Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, Tablo hizmeti çözümleriyle kullanıma uygun bazı desenler açıklanmaktadır. Ayrıca, diğer Tablo depolama tasarımı makalelerinde ele alınan bazı sorunları ve dengeleri pratikte nasıl giderebileceğinizi göreceksiniz. Aşağıdaki diyagramda farklı desenler arasındaki ilişkiler özetlemektedir:
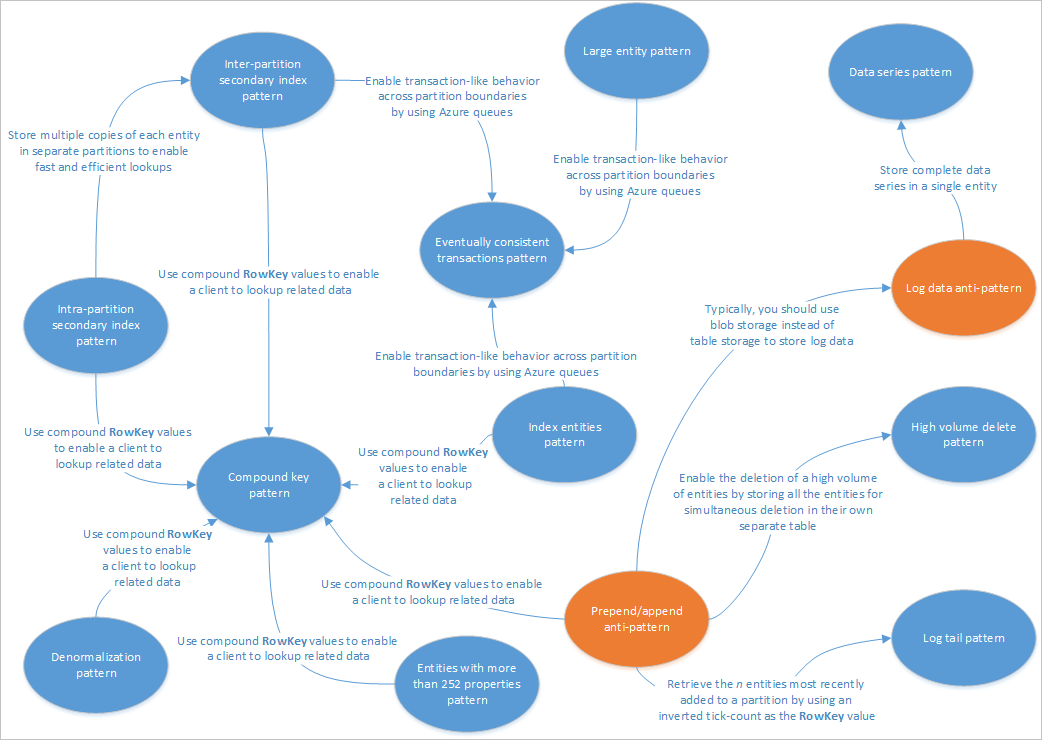
Yukarıdaki desen haritası, bu kılavuzda belgelenen desenler (mavi) ve desen karşıtlık (turuncu) arasındaki bazı ilişkileri vurgular. Dikkate alınması gereken başka birçok desen vardır. Örneğin, Tablo Hizmeti'nin temel senaryolarından biri, Komut Sorgu Sorumluluğu Ayrım (CQRS) deseninden Gerçekleştirilmiş Görünüm Desenini kullanmaktır.
Bölüm içi ikincil dizin deseni
Hızlı ve verimli aramalar ve farklı RowKey değerleri kullanarak alternatif sıralama düzenlerini etkinleştirmek için her varlığın birden çok kopyasını farklı RowKey değerleri (aynı bölümde) kullanarak depolayın. Kopyalar arasındaki Güncelleştirmeler, varlık grubu işlemleri (EGT) kullanılarak tutarlı tutulabilir.
Bağlam ve sorun
Tablo hizmeti, PartitionKey ve RowKey değerlerini kullanarak varlıkları otomatik olarak dizinler. Bu, istemci uygulamasının bu değerleri kullanarak bir varlığı verimli bir şekilde almasını sağlar. Örneğin, aşağıda gösterilen tablo yapısını kullanarak, istemci uygulaması bölüm adını ve çalışan kimliğini (PartitionKey ve RowKey değerleri) kullanarak tek bir çalışan varlığını almak için nokta sorgusu kullanabilir. İstemci, her departmandaki çalışan kimliğine göre sıralanmış varlıkları da alabilir.
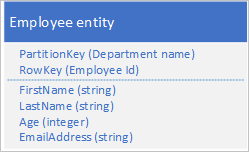
E-posta adresi gibi başka bir özelliğin değerine göre bir çalışan varlığı da bulabilmek istiyorsanız, eşleşme bulmak için daha az verimli bir bölüm taraması kullanmanız gerekir. Bunun nedeni, tablo hizmetinin ikincil dizinler sağlamamasıdır. Buna ek olarak, RowKey düzeninden farklı bir düzende sıralanmış bir çalışan listesi isteme seçeneği yoktur.
Çözüm
İkincil dizin eksikliğini geçici olarak çözmek için, her varlığın birden çok kopyasını farklı bir RowKey değeri kullanarak her kopyayla depolayabilirsiniz. Aşağıda gösterilen yapılara sahip bir varlığı depolarsanız, e-posta adresine veya çalışan kimliğine göre çalışan varlıklarını verimli bir şekilde alabilirsiniz. RowKey, "empid_" ve "email_" ön ek değerleri, bir dizi e-posta adresi veya çalışan kimlikleri kullanarak tek bir çalışanı veya bir çalışan aralığını sorgulamanıza olanak tanır.

Aşağıdaki iki filtre ölçütü (biri çalışan kimliğine ve diğeri e-posta adresine göre arama) nokta sorgularını belirtir:
- $filter=(PartitionKey eq 'Sales') ve (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') ve (RowKey eq 'email_jonesj@contoso.com')
Bir çalışan varlıkları aralığını sorgularsanız, Satır Anahtarı'nda uygun ön eke sahip varlıkları sorgulayarak, çalışan kimliği düzenine göre sıralanmış bir aralık veya e-posta adresi düzeninde sıralanmış bir aralık belirtebilirsiniz.
000100 ile 000199 arasında çalışan kimliğine sahip Satış departmanındaki tüm çalışanları bulmak için: $filter=(PartitionKey eq 'Sales') ve (RowKey ge 'empid_000100') ve (RowKey le 'empid_000199')
Satış departmanındaki tüm çalışanları 'a' harfiyle başlayan bir e-posta adresiyle bulmak için: $filter=(PartitionKey eq 'Sales') ve (RowKey ge 'email_a') ve (RowKey lt 'email_b')
Yukarıdaki örneklerde kullanılan filtre söz dizimi Tablo hizmeti REST API'sinden alınmıştı. Daha fazla bilgi için bkz . Sorgu Varlıkları.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
Tablo depolamanın kullanımı nispeten ucuzdur, bu nedenle yinelenen verileri depolamanın maliyet yükü önemli bir sorun oluşturmamalıdır. Ancak, tasarımınızın maliyetini her zaman beklenen depolama gereksinimlerinize göre değerlendirmeniz ve istemci uygulamanızın yürüteceği sorguları desteklemek için yalnızca yinelenen varlıklar eklemeniz gerekir.
İkincil dizin varlıkları özgün varlıklarla aynı bölümde depolandığından, tek bir bölüm için ölçeklenebilirlik hedeflerini aşmadığınızdan emin olmanız gerekir.
Varlığın iki kopyasını atomik olarak güncelleştirmek için EGT'leri kullanarak yinelenen varlıklarınızı birbiriyle tutarlı tutabilirsiniz. Bu, bir varlığın tüm kopyalarını aynı bölümde depolamanız gerektiği anlamına gelir. Daha fazla bilgi için Varlık Grubu İşlemlerini Kullanma bölümüne bakın.
RowKey için kullanılan değer her varlık için benzersiz olmalıdır. Bileşik anahtar değerlerini kullanmayı göz önünde bulundurun.
RowKey'deki sayısal değerleri doldurma (örneğin, çalışan kimliği 000223), üst ve alt sınırlara göre doğru sıralamayı ve filtrelemeyi etkinleştirir.
Varlığınızın tüm özelliklerini yinelemeniz gerekmez. Örneğin, RowKey'deki e-posta adresini kullanarak varlıkları araştıran sorgular çalışanın yaşına hiçbir zaman ihtiyaç duymazsa, bu varlıklar aşağıdaki yapıya sahip olabilir:
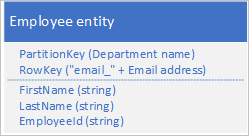
Yinelenen verileri depolamak ve ihtiyacınız olan tüm verileri tek bir sorguyla alabildiğinizden emin olmak, bir varlığı bulmak için bir sorgu, gerekli verileri aramak için başka bir sorgu kullanmaktan daha iyidir.
Bu düzenin kullanılacağı durumlar
İstemci uygulamanızın çeşitli anahtarları kullanarak varlıkları alması gerektiğinde, istemcinizin farklı sıralama düzenlerindeki varlıkları alması gerektiğinde ve her varlığı çeşitli benzersiz değerler kullanarak tanımlayabileceğiniz durumlarda bu düzeni kullanın. Ancak, farklı RowKey değerlerini kullanarak varlık aramaları gerçekleştirirken bölüm ölçeklenebilirlik sınırlarını aşmadığınızdan emin olmanız gerekir.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Bölümler arası ikincil dizin deseni
- Bileşik anahtar deseni
- Varlık Grubu İşlemleri
- Heterojen varlık türleriyle çalışma
Bölümler arası ikincil dizin deseni
Farklı RowKey değerleri kullanarak her varlığın birden çok kopyasını ayrı bölümlerde veya ayrı tablolarda depolayarak farklı RowKey değerleri kullanarak hızlı ve verimli aramalar ve alternatif sıralama düzenleri sağlayabilirsiniz.
Bağlam ve sorun
Tablo hizmeti, PartitionKey ve RowKey değerlerini kullanarak varlıkları otomatik olarak dizinler. Bu, istemci uygulamasının bu değerleri kullanarak bir varlığı verimli bir şekilde almasını sağlar. Örneğin, aşağıda gösterilen tablo yapısını kullanarak, istemci uygulaması bölüm adını ve çalışan kimliğini (PartitionKey ve RowKey değerleri) kullanarak tek bir çalışan varlığını almak için nokta sorgusu kullanabilir. İstemci, her departmandaki çalışan kimliğine göre sıralanmış varlıkları da alabilir.
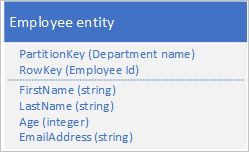
E-posta adresi gibi başka bir özelliğin değerine göre bir çalışan varlığı da bulabilmek istiyorsanız, eşleşme bulmak için daha az verimli bir bölüm taraması kullanmanız gerekir. Bunun nedeni, tablo hizmetinin ikincil dizinler sağlamamasıdır. Buna ek olarak, RowKey düzeninden farklı bir düzende sıralanmış bir çalışan listesi isteme seçeneği yoktur.
Bu varlıklara karşı yüksek hacimli işlemler olmasını istiyorsunuz ve Tablo hizmetinin istemcinizi azaltma riskini en aza indirmek istiyorsunuz.
Çözüm
İkincil dizin eksikliğini geçici olarak çözmek için, farklı PartitionKey ve RowKey değerlerini kullanarak her bir varlığın birden çok kopyasını her kopyayla depolayabilirsiniz. Aşağıda gösterilen yapılara sahip bir varlığı depolarsanız, e-posta adresine veya çalışan kimliğine göre çalışan varlıklarını verimli bir şekilde alabilirsiniz. PartitionKey, "empid_" ve "email_" ön ek değerleri, sorgu için hangi dizini kullanmak istediğinizi belirlemenizi sağlar.

Aşağıdaki iki filtre ölçütü (biri çalışan kimliğine ve diğeri e-posta adresine göre arama) nokta sorgularını belirtir:
- $filter=(PartitionKey eq 'empid_Sales') ve (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') ve (RowKey eq 'jonesj@contoso.com')
Bir çalışan varlıkları aralığını sorgularsanız, Satır Anahtarı'nda uygun ön eke sahip varlıkları sorgulayarak, çalışan kimliği düzenine göre sıralanmış bir aralık veya e-posta adresi düzeninde sıralanmış bir aralık belirtebilirsiniz.
- Satış departmanında çalışan kimliği 000100 ile çalışan kimliği arasında 000199 çalışan kimliğine sahip tüm çalışanları bulmak için şu adımları kullanın: $filter=(PartitionKey eq 'empid_Sales') ve (RowKey ge '000100') ve (RowKey le '000199')
- Satış departmanındaki tüm çalışanları e-posta adresi sırası 'a' ile başlayan bir e-posta adresiyle bulmak için şunu kullanın: $filter=(PartitionKey eq 'email_Sales') ve (RowKey ge 'a') ve (RowKey lt 'b')
Yukarıdaki örneklerde kullanılan filtre söz dizimi Tablo hizmeti REST API'sinden alınmıştı. Daha fazla bilgi için bkz . Sorgu Varlıkları.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
Birincil ve ikincil dizin varlıklarını korumak için Nihai tutarlı işlemler desenini kullanarak yinelenen varlıklarınızı sonunda birbiriyle tutarlı tutabilirsiniz.
Tablo depolamanın kullanımı nispeten ucuzdur, bu nedenle yinelenen verileri depolamanın maliyet yükü önemli bir sorun oluşturmamalıdır. Ancak, tasarımınızın maliyetini her zaman beklenen depolama gereksinimlerinize göre değerlendirmeniz ve istemci uygulamanızın yürüteceği sorguları desteklemek için yalnızca yinelenen varlıklar eklemeniz gerekir.
RowKey için kullanılan değer her varlık için benzersiz olmalıdır. Bileşik anahtar değerlerini kullanmayı göz önünde bulundurun.
RowKey'deki sayısal değerleri doldurma (örneğin, çalışan kimliği 000223), üst ve alt sınırlara göre doğru sıralamayı ve filtrelemeyi etkinleştirir.
Varlığınızın tüm özelliklerini yinelemeniz gerekmez. Örneğin, RowKey'deki e-posta adresini kullanarak varlıkları araştıran sorgular çalışanın yaşına hiçbir zaman ihtiyaç duymazsa, bu varlıklar aşağıdaki yapıya sahip olabilir:
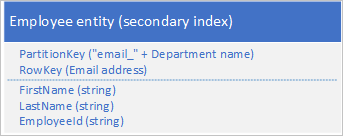
Yinelenen verileri depolamak ve ihtiyacınız olan tüm verileri tek bir sorguyla almak, ikincil dizini kullanan bir varlığı bulmak için bir sorgu ve birincil dizinde gerekli verileri aramak için başka bir sorgu kullanmaktan daha iyidir.
Bu düzenin kullanılacağı durumlar
İstemci uygulamanızın çeşitli anahtarları kullanarak varlıkları alması gerektiğinde, istemcinizin farklı sıralama düzenlerindeki varlıkları alması gerektiğinde ve her varlığı çeşitli benzersiz değerler kullanarak tanımlayabileceğiniz durumlarda bu düzeni kullanın. Farklı RowKey değerlerini kullanarak varlık aramaları gerçekleştirirken bölüm ölçeklenebilirlik sınırlarını aşmaktan kaçınmak istediğinizde bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Sonunda tutarlı işlemler düzeni
- Bölüm içi ikincil dizin deseni
- Bileşik anahtar deseni
- Varlık Grubu İşlemleri
- Heterojen varlık türleriyle çalışma
Sonunda tutarlı işlemler düzeni
Azure kuyruklarını kullanarak bölüm sınırları veya depolama sistemi sınırları arasında nihai tutarlı davranışı etkinleştirin.
Bağlam ve sorun
EGT'ler, aynı bölüm anahtarını paylaşan birden çok varlık arasında atomik işlemleri etkinleştirir. Performans ve ölçeklenebilirlik nedenleriyle, tutarlılık gereksinimleri olan varlıkları ayrı bölümlerde veya ayrı bir depolama sisteminde depolamaya karar verebilirsiniz: böyle bir senaryoda, tutarlılığı korumak için EGT'leri kullanamazsınız. Örneğin, aşağıdakiler arasında nihai tutarlılığı korumanız gerekebilir:
- Aynı tabloda, farklı tablolarda veya farklı depolama hesaplarında iki farklı bölümde depolanan varlıklar.
- Tablo hizmetinde depolanan bir varlık ve Blob hizmetinde depolanan bir blob.
- Tablo hizmetinde depolanan bir varlık ve dosya sisteminde bir dosya.
- Tablo hizmetinde depolanan ancak Azure Bilişsel Arama hizmeti kullanılarak dizine alınan bir varlık.
Çözüm
Azure kuyruklarını kullanarak iki veya daha fazla bölümde veya depolama sisteminde nihai tutarlılık sağlayan bir çözüm uygulayabilirsiniz. Bu yaklaşımı göstermek için eski çalışan varlıklarını arşivleyebilmeniz gerektiğini varsayalım. Eski çalışan varlıkları nadiren sorgulanır ve geçerli çalışanlarla ilgilenen etkinliklerden dışlanmalıdır. Bu gereksinimi uygulamak için etkin çalışanları Geçerli tabloda, eski çalışanları arşiv tablosunda depolarsınız. Bir çalışanı arşivleme, varlığı Geçerli tablodan silmenizi ve varlığı Arşiv tablosuna eklemenizi gerektirir, ancak bu iki işlemi gerçekleştirmek için EGT kullanamazsınız. Bir hatanın bir varlığın her iki tabloda veya ikisinde de görünmesine neden olma riskini önlemek için arşiv işleminin sonunda tutarlı olması gerekir. Aşağıdaki sıralı diyagramda bu işlemdeki adımlar özetlenmiştir. Aşağıdaki metinde özel durum yolları için daha fazla ayrıntı sağlanır.
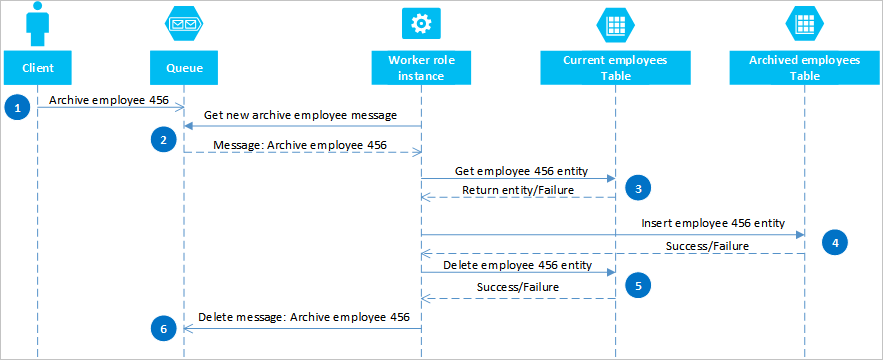
İstemci, azure kuyruğuna bir ileti yerleştirerek arşiv işlemini başlatır. Bu örnekte çalışan 456'yı arşivler. Çalışan rolü kuyruğu yeni iletiler için yoklar; bulduğunda, iletiyi okur ve kuyrukta gizli bir kopya bırakır. Çalışan rolü daha sonra Geçerli tablodan varlığın bir kopyasını getirir, Arşiv tablosuna bir kopya ekler ve özgün öğeyi Geçerli tablodan siler. Son olarak, önceki adımlarda hata yoksa çalışan rolü gizli iletiyi kuyruktan siler.
Bu örnekte, 4. adım çalışanı Arşiv tablosuna ekler. Çalışanı Blob hizmetindeki bir bloba veya dosya sistemindeki bir dosyaya ekleyebilir.
Hatalardan kurtarma
Çalışan rolünün arşiv işlemini yeniden başlatması gerektiğinde 4. ve 5. adımlardaki işlemlerin bir kez etkili olması önemlidir. Tablo hizmetini kullanıyorsanız, 4. adım için bir "ekleme veya değiştirme" işlemi kullanmanız gerekir; 5. adım için kullandığınız istemci kitaplığında "varsa sil" işlemini kullanmanız gerekir. Başka bir depolama sistemi kullanıyorsanız, uygun bir aynı anda etkili bir işlem kullanmanız gerekir.
Çalışan rolü 6. adımı hiç tamamlamazsa, zaman aşımından sonra ileti kuyrukta yeniden görünür ve çalışan rolünün yeniden işlemeye çalışması için hazır olur. Çalışan rolü, kuyrukta bir iletinin kaç kez okunup okunmadığını denetleyerek, gerekirse ayrı bir kuyruğa göndererek bu iletiyi araştırmak üzere "zehirli" bir ileti olarak işaretleyebilir. Kuyruk iletilerini okuma ve dequeue sayısını denetleme hakkında daha fazla bilgi için bkz . İletileri Alma.
Tablo ve Kuyruk hizmetlerinden gelen bazı hatalar geçici hatalardır ve istemci uygulamanız bunları işlemek için uygun yeniden deneme mantığını içermelidir.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Bu çözüm işlem yalıtımı sağlamaz. Örneğin, bir istemci çalışan rolü 4. ve 5. adımlar arasındayken Geçerli ve Arşiv tablolarını okuyabilir ve verilerin tutarsız bir görünümünü görebilir. Veriler sonunda tutarlı olacaktır.
- Nihai tutarlılığı sağlamak için 4. ve 5. adımların bir kez etkili olduğundan emin olmanız gerekir.
- Birden çok kuyruk ve çalışan rolü örneği kullanarak çözümü ölçeklendikleyebilirsiniz.
Bu düzenin kullanılacağı durumlar
Farklı bölümlerde veya tablolarda bulunan varlıklar arasında nihai tutarlılığı garanti etmek istediğinizde bu düzeni kullanın. Tablo hizmeti ve Blob hizmeti ile veritabanı veya dosya sistemi gibi Azure dışı Depolama veri kaynakları genelindeki işlemler için nihai tutarlılığı sağlamak için bu düzeni genişletebilirsiniz.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Varlık Grubu İşlemleri
- Birleştirme veya değiştirme
Dekont
İşlem yalıtımı çözümünüz için önemliyse, EGT'leri kullanabilmeniz için tablolarınızı yeniden tasarlamayı düşünmelisiniz.
Dizin varlıkları düzeni
Varlık listelerini döndüren verimli aramalar sağlamak için dizin varlıklarını koruyun.
Bağlam ve sorun
Tablo hizmeti, PartitionKey ve RowKey değerlerini kullanarak varlıkları otomatik olarak dizinler. Bu, istemci uygulamasının bir nokta sorgusu kullanarak bir varlığı verimli bir şekilde almasını sağlar. Örneğin, aşağıda gösterilen tablo yapısını kullanarak, bir istemci uygulaması departman adını ve çalışan kimliğini ( PartitionKey ve RowKey) kullanarak tek bir çalışan varlığını verimli bir şekilde alabilir.

Ayrıca, soyadı gibi benzersiz olmayan başka bir özelliğin değerine göre çalışan varlıklarının listesini almak istiyorsanız, eşleşmeleri bulmak için doğrudan aramak için dizin kullanmak yerine daha az verimli bir bölüm taraması kullanmanız gerekir. Bunun nedeni, tablo hizmetinin ikincil dizinler sağlamamasıdır.
Çözüm
Yukarıda gösterilen varlık yapısıyla soyadına göre aramayı etkinleştirmek için çalışan kimliklerinin listesini tutmanız gerekir. Jones gibi belirli bir soyadına sahip çalışan varlıklarını almak istiyorsanız, önce soyadı Jones olan çalışanlar için çalışan kimliklerinin listesini bulmanız ve sonra bu çalışan varlıklarını almanız gerekir. Çalışan kimliklerinin listelerini depolamak için üç ana seçenek vardır:
- Blob depolamayı kullanın.
- Çalışan varlıklarıyla aynı bölümde dizin varlıkları oluşturun.
- Ayrı bir bölümde veya tabloda dizin varlıkları oluşturun.
Seçenek 1: Blob depolamayı kullanma
İlk seçenek için, her benzersiz soyadı için bir blob oluşturursunuz ve her blobda bu soyadına sahip çalışanlar için PartitionKey (departman) ve RowKey (çalışan kimliği) değerlerinin listesini depolarsınız. Bir çalışanı eklediğinizde veya sildiğinizde, ilgili blobun içeriğinin sonunda çalışan varlıklarıyla tutarlı olduğundan emin olmanız gerekir.
Seçenek 2: Aynı bölümde dizin varlıkları oluşturma
İkinci seçenek için aşağıdaki verileri depolayan dizin varlıklarını kullanın:
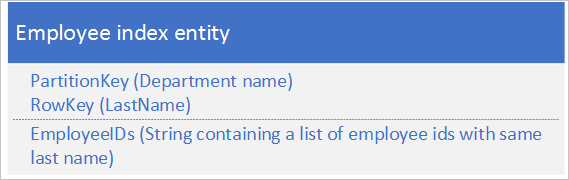
EmployeeIDs özelliği, RowKey'de depolanan soyadıyla çalışanların çalışan kimliklerinin listesini içerir.
Aşağıdaki adımlarda, ikinci seçeneği kullanıyorsanız yeni bir çalışan eklerken izlemeniz gereken işlem özetlenir. Bu örnekte, Satış departmanında kimlik 000152 ve soyadı Jones olan bir çalışan ekliyoruz:
- PartitionKey değeri "Sales" ve RowKey değeri "Jones" olan dizin varlığını alın. 2. adımda kullanmak üzere bu varlığın ETag'ini kaydedin.
- Yeni çalışan varlığını (PartitionKey değeri "Sales" ve RowKey değeri "000152") ekleyen ve yeni çalışan kimliğini EmployeeIDs alanındaki listeye ekleyerek dizin varlığını (PartitionKey değeri "Sales" ve RowKey değeri "Jones") güncelleştiren bir varlık grubu işlemi (toplu işlem) oluşturun. Varlık grubu işlemleri hakkında daha fazla bilgi için bkz. Varlık Grubu İşlemleri.
- Varlık grubu işlemi iyimser eşzamanlılık hatası nedeniyle başarısız olursa (başka biri dizin varlığını yeni değiştirmiştir), 1. adımda yeniden başlamanız gerekir.
İkinci seçeneği kullanıyorsanız, bir çalışanı silmek için benzer bir yaklaşım kullanabilirsiniz. Çalışanın soyadını değiştirmek biraz daha karmaşıktır çünkü üç varlığı güncelleştiren bir varlık grubu işlemi yürütmeniz gerekir: çalışan varlığı, eski soyadının dizin varlığı ve yeni soyadı için dizin varlığı. İyimser eşzamanlılık kullanarak güncelleştirmeleri gerçekleştirmek için kullanabileceğiniz ETag değerlerini almak için herhangi bir değişiklik yapmadan önce her varlığı almanız gerekir.
Aşağıdaki adımlarda, ikinci seçeneği kullanıyorsanız departmanda belirli bir soyadına sahip tüm çalışanları aramanız gerektiğinde izlemeniz gereken işlem özetlenir. Bu örnekte, Satış departmanında Soyadı Jones olan tüm çalışanları arıyoruz:
- PartitionKey değeri "Sales" ve RowKey değeri "Jones" olan dizin varlığını alın.
- Çalışan Kimlikleri alanındaki çalışan kimliklerinin listesini ayrıştırın.
- Bu çalışanların her biri hakkında ek bilgilere ihtiyacınız varsa (örneğin, e-posta adresleri), 2. adımda aldığınız çalışanlar listesinden PartitionKey değeri "Sales" ve RowKey değerlerini kullanarak çalışan varlıklarının her birini alın.
Seçenek 3: Ayrı bir bölümde veya tabloda dizin varlıkları oluşturma
Üçüncü seçenek için aşağıdaki verileri depolayan dizin varlıklarını kullanın:

EmployeeDetails özelliği, içinde depolanan soyadına sahip çalışanlar için çalışan kimliklerinin ve departman adı çiftlerinin RowKeylistesini içerir.
Üçüncü seçenekte, dizin varlıkları çalışan varlıklarından ayrı bir bölümde olduğundan tutarlılığı korumak için EGT'leri kullanamazsınız. Dizin varlıklarının sonunda çalışan varlıklarıyla tutarlı olduğundan emin olun.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Bu çözüm, eşleşen varlıkları almak için en az iki sorgu gerektirir: biri RowKey değerlerinin listesini almak için dizin varlıklarını sorgulamak ve ardından listedeki her varlığı almak için sorgular.
- Tek bir varlığın boyut üst sınırı 1 MB olduğunda çözümdeki 2. seçenek ve 3. seçenek, belirli bir soyadı için çalışan kimlikleri listesinin hiçbir zaman 1 MB'tan büyük olmadığını varsayar. Çalışan kimliklerinin listesinin boyutu büyük olasılıkla 1 MB'tan büyükse, 1. seçeneği kullanın ve dizin verilerini blob depolamada depolayın.
- 2. seçeneği (çalışanların eklenip silinmesini ve bir çalışanın soyadının değiştirilmesini işlemek için EGT'leri kullanarak) kullanıyorsanız, işlem hacminin belirli bir bölümdeki ölçeklenebilirlik sınırlarına yaklaşıp yaklaşmayacağını değerlendirmeniz gerekir. Bu durumda, güncelleştirme isteklerini işlemek için kuyrukları kullanan ve dizin varlıklarınızı çalışan varlıklarından ayrı bir bölümde depolamanıza olanak tanıyan nihai tutarlı bir çözüm (seçenek #1 veya seçenek #3) göz önünde bulundurmanız gerekir.
- Bu çözümdeki 2. seçenek, bir departmanda soyadına göre arama yapmak istediğinizi varsayar: Örneğin, Satış departmanında Soyadı Jones olan çalışanların listesini almak istiyorsunuz. Tüm kuruluş genelinde soyadı Jones olan tüm çalışanları aramak istiyorsanız 1. seçeneği veya 3. seçeneği kullanın.
- Nihai tutarlılık sağlayan kuyruk tabanlı bir çözüm uygulayabilirsiniz (daha fazla ayrıntı için Nihai tutarlı işlemler düzenine bakın).
Bu düzenin kullanılacağı durumlar
Jones soyadına sahip tüm çalışanlar gibi ortak bir özellik değerini paylaşan bir varlık kümesi aramak istediğinizde bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Bileşik anahtar deseni
- Sonunda tutarlı işlemler düzeni
- Varlık Grubu İşlemleri
- Heterojen varlık türleriyle çalışma
Normal dışılaştırma deseni
tek bir nokta sorgusuyla ihtiyacınız olan tüm verileri almanızı sağlamak için ilgili verileri tek bir varlıkta birleştirin.
Bağlam ve sorun
İlişkisel veritabanında, yinelenenleri kaldırmak için genellikle verileri normalleştirirsiniz ve bu da birden çok tablodan veri alan sorgulara neden olur. Verilerinizi Azure tablolarında normalleştirirseniz, ilgili verilerinizi almak için istemciden sunucuya birden çok gidiş dönüş yapmanız gerekir. Örneğin, aşağıda gösterilen tablo yapısıyla, bir departmanın ayrıntılarını almak için iki gidiş dönüş yapmanız gerekir: yönetici kimliğini içeren departman varlığını getirmek için bir tane ve bir çalışan varlığında yöneticinin ayrıntılarını getirmek için başka bir istek.

Çözüm
Verileri iki ayrı varlıkta depolamak yerine, verileri normalleştirin ve yöneticinin ayrıntılarının bir kopyasını departman varlığında tutun. Örneğin:
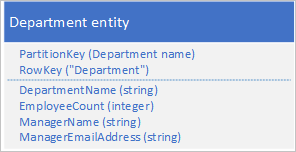
Bu özelliklerle depolanan departman varlıklarıyla artık nokta sorgusu kullanarak bir bölümle ilgili ihtiyacınız olan tüm ayrıntıları alabilirsiniz.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Bazı verilerin iki kez depolanmasıyla ilişkili bazı maliyet ek yükü vardır. Performans avantajı (depolama hizmetine yönelik daha az istekten kaynaklanan) genellikle depolama maliyetlerindeki marjinal artıştan daha fazladır (ve bu maliyet, bölümün ayrıntılarını getirmek için gereken işlem sayısındaki azalmayla kısmen dengelenir).
- Yöneticiler hakkındaki bilgileri depolayan iki varlığın tutarlılığını korumanız gerekir. Tek bir atomik işlemdeki birden çok varlığı güncelleştirmek için EGT'leri kullanarak tutarlılık sorununu çözebilirsiniz: bu durumda departman varlığı ve departman yöneticisinin çalışan varlığı aynı bölümde depolanır.
Bu düzenin kullanılacağı durumlar
İlgili bilgileri sık sık aramanız gerektiğinde bu düzeni kullanın. Bu düzen, istemcinizin gerektirdiği verileri almak için yapması gereken sorgu sayısını azaltır.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Bileşik anahtar deseni
- Varlık Grubu İşlemleri
- Heterojen varlık türleriyle çalışma
Bileşik anahtar deseni
İstemcinin tek noktalı sorguyla ilgili verileri aramasını sağlamak için bileşik RowKey değerlerini kullanın.
Bağlam ve sorun
İlişkisel veritabanında, tek bir sorguda istemciye ilgili veri parçalarını döndürmek için sorgularda birleştirmelerin kullanılması doğaldır. Örneğin, performans içeren ilgili varlıkların listesini aramak ve bu çalışanın verilerini gözden geçirmek için çalışan kimliğini kullanabilirsiniz.
Aşağıdaki yapıyı kullanarak tablo hizmetinde çalışan varlıklarını depoladığınız varsayılır:
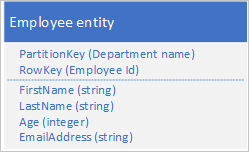
Ayrıca, çalışanın kuruluşunuzda çalıştığı her yıl için incelemeler ve performansla ilgili geçmiş verileri depolamanız ve bu bilgilere yıla göre erişebilmeniz gerekir. Seçeneklerden biri, aşağıdaki yapıya sahip varlıkları depolayan başka bir tablo oluşturmaktır:
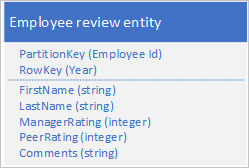
Bu yaklaşımla, verilerinizi tek bir istekle almanızı sağlamak için yeni varlıktaki bazı bilgileri (ad ve soyadı gibi) yinelemeye karar verebilirim. Ancak, iki varlığı atomik olarak güncelleştirmek için BIR EGT kullanamadığınız için güçlü tutarlılığı koruyamazsınız.
Çözüm
Aşağıdaki yapıya sahip varlıkları kullanarak özgün tablonuzda yeni bir varlık türü depolayın:
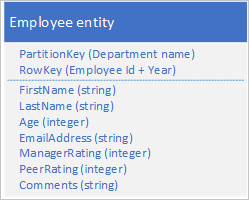
RowKey'in artık çalışanın performansını almanıza ve tek bir varlık için tek bir istekle verileri gözden geçirmenize olanak tanıyan, çalışan kimliğinden ve gözden geçirme verilerinin yılından oluşan bir bileşik anahtar olduğuna dikkat edin.
Aşağıdaki örnekte, belirli bir çalışanın tüm gözden geçirme verilerini (Satış departmanındaki çalışan 000123 gibi) nasıl alabildiğiniz özetlenmiştir:
$filter=(PartitionKey eq 'Sales') ve (RowKey ge 'empid_000123') ve (RowKey lt '000123_2012')&$select=RowKey,Manager Derecelendirmesi,Eş Derecelendirmesi,Açıklamalar
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- RowKey değerini ayrıştırmanızı kolaylaştıran uygun bir ayırıcı karakter kullanmalısınız: örneğin, 000123_2012.
- Bu varlığı aynı çalışanın ilgili verilerini içeren diğer varlıklarla aynı bölümde de depolursunuz. Bu, güçlü tutarlılığı korumak için EGT'leri kullanabileceğiniz anlamına gelir.
- Bu düzenin uygun olup olmadığını belirlemek için verileri ne sıklıkta sorgulayabileceğinizi göz önünde bulundurmalısınız. Örneğin, gözden geçirme verilerine seyrek erişecekseniz ve ana çalışan verilerine genellikle bunları ayrı varlıklar olarak tutmalısınız.
Bu düzenin kullanılacağı durumlar
Sık sorguladığınız bir veya daha fazla ilgili varlığı depolamanız gerektiğinde bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Varlık Grubu İşlemleri
- Heterojen varlık türleriyle çalışma
- Sonunda tutarlı işlemler düzeni
Günlük kuyruğu deseni
Ters tarih ve saat düzeninde sıralayan bir RowKey değeri kullanarak bölüme en son eklenen n varlığı alın.
Bağlam ve sorun
Yaygın bir gereksinim, en son oluşturulan varlıkları (örneğin, bir çalışan tarafından gönderilen en son 10 gider talebi) alabilir. Tablo sorguları, bir kümedeki ilk n varlığı döndürmek için $top sorgu işlemini destekler: kümedeki son n varlığı döndürmek için eşdeğer sorgu işlemi yoktur.
Çözüm
Kullanarak doğal olarak ters tarih/saat düzeninde sıralayan bir RowKey kullanarak varlıkları depolayın, böylece en son girdi her zaman tablodaki ilk girdi olur.
Örneğin, bir çalışan tarafından gönderilen en son 10 gider beyanını alabilmek için geçerli tarih/saatten türetilmiş bir ters değer değeri kullanabilirsiniz. Aşağıdaki C# kod örneği, bir RowKey için en son değerden en eskiye doğru sıralanan uygun bir "ters değer" değeri oluşturmanın bir yolunu gösterir:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Aşağıdaki kodu kullanarak tarih saat değerine geri dönebilirsiniz:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
Tablo sorgusu şöyle görünür:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Dize değerinin beklendiği gibi sıralandığından emin olmak için ters değer değerini baştaki sıfırlarla doldurmanız gerekir.
- Bölüm düzeyinde ölçeklenebilirlik hedeflerinin farkında olmanız gerekir. Sık erişim noktası bölümleri oluşturmamaya dikkat edin.
Bu düzenin kullanılacağı durumlar
Varlıklara ters tarih/saat sırasına göre erişmeniz gerektiğinde veya en son eklenen varlıklara erişmeniz gerektiğinde bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
Yüksek hacimli silme düzeni
Aynı anda silinmek üzere tüm varlıkları kendi ayrı tablolarında depolayarak yüksek hacimli varlıkların silinmesini etkinleştirin; tabloyu silerek varlıkları silebilirsiniz.
Bağlam ve sorun
Birçok uygulama, artık bir istemci uygulaması için kullanılabilir olması gerekmeyen veya uygulamanın başka bir depolama ortamına arşivlediği eski verileri siler. Bu tür verileri genellikle bir tarihe göre tanımlarsınız: Örneğin, 60 günden eski tüm oturum açma isteklerinin kayıtlarını silmeniz gerekir.
Olası tasarımlardan biri, RowKey'de oturum açma isteğinin tarih ve saatini kullanmaktır:
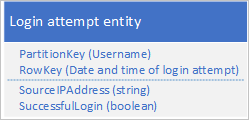
Uygulama ayrı bir bölüme her kullanıcı için oturum açma varlıkları ekleyip silebildiğinden bu yaklaşım bölüm etkin noktalarını önler. Ancak, çok fazla sayıda varlığınız varsa bu yaklaşım maliyetli ve zaman alabilir çünkü önce silinecek tüm varlıkları tanımlamak için bir tablo taraması gerçekleştirmeniz ve ardından her eski varlığı silmeniz gerekir. Birden çok silme isteğini EGT'ler halinde toplu işleyerek eski varlıkları silmek için gereken sunucuya gidiş dönüş sayısını azaltabilirsiniz.
Çözüm
Oturum açma girişimlerinin her günü için ayrı bir tablo kullanın. Varlıkları eklerken etkin noktaları önlemek için yukarıdaki varlık tasarımını kullanabilirsiniz ve eski varlıkları silmek artık her gün yüzlerce ve binlerce bireysel oturum açma varlığını bulup silmek yerine her gün bir tabloyu silme (tek bir depolama işlemi) sorunudur.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Tasarımınız, uygulamanızın belirli varlıkları arama, diğer verilerle bağlantı kurma veya toplama bilgileri oluşturma gibi verileri kullanmasının diğer yollarını destekliyor mu?
- Tasarımınız yeni varlıklar eklerken sık erişimli noktalardan kaçınıyor mu?
- Sildikten sonra aynı tablo adını yeniden kullanmak istiyorsanız gecikmeli bir durumla karşılaşabilirsiniz. Her zaman benzersiz tablo adları kullanmak daha iyidir.
- Tablo hizmeti erişim desenlerini öğrenir ve bölümleri düğümler arasında dağıtırken yeni bir tablo ilk kullandığınızda biraz azaltma bekleyebilirsiniz. Yeni tablolar oluşturmak için ne sıklıkta ihtiyacınız olduğunu göz önünde bulundurmalısınız.
Bu düzenin kullanılacağı durumlar
Aynı anda silmeniz gereken yüksek hacimli varlıklar varsa bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Varlık Grubu İşlemleri
- Varlıkları değiştirme
Veri serisi deseni
Yaptığınız istek sayısını en aza indirmek için tam veri serisini tek bir varlıkta depolayın.
Bağlam ve sorun
Yaygın bir senaryo, bir uygulamanın genellikle tümünü aynı anda alması gereken bir dizi veriyi depolamasıdır. Örneğin, uygulamanız her çalışanın saatte bir kaç anlık ileti gönderdiğini kaydedebilir ve ardından her kullanıcının önceki 24 saat içinde gönderdiği ileti sayısını çizmek için bu bilgileri kullanabilir. Tasarımlardan biri, her çalışan için 24 varlığı depolamak olabilir:
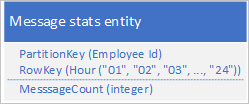
Bu tasarımla, uygulamanın ileti sayısı değerini güncelleştirmesi gerektiğinde varlığı her çalışan için güncelleştirilecek şekilde kolayca bulabilir ve güncelleştirebilirsiniz. Ancak, önceki 24 saat boyunca etkinliğin grafiğini çizmek üzere bilgileri almak için 24 varlık almanız gerekir.
Çözüm
Her saat için ileti sayısını depolamak için ayrı bir özellik ile aşağıdaki tasarımı kullanın:
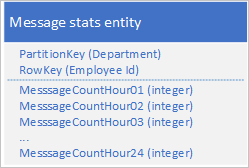
Bu tasarımla, bir çalışanın belirli bir saat için ileti sayısını güncelleştirmek için birleştirme işlemini kullanabilirsiniz. Artık tek bir varlık için istek kullanarak grafiği çizmek için ihtiyacınız olan tüm bilgileri alabilirsiniz.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Tam veri seriniz tek bir varlığa sığmıyorsa (bir varlığın en fazla 252 özelliği olabilir), blob gibi alternatif bir veri deposu kullanın.
- Bir varlığı aynı anda güncelleştiren birden çok istemciniz varsa, iyimser eşzamanlılık uygulamak için ETag'i kullanmanız gerekir. Çok sayıda istemciniz varsa, yüksek çekişmeyle karşılaşabilirsiniz.
Bu düzenin kullanılacağı durumlar
Tek bir varlıkla ilişkili bir veri serisini güncelleştirmeniz ve almanız gerektiğinde bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Büyük varlıklar düzeni
- Birleştirme veya değiştirme
- Nihai tutarlı işlemler düzeni (veri serisini bir blobda depoluyorsanız)
Geniş varlıklar düzeni
252'den fazla özelliğe sahip mantıksal varlıkları depolamak için birden çok fiziksel varlık kullanın.
Bağlam ve sorun
Tek bir varlığın en fazla 252 özelliği (zorunlu sistem özellikleri hariç) olabilir ve toplamda 1 MB'tan fazla veri depolayamaz. İlişkisel veritabanında, genellikle yeni bir tablo ekleyerek ve aralarında 1-1 ilişkisi zorlayarak satırın boyutuyla ilgili tüm sınırları yuvarlarsınız.
Çözüm
Tablo hizmetini kullanarak, 252'den fazla özelliğe sahip tek bir büyük iş nesnesini temsil eden birden çok varlık depolayabilirsiniz. Örneğin, her çalışan tarafından son 365 gün boyunca gönderilen anlık ileti sayısının sayısını depolamak istiyorsanız, farklı şemalara sahip iki varlık kullanan aşağıdaki tasarımı kullanabilirsiniz:
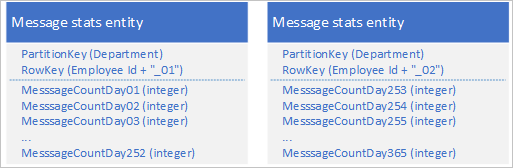
Her iki varlığın da birbiriyle eşitlenmesini sağlamak için güncelleştirilmesini gerektiren bir değişiklik yapmanız gerekiyorsa, EGT kullanabilirsiniz. Aksi takdirde, belirli bir günün ileti sayısını güncelleştirmek için tek bir birleştirme işlemi kullanabilirsiniz. Tek bir çalışanın tüm verilerini almak için her iki varlığı da almanız gerekir. Bunu hem PartitionKey hem de RowKey değeri kullanan iki verimli istekle yapabilirsiniz.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Tam bir mantıksal varlığın alınması en az iki depolama işlemi gerektirir: her fiziksel varlığı almak için bir tane.
Bu düzenin kullanılacağı durumlar
Boyut veya özellik sayısı Tablo hizmetindeki tek bir varlığın sınırlarını aşan varlıkları depolamanız gerektiğinde bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
- Varlık Grubu İşlemleri
- Birleştirme veya değiştirme
Büyük varlıklar düzeni
Büyük özellik değerlerini depolamak için blob depolamayı kullanın.
Bağlam ve sorun
Tek bir varlık toplam 1 MB'tan fazla veri depolayamaz. Özelliklerinizden biri veya birkaçı varlığınızın toplam boyutunun bu değeri aşmasına neden olan değerleri depolarsa, varlığın tamamını Tablo hizmetinde depolayamazsınız.
