Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Akış giriş verilerinizde gerçek zamanlı puanlama ve tahminler yapmak için Azure Stream Analytics işlerinizde makine öğrenmesi modellerini kullanıcı tanımlı bir işlev (UDF) olarak uygulayabilirsiniz. Azure Machine Learning , modelleri hazırlamak, eğitmek ve dağıtmak için TensorFlow, scikit-learn veya PyTorch gibi popüler açık kaynak araçları kullanmanıza olanak tanır.
Önkoşullar
Stream Analytics işinize işlev olarak bir makine öğrenmesi modeli eklemeden önce aşağıdaki adımları tamamlayın:
Modelinizi web hizmeti olarak dağıtmak için Azure Machine Learning'i kullanın.
Makine öğrenmesi uç noktanızın, Stream Analytics'in giriş ve çıkışın şemasını anlamasına yardımcı olan ilişkili bir Swagger'a sahip olması gerekir. Doğru şekilde ayarladığınızdan emin olmak için bu örnek swagger tanımını başvuru olarak kullanabilirsiniz.
Web hizmetinizin JSON serileştirilmiş verileri kabul edip döndürdüğüne emin olun.
Yüksek ölçekli üretim dağıtımları için modelinizi Azure Kubernetes Service'te dağıtın. Web hizmeti, işinizden gelen isteklerin sayısını işleyemezse Stream Analytics işinizin performansı düşer ve bu da gecikme süresini etkiler. Azure Container Instances'a dağıtılan modeller yalnızca Azure portalını kullandığınızda desteklenir.
İşinize makine öğrenmesi modeli ekleme
Stream Analytics işinize Azure Machine Learning işlevlerini doğrudan Azure portalından veya Visual Studio Code'dan ekleyebilirsiniz.
Azure portal
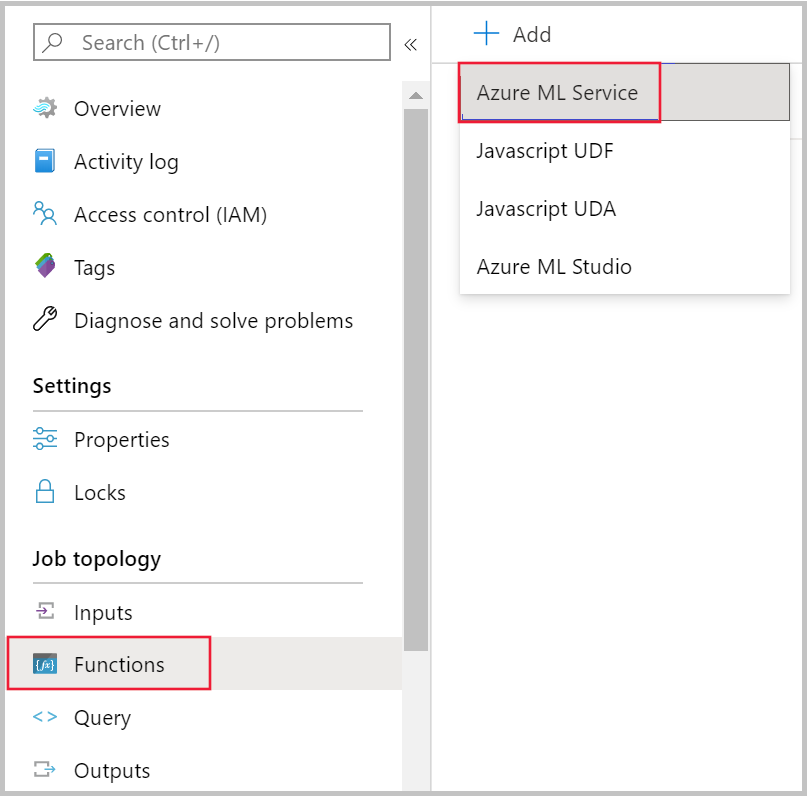
Azure portalında Stream Analytics işinize gidin ve İş topolojisi'nin altındaki İşlevler'i seçin. Ardından + Ekle açılan menüsünden Azure Machine Learning Hizmeti'ni seçin.
Azure Machine Learning Hizmeti işlev formunu aşağıdaki özellik değerleriyle doldurun:
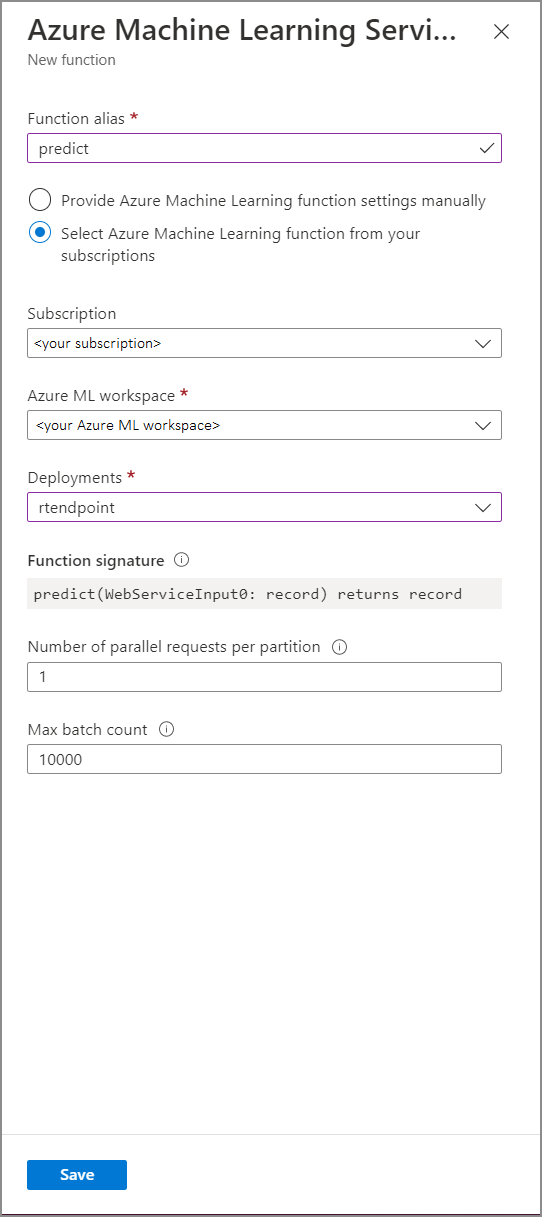
Aşağıdaki tabloda, Stream Analytics'teki Azure Machine Learning Service işlevlerinin her özelliği açıklanmaktadır.
| Özellik | Açıklama |
|---|---|
| Fonksiyon takma adı | Sorgunuzda işlevi çağırmak için bir ad girin. |
| Abonelik | Azure aboneliğiniz. |
| Azure Machine Learning çalışma alanı | Modelinizi web hizmeti olarak dağıtmak için kullandığınız Azure Machine Learning çalışma alanı. |
| Uç nokta | Modelinizi barındıran web hizmeti. |
| İşlev imzası | WEB hizmetinizin imzası API'nin şema belirtiminden çıkarılır. İmzanız yüklenemezse, şemayı otomatik olarak oluşturmak için puanlama betiğinizde örnek giriş ve çıkış sağladığınızı denetleyin. |
| Bölüm başına paralel istek sayısı | Bu, yüksek ölçekli aktarım hızını iyileştirmeye yönelik gelişmiş bir yapılandırmadır. Bu sayı, işinizin her bölümünden web hizmetine gönderilen eşzamanlı istekleri temsil eder. Altı veya daha az akış birimine (SU) sahip işler tek bir bölümle yapılandırılır. 12 SU'ya sahip işlerin iki bölümü vardır, 18 SU'nun üç bölümü vardır ve bu şekilde devam eder. Örneğin, işinizin iki bölümü varsa ve bu parametreyi dört olarak ayarlarsanız, işinizden web hizmetinize sekiz eşzamanlı istek olur. |
| Maksimum işlem grubu sayısı | Bu, yüksek ölçekli aktarım hızını iyileştirmeye yönelik gelişmiş bir yapılandırmadır. Bu sayı, web hizmetinize gönderilen tek bir istekte birlikte toplu işlenecek en fazla olay sayısını temsil eder. |
Sorgunuzdan makine öğrenmesi uç noktasını çağırma
Stream Analytics sorgunuz bir Azure Machine Learning UDF'sini çağırdığında, iş web hizmetine JSON serileştirilmiş bir istek oluşturur. İstek, Stream Analytics'in uç noktanın Swagger tanımından çıkardığı, modele özgü bir şemayı temel alır.
Uyarı
İş çalışmadığından Azure portal sorgu düzenleyicisiyle test yaparken Machine Learning uç noktaları çağrılmaz. Portaldan uç nokta çağrısını test etmek için Stream Analytics işinin çalışıyor olması gerekir.
Aşağıdaki Stream Analytics sorgusu, Azure Machine Learning UDF'sini çağırmaya yönelik bir örnektir:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
ML UDF'ye gönderilen giriş verileriniz beklenen şemayla tutarsızsa, uç nokta 400 hata koduyla bir yanıt döndürür ve bu da Stream Analytics işinizin başarısız duruma gitmesine neden olur. İşiniz için kaynak günlüklerini etkinleştirmeniz önerilir; bu sayede bu tür sorunları kolayca ayıklayıp giderebilirsiniz. Bu nedenle şunları yapmanızı kesinlikle öneririz:
- Makine Öğrenimi UDF için giriş verisinin null olmadığını doğrulayın
- Uç noktanın beklediğiyle eşleştiğinden emin olmak için ML UDF'nize giriş olan her alanın türünü doğrulayın
Not
ML UDF'leri, koşullu ifade (örneğin CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END) aracılığıyla çağrıldığında bile belirli bir sorgu adımının her satırı için değerlendirilir. Gerekirse, yalnızca gerektiğinde ML UDF'yi çağırarak ayrılan yollar oluşturmak için WITH koşulunu kullanın, ardından yolları yeniden birleştirmek için UNION kullanın.
