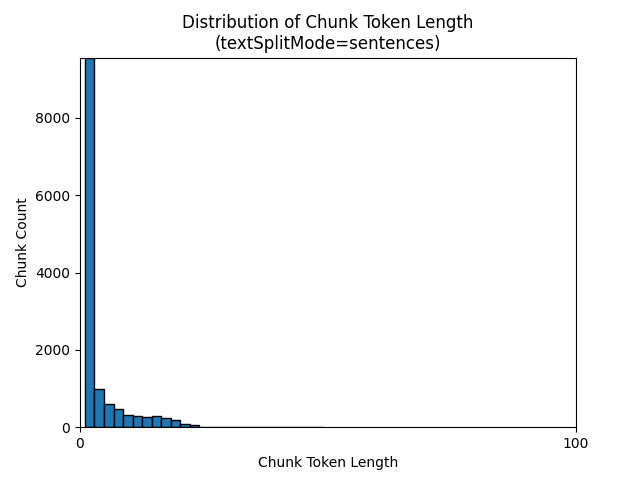
Bir textSplitMode öğesinin sentences kullanılması, tek tek cümlelerden oluşan çok sayıda öbekle sonuç verir. Bu öbekler tarafından pagesüretilenlerden önemli ölçüde daha küçüktür ve öbeklerin belirteç sayısı karakter sayılarıyla daha yakından eşleşir.
Aşağıdaki histogramlar, Gece e-kitabı'nda Dünya üzerinde kullanırken textSplitMode öbek karakter uzunluğunun dağılımının sentences gpt-35-turbo için öbek belirteci uzunluğuyla karşılaştırmasını göstermektedir:
Parametrelerin en uygun seçimi, öbeklerin nasıl kullanılacağına bağlıdır. Çoğu uygulama için aşağıdaki varsayılan parametrelerle başlamanızı öneririz:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
Kategori 2000 | 500 |
LangChain veri öbekleme örneği
LangChain, belge yükleyicileri ve metin bölücüleri sağlar. Bu örnekte PDF yükleme, belirteç sayılarını alma ve metin bölücü ayarlama işlemleri gösterilmektedir. Belirteç sayılarını almak, öbek boyutlandırma konusunda bilinçli bir karar vermenizi sağlar.
Bu örnek için örnek bir not defteri azure-search-vector-samples deposunda bulunabilir.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Çıktı, PDF'de 200 belgeyi veya sayfayı gösterir.
Bu sayfaların tahmini belirteç sayısını almak için TikToken kullanın.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Çıktı, hiçbir sayfanın sıfır belirteci olmadığını, sayfa başına ortalama belirteç uzunluğunun 189 belirteç olduğunu ve herhangi bir sayfanın en fazla belirteç sayısının 1.583 olduğunu gösterir.
Ortalama ve maksimum belirteç boyutunu bilmek, öbek boyutunu ayarlama hakkında içgörü sağlar. 500 karakter çakışması olan 2000 karakterlik standart öneriyi kullanabilseniz de, bu durumda örnek belgenin belirteç sayıları göz önüne alındığında daha düşük bir sayıya inmek mantıklıdır. Aslında, çok büyük bir çakışma değeri ayarlamak hiç çakışma görünmemesine neden olabilir.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Ardışık iki öbek için çıkış, ikinci öbekle örtüşen ilk öbekten gelen metni gösterir. Çıktı, okunabilirlik için basit bir şekilde düzenlenmiştir.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Özel beceri
Sabit boyutlu bir öbekleme ve ekleme oluşturma örneği, Azure OpenAI ekleme modellerini kullanarak hem öbek hem de vektör ekleme oluşturma işlemini gösterir. Bu örnek, öbekleme adımını sarmak için Power Skills deposundaki bir Azure AI Search özel becerisini kullanır.
Ayrıca bkz.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin