Öğretici: Synapse Studio'da Apache Spark iş tanımı oluşturma
Bu öğreticide Synapse Studio'yu kullanarak Apache Spark iş tanımları oluşturma ve bunları sunucusuz apache Spark havuzuna gönderme işlemleri gösterilmektedir.
Bu öğretici aşağıdaki görevleri kapsar:
- PySpark için Apache Spark iş tanımı oluşturma (Python)
- Spark için Apache Spark iş tanımı oluşturma (Scala)
- .NET Spark için Apache Spark iş tanımı oluşturma (C#/F#)
- JSON dosyasını içeri aktararak iş tanımı oluşturma
- Apache Spark iş tanımı dosyasını yerel olarak dışarı aktarma
- Apache Spark iş tanımını toplu iş olarak gönderme
- İşlem hattına Apache Spark iş tanımı ekleme
Önkoşullar
Bu öğreticiye başlamadan önce aşağıdaki gereksinimlerin karşılandığından emin olun:
- Azure Synapse Analytics çalışma alanı. Yönergeler için bkz . Azure Synapse Analytics çalışma alanı oluşturma.
- Sunucusuz bir Apache Spark havuzu.
- AdLS 2. Nesil depolama hesabı. Çalışmak istediğiniz ADLS 2. Nesil dosya sisteminin Depolama Blob Verileri Katkıda Bulunanı olmanız gerekir. Değilseniz, izni el ile eklemeniz gerekir.
- Çalışma alanı varsayılan depolama alanını kullanmak istemiyorsanız Synapse Studio'da gerekli ADLS 2. Nesil depolama hesabını bağlayın.
PySpark için Apache Spark iş tanımı oluşturma (Python)
Bu bölümde PySpark (Python) için bir Apache Spark iş tanımı oluşturacaksınız.
Synapse Studio'yu açın.
python.zip için örnek dosyaları indirmek, sıkıştırılmış paketin sıkıştırmasını açmak ve wordcount.py ve shakespeare.txt dosyalarını ayıklamak üzere Apache Spark iş tanımları oluşturmak için örnek dosyalar'a gidebilirsiniz.
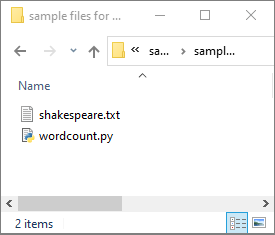
Veri -Bağlı ->>Azure Data Lake Storage 2. Nesil'ı seçin ve wordcount.py ve shakespeare.txt ADLS 2. Nesil dosya sisteminize yükleyin.
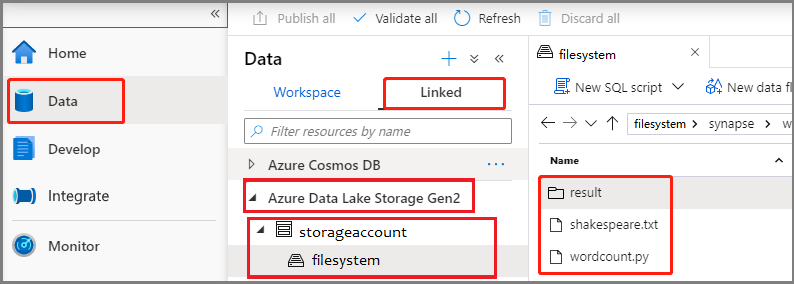
Yeni bir Spark iş tanımı oluşturmak için Hub geliştir'i seçin, '+' simgesini seçin ve Spark iş tanımı'nı seçin.
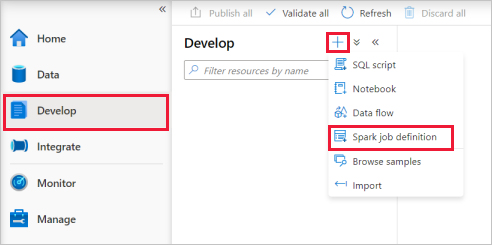
Apache Spark iş tanımı ana penceresindeki Dil açılan listesinden PySpark (Python) öğesini seçin.
Apache Spark iş tanımı bilgilerini doldurun.
Özellik Açıklama İş tanımı adı Apache Spark iş tanımınız için bir ad girin. Bu ad, yayımlanana kadar herhangi bir zamanda güncelleştirilebilir.
Örnek:job definition sampleAna tanım dosyası İş için kullanılan ana dosya. Depolama alanınızdan bir PY dosyası seçin. Dosyayı bir depolama hesabına yüklemek için Dosyayı karşıya yükle'yi seçebilirsiniz.
Örnek:abfss://…/path/to/wordcount.pyKomut satırı bağımsız değişkenleri İşin isteğe bağlı bağımsız değişkenleri.
Örnek:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Not: Örnek iş tanımı için iki bağımsız değişken bir boşlukla ayrılır.Başvuru dosyaları Ana tanım dosyasında başvuru için kullanılan ek dosyalar. Dosyayı bir depolama hesabına yüklemek için Dosyayı karşıya yükle'yi seçebilirsiniz. Spark havuzu İş seçilen Apache Spark havuzuna gönderilir. Spark sürümü Apache Spark havuzunun çalıştırılan Apache Spark sürümü. Yürütücüler İş için belirtilen Apache Spark havuzunda verilecek yürütücü sayısı. Yürütücü boyutu İş için belirtilen Apache Spark havuzunda verilen yürütücüler için kullanılacak çekirdek ve bellek sayısı. Sürücü boyutu İş için belirtilen Apache Spark havuzunda verilen sürücü için kullanılacak çekirdek ve bellek sayısı. Apache Spark yapılandırması Aşağıdaki özellikleri ekleyerek yapılandırmaları özelleştirin. Özellik eklemezseniz Azure Synapse, uygun olduğunda varsayılan değeri kullanır. 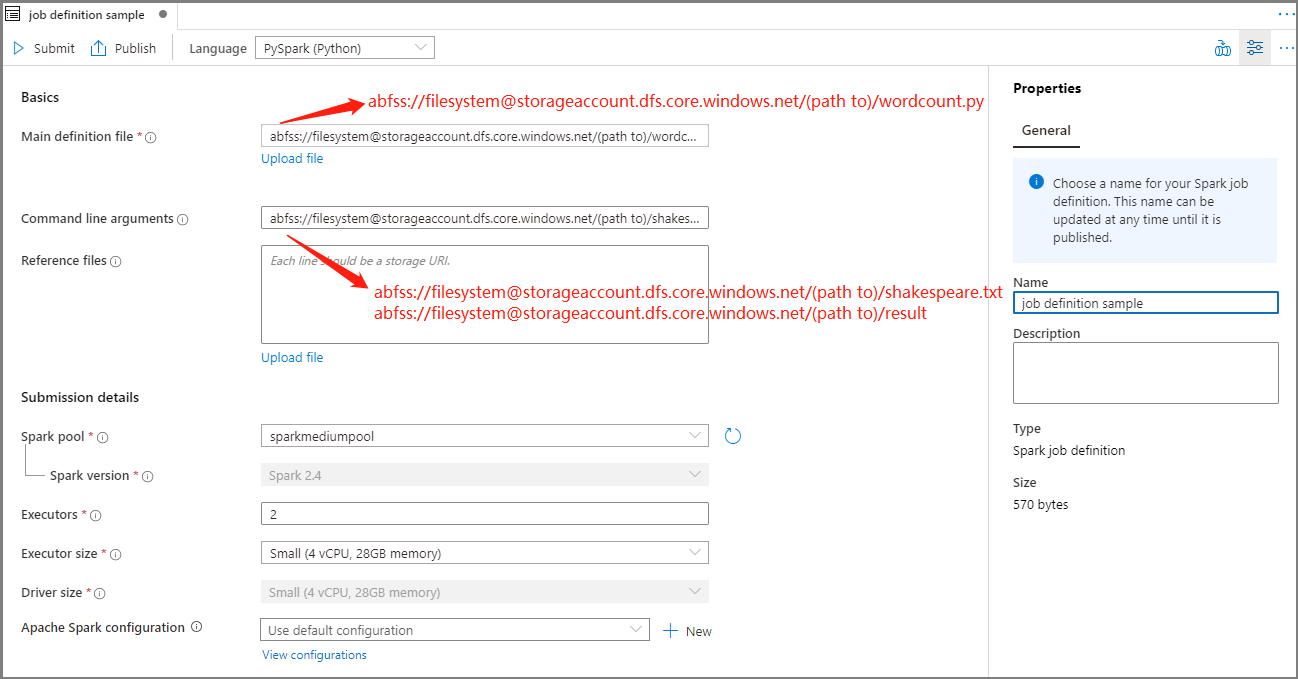
Apache Spark iş tanımını kaydetmek için Yayımla'yı seçin.

Apache Spark için Apache Spark iş tanımı oluşturma (Scala)
Bu bölümde, Apache Spark (Scala) için bir Apache Spark iş tanımı oluşturacaksınız.
Azure Synapse Studio'yu açın.
scala.zip için örnek dosyaları indirmek, sıkıştırılmış paketin sıkıştırmasını açmak ve wordcount.jar ve shakespeare.txt dosyalarını ayıklamak için Apache Spark iş tanımları oluşturmak için örnek dosyalar'a gidebilirsiniz.
Veri -Bağlı ->>Azure Data Lake Storage 2. Nesil'ı seçin ve wordcount.jar ve shakespeare.txt ADLS 2. Nesil dosya sisteminize yükleyin.
Yeni bir Spark iş tanımı oluşturmak için Hub geliştir'i seçin, '+' simgesini seçin ve Spark iş tanımı'nı seçin. (Örnek görüntü 4. adımla aynıdırPySpark için Apache Spark iş tanımı (Python) oluşturun.)
Apache Spark iş tanımı ana penceresindeki Dil açılan listesinden Spark(Scala) öğesini seçin.
Apache Spark iş tanımı bilgilerini doldurun. Örnek bilgileri kopyalayabilirsiniz.
Özellik Açıklama İş tanımı adı Apache Spark iş tanımınız için bir ad girin. Bu ad, yayımlanana kadar herhangi bir zamanda güncelleştirilebilir.
Örnek:scalaAna tanım dosyası İş için kullanılan ana dosya. Depolama alanınızdan bir JAR dosyası seçin. Dosyayı bir depolama hesabına yüklemek için Dosyayı karşıya yükle'yi seçebilirsiniz.
Örnek:abfss://…/path/to/wordcount.jarAna sınıf adı Tam tanımlayıcı veya ana tanım dosyasındaki ana sınıf.
Örnek:WordCountKomut satırı bağımsız değişkenleri İşin isteğe bağlı bağımsız değişkenleri.
Örnek:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Not: Örnek iş tanımı için iki bağımsız değişken bir boşlukla ayrılır.Başvuru dosyaları Ana tanım dosyasında başvuru için kullanılan ek dosyalar. Dosyayı bir depolama hesabına yüklemek için Dosyayı karşıya yükle'yi seçebilirsiniz. Spark havuzu İş seçilen Apache Spark havuzuna gönderilir. Spark sürümü Apache Spark havuzunun çalıştırılan Apache Spark sürümü. Yürütücüler İş için belirtilen Apache Spark havuzunda verilecek yürütücü sayısı. Yürütücü boyutu İş için belirtilen Apache Spark havuzunda verilen yürütücüler için kullanılacak çekirdek ve bellek sayısı. Sürücü boyutu İş için belirtilen Apache Spark havuzunda verilen sürücü için kullanılacak çekirdek ve bellek sayısı. Apache Spark yapılandırması Aşağıdaki özellikleri ekleyerek yapılandırmaları özelleştirin. Özellik eklemezseniz Azure Synapse, uygun olduğunda varsayılan değeri kullanır. 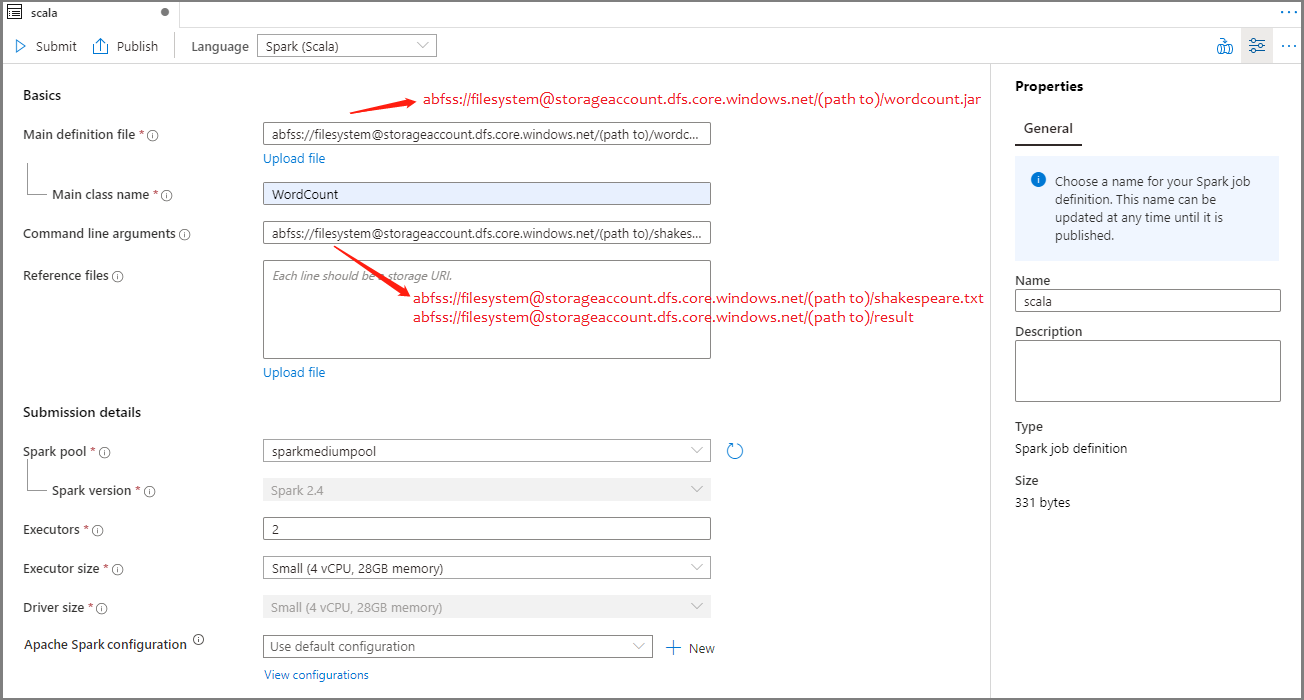
Apache Spark iş tanımını kaydetmek için Yayımla'yı seçin.

.NET Spark için Apache Spark iş tanımı oluşturma(C#/F#)
Bu bölümde,.NET Spark(C#/F#) için bir Apache Spark iş tanımı oluşturacaksınız.
Azure Synapse Studio'yu açın.
dotnet.zip için örnek dosyaları indirmek, sıkıştırılmış paketin sıkıştırmasını açmak ve wordcount.zip ve shakespeare.txt dosyalarını ayıklamak üzere Apache Spark iş tanımları oluşturmak için örnek dosyalar'a gidebilirsiniz.
Veri -Bağlı ->>Azure Data Lake Storage 2. Nesil'ı seçin ve wordcount.zip ve shakespeare.txt ADLS 2. Nesil dosya sisteminize yükleyin.
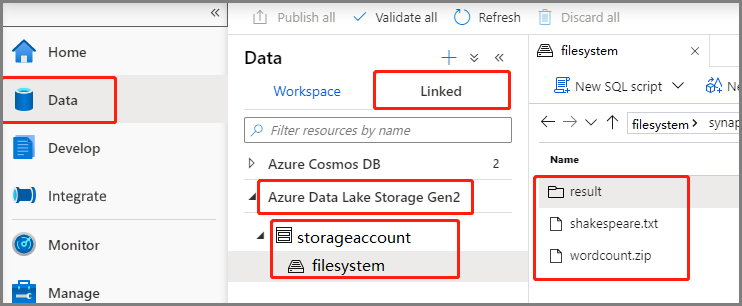
Yeni bir Spark iş tanımı oluşturmak için Hub geliştir'i seçin, '+' simgesini seçin ve Spark iş tanımı'nı seçin. (Örnek görüntü 4. adımla aynıdırPySpark için Apache Spark iş tanımı (Python) oluşturun.)
Apache Spark İş Tanımı ana penceresindeki Dil açılan listesinden .NET Spark(C#/F#) öğesini seçin.
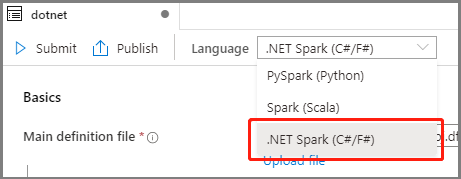
Apache Spark İş Tanımı bilgilerini doldurun. Örnek bilgileri kopyalayabilirsiniz.
Özellik Açıklama İş tanımı adı Apache Spark iş tanımınız için bir ad girin. Bu ad, yayımlanana kadar herhangi bir zamanda güncelleştirilebilir.
Örnek:dotnetAna tanım dosyası İş için kullanılan ana dosya. Depolama alanınızdan Apache Spark için .NET uygulamanızı (ana yürütülebilir dosya, kullanıcı tanımlı işlevleri içeren DLL'ler ve diğer gerekli dosyaları) içeren bir ZIP dosyası seçin. Dosyayı bir depolama hesabına yüklemek için Dosyayı karşıya yükle'yi seçebilirsiniz.
Örnek:abfss://…/path/to/wordcount.zipAna yürütülebilir dosya Ana tanım ZIP dosyasındaki ana yürütülebilir dosya.
Örnek:WordCountKomut satırı bağımsız değişkenleri İşin isteğe bağlı bağımsız değişkenleri.
Örnek:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Not: Örnek iş tanımı için iki bağımsız değişken bir boşlukla ayrılır.Başvuru dosyaları Ana tanım ZIP dosyasına (bağımlı jar'lar, ek kullanıcı tanımlı işlev DLL'leri ve diğer yapılandırma dosyaları) dahil olmayan Apache Spark uygulaması için .NET'i yürütmek için çalışan düğümleri tarafından gereken ek dosyalar. Dosyayı bir depolama hesabına yüklemek için Dosyayı karşıya yükle'yi seçebilirsiniz. Spark havuzu İş seçilen Apache Spark havuzuna gönderilir. Spark sürümü Apache Spark havuzunun çalıştırılan Apache Spark sürümü. Yürütücüler İş için belirtilen Apache Spark havuzunda verilecek yürütücü sayısı. Yürütücü boyutu İş için belirtilen Apache Spark havuzunda verilen yürütücüler için kullanılacak çekirdek ve bellek sayısı. Sürücü boyutu İş için belirtilen Apache Spark havuzunda verilen sürücü için kullanılacak çekirdek ve bellek sayısı. Apache Spark yapılandırması Aşağıdaki özellikleri ekleyerek yapılandırmaları özelleştirin. Özellik eklemezseniz Azure Synapse, uygun olduğunda varsayılan değeri kullanır. 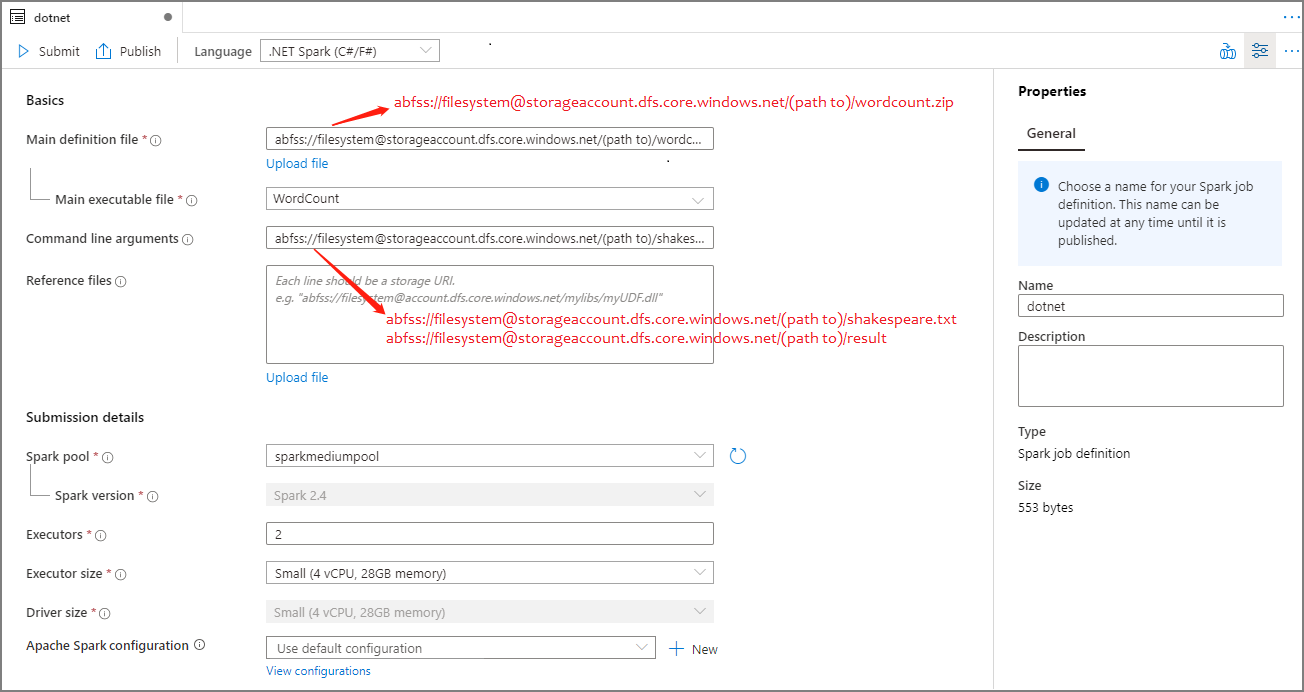
Apache Spark iş tanımını kaydetmek için Yayımla'yı seçin.

