Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Sorgu hızlandırma, uygulamaların ve analiz çerçevelerinin yalnızca belirli bir işlemi gerçekleştirmek için ihtiyaç duydukları verileri alarak veri işlemeyi önemli ölçüde iyileştirmesini sağlar. Bu, depolanan veriler hakkında kritik içgörüler elde etmek için gereken süreyi ve işlem gücünü azaltır.
Genel Bakış
Sorgu hızlandırma, uygulamaların diskten veri okunduğu sırada satırları ve sütunları filtrelemesini sağlayan filtreleme koşullarını ve sütun projeksiyonlarını kabul eder. Yalnızca bir koşulun koşullarını karşılayan veriler ağ üzerinden uygulamaya aktarılır. Bu, ağ gecikme süresini ve işlem maliyetini azaltır.
Sorgu hızlandırma isteğinde satır filtresi koşullarını ve sütun projeksiyonlarını belirtmek için SQL kullanabilirsiniz. İstek yalnızca bir dosyayı işler. Bu nedenle, SQL'in birleşimler ve toplamalara göre gruplandırma gibi gelişmiş ilişkisel özellikleri desteklenmez. Sorgu hızlandırma, her isteğe giriş olarak CSV ve JSON biçimli verileri destekler.
Sorgu hızlandırma özelliği Data Lake Storage (hiyerarşik ad alanının etkinleştirildiği depolama hesapları) ile sınırlı değildir. Sorgu hızlandırma, depolama hesaplarında hiyerarşik ad alanı etkinleştirilmemiş bloblarla uyumludur. Bu, depolama hesaplarında blob olarak depoladığınız verileri işlerken ağ gecikme süresi ve işlem maliyetlerinde aynı düşüşe ulaşabileceğiniz anlamına gelir.
İstemci uygulamasında sorgu hızlandırmanın nasıl kullanılacağına ilişkin bir örnek için bkz. Azure Data Lake Storage sorgu hızlandırmasını kullanarak verileri filtreleme.
Veri akışı
Aşağıdaki diyagramda tipik bir uygulamanın verileri işlemek için sorgu hızlandırmayı nasıl kullandığı gösterilmektedir.
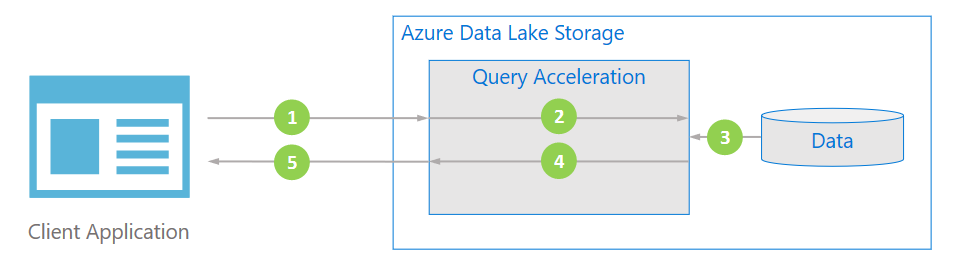
İstemci uygulaması, koşul ve sütun projeksiyonları belirterek dosya verilerini istemektedir.
Sorgu hızlandırma, belirtilen SQL sorgusunu ayrıştırıp verileri ayrıştırmak ve filtrelemek için çalışmayı dağıtır.
İşlemciler diskten verileri okur, uygun biçimi kullanarak verileri ayrıştırıp belirtilen koşul ve sütun projeksiyonlarını uygulayarak verileri filtreler.
Sorgu hızlandırma, istemci uygulamasına geri akış yapmak için yanıt parçalarını birleştirir.
İstemci uygulaması akış yanıtını alır ve ayrıştırıyor. Uygulamanın diğer verileri filtrelemesi gerekmez ve istenen hesaplamayı veya dönüştürmeyi doğrudan uygulayabilir.
Daha düşük maliyetle daha iyi performans
Sorgu hızlandırma, uygulamanız tarafından aktarılan ve işlenen veri miktarını azaltarak performansı iyileştirir.
Toplanan bir değeri hesaplamak için, uygulamalar genellikle bir dosyadaki tüm verileri alır ve verileri yerel olarak işleyip filtreler. Analiz iş yükleri için giriş/çıkış desenlerinin analizi, uygulamaların belirli bir hesaplamayı gerçekleştirmek için genellikle okudukları verilerin yalnızca 20% gerektirdiğini ortaya koyuyor. Bu istatistik, bölüm ayıklama gibi teknikler uygulandıktan sonra bile geçerlidir. Bu, bu verilerin 80% gereksiz şekilde ağ üzerinden aktarıldığı, ayrıştırıldığı ve uygulamalara göre filtrelendiği anlamına gelir. Gereksiz verileri kaldırmak için tasarlanan bu desen, önemli bir işlem maliyetine neden olur.
Azure, hem aktarım hızı hem de gecikme süresi açısından sektör lideri bir ağa sahip olsa da, bu ağ üzerinden veri aktarımının gerekmemesine rağmen uygulama performansı açısından yüksek maliyetlidir. Depolama isteği sırasında istenmeyen verileri filtreleyerek sorgu hızlandırma bu maliyeti ortadan kaldırır.
Buna ek olarak, gereksiz verileri ayrıştırmak ve filtrelemek için gereken CPU yükü, uygulamanızın işini yapabilmesi için daha fazla sayıda ve daha büyük VM'ler sağlamasını gerektirir. Uygulamalar, bu işlem yükünü sorgu hızlandırmaya aktararak önemli maliyet tasarrufu sağlayabilir.
Sorgu hızlandırmadan yararlanabilen uygulamalar
Sorgu hızlandırma, dağıtılmış analiz çerçeveleri ve veri işleme uygulamaları için tasarlanmıştır.
Apache Spark ve Apache Hive gibi dağıtılmış analiz çerçeveleri, çerçeve içinde bir depolama soyutlama katmanı içerir. Bu altyapılar, kullanıcı sorguları için en uygun sorgu planını belirlerken temel G/Ç hizmetinin özellikleri hakkında bilgi edinebilen sorgu iyileştiricileri de içerir. Bu çerçeveler sorgu hızlandırmayı tümleştirmeye başlıyor. Sonuç olarak, bu çerçevelerin kullanıcıları sorgularda herhangi bir değişiklik yapmak zorunda kalmadan geliştirilmiş sorgu gecikme süresi ve daha düşük toplam sahip olma maliyeti görür.
Sorgu hızlandırma, veri işleme uygulamaları için de tasarlanmıştır. Bu tür uygulamalar genellikle analiz içgörülerine doğrudan yol açmayacak büyük ölçekli veri dönüştürmeleri gerçekleştirir ve bu nedenle her zaman yerleşik dağıtılmış analiz çerçevelerini kullanmaz. Bu uygulamaların genellikle temel depolama hizmetiyle daha doğrudan bir ilişkisi vardır, böylece sorgu hızlandırma gibi özelliklerden doğrudan yararlanabilirler.
Bir uygulamanın sorgu hızlandırmayı nasıl tümleştirebileceğine ilişkin bir örnek için bkz. Azure Data Lake Storage sorgu hızlandırmasını kullanarak verileri filtreleme.
Fiyatlandırma
Azure Data Lake Storage hizmetindeki artan işlem yükü nedeniyle, sorgu hızlandırmayı kullanmak için fiyatlandırma modeli normal Azure Data Lake Storage işlem modelinden farklıdır. Sorgu hızlandırma, taranan veri miktarı için bir maliyetin yanı sıra arayana döndürülen veri miktarı için de ücretlendirilir. Daha fazla bilgi için bkz. Azure Data Lake Storage fiyatlandırması.
Faturalama modelinde yapılan değişikliğe rağmen Sorgu hızlandırmanın fiyatlandırma modeli, çok daha pahalı VM maliyetlerinin azalması göz önünde bulundurularak bir iş yükü için toplam sahip olma maliyetini düşürecek şekilde tasarlanmıştır.