UDF'ye birden çok giriş parametresi geçirme
Makine öğrenmesi modellerine yönelik girişlerin en yaygın örnekleri numpy dizileri ve DataFrame'lerdir. JavaScript UDF kullanarak bir dizi oluşturabilir ve WITH ifadesini kullanarak JSON ile serileştirilmiş bir DataFrame oluşturabilirsiniz.
Giriş dizisi oluşturma
N sayıda girişi kabul eden ve Azure Machine Learning UDF'nize giriş olarak kullanılabilecek bir dizi oluşturan bir JavaScript UDF oluşturabilirsiniz.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
JavaScript UDF'yi işinize ekledikten sonra aşağıdaki sorguyu kullanarak Azure Machine Learning UDF'nizi çağırabilirsiniz:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
Aşağıdaki JSON örnek bir istektir:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Pandas veya PySpark DataFrame oluşturma
Azure Machine Learning UDF'nize giriş olarak geçirilebilecek bir JSON serileştirilmiş DataFrame oluşturmak için WITH ifadesini kullanabilirsiniz, aşağıda gösterildiği gibi.
Aşağıdaki sorgu, gerekli alanları seçerek bir DataFrame oluşturur ve DataFrame'i Azure Machine Learning UDF'sine giriş olarak kullanır.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Aşağıdaki JSON, önceki sorgudan gelen örnek bir istektir:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Azure Machine Learning UDF'leri için performansı iyileştirme
Modelinizi Azure Kubernetes Service'e dağıttığınızda, kaynak kullanımını belirlemek için modelinizin profilini oluşturabilirsiniz. İstek oranlarını, yanıt sürelerini ve hata oranlarını anlamak için dağıtımlarınız için App Insights'ı da etkinleştirebilirsiniz.
Yüksek olay aktarım hızına sahip bir senaryonuz varsa, düşük uçtan uca gecikme süreleriyle en iyi performansı elde etmek için Stream Analytics'te aşağıdaki parametreleri değiştirmeniz gerekebilir:
- En fazla toplu iş sayısı.
- Bölüm başına paralel istek sayısı.
Doğru toplu işlem boyutunu belirleme
Web hizmetinizi dağıttıktan sonra, 50'den başlayarak değişen toplu iş boyutlarıyla örnek istek gönderir ve toplu iş boyutunu yüzer yüzer artırırsınız. Örneğin, 200, 500, 1000, 2000 vb. Belirli bir toplu iş boyutundan sonra yanıtın gecikme süresinin arttığını fark edeceksiniz. Yanıt gecikmesinin arttığı nokta, işiniz için maksimum işlem grubu sayısı olmalıdır.
Bölüm başına paralel istek sayısını belirleme
En iyi ölçeklendirmede Stream Analytics işinizin web hizmetinize birden çok paralel istek gönderebilmesi ve birkaç milisaniye içinde yanıt alabilmesi gerekir. Web hizmetinin yanıt gecikmesi, Stream Analytics işinizin gecikme süresini ve performansını doğrudan etkileyebilir. İş yükünüzden web hizmetine yapılan çağrı uzun sürüyorsa, büyük olasılıkla filigran gecikmesinde bir artış görürsünüz ve ayrıca birikmiş giriş olaylarının sayısında bir artış görebilirsiniz.
Azure Kubernetes Service (AKS) kümenizin doğru sayıda düğüm ve çoğaltmalar ile sağlandığından emin olarak düşük gecikme süresi elde edebilirsiniz. Web hizmetinizin yüksek oranda kullanılabilir olması ve başarılı yanıtlar döndürmesi kritik önem taşır. İşleminiz hizmet kullanılamıyor yanıtı (503) gibi yeniden denenebilecek bir hata alırsa, üstel geri çekilme ile otomatik olarak yeniden denenecektir. İşiniz bu hatalardan birini uç noktadan yanıt olarak alırsa, iş başarısız duruma geçer.
- Hatalı İstek (400)
- Çakışma (409)
- Bulunamadı (404)
- Yetkisiz (401)
Sınırlamalar
Azure ML Yönetilen Uç Nokta hizmeti kullanıyorsanız Stream Analytics şu anda yalnızca genel ağ erişimi etkinleştirilmiş uç noktalara erişebilir. Azure ML özel uç noktaları hakkında sayfada bu konuda daha fazla bilgi edinin.