Not
Apache Spark yapılandırması için Apache Spark yapılandırması Apache Spark iş tanımı özel bir şey yapmazsa, işi çalıştırırken varsayılan yapılandırma kullanılır.
JSON dosyasını içeri aktararak Apache Spark iş tanımı oluşturma
Yeni bir Apache Spark iş tanımı oluşturmak için Apache Spark iş tanımı Gezgini'nin Eylemler (...) menüsünden mevcut bir yerel JSON dosyasını Azure Synapse çalışma alanına aktarabilirsiniz.
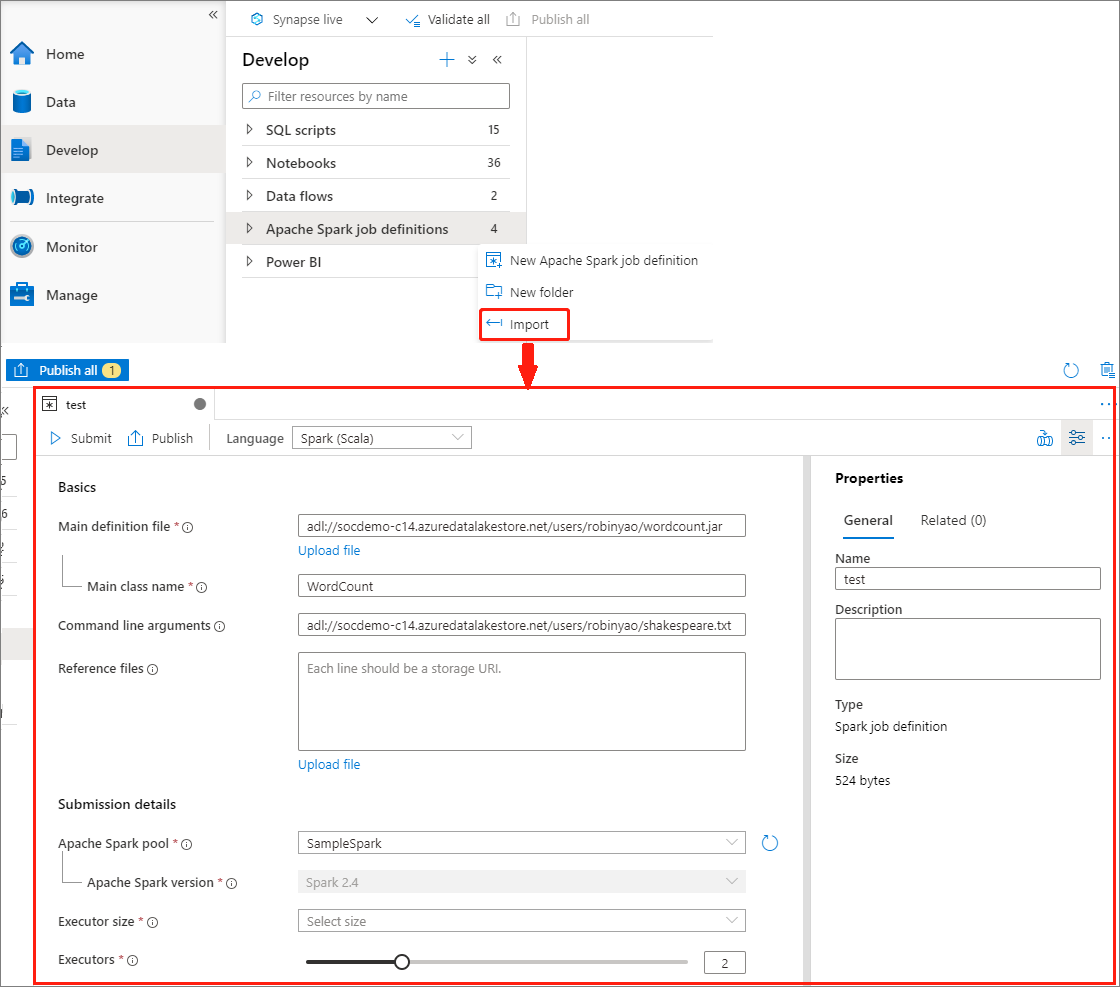
Spark iş tanımı Livy API ile tamamen uyumludur. Yerel JSON dosyasına diğer Livy özellikleri (Livy Docs - REST API (apache.org) için ek parametreler ekleyebilirsiniz. Spark yapılandırmasıyla ilgili parametreleri aşağıda gösterildiği gibi yapılandırma özelliğinde de belirtebilirsiniz. Ardından JSON dosyasını içeri aktararak toplu işiniz için yeni bir Apache Spark iş tanımı oluşturabilirsiniz. Spark tanımı içeri aktarma için örnek JSON:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
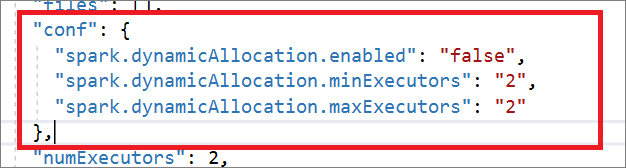
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
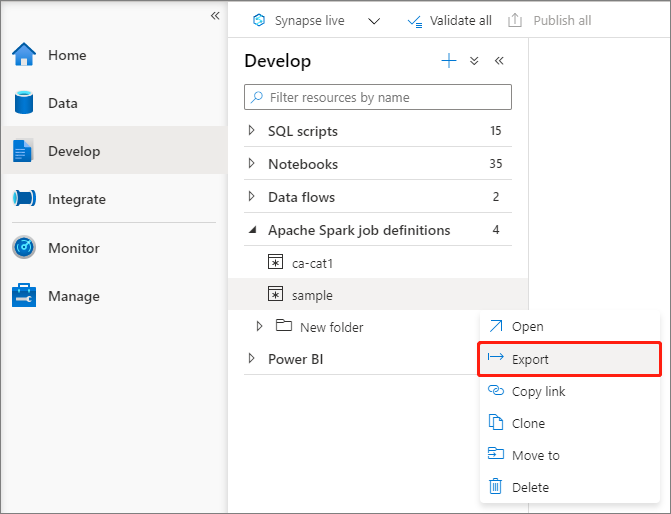
Mevcut bir Apache Spark iş tanımı dosyasını dışarı aktarma
Mevcut Apache Spark iş tanımı dosyalarını Dosya Gezgini Eylemler (...) menüsünden yerel olarak dışarı aktarabilirsiniz. Ek Livy özellikleri için JSON dosyasını daha fazla güncelleştirebilir ve gerekirse yeni iş tanımı oluşturmak üzere içeri aktarabilirsiniz.
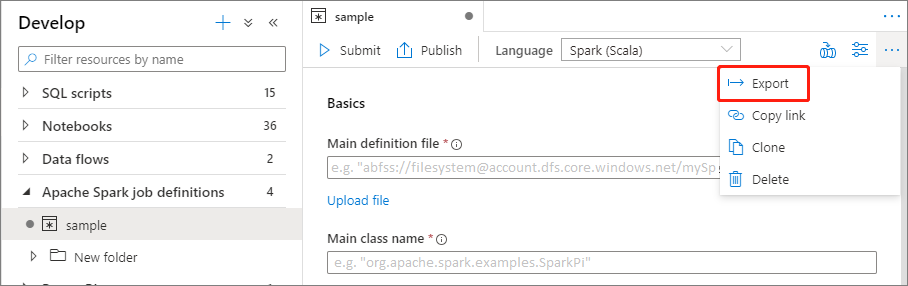
Apache Spark iş tanımını toplu iş olarak gönderme
Apache Spark iş tanımı oluşturduktan sonra bir Apache Spark havuzuna gönderebilirsiniz. Çalışmak istediğiniz ADLS 2. Nesil dosya sisteminin Depolama Blob Verileri Katkıda Bulunanı olduğunuzdan emin olun. Değilseniz, izni el ile eklemeniz gerekir.
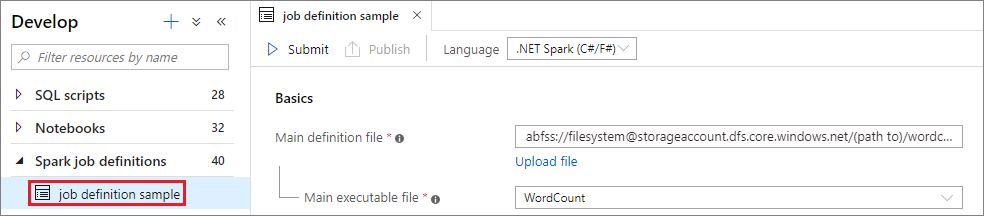
Senaryo 1: Apache Spark iş tanımını gönderme
Apache spark iş tanımı penceresini seçerek açın.
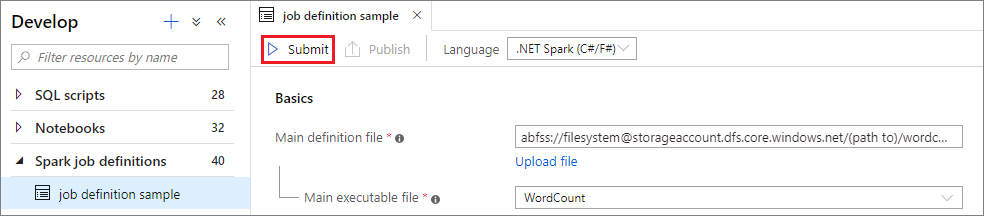
Projenizi seçili Apache Spark Havuzu'na göndermek için Gönder düğmesini seçin. Apache Spark uygulamasının LogQuery'sini görmek için Spark izleme URL'si sekmesini seçebilirsiniz.
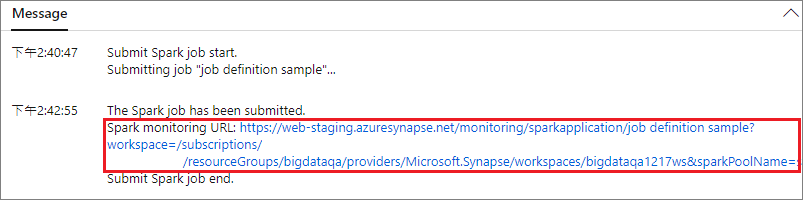
Senaryo 2: İlerleme durumunu çalıştıran Apache Spark işini görüntüleme
İzleyici'yi ve ardından Apache Spark uygulamaları seçeneğini belirleyin. Gönderilen Apache Spark uygulamasını bulabilirsiniz.
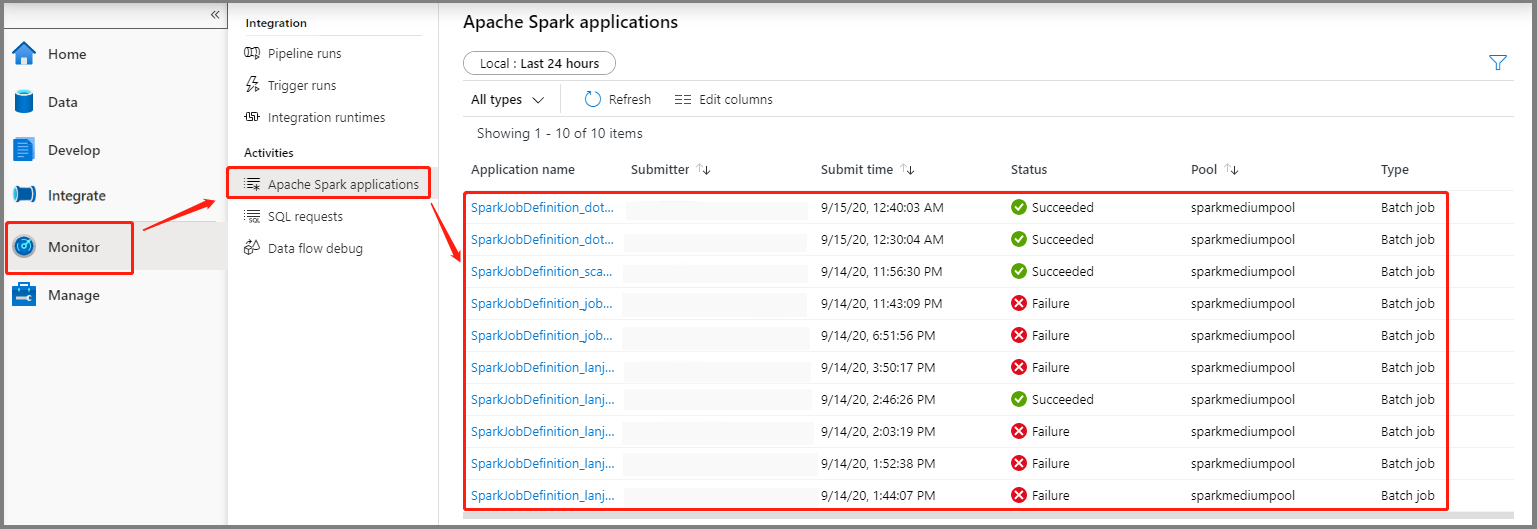
Ardından bir Apache Spark uygulaması seçtiğinizde SparkJobDefinition iş penceresi görüntülenir. İş yürütme ilerleme durumunu buradan görüntüleyebilirsiniz.
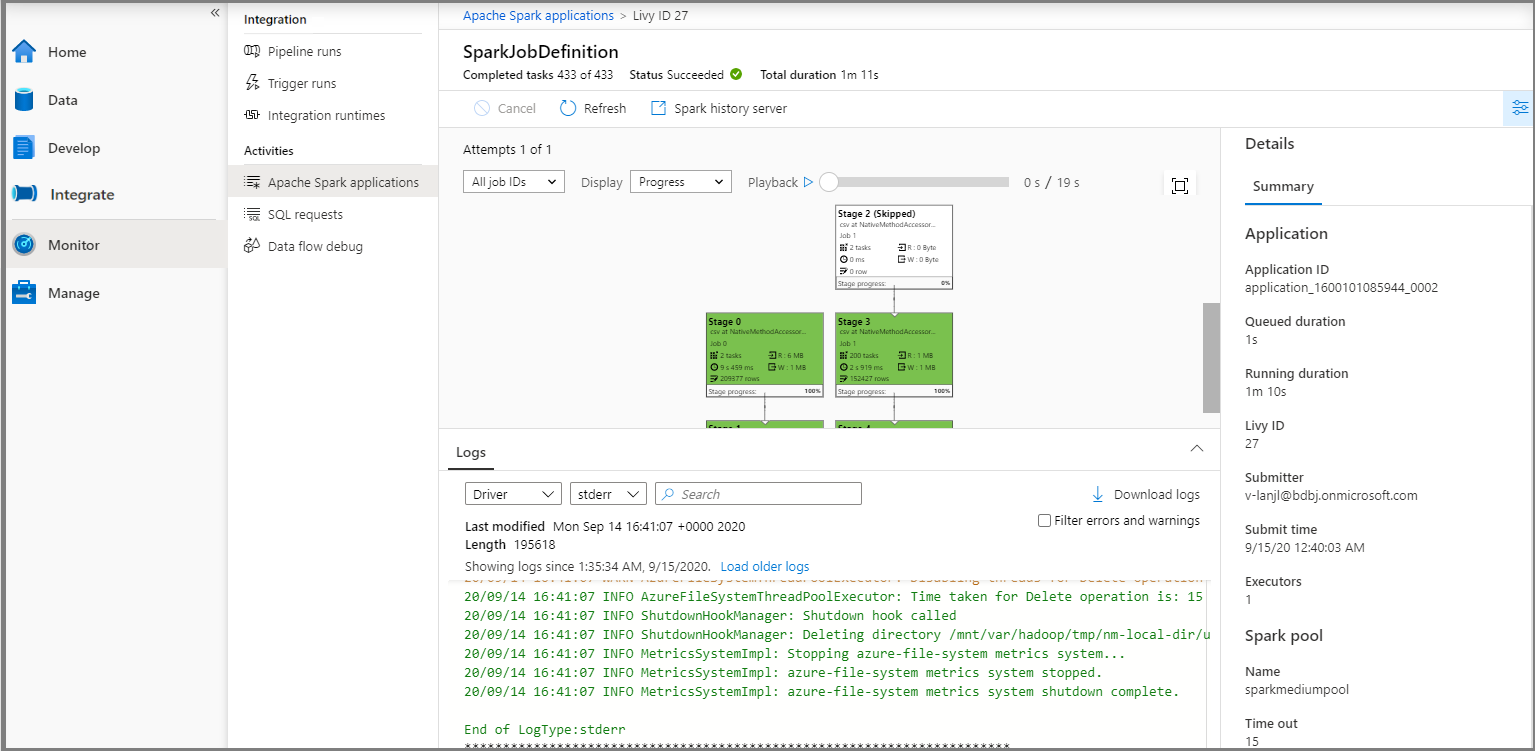
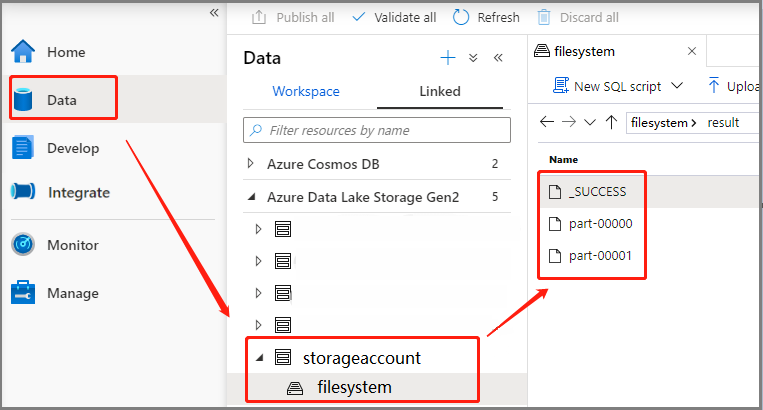
Senaryo 3: Çıkış dosyasını denetleme
Veri -Bağlı ->>Azure Data Lake Storage 2. Nesil (hozhaobdbj) öğesini seçin, daha önce oluşturulan sonuç klasörünü açın, sonuç klasörüne gidip çıkışın oluşturulup oluşturulmadiğini kontrol edebilirsiniz.
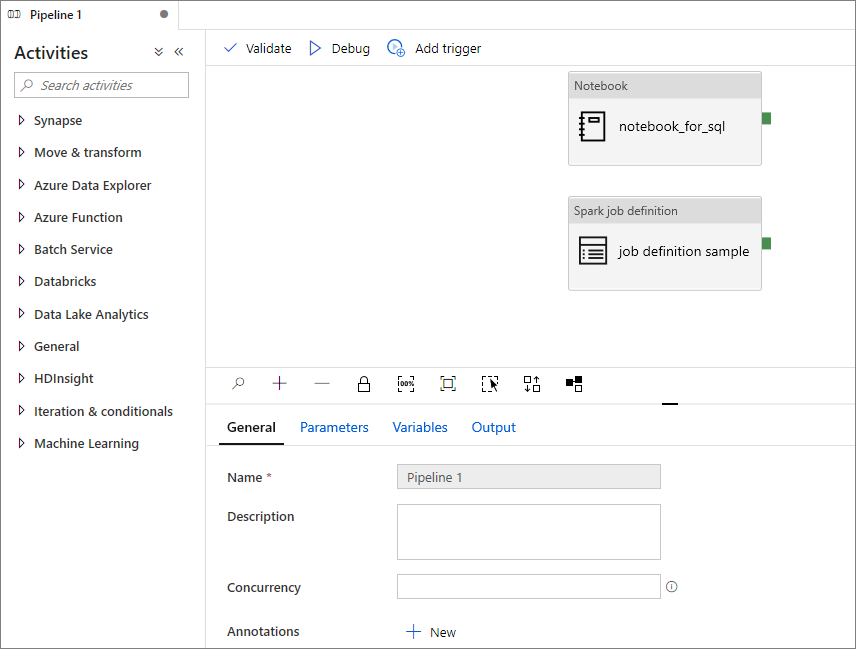
İşlem hattına Apache Spark iş tanımı ekleme
Bu bölümde, işlem hattına bir Apache Spark iş tanımı eklersiniz.
Mevcut bir Apache Spark iş tanımını açın.
Apache Spark iş tanımının sağ üst kısmındaki simgeyi seçin, Mevcut İşlem Hattı'nı veya Yeni işlem hattı'nı seçin. Daha fazla bilgi için İşlem Hattı sayfasına başvurabilirsiniz.
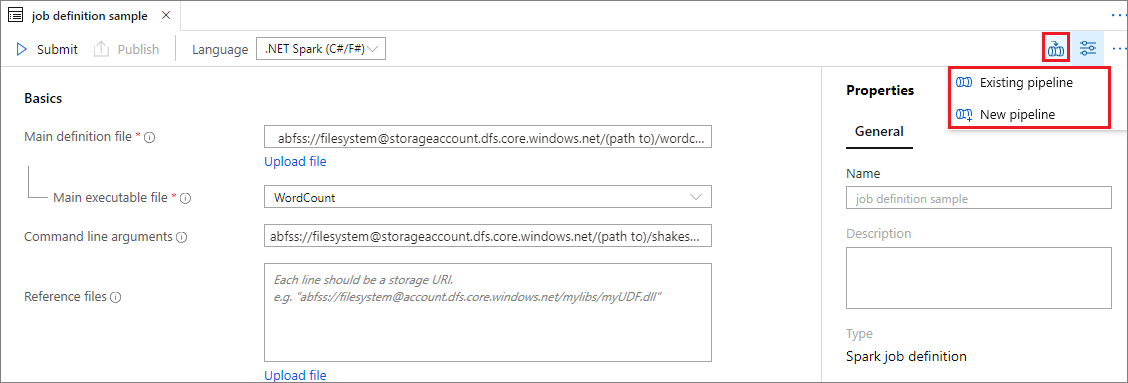
Sonraki adımlar
Ardından Azure Synapse Studio'yu kullanarak Power BI veri kümeleri oluşturabilir ve Power BI verilerini yönetebilirsiniz. Daha fazla bilgi edinmek için Power BI çalışma alanını Synapse çalışma alanına bağlama makalesine ilerleyin.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin