Oracle geçişleri için veri geçişi, ETL ve yükleme
Bu makale, Oracle'dan Azure Synapse Analytics'e geçiş konusunda rehberlik sağlayan yedi bölümden oluşan serinin ikinci bölümüdür. Bu makalenin odak noktası ETL ve yük geçişi için en iyi yöntemlerdir.
Veri geçişiyle ilgili dikkat edilmesi gerekenler
Eski bir Oracle veri ambarından ve veri reyonlarından Azure Synapse'e veri, ETL ve yükler geçirilirken dikkate alınması gereken birçok faktör vardır.
Oracle'dan veri geçişi hakkında ilk kararlar
Mevcut oracle ortamından geçiş yapmayı planlarken veriyle ilgili aşağıdaki soruları göz önünde bulundurun:
Kullanılmayan tablo yapıları geçirilmeli mi?
Kullanıcılar için riski ve etkiyi en aza indirmek için en iyi geçiş yaklaşımı nedir?
Veri reyonlarını geçirirken: fiziksel mi kal yoksa sanal mı kal?
Sonraki bölümlerde Oracle'dan geçiş bağlamında bu noktalar ele alınıyor.
Kullanılmayan tablolar geçirilir mi?
Yalnızca kullanımda olan tabloları geçirmek mantıklıdır. Etkin olmayan tablolar geçirilmeyecek şekilde arşivlenebilir, böylece veriler gelecekte gerekirse kullanılabilir. Belgeler güncel olmadığından, hangi tabloların kullanımda olduğunu belirlemek için belgeler yerine sistem meta verilerini ve günlük dosyalarını kullanmak en iyisidir.
Oracle sistem kataloğu tabloları ve günlükleri, belirli bir tabloya en son ne zaman erişildiğini belirlemek için kullanılabilecek bilgiler içerir. Bu bilgiler de tablonun geçiş adayı olup olmadığına karar vermek için kullanılabilir.
Oracle Tanılama Paketi'ni lisansladıysanız, bir tabloya en son ne zaman erişildiğini belirlemek için kullanabileceğiniz Etkin Oturum Geçmişi'ne erişiminiz vardır.
İpucu
Eski sistemlerde tabloların zaman içinde yedekli hale gelmesi olağan dışı değildir; çoğu durumda bunların geçirilmesi gerekmez.
Belirli bir zaman penceresinde belirli bir tablonun kullanımını arayan örnek bir sorgu aşağıda verilmiştir:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
Çok sayıda sorgu çalıştırdıysanız bu sorguyu çalıştırmak biraz zaman alabilir.
Riski ve kullanıcıları etkilemeyi en aza indirmek için en iyi geçiş yaklaşımı hangisidir?
Şirketler çevikliği artırmak için veri ambarı veri modeli üzerindeki değişikliklerin etkisini azaltmak isteyebileceğinden bu soru sık sık ortaya çıkar. Şirketler genellikle ETL geçişi sırasında verilerini daha modernleştirme veya dönüştürme fırsatı görür. Bu yaklaşım aynı anda birden çok faktörü değiştirdiğinden daha yüksek bir risk taşır ve eski sistemin sonuçlarını yeniyle karşılaştırmayı zorlaştırır. Burada veri modeli değişiklikleri yapmak, yukarı veya aşağı akış ETL işlerini diğer sistemlere de etkileyebilir. Bu risk nedeniyle, veri ambarı geçişi sonrasında bu ölçekte yeniden tasarım yapmak daha iyidir.
Bir veri modeli genel geçişin bir parçası olarak kasıtlı olarak değiştiriliyor olsa bile, yeni platformda yeniden mühendislik yapmak yerine mevcut modeli olduğu gibi Azure Synapse'e geçirmek iyi bir uygulamadır. Bu yaklaşım mevcut üretim sistemleri üzerindeki etkiyi en aza indirirken, azure platformunun tek seferlik yeniden mühendislik görevleri için performansından ve elastik ölçeklenebilirliğinden yararlanıyor.
İpucu
Gelecekte veri modelinde bir değişiklik planlansa bile mevcut modeli başlangıçta olduğu gibi geçirin.
Veri reyonu geçişi: Fiziksel olarak mı kal yoksa sanal mı kalsın?
Eski Oracle veri ambarı ortamlarında, kuruluş içindeki belirli bir departman veya iş işlevi için geçici self servis sorguları ve raporları için iyi performans sağlayacak şekilde yapılandırılmış birçok veri reyonu oluşturmak yaygın bir uygulamadır. Veri reyonları genellikle verilerin toplu sürümlerini içeren veri ambarının bir alt kümesinden oluşur ve bu sayede kullanıcılar bu verileri hızlı yanıt süreleriyle kolayca sorgular. Kullanıcılar, iş kullanıcılarının veri reyonlarıyla etkileşimlerini destekleyen Microsoft Power BI gibi kullanıcı dostu sorgu araçlarını kullanabilir. Veri reyonlarındaki verilerin biçimi genellikle boyutlu bir veri modelidir. Veri reyonlarının bir kullanımı, temel alınan ambar veri modeli veri kasası gibi farklı bir şey olsa bile verileri kullanılabilir bir biçimde kullanıma sunmadır.
Sağlam veri güvenliği rejimleri uygulamak için kuruluş içindeki tek tek iş birimleri için ayrı veri reyonları kullanabilirsiniz. Kullanıcılarla ilgili belirli veri reyonlarına erişimi kısıtlayın ve hassas verileri ortadan kaldırın, gizlenin veya anonimleştirin.
Bu veri reyonları fiziksel tablolar olarak uygulanırsa, bunları düzenli olarak derlemek ve yenilemek için ek depolama kaynaklarına ve işlemeye ihtiyaç duyarlar. Ayrıca, marttaki veriler yalnızca son yenileme işlemi kadar güncel olacaktır ve bu nedenle son derece geçici veri panoları için uygun olmayabilir.
İpucu
Veri reyonlarının sanallaştırılması, depolama ve işleme kaynaklarından tasarruf edebilir.
Azure Synapse gibi daha düşük maliyetli ölçeklenebilir MPP mimarilerinin ve bunların doğal performans özelliklerinin ortaya çıkmasıyla, reyonu bir dizi fiziksel tablo olarak örneklemeden veri reyonu işlevselliği sağlayabilirsiniz. Bir yöntem, SQL görünümleri aracılığıyla veri reyonlarını ana veri ambarı üzerinde etkili bir şekilde sanallaştırmaktır. Bir diğer yol da Azure'daki görünümler veya üçüncü taraf sanallaştırma ürünleri gibi özellikleri kullanarak bir sanallaştırma katmanı aracılığıyla veri reyonlarını sanallaştırmaktır. Bu yaklaşım ek depolama ve toplama işleme gereksinimini basitleştirir veya ortadan kaldırır ve geçirilecek veritabanı nesnelerinin toplam sayısını azaltır.
Bu yaklaşımın başka bir olası avantajı da vardır. Toplama ve birleştirme mantığını bir sanallaştırma katmanı içinde uygulayarak ve dış raporlama araçlarını sanallaştırılmış bir görünüm aracılığıyla sunarak, bu görünümleri oluşturmak için gereken işlem veri ambarı içine gönderilir. Veri ambarı genellikle büyük veri hacimlerinde birleştirmeleri, toplamaları ve diğer ilgili işlemleri çalıştırmak için en iyi yerdir.
Fiziksel veri reyonu üzerinden sanal veri reyonu uygulamak için birincil etmenler şunlardır:
Daha fazla çeviklik: Sanal veri reyonunun değiştirilmesi, fiziksel tablolara ve ilişkili ETL işlemlerine göre daha kolaydır.
Daha düşük toplam sahip olma maliyeti: Sanallaştırılmış bir uygulama için daha az veri deposu ve veri kopyası gerekir.
Sanallaştırılmış bir ortamda veri ambarı mimarisini geçirmek ve basitleştirmek için ETL işlerinin ortadan kaldırılması.
Performans: Fiziksel veri reyonları geçmişte daha iyi performans göstermiş olsa da sanallaştırma ürünleri artık bu farkı azaltmak için akıllı önbelleğe alma teknikleri uyguluyor.
İpucu
Azure Synapse'in performansı ve ölçeklenebilirliği, performansdan ödün vermeden sanallaştırmayı etkinleştirir.
Oracle'dan veri geçişi
Verilerinizi anlama
Geçiş planlamasının bir parçası olarak, geçiş yaklaşımı hakkındaki kararları etkileyebileceği için geçirilecek veri hacmini ayrıntılı olarak anlamanız gerekir. Geçirilecek tabloların içindeki ham verilerin kapladığı fiziksel alanı belirlemek için sistem meta verilerini kullanın. Bu bağlamda ham veriler, dizinler ve sıkıştırma gibi ek yükü hariç olmak üzere tablo içindeki veri satırları tarafından kullanılan alan miktarı anlamına gelir. En büyük olgu tabloları genellikle verilerin %95'inden fazlasını oluşturur.
Bu sorgu size Oracle'daki toplam veritabanı boyutunu verir:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
Veritabanı boyutu boyutuna (data files + temp files + online/offline redo log files + control files)eşittir. Genel veritabanı boyutu, kullanılan alanı ve boş alanı içerir.
Aşağıdaki örnek sorgu, tablo verileri ve dizinler tarafından kullanılan disk alanının dökümünü verir:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
Buna ek olarak, Microsoft veritabanı geçiş ekibi Oracle Inventory Script Artifacts dahil olmak üzere birçok kaynak sağlar. Oracle Inventory Script Artifacts aracı, Oracle sistem tablolarına erişen ve şema türüne, nesne türüne ve durumuna göre nesne sayısı sağlayan bir PL/SQL sorgusu içerir. Araç ayrıca her şemadaki ham verilerin kabaca tahminini ve her şemadaki tabloların boyutunu ve sonuçların CSV biçiminde depolanmasını sağlar. Dahil edilen hesap makinesi elektronik tablosu GIRIŞ olarak CSV'yi alır ve boyutlandırma verileri sağlar.
Herhangi bir tablo için, verilerin bir milyon satır gibi temsili bir örneğini sıkıştırılmamış sınırlandırılmış düz ASCII veri dosyasına ayıklayarak geçirilmesi gereken veri hacmini doğru şekilde tahmin edebilirsiniz. Ardından, satır başına ortalama ham veri boyutu elde etmek için bu dosyanın boyutunu kullanın. Son olarak, tablonun ham veri boyutunu vermek için bu ortalama boyutu tam tablodaki toplam satır sayısıyla çarpın. Planlamanızda bu ham veri boyutunu kullanın.
Veri türlerini bulmak için SQL sorgularını kullanma
Oracle statik veri sözlüğü DBA_TAB_COLUMNS görünümünü sorgulayarak şemada hangi veri türlerinin kullanıldığını ve bu veri türlerinden herhangi birinin değiştirilmesi gerekip gerekmediğini belirleyebilirsiniz. Azure Synapse'teki veri türleriyle doğrudan eşlenmeyen veri türlerine sahip herhangi bir Oracle şemasındaki sütunları bulmak için SQL sorgularını kullanın. Benzer şekilde, sorguları kullanarak her Oracle veri türünün doğrudan Azure Synapse'e eşlenmeyen oluşum sayısını sayabilirsiniz. Bu sorgulardan elde edilen sonuçları veri türü karşılaştırma tablosuyla birlikte kullanarak, Azure Synapse ortamında hangi veri türlerinin değiştirilmesi gerektiğini belirleyebilirsiniz.
Azure Synapse'te veri türleriyle eşleşmeyen veri türlerine sahip sütunları bulmak için, aşağıdaki sorguyu şemanızın ilgili sahibiyle değiştirdikten <owner_name> sonra çalıştırın:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
Eşlenemeyen veri türlerini saymak için aşağıdaki sorguyu kullanın:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft, veri türlerinin eşlemesi de dahil olmak üzere eski Oracle ortamlarından veri ambarlarının geçişini otomatikleştirmek için Oracle için SQL Server Geçiş Yardımcısı (SSMA) sunar. Oracle gibi ortamlardan geçiş planlamanıza ve gerçekleştirmenize yardımcı olması için Azure Veritabanı Geçiş Hizmeti'leri de kullanabilirsiniz. Üçüncü taraf satıcılar, geçişi otomatikleştirmek için araçlar ve hizmetler de sunar. Oracle ortamında bir üçüncü taraf ETL aracı zaten kullanılıyorsa, gerekli veri dönüştürmelerini uygulamak için bu aracı kullanabilirsiniz. Sonraki bölümde mevcut ETL işlemlerinin geçişini inceleyebilirsiniz.
ETL geçişiyle ilgili dikkat edilmesi gerekenler
Oracle ETL geçişi hakkında ilk kararlar
ETL/ELT işleme için eski Oracle veri ambarları genellikle özel olarak oluşturulmuş betikler, üçüncü taraf ETL araçları veya zaman içinde gelişen yaklaşımların bir birleşimini kullanır. Azure Synapse'e geçiş yapmayı planlarken, yeni ortamda gerekli ETL/ELT işlemeyi uygulamanın en iyi yolunu belirlerken maliyeti ve riski de en aza indirirsiniz.
İpucu
ETL geçişi yaklaşımını önceden planlayın ve uygun durumlarda Azure olanaklarından yararlanın.
Aşağıdaki akış çizelgesi bir yaklaşımı özetler:
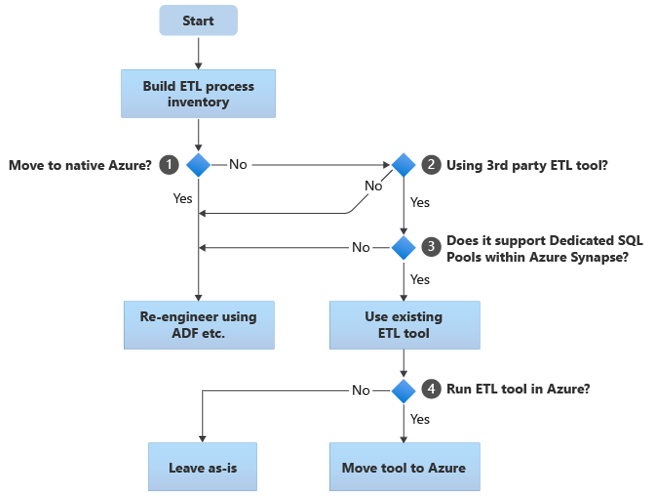
Akış çizelgesinde gösterildiği gibi, ilk adım her zaman geçirilmesi gereken ETL/ELT işlemlerinin envanterini oluşturmaktır. Standart yerleşik Azure özellikleriyle, mevcut bazı işlemlerin taşınması gerekmeyebilir. Planlama amacıyla geçişin ölçeğini anlamanız önemlidir. Ardından akış çizelgesi karar ağacındaki soruları göz önünde bulundurun:
Yerel Azure'a taşınsın mı? Yanıtınız tamamen Azure'a özel bir ortama geçiş yapıp yapmadığınız bağlıdır. Bu durumda, Azure Data Factory veya Azure Synapse işlem hatlarındaki İşlem Hatlarını ve etkinlikleri kullanarak ETL işlemede yeniden mühendislik gerçekleştirmenizi öneririz.
Üçüncü taraf ETL aracı mı kullanıyorsunuz? Tamamen Azure'a özel bir ortama geçmiyorsanız mevcut bir üçüncü taraf ETL aracının zaten kullanımda olup olmadığını denetleyin. Oracle ortamında ETL işlemenin bir kısmının veya tamamının Oracle SQL Developer, Oracle SQL*Loader veya Oracle Data Pump gibi Oracle'a özgü yardımcı programlar kullanılarak özel betikler tarafından gerçekleştirildiğini fark edebilirsiniz. Bu örnekte yaklaşım, Azure Data Factory kullanarak yeniden mühendislik yapmaktır.
Üçüncü taraf Azure Synapse içindeki ayrılmış SQL havuzlarını destekliyor mu? Üçüncü taraf ETL aracındaki becerilere büyük bir yatırım yapılıp yapılmadığını veya mevcut iş akışlarının ve zamanlamaların bu aracı kullanıp kullanmadığını göz önünde bulundurun. Bu durumda aracın hedef ortam olarak Azure Synapse'i verimli bir şekilde destekleyip desteklemediğini belirleyin. İdeal olan araç, en verimli veri yükleme için PolyBase veya COPY INTO gibi Azure olanaklarını kullanabilen yerel bağlayıcılar içerecektir. Ancak yerel bağlayıcılar olmasa bile, genellikle PolyBase veya
COPY INTOgibi dış işlemleri çağırmanın ve geçerli parametreleri geçirmenin bir yolu vardır. Bu durumda, yeni hedef ortam olarak Azure Synapse ile mevcut becerileri ve iş akışlarını kullanın.ELT işleme için Oracle Veri Tümleştiricisi (ODI) kullanıyorsanız Azure Synapse için ODI Bilgi Modüllerine ihtiyacınız vardır. Kuruluşunuzda bu modüller kullanılamıyorsa ancak ODI'niz varsa düz dosyalar oluşturmak için ODI kullanabilirsiniz. Daha sonra bu düz dosyalar Azure Synapse'e yüklenmek üzere Azure Data Lake Storage'a taşınabilir.
Azure'da ETL araçları çalıştırılsın mı? Mevcut bir üçüncü taraf ETL aracını tutmaya karar verirseniz, bu aracı Azure ortamında (mevcut bir şirket içi ETL sunucusunda değil) çalıştırabilir ve Data Factory'nin mevcut iş akışlarının genel düzenlemesini işlemesini sağlayabilirsiniz. Bu nedenle maliyet, performans ve ölçeklenebilirlik avantajları elde etmek için mevcut aracı olduğu gibi bırakıp bırakmamaya veya Azure ortamına taşımaya karar verin.
İpucu
Performans, ölçeklenebilirlik ve maliyet avantajlarından yararlanmak için Azure'da ETL araçlarını çalıştırmayı göz önünde bulundurun.
Mevcut Oracle'a özgü betikleri yeniden mühendislikle kullanma
Mevcut Oracle ambarı ETL/ELT işlemenin bir kısmı veya tamamı Oracle SQL*Plus, Oracle SQL Developer, Oracle SQL*Loader veya Oracle Data Pump gibi Oracle'a özgü yardımcı programları kullanan özel betikler tarafından işleniyorsa, bu betikleri Azure Synapse ortamı için yeniden kodlamanız gerekir. Benzer şekilde, ETL işlemleri Oracle'da saklı yordamlar kullanılarak uygulandıysa bu işlemleri yeniden kodlamanız gerekir.
ETL işleminin bazı öğelerinin geçirilmesi kolaydır; örneğin, dış dosyadan hazırlama tablosuna basit bir toplu veri yükü. Örneğin SQL*Loader yerine Azure Synapse COPY INTO veya PolyBase kullanarak işlemin bu bölümlerini otomatikleştirmek bile mümkün olabilir. İşlemin rastgele karmaşık SQL ve/veya saklı yordamlar içeren diğer bölümlerinin yeniden mühendislik işlemi daha uzun sürer.
İpucu
Geçirilecek ETL görevlerinin envanteri betikleri ve saklı yordamları içermelidir.
Oracle SQL'i Azure Synapse ile uyumluluk açısından test etmenin bir yolu, Oracle'ın v$active_session_history bir birleşiminden bazı temsili SQL deyimlerini yakalamak ve almak sql_textve v$sql ardından bu sorgulara ön ekini eklemektirEXPLAIN. Azure Synapse'te benzer bir geçirilen veri modeli olduğunu varsayarsak, bu EXPLAIN deyimleri Azure Synapse'te çalıştırın. Uyumsuz tüm SQL'ler hata verir. Bu bilgileri, kodlama görevinin ölçeğini belirlemek için kullanabilirsiniz.
İpucu
SQL uyumsuzluklarını bulmak için kullanın EXPLAIN .
En kötü durumda el ile geri kodlama gerekebilir. Ancak, Microsoft iş ortaklarının Oracle'a özgü kodu yeniden mühendislik konusunda yardımcı olması için kullanabileceğiniz ürünler ve hizmetler vardır.
İpucu
İş ortakları, Oracle'a özgü kodun yeniden mühendisliğine yardımcı olacak ürünler ve beceriler sunar.
Mevcut üçüncü taraf ETL araçlarını kullanma
Çoğu durumda, mevcut eski veri ambarı sistemi zaten bir üçüncü taraf ETL ürünü tarafından doldurulur ve korunur. Azure Synapse için geçerli Microsoft veri tümleştirme iş ortaklarının listesi için bkz. Azure Synapse Analytics veri tümleştirme iş ortakları.
Oracle topluluğu sık sık birkaç popüler ETL ürünü kullanır. Aşağıdaki paragraflarda Oracle ambarları için en popüler ETL araçları açıklanır. Bu ürünlerin tümünü Azure'daki bir VM'de çalıştırabilir ve Azure veritabanlarını ve dosyalarını okumak ve yazmak için kullanabilirsiniz.
İpucu
Maliyeti ve riski azaltmak için mevcut üçüncü taraf araçlarına yatırımdan yararlanın.
Oracle'dan veri yükleme
Oracle'dan veri yüklerken kullanılabilen seçenekler
Oracle veri ambarından veri geçirmeye hazırlanırken, verilerin mevcut şirket içi ortamdan bulutta Azure Synapse'e fiziksel olarak nasıl taşınacağını ve aktarım ve yüklemeyi gerçekleştirmek için hangi araçların kullanılacağına karar verin. Aşağıdaki bölümlerde ele alınan aşağıdaki soruları göz önünde bulundurun.
Verileri dosyalara mı ayıklayacaksınız yoksa doğrudan bir ağ bağlantısı üzerinden mi taşıyacaksınız?
İşlemi kaynak sistemden mi yoksa Azure hedef ortamından mı düzenleyeceksiniz?
Geçiş işlemini otomatikleştirmek ve yönetmek için hangi araçları kullanacaksınız?
Dosyalar veya ağ bağlantısı aracılığıyla veri aktarılasın mı?
Geçirilecek veritabanı tabloları Azure Synapse'te oluşturulduktan sonra, bu tabloları dolduran verileri eski Oracle sisteminin dışına ve yeni ortama taşıyabilirsiniz. İki temel yaklaşım vardır:
Dosya Ayıklama: Oracle tablolarındaki verileri normalde CSV biçiminde düz sınırlandırılmış dosyalara ayıklayın. Tablo verilerini çeşitli yollarla ayıklayabilirsiniz:
- SQL*Plus, SQL Geliştirici ve SQLcl gibi standart Oracle araçlarını kullanın.
- Düz dosyalar oluşturmak için Oracle Veri Tümleştiricisi'ni (ODI) kullanın.
- Bölümlere göre veri yüklemeyi etkinleştirmek üzere Oracle tablolarını paralel olarak kaldırmak için Data Factory'de Oracle bağlayıcısını kullanın.
- Üçüncü taraf ETL aracı kullanın.
Oracle tablo verilerini ayıklama örnekleri için ek makaleye bakın.
Bu yaklaşım, ayıklanan veri dosyalarını almak için alan gerektirir. Yeterli depolama alanı varsa, alan Oracle kaynak veritabanında yerel veya Azure Blob Depolama uzak olabilir. En iyi performans, ağ ek yükünü önlediğinden bir dosya yerel olarak yazıldığında elde edilir.
Depolama ve ağ aktarımı gereksinimlerini en aza indirmek için gzip gibi bir yardımcı program kullanarak ayıklanan veri dosyalarını sıkıştırın.
Ayıklamadan sonra düz dosyaları Azure Blob Depolama taşıyın. Microsoft, büyük hacimli verileri taşımak için aşağıdakiler dahil olmak üzere çeşitli seçenekler sunar:
- Dosyaları ağ üzerinden Azure Depolama'ya taşımak için AzCopy .
- Toplu verileri özel ağ bağlantısı üzerinden taşımak için Azure ExpressRoute .
- Dosyaları yüklemek üzere bir Azure veri merkezine sevk ettiğiniz fiziksel bir depolama cihazına taşımak için Azure Data Box .
Daha fazla bilgi için bkz . Azure'a ve Azure'dan veri aktarma.
Ağ üzerinden doğrudan ayıklama ve yükleme: Hedef Azure ortamı normalde SQL komutu aracılığıyla verileri ayıklamak için eski Oracle sistemine bir veri ayıklama isteği gönderir. Sonuçlar ağ üzerinden gönderilir ve verileri ara dosyalara aktarmaya gerek olmadan doğrudan Azure Synapse'e yüklenir. Bu senaryoda sınırlayıcı faktör normalde Oracle veritabanı ile Azure ortamı arasındaki ağ bağlantısının bant genişliğidir. Olağanüstü büyük veri hacimleri için bu yaklaşım pratik olmayabilir.
İpucu
Bu faktörler geçiş yaklaşımı kararını etkilediğinden geçirilecek veri hacimlerini ve kullanılabilir ağ bant genişliğini anlayın.
Ayrıca her iki yöntemi de kullanan karma bir yaklaşım vardır. Örneğin, Azure Synapse'te hızlı bir şekilde bir test ortamı sağlamak için daha küçük boyut tabloları ve daha büyük olgu tablolarının örnekleri için doğrudan ağ ayıklama yaklaşımını kullanabilirsiniz. Büyük hacimli geçmiş olgu tabloları için Azure Data Box kullanarak dosya ayıklama ve aktarma yaklaşımını kullanabilirsiniz.
Oracle'dan mı yoksa Azure'dan mı düzenleme?
Azure Synapse'e geçiş yaparken önerilen yaklaşım, SSMA veya Data Factory kullanarak Azure ortamından veri ayıklamayı ve yüklemeyi yönetmektir. En verimli veri yükleme için PolyBase veya COPY INTOgibi ilişkili yardımcı programları kullanın. Bu yaklaşım, yerleşik Azure özelliklerinden yararlanır ve yeniden kullanılabilir veri yükü işlem hatları oluşturma çabasını azaltır. Geçiş işlemini otomatikleştirmek için meta veri temelli veri yükleme işlem hatlarını kullanabilirsiniz.
Önerilen yaklaşım, yönetim ve yükleme işlemi Azure'da çalıştırıldığından, veri yükleme işlemi sırasında mevcut Oracle ortamındaki performans isabetini de en aza indirir.
Mevcut veri geçiş araçları
Veri dönüştürme ve taşıma, tüm ETL ürünlerinin temel işlevidir. Veri geçiş aracı mevcut Oracle ortamında zaten kullanılıyorsa ve hedef ortam olarak Azure Synapse'i destekliyorsa, veri geçişini basitleştirmek için bu aracı kullanmayı göz önünde bulundurun.
Mevcut bir ETL aracı mevcut olmasa bile Azure Synapse Analytics veri tümleştirme iş ortakları, veri geçişi görevini basitleştirmek için ETL araçları sunar.
Son olarak, bir ETL aracı kullanmayı planlıyorsanız Azure bulut performansı, ölçeklenebilirlik ve maliyet avantajlarından yararlanmak için bu aracı Azure ortamında çalıştırmayı göz önünde bulundurun. Bu yaklaşım oracle veri merkezindeki kaynakları da boşaltıyor.
Özet
Özetlemek gerekirse, verileri ve ilişkili ETL işlemlerini Oracle'dan Azure Synapse'e geçirme önerilerimiz şunlardır:
Başarılı bir geçiş alıştırması yapmak için önceden plan yapın.
En kısa sürede geçirilecek verilerin ve işlemlerin ayrıntılı bir envanterini oluşturun.
Verileri ve işlem kullanımını doğru bir şekilde anlamak için sistem meta verilerini ve günlük dosyalarını kullanın. Güncel olmayabileceği için belgelere güvenmeyin.
Geçirilecek veri birimlerini ve şirket içi veri merkezi ile Azure bulut ortamları arasındaki ağ bant genişliğini anlayın.
Eski Oracle ortamından geçişi boşaltmak için Azure VM'de bir Oracle örneğini adımlama taşı olarak kullanmayı göz önünde bulundurun.
Geçiş iş yükünü en aza indirmek için standart yerleşik Azure özelliklerini kullanın.
Hem Oracle hem de Azure ortamlarında veri ayıklama ve yükleme için en verimli araçları belirleyin ve anlayın. İşlemin her aşamasında uygun araçları kullanın.
Oracle sistemi üzerindeki etkiyi en aza indirirken geçiş işlemini düzenleyip otomatikleştirmek için Data Factory gibi Azure olanaklarını kullanın.
Ek: Oracle verilerini ayıklama teknikleri örnekleri
Oracle'dan Azure Synapse'e geçiş yaparken Oracle verilerini ayıklamak için çeşitli teknikler kullanabilirsiniz. Sonraki bölümlerde Oracle SQL Developer'ı ve Data Factory'deki Oracle bağlayıcısını kullanarak Oracle verilerini ayıklama gösterilmektedir.
Veri ayıklama için Oracle SQL Developer kullanma
Aşağıdaki ekran görüntüsünde gösterildiği gibi tablo verilerini CSV gibi birçok biçime aktarmak için Oracle SQL Geliştirici kullanıcı arabirimini kullanabilirsiniz:

Diğer dışarı aktarma seçenekleri arasında JSON ve XML bulunur. Kullanıcı arabirimini kullanarak bir "sepete" tablo adları kümesi ekleyebilir ve ardından dışarı aktarma işlemini sepetteki kümenin tamamına uygulayabilirsiniz:

Oracle verilerini dışarı aktarmak için Oracle SQL Geliştirici Komut Satırı'nı (SQLcl) de kullanabilirsiniz. Bu seçenek, kabuk betiği kullanarak otomasyonu destekler.
Nispeten küçük tablolar için, doğrudan bağlantı üzerinden veri ayıklama sorunlarıyla karşılaşırsanız bu tekniği yararlı bulabilirsiniz.
Paralel kopyalama için Azure Data Factory'de Oracle bağlayıcısını kullanma
Büyük Oracle tablolarını paralel olarak kaldırmak için Data Factory'deki Oracle bağlayıcısını kullanabilirsiniz. Oracle bağlayıcısı, Oracle'dan paralel olarak veri kopyalamak için yerleşik veri bölümleme sağlar. Veri bölümleme seçeneklerini kopyalama etkinliğinin Kaynak sekmesinde bulabilirsiniz.

Oracle bağlayıcısını paralel kopyalama için yapılandırma hakkında bilgi için bkz . Oracle'dan paralel kopyalama.
Data Factory kopyalama etkinliği performansı ve ölçeklenebilirliği hakkında daha fazla bilgi için Kopyalama etkinliği performans ve ölçeklenebilirlik kılavuzuna bakın.
Sonraki adımlar
Güvenlik erişim işlemleri hakkında bilgi edinmek için bu serinin sonraki makalesine bakın: Oracle geçişleri için güvenlik, erişim ve işlemler.