Öğretici: Azure AI hizmetleriyle Metin Analizi
Metin Analizi, Doğal Dil İşleme (NLP) özellikleriyle metin madenciliği ve metin analizi gerçekleştirmenizi sağlayan bir Azure AI hizmetleridir. Bu öğreticide, Metin Analizi kullanarak Azure Synapse Analytics'te yapılandırılmamış metinleri analiz etmeyi öğreneceksiniz.
Bu öğreticide şunları yapmak için SynapseML ile metin analizinin kullanılması gösterilmektedir:
- Tümce veya belge düzeyinde yaklaşım etiketlerini algılama
- Belirli bir metin girişi için dili tanımlama
- İyi bilinen bir bilgi bankası bağlantıları olan bir metindeki varlıkları tanıma
- Metinden anahtar aşamaları ayıklama
- Metindeki farklı varlıkları tanımlama ve bunları önceden tanımlanmış sınıflara veya türlere ayırma
- Belirli bir metindeki hassas varlıkları tanımlama ve yeniden düzenleme
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Önkoşullar
- Azure Synapse Analytics çalışma alanında varsayılan depolama alanı olarak yapılandırılmış bir Azure Data Lake Storage 2. Nesil depolama hesabı. Birlikte çalıştığınız Data Lake Storage 2. Nesil dosya sisteminin Depolama Blob Verileri Katkıda Bulunanı olmanız gerekir.
- Azure Synapse Analytics çalışma alanınızdaki Spark havuzu. Ayrıntılar için bkz. Azure Synapse'da Spark havuzu oluşturma.
- Azure Synapse'de Azure AI hizmetlerini yapılandırma öğreticisinde açıklanan yapılandırma öncesi adımlar.
Başlarken
Synapse Studio açın ve yeni bir not defteri oluşturun. Başlamak için SynapseML'yi içeri aktarin.
import synapse.ml
from synapse.ml.cognitive import *
from pyspark.sql.functions import col
Metin analizini yapılandırma
Yapılandırma öncesi adımlarında yapılandırdığınız bağlantılı metin analizini kullanın.
ai_service_name = "<Your linked service for text analytics>"
Metin Yaklaşımı
Metin Yaklaşımı Analizi, yaklaşım etiketlerini ("negatif", "nötr" ve "pozitif" gibi) ve tümce ve belge düzeyinde güvenilirlik puanlarını algılamak için bir yol sağlar. Etkinleştirilmiş dillerin listesi için bkz. Metin Analizi API'de desteklenen diller.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, its sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Beklenen sonuçlar
| metin | Duyguları |
|---|---|
| Bugün çok mutluyum, güneşli! | pozitif |
| Bu yoğun saatlik trafik beni hayal kırıklığına uğrattı | negatif |
| Spark aint bad üzerinde Azure AI hizmetleri | pozitif |
Dil Algılayıcısı
Dil Algılayıcısı her belge için metin girişini değerlendirir ve dil tanımlayıcılarını çözümlemenin gücünü gösteren bir puanla döndürür. Bu özellik, dilin bilinmediği rastgele metni toplayan içerik depoları için kullanışlıdır. Etkinleştirilmiş dillerin listesi için bkz. Metin Analizi API'de desteklenen diller.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
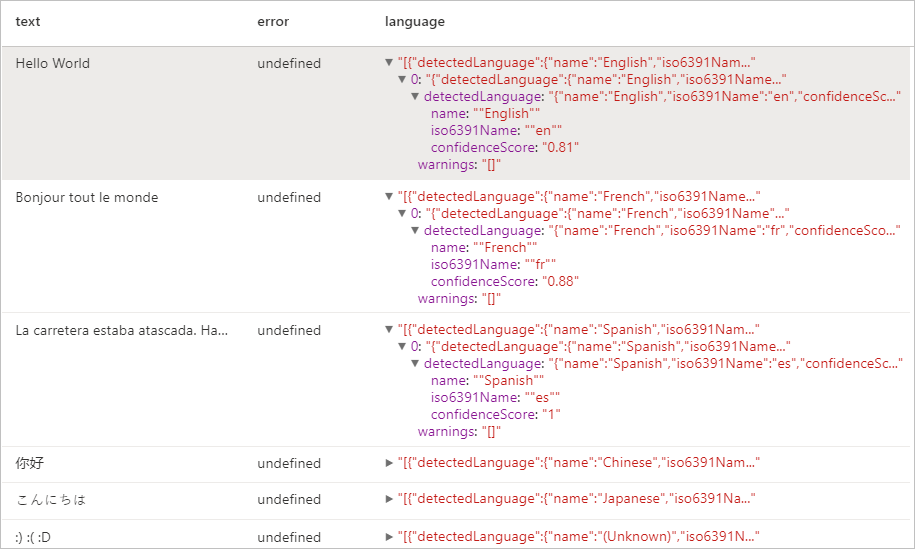
display(language.transform(df))
Beklenen sonuçlar
Varlık Algılayıcısı
Varlık Algılayıcısı, tanınmış bir bilgi bankası bağlantıları olan tanınan varlıkların listesini döndürür. Etkinleştirilmiş dillerin listesi için bkz. Metin Analizi API'de desteklenen diller.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
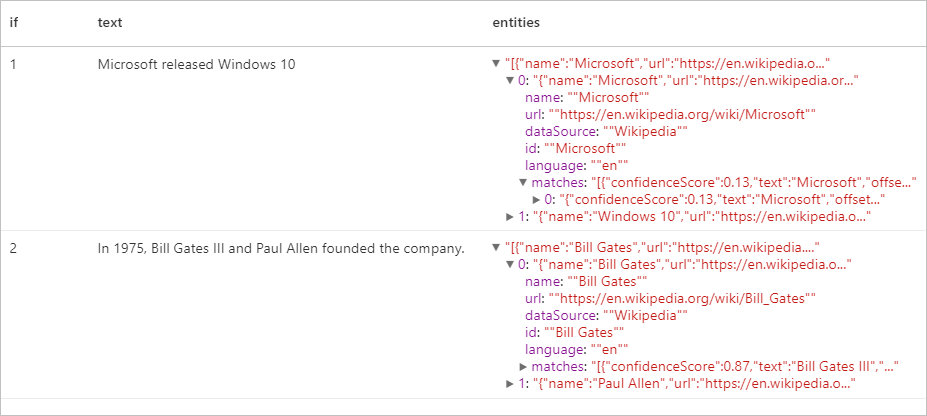
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Beklenen sonuçlar
Anahtar İfade Ayıklayıcısı
Anahtar İfade Ayıklama yapılandırılmamış metni değerlendirir ve anahtar ifadelerin listesini döndürür. Bir belge koleksiyonundaki ana noktaları hızlı şekilde belirlemeniz gerekiyorsa bu özellik kullanışlıdır. Etkinleştirilmiş dillerin listesi için bkz. Metin Analizi API'de desteklenen diller.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Beklenen sonuçlar
| metin | keyPhrases |
|---|---|
| Merhaba Dünya. Bu çok sevdiğim bir giriş metni. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Adlandırılmış Varlık Tanıma (NER)
Adlandırılmış Varlık Tanıma (NER), metindeki farklı varlıkları tanımlayıp bunları önceden tanımlanmış sınıflara veya kişi, konum, olay, ürün ve kuruluş gibi türlere ayırabilme özelliğidir. Etkinleştirilmiş dillerin listesi için bkz. Metin Analizi API'de desteklenen diller.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
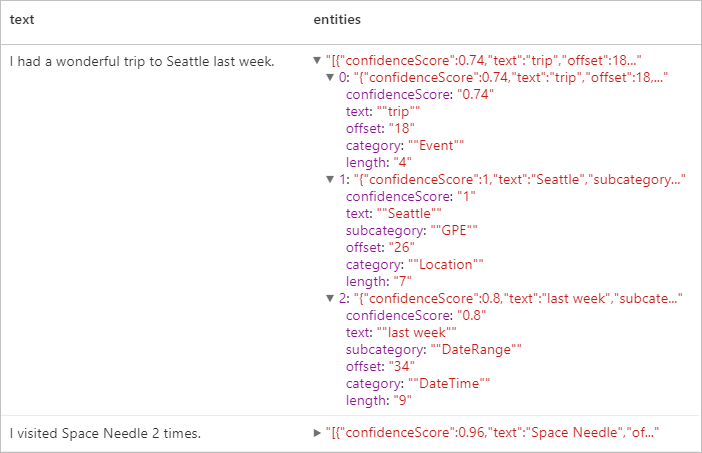
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Beklenen sonuçlar
Kişisel Bilgiler (PII) V3.1
PII özelliği NER'nin bir parçasıdır ve tek bir kişiyle ilişkili metindeki telefon numarası, e-posta adresi, posta adresi, pasaport numarası gibi hassas varlıkları tanımlayabilir ve düzeltebilir. Etkinleştirilmiş dillerin listesi için bkz. Metin Analizi API'de desteklenen diller.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
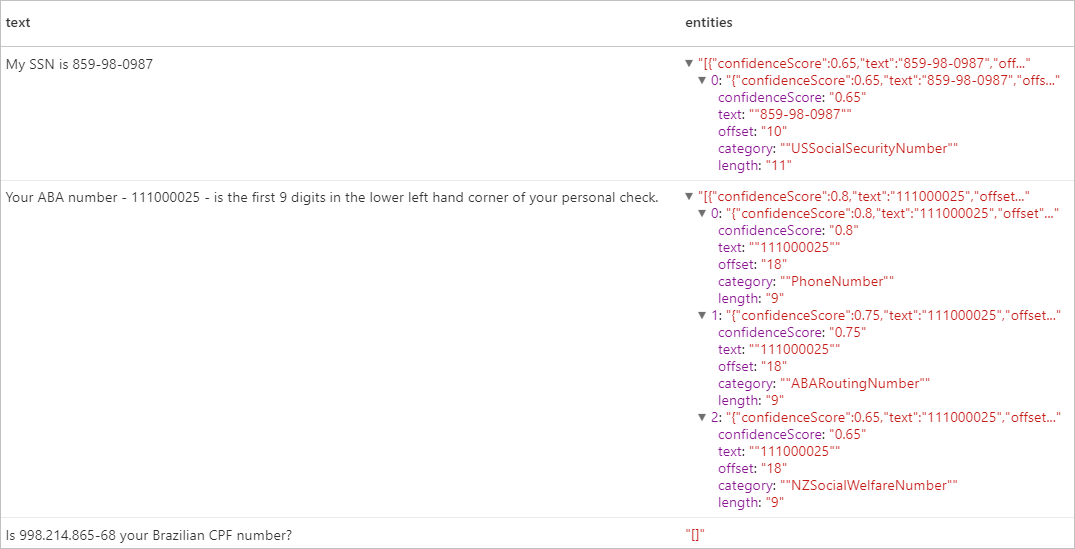
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Beklenen sonuçlar
Kaynakları temizleme
Spark örneğinin kapatılmış olduğundan emin olmak için bağlı oturumları (not defterlerini) sonlandırın. Apache Spark havuzunda belirtilen boşta kalma süresine ulaşıldığında havuz kapatılır. Ayrıca, not defterinin sağ üst kısmındaki durum çubuğunda oturumu durdur'u da seçebilirsiniz.

Sonraki adımlar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin