Sıralı kümelenmiş columnstore dizini ile performans ayarlama
Şunlar için geçerlidir: Azure Synapse Analytics ayrılmış SQL havuzları, SQL Server 2022 (16.x) ve üzeri
Kullanıcılar ayrılmış SQL havuzundaki bir columnstore tablosunu sorguladığında, iyileştirici her segmentte depolanan en düşük ve en yüksek değerleri denetler. Sorgu koşulunun sınırlarının dışında olan kesimler diskten belleğe okunamaz. Okunacak kesim sayısı ve toplam boyutları küçükse sorgu daha hızlı tamamlanabilir.
Sıralı ve sıralı olmayan kümelenmiş columnstore dizini karşılaştırması
Varsayılan olarak, dizin seçeneği olmadan oluşturulan her tablo için bir iç bileşen (dizin oluşturucusu) üzerinde sıralı olmayan bir kümelenmiş columnstore dizini (CCI) oluşturur. Her sütundaki veriler ayrı bir CCI satır grubu kesimine sıkıştırılır. Her kesimin değer aralığında meta veriler vardır, bu nedenle sorgu koşulunun sınırlarının dışında olan kesimler sorgu yürütme sırasında diskten okunamaz. CCI, en yüksek veri sıkıştırma düzeyini sunar ve sorguların daha hızlı çalışabilmesi için okunacak kesimlerin boyutunu azaltır. Ancak, dizin oluşturucu verileri segmentlere sıkıştırmadan önce sıralamadığından, çakışan değer aralıklarına sahip segmentler oluşabilir ve bu da sorguların diskten daha fazla kesim okumasına ve tamamlanmasının daha uzun sürmesine neden olabilir.
Verimli kesim ortadan kaldırmayı etkinleştirerek sıralı kümelenmiş columnstore dizinleri, sorgu koşuluyla eşleşmeyen büyük miktarlardaki sıralı verileri atlayarak çok daha hızlı performans sağlar. Sıralı bir CCI oluştururken, ayrılmış SQL havuzu altyapısı dizin oluşturucusu bunları dizin segmentlerine sıkıştırmadan önce bellekteki mevcut verileri sıralama anahtarlarına göre sıralar. Sıralanmış verilerle, segment çakışması azaltılarak sorguların daha verimli bir kesim ortadan kaldırılmasına ve diskten okunacak kesimlerin sayısı daha az olduğundan daha hızlı performans elde edilmesine olanak sağlanır. Tüm veriler aynı anda bellekte sıralanabilirse, segment çakışması önlenebilir. Veri ambarlarındaki büyük tablolar nedeniyle bu senaryo sık gerçekleşmez.
Bir sütunun segment aralıklarını denetlemek için tablonuzun adı ve sütun adı ile aşağıdaki komutu çalıştırın:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Not
Sıralı bir CCI tablosunda, aynı DML toplu işleminin veya veri yükleme işlemlerinin sonucunda elde edilen yeni veriler bu toplu işte sıralanır; tablodaki tüm verilerde genel sıralama yoktur. Kullanıcılar tablodaki tüm verileri sıralamak için sıralı CCI'yi YENIDEN DERLEYEBILIR. Ayrılmış SQL havuzunda columnstore dizini REBUILD çevrimdışı bir işlemdir. Bölümlenmiş bir tablo için REBUILD işlemi bir kerede bir bölüm olarak gerçekleştirilir. Yeniden derlenen bölümdeki veriler "çevrimdışıdır" ve söz konusu bölüm için REBUILD tamamlanana kadar kullanılamaz.
Sorgu performansı
Sıralı bir CCI'den elde edilen sorgunun performans kazancı sorgu desenlerine, verilerin boyutuna, verilerin ne kadar iyi sıralandığına, segmentlerin fiziksel yapısına ve sorgu yürütme için seçilen DWU ve kaynak sınıfına bağlıdır. Kullanıcılar, sıralı bir CCI tablosu tasarlarken sıralama sütunlarını seçmeden önce tüm bu faktörleri gözden geçirmelidir.
Tüm bu desenlere sahip sorgular genellikle sıralı CCI ile daha hızlı çalışır.
- Sorguların eşitlik, eşitsizlik veya aralık önkoşulları vardır
- Koşul sütunları ve sıralı CCI sütunları aynıdır.
Bu örnekte T1 tablosunda Col_C, Col_B ve Col_A sıralanmış kümelenmiş columnstore dizini vardır.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Tüm sıralı CCI sütunlarına başvuran sorgu 1 ve sorgu 2'nin performansı, diğer sorgulardan daha fazla sıralı CCI'den yararlanabilir.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Veri yükleme performansı
Sıralı bir CCI tablosuna veri yükleme performansı bölümlenmiş tabloya benzer. Verileri sıralı bir CCI tablosuna yüklemek, veri sıralama işlemi nedeniyle sıralı olmayan bir CCI tablosundan daha uzun sürebilir, ancak sorgular daha sonra sıralı CCI ile daha hızlı çalışabilir.
Verileri farklı şemalara sahip tablolara yüklemenin örnek performans karşılaştırması aşağıda verilmiştir.
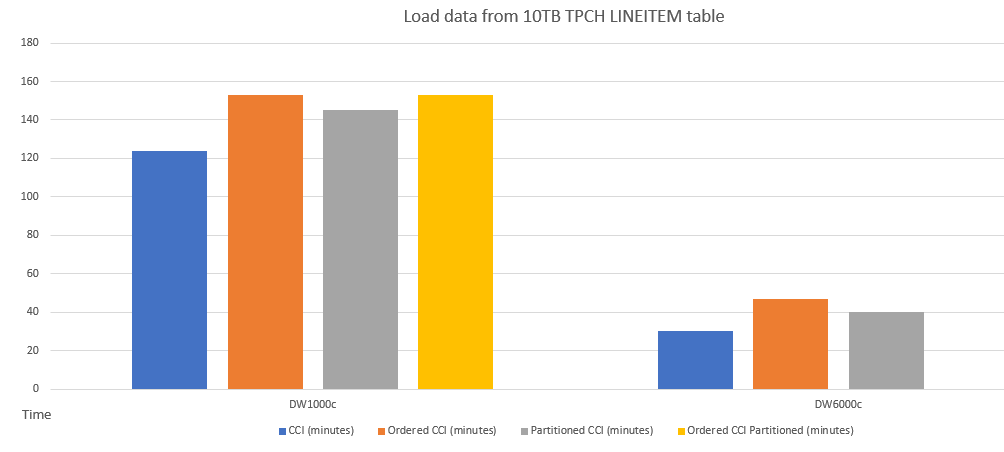
Aşağıda CCI ile sıralı CCI arasında bir sorgu performansı karşılaştırması örneği verilmiştir.
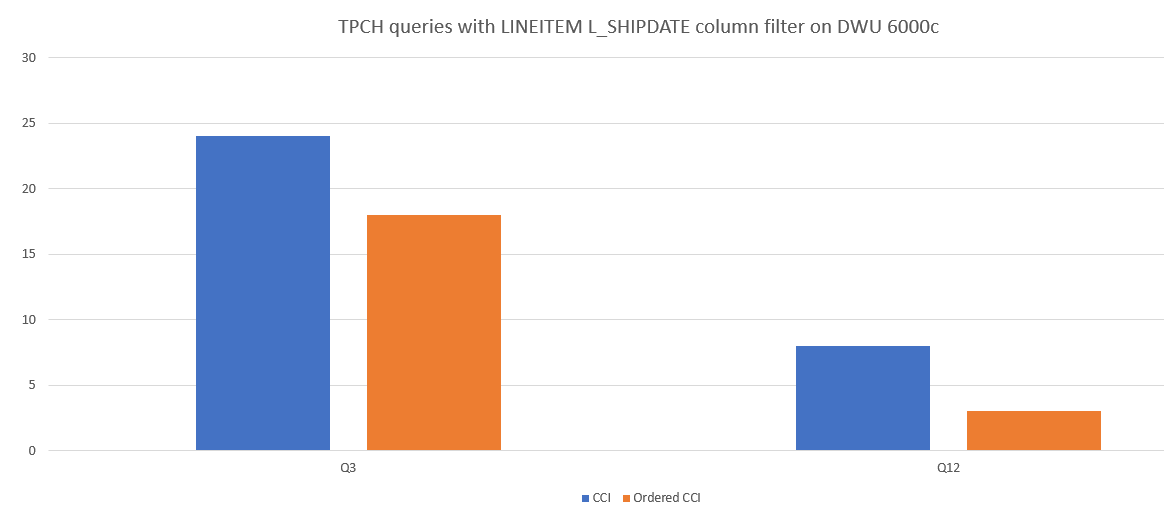
Segment çakışmalarını azaltma
Çakışan segmentlerin sayısı sıralı CCI oluşturma sırasında sıralanacak verilerin boyutuna, kullanılabilir belleğe ve maksimum paralellik derecesi (MAXDOP) ayarına bağlıdır. Aşağıdaki stratejiler sıralı CCI oluşturulurken segment çakışmasını azaltır.
Dizin oluşturucu verileri segmentlere sıkıştırmadan önce veri sıralama için daha fazla bellek sağlamak üzere daha yüksek bir DWU üzerinde kaynak sınıfını kullanın
xlargerc. Dizin kesimine girdikten sonra, verilerin fiziksel konumu değiştirilemez. Bir segment içinde veya segmentler arasında veri sıralama yoktur.ile
OPTION (MAXDOP = 1)sıralı CCI oluşturun. Sıralı CCI oluşturma için kullanılan her iş parçacığı bir veri alt kümesi üzerinde çalışır ve yerel olarak sıralar. Farklı iş parçacıklarına göre sıralanmış veriler arasında genel sıralama yoktur. Paralel iş parçacıklarının kullanılması sıralı bir CCI oluşturma süresini kısaltabilir, ancak tek bir iş parçacığı kullanmaktan daha fazla çakışan segmentler oluşturur. Tek bir iş parçacıklı işlem kullanmak en yüksek sıkıştırma kalitesini sağlar. Örnek:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Not
Şu anda, Azure Synapse Analytics'teki ayrılmış SQL havuzlarında MAXDOP seçeneği yalnızca komutu kullanılarak CREATE TABLE AS SELECT sıralı bir CCI tablosu oluşturmada desteklenmektedir. veya CREATE TABLE komutları aracılığıyla CREATE INDEX sıralı bir CCI oluşturmak MAXDOP seçeneğini desteklemez. Bu sınırlama, veya CREATE TABLE komutlarıyla MAXDOP belirtebileceğiniz SQL Server 2022 ve sonraki sürümler için CREATE INDEX geçerli değildir.
- Verileri tablolara yüklemeden önce sıralama anahtarlarına göre önceden sıralayın.
Yukarıdaki önerilere göre çakışan sıfır segment içeren sıralı bir CCI tablo dağılımı örneği aşağıda verilmiştir. Sıralı CCI tablosu, MAXDOP 1 ve xlargerckullanılarak 20 GB yığın tablosundan CTAS aracılığıyla bir DWU1000c veritabanında oluşturulur. CCI, yineleme içermeyen bir BIGINT sütununda sıralanır.
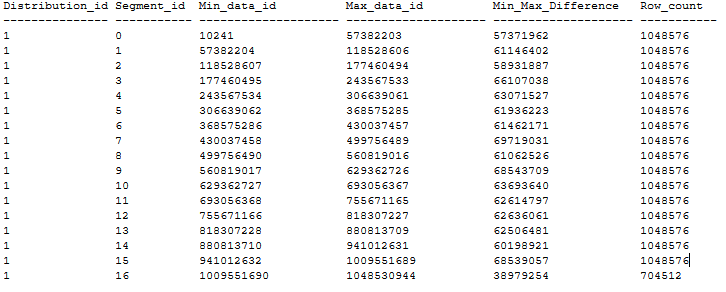
Büyük tablolarda sıralı CCI oluşturma
Sıralı CCI oluşturmak çevrimdışı bir işlemdir. Bölüm içermeyen tablolar için, sıralı CCI oluşturma işlemi tamamlanana kadar verilere kullanıcılar erişemez. Bölümlenmiş tablolar için, altyapı bölüme göre sıralı CCI bölümünü oluşturduğundan, kullanıcılar sıralı CCI oluşturma işleminin devam etmediği bölümlerdeki verilere erişmeye devam edebilir. Büyük tablolarda sıralı CCI oluşturma sırasında kapalı kalma süresini en aza indirmek için bu seçeneği kullanabilirsiniz:
- Hedef büyük tabloda (olarak adlandırılır)
Table_Abölümler oluşturun. - ile aynı tabloya ve bölüm şemasına
Table_Asahip boş bir sıralı CCI tablosu (olarak adlandırılırTable_B) oluşturun. - Bir bölümü ile
Table_Aarasında geçiş yapınTable_B. - üzerinde anahtarlanan bölümü
Table_Byeniden derlemek için komutunu çalıştırınALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>. - içindeki her bölüm
Table_Aiçin 3. ve 4. adımı yineleyin. - Tüm bölümler olarak değiştirildikten
Table_ATable_Bve yeniden oluşturulduktan sonra bırakınTable_Ave olarak yeniden adlandırınTable_BTable_A.
İpucu
Sıralı CCI içeren ayrılmış bir SQL havuzu tablosu için ALTER INDEX REBUILD kullanarak tempdbverileri yeniden sıralar. Yeniden oluşturma işlemleri sırasında izleme tempdb . Daha fazla tempdb alana ihtiyacınız varsa havuzun ölçeğini büyütün. Dizin yeniden oluşturma işlemi tamamlandıktan sonra ölçeği yeniden azaltma.
Sıralı CCI içeren ayrılmış bir SQL havuzu tablosu için ALTER INDEX REORGANIZE verileri yeniden sıralamaz. Verilere başvurmak için ALTER INDEX REBUILD komutunu kullanın.
Sıralı CCI bakımı hakkında daha fazla bilgi için bkz. Kümelenmiş columnstore dizinlerini iyileştirme.
SQL Server 2022 özelliklerindeki özellik farklılıkları
SQL Server 2022 (16.x), ayrılmış Azure Synapse SQL havuzlarındaki özelliğe benzer sıralı kümelenmiş columnstore dizinlerini kullanıma sunar.
- Şu anda yalnızca SQL Server 2022 (16.x) ve sonraki sürümleri dize, ikili ve guid veri türleri için kümelenmiş columnstore gelişmiş segment eleme özelliklerini ve ikiden büyük bir ölçek için datetimeoffset veri türünü destekler. Daha önce, bu segment eleme sayısal, tarih ve saat veri türleri ve ikiden küçük veya buna eşit ölçekle datetimeoffset veri türü için geçerlidir.
- Şu anda yalnızca SQL Server 2022 (16.x) ve sonraki sürümleri, koşul ön eki
LIKEiçin kümelenmiş columnstore satır grubu ortadan kaldırmayı destekler, örneğincolumn LIKE 'string%'. Segment eleme, gibicolumn LIKE '%string'LIKE ön eksiz kullanımı için desteklenmez.
Daha fazla bilgi için bkz. Columnstore Dizinlerindeki Yenilikler.
Örnekler
A. Sıralı sütunları ve sıralı sırayı denetlemek için:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Sütun sırasını değiştirmek için, sıra listesinden sütun ekleyin veya kaldırın ya da CCI'den sıralı CCI'ye geçmek için:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);