Öğretici: Event Hubs verilerini parquet biçiminde yakalama ve Azure Synapse Analytics ile analiz etme
Bu öğreticide, Içinde Event Hubs verilerini parquet biçiminde Azure Data Lake Storage 2. Nesil yakalayan bir iş oluşturmak için Kod düzenleyicisi olmayan Stream Analytics'in nasıl kullanılacağı gösterilmektedir.
Bu öğreticide şunların nasıl yapıldığını öğreneceksiniz:
- Olay hub'ına örnek olaylar gönderen bir olay oluşturucu dağıtma
- Kod yok düzenleyicisini kullanarak Stream Analytics işi oluşturma
- Giriş verilerini ve şemayı gözden geçirme
- Olay hub'ı verilerinin yakalanacağı Azure Data Lake Storage 2. Nesil yapılandırma
- Stream Analytics işini çalıştırma
- Parquet dosyalarını sorgulamak için Azure Synapse Analytics'i kullanma
Önkoşullar
Başlamadan önce aşağıdaki adımları tamamladığınızdan emin olun:
- Azure aboneliğiniz yoksa ücretsiz bir hesap oluşturun.
- TollApp olay oluşturucu uygulamasını Azure'a dağıtın. 'interval' parametresini 1 olarak ayarlayın ve bu adım için yeni bir kaynak grubu kullanın.
- Data Lake Storage 2. Nesil hesabıyla bir Azure Synapse Analytics çalışma alanı oluşturun.
Stream Analytics işi oluşturmak için kod düzenleyicisi kullanma
TollApp olay oluşturucusunun dağıtıldığı Kaynak Grubunu bulun.
Azure Event Hubs ad alanını seçin.
Event Hubs Ad Alanı sayfasında, soldaki menüde Varlıklar'ın altında Event Hubs'ı seçin.
Örnek seçin
entrystream.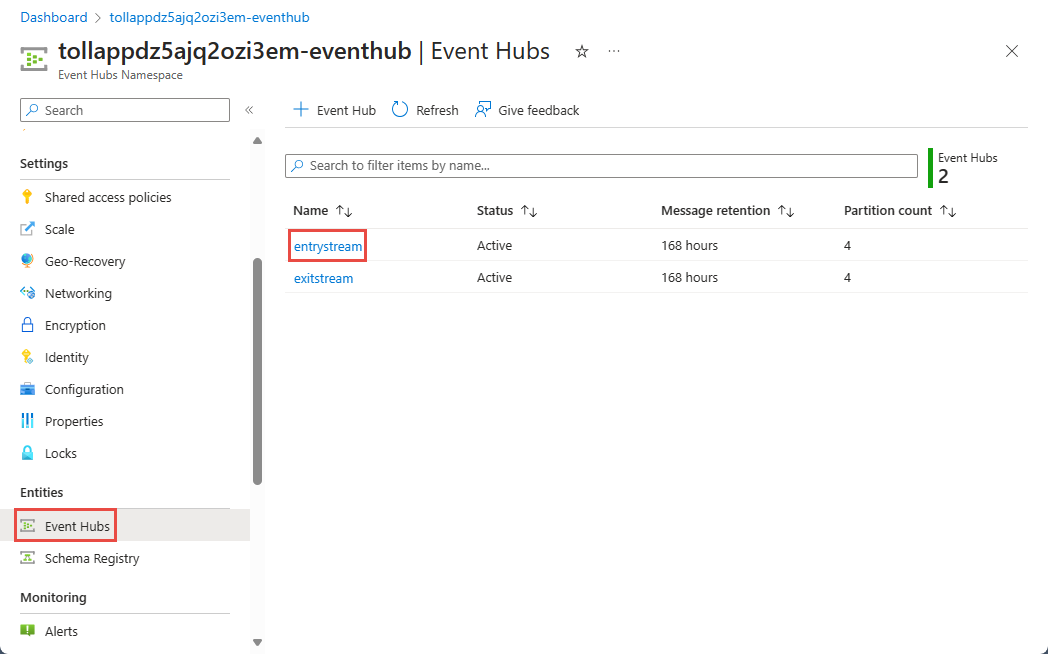
Event Hubs örneği sayfasında, soldaki menünün Özellikler bölümünde verileri işle'yi seçin.
Verileri Parquet biçiminde ADLS 2. Nesil'e yakala kutucuğunda Başlat'ı seçin.
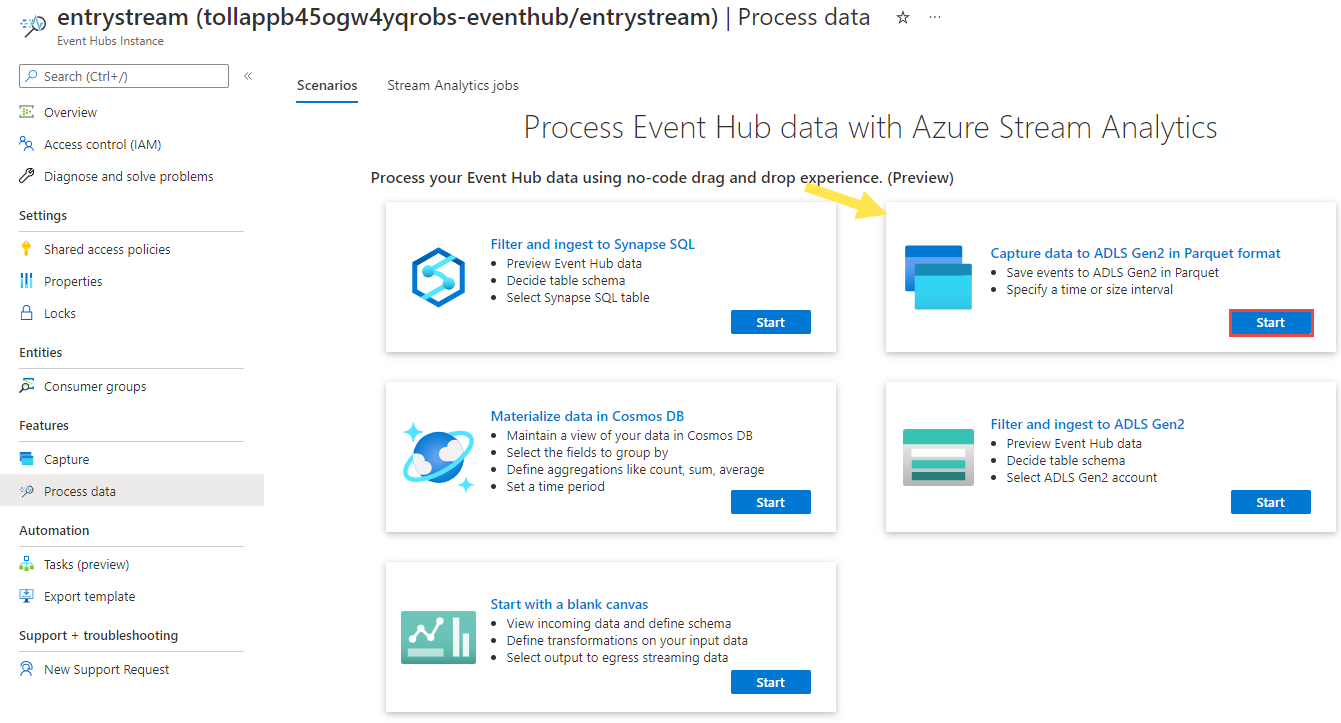
İşinizi
parquetcaptureadlandırıp Oluştur'u seçin.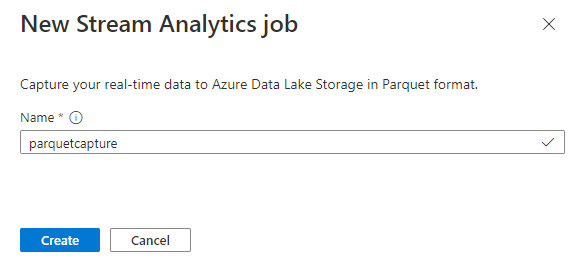
Olay hub'ı yapılandırma sayfasında aşağıdaki ayarları onaylayın ve bağlan'ı seçin.
Tüketici Grubu: Varsayılan
Giriş verilerinizin serileştirme türü: JSON
İşin olay hub'ınıza bağlanmak için kullanacağı kimlik doğrulama modu: Bağlantı dizesi.

Birkaç saniye içinde örnek giriş verilerini ve şemayı görürsünüz. Alanları bırakmayı, alanları yeniden adlandırmayı veya veri türünü değiştirmeyi seçebilirsiniz.

Tuvalinizde Azure Data Lake Storage 2. Nesil kutucuğunu seçin ve belirterek yapılandırın
- Azure Data Lake 2. Nesil hesabınızın bulunduğu abonelik
- Depolama hesabı adı; Önkoşullar bölümünde yapılan Azure Synapse Analytics çalışma alanınızda kullanılan ADLS 2. Nesil hesabıyla aynı olmalıdır.
- Parquet dosyalarının oluşturulacağı kapsayıcı.
- Yol deseni {date}/{time} olarak ayarlandı
- Varsayılan yyyy-aa-gg ve SS olarak tarih ve saat deseni.
- Bağlan'ı seçin
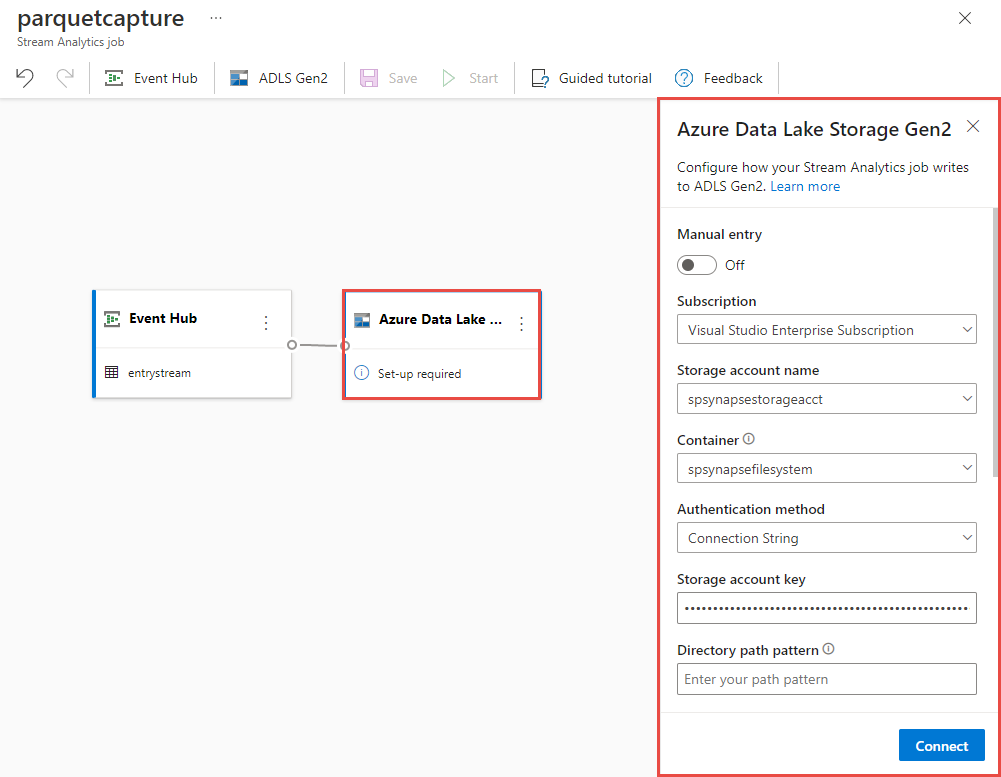
İşinizi kaydetmek için üst şeritte Kaydet'i seçin ve ardından işinizi çalıştırmak için Başlat'ı seçin. İş başlatıldıktan sonra sağ köşedeki X işaretini seçerek Stream Analytics iş sayfasını kapatın.
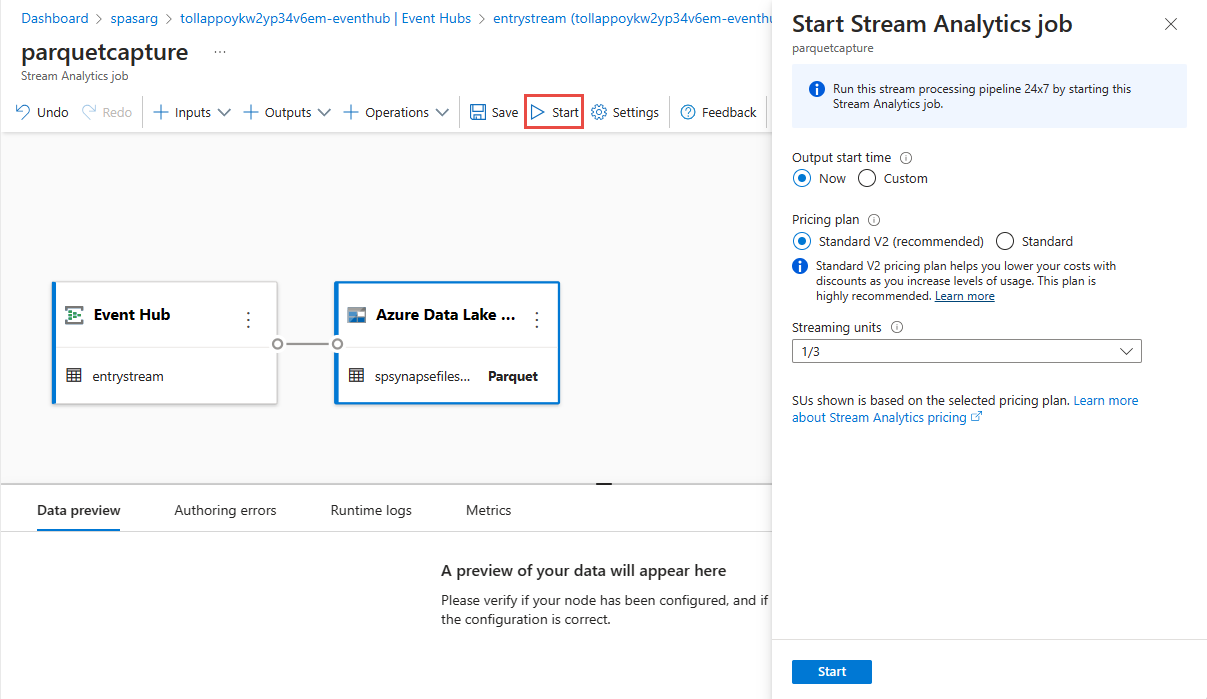
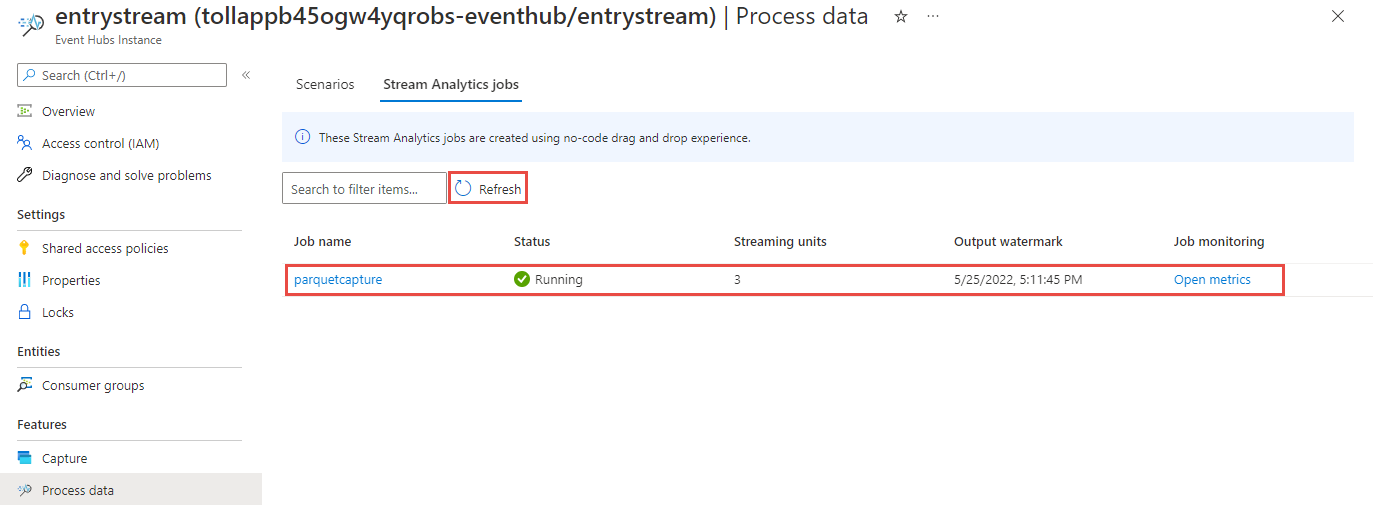
Ardından kod düzenleyicisi olmadan oluşturulan tüm Stream Analytics işlerinin listesini görürsünüz. İki dakika içinde işiniz Çalışıyor durumuna geçer. Oluşturuldu - Başlatılıyor ->> Çalışıyor'dan durumun değiştiğini görmek için sayfadaki Yenile düğmesini seçin.








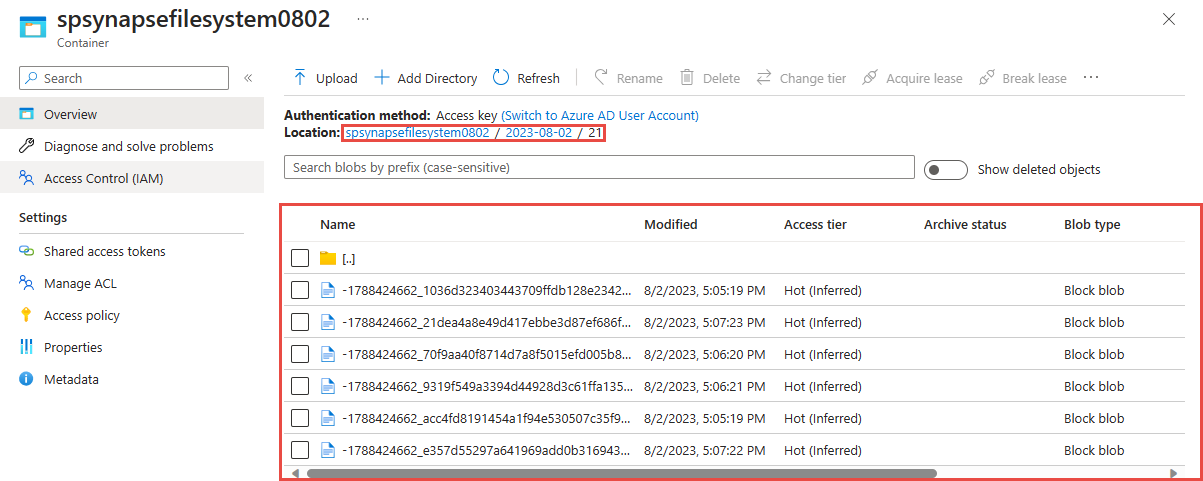
Azure Data Lake Storage 2. Nesil hesabınızda çıkışı görüntüleme
Önceki adımda kullandığınız Azure Data Lake Storage 2. Nesil hesabını bulun.
Önceki adımda kullandığınız kapsayıcıyı seçin. Önceki adımda kullanılan {date}/{time} yol deseni temelinde oluşturulan parquet dosyalarını görürsünüz.
Yakalanan verileri Azure Synapse Analytics ile Parquet biçiminde sorgulama
Azure Synapse Spark kullanarak sorgulama
Azure Synapse Analytics çalışma alanınızı bulun ve Synapse Studio açın.
Henüz yoksa çalışma alanınızda sunucusuz bir Apache Spark havuzu oluşturun.
Synapse Studio Geliştirme hub'ına gidin ve yeni bir Not Defteri oluşturun.
Yeni bir kod hücresi oluşturun ve bu hücreye aşağıdaki kodu yapıştırın. container ve adlsname değerlerini önceki adımda kullanılan kapsayıcının adı ve ADLS 2. Nesil hesabıyla değiştirin.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Araç çubuğundaki Ekle için açılan listeden Spark havuzunuzu seçin.
Sonuçları görmek için Tümünü Çalıştır'ı seçin


Sunucusuz SQL kullanarak Azure Synapse sorgulama
Geliştirme merkezinde yeni bir SQL betiği oluşturun.
Aşağıdaki betiği yapıştırın ve Yerleşik sunucusuz SQL uç noktasını kullanarak çalıştırın. container ve adlsname değerlerini önceki adımda kullanılan kapsayıcının adı ve ADLS 2. Nesil hesabıyla değiştirin.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]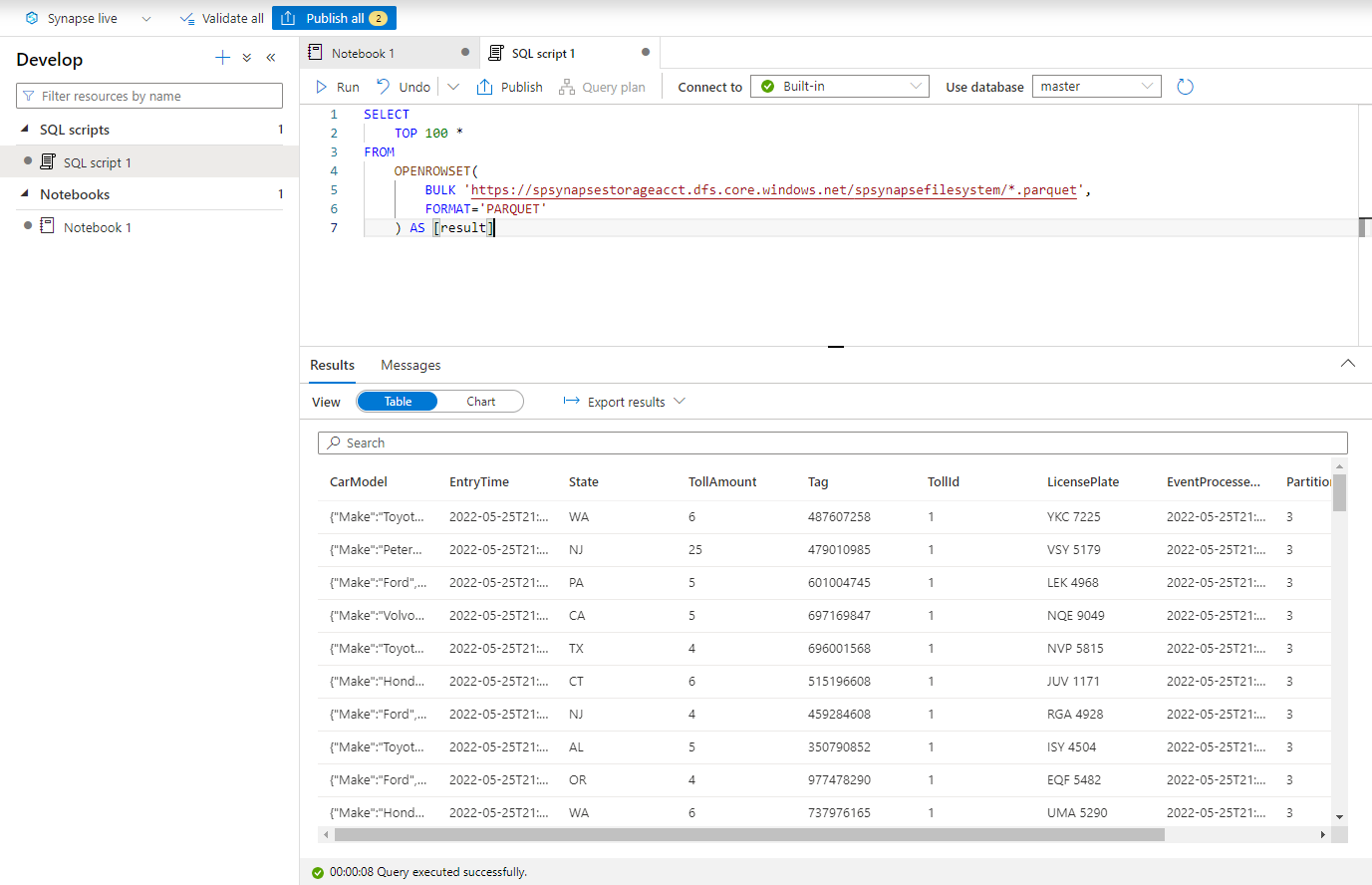

Kaynakları temizleme
- Event Hubs örneğinizi bulun ve İşlem Verileri bölümünde Stream Analytics işlerinin listesine bakın. Çalışan tüm işleri durdurun.
- TollApp olay oluşturucuyu dağıtırken kullandığınız kaynak grubuna gidin.
- Kaynak grubunu sil'i seçin. Silme işlemini onaylamak için kaynak grubunun adını yazın.
Sonraki adımlar
Bu öğreticide, Parquet biçiminde Event Hubs veri akışlarını yakalamak için kod düzenleyicisi olmadan Stream Analytics işi oluşturmayı öğrendiniz. Ardından hem Synapse Spark hem de Synapse SQL kullanarak parquet dosyalarını sorgulamak için Azure Synapse Analytics'i kullandınız.