Çözüm
Bir veya daha fazla özellik büyük miktarda veri içerdiğinden varlığınızın boyutu 1 MB'ı aşarsa, verileri Blob hizmetinde depolayabilir ve ardından blobun adresini varlıktaki bir özellikte depolayabilirsiniz. Örneğin, bir çalışanın fotoğrafını blob depolama alanında depolayabilir ve fotoğrafın bağlantısını çalışan varlığınızın Photo özelliğinde depolayabilirsiniz:
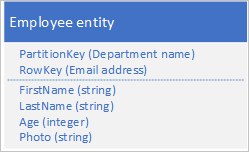
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Tablo hizmetindeki varlıkla Blob hizmetindeki veriler arasında nihai tutarlılığı korumak için varlıklarınızı korumak için Nihai tutarlılıktaki işlemler desenini kullanın.
- Tam bir varlığın alınması en az iki depolama işlemi gerektirir: biri varlığı almak için, diğeri de blob verilerini almak için.
Bu düzenin kullanılacağı durumlar
Boyutu Tablo hizmetindeki tek bir varlığın sınırlarını aşan varlıkları depolamanız gerektiğinde bu düzeni kullanın.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
Prepend/append anti-pattern
Eklemeleri birden çok bölüme yayarak yüksek hacimli eklemelere sahip olduğunuzda ölçeklenebilirliği artırın.
Bağlam ve sorun
Varlıkların depolanmış varlıklarınıza önceden eklenmesi veya eklenmesi genellikle uygulamanın bir bölüm dizisinin ilk veya son bölümüne yeni varlıklar eklemesine neden olur. Bu durumda, herhangi bir zamanda tüm eklemeler aynı bölümde gerçekleşir ve tablo hizmetinin birden çok düğümdeki eklemeleri yük dengelemesini engelleyen ve büyük olasılıkla uygulamanızın bölüm için ölçeklenebilirlik hedeflerine ulaşmasını engelleyen bir etkin nokta oluşturulur. Örneğin, çalışanlar tarafından ağ ve kaynak erişimini günlüğe kaydeden bir uygulamanız varsa, aşağıda gösterildiği gibi bir varlık yapısı, işlem hacmi tek bir bölüm için ölçeklenebilirlik hedeflerine ulaşırsa geçerli saatin bölümünün etkin nokta haline gelmesine neden olabilir:

Çözüm
Aşağıdaki alternatif varlık yapısı, uygulama olayları günlüğe kaydederken belirli bir bölümde etkin noktayı önler:
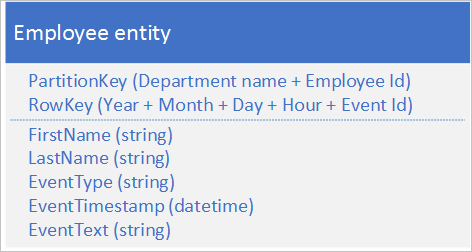
Bu örnekte hem PartitionKey hem de RowKey'in bileşik anahtarlar olduğunu fark edin. PartitionKey, günlüğü birden çok bölüme dağıtmak için hem departman hem de çalışan kimliğini kullanır.
Sorunlar ve dikkat edilmesi gerekenler
Bu düzenin nasıl uygulanacağına karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Eklemelerde sık erişimli bölümler oluşturmayı engelleyen alternatif anahtar yapısı, istemci uygulamanızın yaptığı sorguları verimli bir şekilde destekliyor mu?
- Tahmini işlem hacminiz, tek bir bölüm için ölçeklenebilirlik hedeflerine ulaşıp depolama hizmeti tarafından kısıtlanma olasılığınız olduğu anlamına mı geliyor?
Bu düzenin kullanılacağı durumlar
Sık erişimli bir bölüme eriştiğinizde işlem hacminizin depolama hizmeti tarafından azaltmaya neden olma olasılığı yüksek olduğunda, önceden eklenen/eklenen anti-desenden kaçının.
İlgili düzenler ve kılavuzlar
Bu düzeni uygularken aşağıdaki düzenler ve yönergeler de yararlı olabilir:
Günlük verileri desenden koruma
Günlük verilerini depolamak için genellikle Tablo hizmeti yerine Blob hizmetini kullanmanız gerekir.
Bağlam ve sorun
Günlük verilerinin yaygın kullanım örneklerinden biri, belirli bir tarih/saat aralığına ait günlük girdilerinin seçimini almaktır: Örneğin, uygulamanızın belirli bir tarihte 15:04 ile 15:06 arasında günlüğe kaydetmiş olduğu tüm hata ve kritik iletileri bulmak istersiniz. Günlük varlıklarını kaydettiğiniz bölümü belirlemek için günlük iletisinin tarih ve saatini kullanmak istemezsiniz: bu da sık erişimli bölümle sonuçlanır, çünkü herhangi bir zamanda tüm günlük varlıkları aynı PartitionKey değerini paylaşır (bkz . Prepend/append anti-pattern). Örneğin, bir günlük iletisi için aşağıdaki varlık şeması, uygulama geçerli tarih ve saat için tüm günlük iletilerini bölüme yazdığından sık erişimli bölümle sonuçlanır:
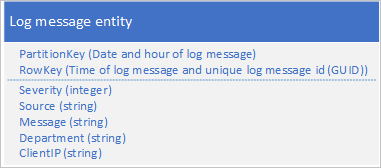
Bu örnekte RowKey, günlük iletilerinin tarih/saat sırasına göre sıralandığından emin olmak için günlük iletisinin tarih ve saatini ve birden çok günlük iletisinin aynı tarih ve saati paylaşması durumunda bir ileti kimliği içerir.
Bir diğer yaklaşım da uygulamanın iletileri bir dizi bölüme yazmasını sağlayan bir PartitionKey kullanmaktır. Örneğin, günlük iletisinin kaynağı iletileri birçok bölüme dağıtmak için bir yol sağlıyorsa aşağıdaki varlık şemasını kullanabilirsiniz:
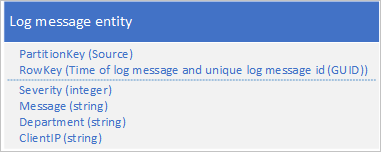
Ancak bu şemadaki sorun, belirli bir zaman aralığına ilişkin tüm günlük iletilerini almak için tablodaki her bölümde arama yapmanız gerektiğidir.
Çözüm
Önceki bölümde, günlük girdilerini depolamak için Tablo hizmetini kullanmaya çalışma sorunu vurgulanmış ve iki, yetersiz tasarım önerilmişti. Bir çözüm, günlük iletileri yazarken düşük performans riski olan etkin bir bölüme yol açtı; diğer çözüm, belirli bir zaman aralığı için günlük iletilerini almak üzere tablodaki her bölümü tarama gereksinimi nedeniyle sorgu performansının düşmesine neden oldu. Blob depolama, bu tür senaryolar için daha iyi bir çözüm sunar ve Azure Depolama Analytics topladığı günlük verilerini bu şekilde depolar.
Bu bölümde, Depolama Analytics'in günlük verilerini blob depolamada nasıl depoladığı, genellikle aralığa göre sorguladığınız verileri depolamaya yönelik bu yaklaşımın bir çizimi olarak açıklanmıştır.
Depolama Analytics, günlük iletilerini birden çok blobda sınırlandırılmış biçimde depolar. Sınırlandırılmış biçim, istemci uygulamasının günlük iletisindeki verileri ayrıştırmasını kolaylaştırır.
Depolama Analytics, aradığınız günlük iletilerini içeren blobu (veya blobları) bulmanızı sağlayan bloblar için bir adlandırma kuralı kullanır. Örneğin, "queue/2014/07/31/1800/000001.log" adlı blob, 31 Temmuz 2014 saat 18:00'da başlayan sıra hizmetiyle ilgili günlük iletilerini içerir. "000001", bu dönemin ilk günlük dosyası olduğunu gösterir. Depolama Analytics, blobun meta verilerinin bir parçası olarak dosyada depolanan ilk ve son günlük iletilerinin zaman damgalarını da kaydeder. Blob depolama API'si, bir kapsayıcıdaki blobları ad ön ekine göre bulmanıza olanak tanır: Saat 18:00'den itibaren sıra günlüğü verilerini içeren tüm blobları bulmak için "kuyruk/2014/07/31/1800" ön ekini kullanabilirsiniz.
Depolama Analytics, günlük iletilerini dahili olarak arabelleğe alır ve ardından uygun blobu düzenli aralıklarla güncelleştirir veya en son günlük girdileri toplu işlemiyle yeni bir tane oluşturur. Bu, blob hizmetine gerçekleştirmesi gereken yazma işlemlerinin sayısını azaltır.
Kendi uygulamanızda benzer bir çözüm uyguluyorsanız güvenilirlik (her günlük girdisini blob depolamaya yazarken yazma) ve maliyet ve ölçeklenebilirlik (uygulamanızdaki güncelleştirmeleri arabelleğe alma ve bunları toplu olarak blob depolamaya yazma) arasındaki dengeyi nasıl yönetebilirsiniz?
Sorunlar ve dikkat edilmesi gerekenler
Günlük verilerini depolamaya karar verirken aşağıdaki noktaları göz önünde bulundurun:
- Olası sık erişimli bölümleri önleyen bir tablo tasarımı oluşturursanız, günlük verilerinize verimli bir şekilde erişemediğinizi fark edebilirsiniz.
- Günlük verilerini işlemek için istemcinin genellikle birçok kaydı yüklemesi gerekir.
- Günlük verileri genellikle yapılandırılmış olsa da blob depolama daha iyi bir çözüm olabilir.
Uygulama ile ilgili hususlar
Bu bölümde, önceki bölümlerde açıklanan desenleri uygularken göz önünde bulundurmanız gereken bazı noktalar açıklanmaktadır. Bu bölümün çoğu, Depolama istemci kitaplığını (yazma sırasında sürüm 4.3.0) kullanan C# dilinde yazılmış örnekleri kullanır.
Varlıklar alınıyor
Sorgulama için tasarım bölümünde açıklandığı gibi, en verimli sorgu nokta sorgusudur. Ancak bazı senaryolarda birden çok varlık almanız gerekebilir. Bu bölümde, Depolama istemci kitaplığını kullanarak varlıkları almaya yönelik bazı yaygın yaklaşımlar açıklanmaktadır.
Depolama istemci kitaplığını kullanarak nokta sorgusu yürütme
Nokta sorgusunu yürütmenin en kolay yolu, aşağıdaki C# kod parçacığında gösterildiği gibi GetEntityAsync yöntemini kullanarak "Sales" değerinin PartitionKey değerini ve "212" değerinin RowKey değerini alan bir varlığı almaktır:
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Bu örneğin, aldığınız varlığın EmployeeEntity türünde olmasını nasıl beklediğine dikkat edin.
LINQ kullanarak birden çok varlık alma
Microsoft Azure Cosmos DB Tablo Standart Kitaplığı ile çalışırken Tablo hizmetinden birden çok varlık almak için LINQ kullanabilirsiniz.
dotnet add package Azure.Data.Tables
Aşağıdaki örneklerin çalışmasını sağlamak için ad alanlarını eklemeniz gerekir:
using System.Linq;
using Azure.Data.Tables
Birden çok varlığın alınması, filtre yan tümcesi ile bir sorgu belirtilerek elde edilebilir. Tablo taramasını önlemek için, filter yan tümcesine her zaman PartitionKey değerini ve mümkünse tablo ve bölüm taramalarını önlemek için RowKey değerini eklemeniz gerekir. Tablo hizmeti, filtre yan tümcesinde kullanmak üzere sınırlı bir karşılaştırma işleçleri kümesini (büyüktür, büyüktür veya eşittir, küçüktür, küçüktür veya eşit, eşit ve eşit değildir) destekler.
Aşağıdaki örnekte bir employeeTable TableClient nesnesidir. Bu örnek, satış departmanında soyadı "B" ile başlayan tüm çalışanları bulur (RowKey'in soyadını depoladığını varsayarsak) (Bölüm Anahtarı'nın bölüm adını depoladığını varsayarsak):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Daha iyi performans sağlamak için sorgunun hem RowKey hem de PartitionKey belirttiğine dikkat edin.
Aşağıdaki kod örneği LINQ söz dizimi kullanmadan eşdeğer işlevselliği gösterir:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Dekont
Örnek Sorgu yöntemleri üç filtre koşulunu içerir.
Sorgudan çok sayıda varlık alma
En uygun sorgu, PartitionKey değerini ve RowKey değerini temel alan tek bir varlık döndürür. Ancak bazı senaryolarda, aynı bölümden veya hatta birçok bölümden birçok varlık döndürme gereksiniminiz olabilir.
Bu tür senaryolarda uygulamanızın performansını her zaman tam olarak test etmelisiniz.
Tablo hizmetine yönelik bir sorgu bir kerede en fazla 1.000 varlık döndürebilir ve en fazla beş saniye yürütülebilir. Sonuç kümesi 1.000'den fazla varlık içeriyorsa, sorgu beş saniye içinde tamamlanmadıysa veya sorgu bölüm sınırını geçerse, Tablo hizmeti istemci uygulamasının sonraki varlık kümesini istemesini sağlamak için bir devamlılık belirteci döndürür. Devamlılık belirteçlerinin nasıl çalıştığı hakkında daha fazla bilgi için bkz . Sorgu Zaman Aşımı ve Sayfalandırma.
Azure Tabloları istemci kitaplığını kullanıyorsanız, Tablo hizmetinden varlıklar döndürdüğünden sizin için devamlılık belirteçlerini otomatik olarak işleyebilir. İstemci kitaplığını kullanan aşağıdaki C# kod örneği, tablo hizmeti bunları yanıt olarak döndürürse devamlılık belirteçlerini otomatik olarak işler:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Sayfa başına döndürülen en fazla varlık sayısını da belirtebilirsiniz. Aşağıdaki örnekte ile varlıkların nasıl sorgu yapılacağı gösterilmektedir maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
Daha gelişmiş senaryolarda, kodunuzun sonraki sayfaların getirildiğinde tam olarak kontrol etmesi için hizmetten döndürülen devamlılık belirtecini depolamak isteyebilirsiniz. Aşağıdaki örnekte belirtecin nasıl getirilip sayfalandırılmış sonuçlara uygulanabileceğine ilişkin temel bir senaryo gösterilmektedir:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Devamlılık belirteçlerini açıkça kullanarak uygulamanızın bir sonraki veri kesimini ne zaman alabileceğini denetleyebilirsiniz. Örneğin, istemci uygulamanız kullanıcıların bir tabloda depolanan varlıklar arasında sayfalandırmasına olanak sağlıyorsa, kullanıcı sorgu tarafından alınan tüm varlıkları sayfalandırmamaya karar verebilir, böylece kullanıcı geçerli kesimdeki tüm varlıkları sayfalamayı bitirdiğinde uygulamanız yalnızca bir devam belirteci kullanarak sonraki segmenti alabilir. Bu yaklaşımın çeşitli avantajları vardır:
- Tablo hizmetinden alınacak veri miktarını sınırlamanıza ve ağ üzerinden taşımanıza olanak tanır.
- .NET'te zaman uyumsuz GÇ gerçekleştirmenizi sağlar.
- Uygulama kilitlenmesi durumunda devam edebilmeniz için devamlılık belirtecini kalıcı depolamaya seri hale getirmenizi sağlar.
Dekont
Devamlılık belirteci genellikle 1.000 varlık içeren bir kesim döndürür, ancak daha az olabilir. Arama ölçütlerinizle eşleşen ilk n varlığı döndürmek için Take kullanarak sorgunun döndürdüğü girdi sayısını sınırlandırırsanız da bu durum söz konusudur: tablo hizmeti, kalan varlıkları almanıza olanak tanımak için bir devamlılık belirteciyle birlikte n'den az varlık içeren bir kesim döndürebilir.
Sunucu tarafı projeksiyonu
Tek bir varlığın en fazla 255 özelliği olabilir ve boyutu 1 MB'a kadar olabilir. Tabloyu sorgulayıp varlıkları aldığınızda, tüm özelliklere ihtiyacınız olmayabilir ve verileri gereksiz yere aktarmaktan kaçınabilirsiniz (gecikme süresini ve maliyeti azaltmaya yardımcı olmak için). Yalnızca ihtiyacınız olan özellikleri aktarmak için sunucu tarafı projeksiyonunu kullanabilirsiniz. Aşağıdaki örnek, sorgu tarafından seçilen varlıklardan yalnızca Email özelliğini (PartitionKey, RowKey, Timestamp ve ETag ile birlikte) alır.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
RowKey değerinin, alınacak özellikler listesine dahil edilmemesine rağmen nasıl kullanılabilir olduğuna dikkat edin.
Varlıkları değiştirme
Depolama istemci kitaplığı, varlıkları ekleyerek, silerek ve güncelleştirerek tablo hizmetinde depolanan varlıklarınızı değiştirmenize olanak tanır. EGT'leri kullanarak gereken gidiş dönüş sayısını azaltmak ve çözümünüzün performansını artırmak için birden çok eklemeyi toplu işleyebilir, güncelleştirebilir ve silebilirsiniz.
Depolama istemci kitaplığı bir EGT yürüttüğünde oluşan özel durumlar genellikle toplu işlemin başarısız olmasına neden olan varlığın dizinini içerir. BU, EGT'leri kullanan kodda hata ayıklarken yararlı olur.
Ayrıca tasarımınızın istemci uygulamanızın eşzamanlılık ve güncelleştirme işlemlerini nasıl işlediğini nasıl etkilediğini de göz önünde bulundurmalısınız.
Eşzamanlılığı yönetme
Varsayılan olarak, tablo hizmeti Ekleme, Birleştirme ve Silme işlemleri için tek tek varlıklar düzeyinde iyimser eşzamanlılık denetimleri uygular, ancak bir istemcinin tablo hizmetini bu denetimleri atlamasına zorlaması mümkündür. Tablo hizmetinin eşzamanlılığı nasıl yönettiği hakkında daha fazla bilgi için bkz. Microsoft Azure Depolama'de Eşzamanlılığı Yönetme.
Birleştirme veya değiştirme
TableOperation sınıfının Replace yöntemi her zaman Tablo hizmetindeki tüm varlığın yerini alır. Bu özellik depolanan varlıkta mevcut olduğunda isteğe bir özellik eklemezseniz, istek bu özelliği depolanan varlıktan kaldırır. Bir özelliği depolanan bir varlıktan açıkça kaldırmak istemiyorsanız, isteğe her özelliği eklemeniz gerekir.
Bir varlığı güncelleştirmek istediğinizde Tablo hizmetine gönderdiğiniz veri miktarını azaltmak için TableOperation sınıfının Merge yöntemini kullanabilirsiniz. Merge yöntemi, depolanan varlıktaki tüm özellikleri isteğe dahil edilen varlığın özellik değerleriyle değiştirir, ancak depolanan varlıkta istekte bulunmayan özellikleri olduğu gibi bırakır. Bu, büyük varlıklarınız varsa ve bir istekte yalnızca az sayıda özelliği güncelleştirmeniz gerekiyorsa kullanışlıdır.
Dekont
Varlık yoksa Değiştir ve Birleştir yöntemleri başarısız olur. Alternatif olarak, mevcut değilse yeni bir varlık oluşturan InsertOrReplace ve InsertOrMerge yöntemlerini kullanabilirsiniz.
Heterojen varlık türleriyle çalışma
Tablo hizmeti, tek bir tablonun tasarımınızda büyük esneklik sağlayan birden çok türde varlık depolayabileceğiniz anlamına gelen şemasız bir tablo deposudur. Aşağıdaki örnekte hem çalışan hem de departman varlıklarını depoleyen bir tablo gösterilmektedir:
| PartitionKey | RowKey | Zaman damgası | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Her varlığın PartitionKey, RowKey ve Timestamp değerlerine sahip olması gerekir, ancak herhangi bir özellik kümesine sahip olabilir. Ayrıca, bu bilgileri bir yerde depolamayı seçmediğiniz sürece varlığın türünü belirtecek hiçbir şey yoktur. Varlık türünü tanımlamak için iki seçenek vardır:
- Varlık türünü RowKey'e (veya büyük olasılıkla PartitionKey'e) ekleyin. Örneğin, RowKey değerleri olarak EMPLOYEE_000123 veya DEPARTMENT_SALES.
- Varlık türünü aşağıdaki tabloda gösterildiği gibi kaydetmek için ayrı bir özellik kullanın.
| PartitionKey | RowKey | Zaman damgası | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
Varlık türünü RowKey'e önleyen ilk seçenek, farklı türlerdeki iki varlığın aynı anahtar değerine sahip olma olasılığı varsa kullanışlıdır. Ayrıca, aynı türdeki varlıkları bölümde birlikte gruplandırma.
Bu bölümde ele alınan teknikler, özellikle ilişkileri modelleme makalesindeki bu kılavuzun önceki bölümlerinde yer alan Devralma ilişkileri tartışması ile ilgilidir.
Dekont
İstemci uygulamalarının POCO nesnelerini geliştirmesini ve farklı sürümlerle çalışmasını sağlamak için varlık türü değerine bir sürüm numarası eklemeyi düşünmelisiniz.
Bu bölümün geri kalanında, Depolama istemci kitaplığındaki aynı tablodaki birden çok varlık türüyle çalışmayı kolaylaştıran bazı özellikler açıklanmaktadır.
Heterojen varlık türlerini alma
Tablo istemci kitaplığını kullanıyorsanız, birden çok varlık türüyle çalışmak için üç seçeneğiniz vardır.
Belirli bir RowKey ve PartitionKey değerleriyle depolanan varlığın türünü biliyorsanız, EmployeeEntity türündeki varlıkları alan önceki iki örnekte gösterildiği gibi varlığı alırken varlık türünü belirtebilirsiniz: Depolama istemci kitaplığını kullanarak bir nokta sorgusu yürütme ve LINQ kullanarak birden çok varlığı alma.
İkinci seçenek, somut bir POCO varlık türü yerine TableEntity türünü (özellik paketi) kullanmaktır (varlığı .NET türlerine seri hale getirmeniz ve seri durumdan çıkarmanız gerekmeyen bu seçenek performansı da artırabilir). Aşağıdaki C# kodu büyük olasılıkla tablodan farklı türlerde birden çok varlık alır, ancak tüm varlıkları TableEntity örnekleri olarak döndürür. Ardından entityType özelliğini kullanarak her varlığın türünü belirler:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Diğer özellikleri almak için TableEntity sınıfının varlığında GetString yöntemini kullanmanız gerekir.
Heterojen varlık türlerini değiştirme
Silmek için bir varlığın türünü bilmeniz gerekmez ve eklediğinizde varlığın türünü her zaman bilirsiniz. Ancak, tableEntity türünü kullanarak bir varlığı türünü bilmeden ve POCO varlık sınıfı kullanmadan güncelleştirebilirsiniz. Aşağıdaki kod örneği tek bir varlığı alır ve güncelleştirmeden önce EmployeeCount özelliğinin mevcut olup olmadığını denetler.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Paylaşılan Erişim İmzaları ile erişimi denetleme
İstemci uygulamalarının koduna depolama hesabı anahtarınızı eklemeye gerek kalmadan tablo varlıklarını değiştirmesini (ve sorgulamasını) sağlamak için Paylaşılan Erişim İmzası (SAS) belirteçlerini kullanabilirsiniz. Genellikle uygulamanızda SAS kullanmanın üç temel avantajı vardır:
- Bu cihazın Tablo hizmetindeki varlıklara erişmesine ve bunları değiştirmesine izin vermek için depolama hesabı anahtarınızı güvenli olmayan bir platforma (mobil cihaz gibi) dağıtmanız gerekmez.
- Varlıklarınızı yönetirken web ve çalışan rollerinin gerçekleştirdiği bazı işleri son kullanıcı bilgisayarları ve mobil cihazlar gibi istemci cihazlara devredebilirsiniz.
- bir istemciye kısıtlı ve sınırlı bir izin kümesi atayabilirsiniz (örneğin, belirli kaynaklara salt okunur erişime izin verme).
Tablo hizmetiyle SAS belirteçlerini kullanma hakkında daha fazla bilgi için bkz . Paylaşılan Erişim İmzalarını (SAS) Kullanma.
Ancak, bir istemci uygulamasına tablo hizmetindeki varlıklara veren SAS belirteçlerini yine de oluşturmanız gerekir: Bunu depolama hesabı anahtarlarınıza güvenli erişimi olan bir ortamda yapmalısınız. Genellikle SAS belirteçlerini oluşturmak ve varlıklarınıza erişmesi gereken istemci uygulamalarına teslim etmek için bir web veya çalışan rolü kullanırsınız. SAS belirteçleri oluşturma ve istemcilere teslim etme konusunda hala bir ek yük olduğundan, özellikle yüksek hacimli senaryolarda bu ek yükü en iyi nasıl azaltabileceğinizi düşünmelisiniz.
Bir tablodaki varlıkların bir alt kümesine erişim veren bir SAS belirteci oluşturmak mümkündür. Varsayılan olarak, tablonun tamamı için bir SAS belirteci oluşturursunuz, ancak SAS belirtecinin bir bölüm anahtarı değerleri aralığına veya PartitionKey ve RowKey değerleri aralığına erişim izni vereceğini de belirtebilirsiniz. Sisteminizin tek tek kullanıcıları için, her kullanıcının SAS belirtecinin yalnızca tablo hizmetindeki kendi varlıklarına erişmesine izin vermesi için SAS belirteçleri oluşturmayı seçebilirsiniz.
Zaman uyumsuz ve paralel işlemler
İsteklerinizi birden çok bölüme yayıyorsanız, zaman uyumsuz veya paralel sorgular kullanarak aktarım hızını ve istemci yanıt hızını geliştirebilirsiniz. Örneğin, tablolarınıza paralel olarak erişen iki veya daha fazla çalışan rolü örneğiniz olabilir. Belirli bölüm kümelerinden sorumlu tek tek çalışan rolleriniz olabilir veya her biri bir tablodaki tüm bölümlere erişebilen birden çok çalışan rolü örneğine sahip olabilir.
İstemci örneğinde depolama işlemlerini zaman uyumsuz olarak yürüterek aktarım hızını geliştirebilirsiniz. Depolama istemci kitaplığı, zaman uyumsuz sorgular ve değişiklikler yazmayı kolaylaştırır. Örneğin, aşağıdaki C# kodunda gösterildiği gibi bir bölümdeki tüm varlıkları alan zaman uyumlu yöntemle başlayabilirsiniz:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Sorgunun zaman uyumsuz olarak çalışması için bu kodu aşağıdaki gibi kolayca değiştirebilirsiniz:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Bu zaman uyumsuz örnekte, zaman uyumlu sürümden aşağıdaki değişiklikleri görebilirsiniz:
- Yöntem imzası artık zaman uyumsuz değiştiriciyi içerir ve bir Görev örneği döndürür.
- Yöntem artık sonuçları almak için Query yöntemini çağırmak yerine QueryAsync yöntemini çağırır ve sonuçları zaman uyumsuz olarak almak için await değiştiricisini kullanır.
İstemci uygulaması bu yöntemi birden çok kez çağırabilir (departman parametresi için farklı değerlerle) ve her sorgu ayrı bir iş parçacığında çalıştırılır.
Ayrıca varlıkları zaman uyumsuz olarak ekleyebilir, güncelleştirebilir ve silebilirsiniz. Aşağıdaki C# örneği, bir çalışan varlığını eklemek veya değiştirmek için basit, zaman uyumlu bir yöntem gösterir:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Güncelleştirmenin zaman uyumsuz olarak çalışması için bu kodu aşağıdaki gibi kolayca değiştirebilirsiniz:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
Bu zaman uyumsuz örnekte, zaman uyumlu sürümden aşağıdaki değişiklikleri görebilirsiniz:
- Yöntem imzası artık zaman uyumsuz değiştiriciyi içerir ve bir Görev örneği döndürür.
- Yöntemi, varlığı güncelleştirmek için Execute yöntemini çağırmak yerine şimdi ExecuteAsync yöntemini çağırır ve sonuçları zaman uyumsuz olarak almak için await değiştiricisini kullanır.
İstemci uygulaması bunun gibi birden çok zaman uyumsuz yöntemi çağırabilir ve her yöntem çağrısı ayrı bir iş parçacığında çalıştırılır.