Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Tip
Microsoft Fabric Data Warehouse geleceğe hazır mimariye, yerleşik yapay zekaya ve yeni özelliklere sahip data lake foundation üzerinde kurumsal ölçekli ilişkisel bir ambardır. Veri ambarı konusunda yeniyseniz Fabric Data Warehouse ile başlayın. Mevcut özel SQL havuzu iş yükleri, veri bilimi, gerçek zamanlı analiz ve raporlama genelinde yeni özelliklere erişmek için Fabric yükseltilebilir.
Bu bilgi sayfası, ayrılmış SQL havuzu (eski adı SQL DW) çözümleri oluşturmaya yönelik yararlı ipuçları ve en iyi yöntemler sağlar.
Aşağıdaki grafikte ayrılmış SQL havuzuyla (eski adı SQL DW) veri ambarı tasarlama işlemi gösterilmektedir:
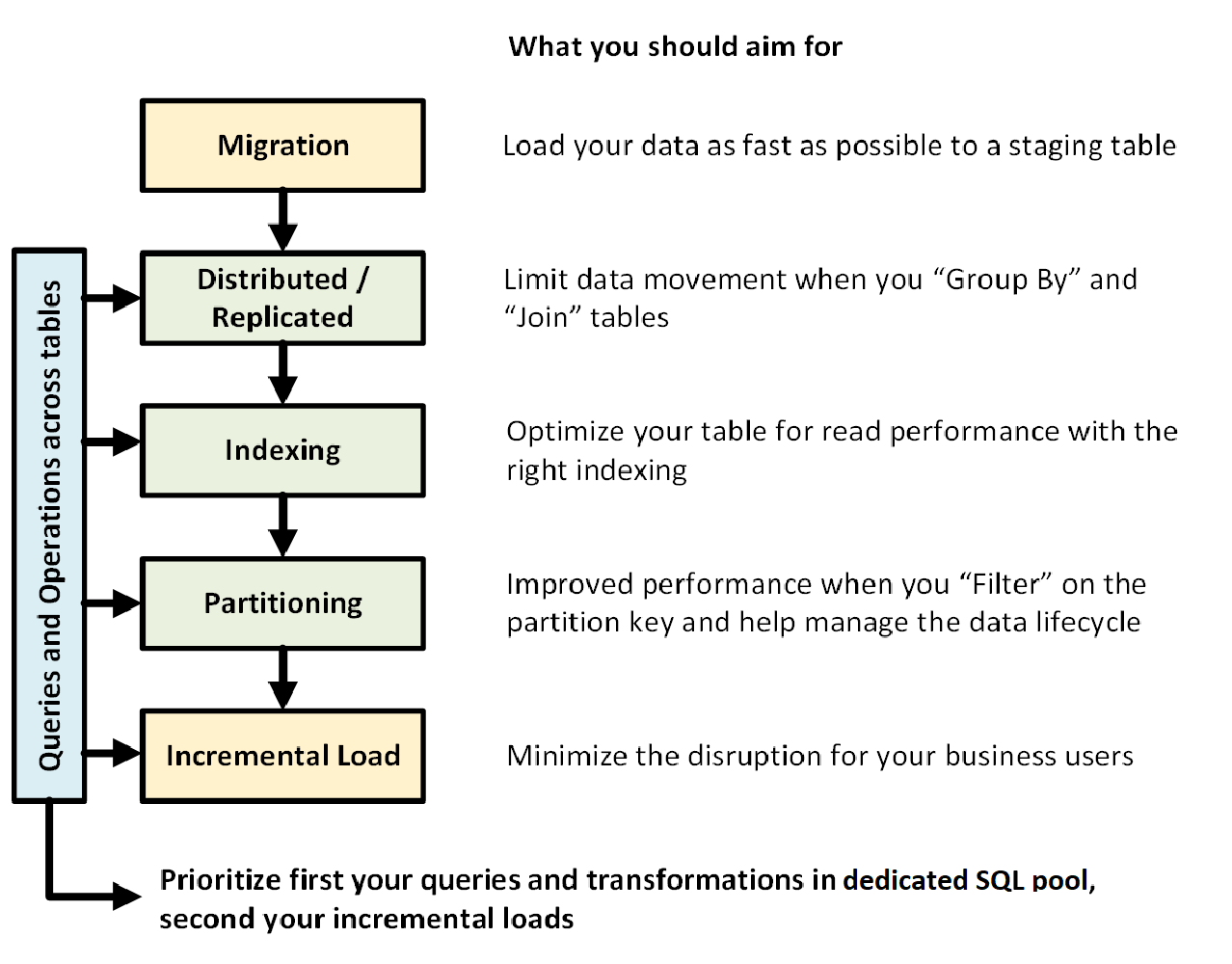
Tablolar arasında sorgular ve işlemler
Veri ambarınızda çalıştırılacak birincil işlemleri ve sorguları önceden bildiğinizde, bu işlemler için veri ambarı mimarinizin önceliğini ayarlayabilirsiniz. Bu sorgular ve işlemler şunları içerebilir:
- Boyut tablolarıyla bir veya iki olgu tablosunu birleştirme, birleştirilmiş tabloyu filtreleme ve ardından sonuçları bir veri reyonuna ekleme.
- Satış verilerinizde büyük veya küçük güncellemeler yapma.
- Tablolarınıza yalnızca veri ekleme.
İşlem türlerini önceden bilmek, tablolarınızın tasarımını iyileştirmenize yardımcı olur.
Veri geçişi
İlk olarak verilerinizi Azure Data Lake Storage veya Azure Blob Depolama yükleyin. Ardından, verilerinizi hazırlama tablolarına yüklemek için COPY deyimini kullanın. Aşağıdaki yapılandırmayı kullanın:
| Tasarlama | Tavsiye |
|---|---|
| Dağıtım | Döner Sistem |
| Dizinleme | Heap |
| Bölümleme | Hiç kimse |
| Kaynak Sınıfı | largerc veya xlargerc |
Veri geçişi, veri yükleme ve Ayıklama, Yükleme ve Dönüştürme (ELT) işlemi hakkında daha fazla bilgi edinin.
Dağıtılmış veya çoğaltılmış tablolar
Tablo özelliklerine bağlı olarak aşağıdaki stratejileri kullanın:
| Türü | Mükemmel uyum | Dikkat edin, eğer... |
|---|---|---|
| Çoğaltılmış | * Sıkıştırmadan sonra 2 GB'tan az depolama alanına sahip bir yıldız şemasındaki küçük boyut tabloları (~5x sıkıştırma) | * Birçok yazma işlemi tablo üzerinde gerçekleştirilir (ekleme, güncelleme, silme, güncelleme gibi) * Data Warehouse Birimleri (DWU) sağlamayı sıklıkla değiştirirsiniz * Yalnızca 2-3 sütun kullanıyorsunuz, ancak tablonuzda birçok sütun var * Çoğaltılmış bir tablonun dizinini oluşturursunuz |
| Sıralı Dağılım (varsayılan) | * Geçici/hazırlama tablosu * Bariz birleştirme tuşu veya iyi aday sütunu yok |
* Veri taşıma nedeniyle performans yavaş |
| Hash | * Olgu tabloları * Büyük boyut tabloları |
* Dağıtım anahtarı güncelleştirilemiyor |
Tips:
- Hepsini Bir Kez Deneme ile başlayın, ancak yüksek düzeyde paralel bir mimariden yararlanmak için karma dağıtım stratejisini hedefleyin.
- Ortak karma anahtarların aynı veri biçimine sahip olduğundan emin olun.
- Varchar biçiminde dağıtmayın.
- Sık birleştirme işlemlerine sahip olgu tablosunun ortak karma anahtarına sahip boyut tabloları karma olarak dağıtılabilir.
- Verilerdeki dengesizliği analiz etmek için sys.dm_pdw_nodes_db_partition_stats kullanın.
- Sorguların arkasındaki veri hareketlerini analiz etmek, yayın süresini izlemek ve karıştırma işlemlerini izlemek için sys.dm_pdw_request_steps kullanın. Bu, dağıtım stratejinizi gözden geçirmenize yardımcı olur.
Çoğaltılan tablolar ve dağıtılmış tablolar hakkında daha fazla bilgi edinin.
Tablonuzu dizinleyin
Dizin oluşturma, tabloları hızla okumak için yararlıdır. gereksinimlerinize göre kullanabileceğiniz benzersiz bir teknoloji kümesi vardır:
| Türü | Mükemmel uyum | Dikkat edin, eğer... |
|---|---|---|
| Heap | * Hazırlık/geçici tablo * Küçük aramalar içeren küçük tablolar |
* Tüm aramalar tablonun tamamını tarar |
| Kümelenmiş indeks | * 100 milyon satıra kadar olan tablolar * Yalnızca 1-2 sütunun yoğun kullanıldığı büyük tablolar (100 milyondan fazla satır) |
* Çoğaltılmış tabloda kullanılır * Birden çok birleştirme ve Grup By işlemlerini içeren karmaşık sorgularınız var * Dizine alınan sütunlarda güncelleştirmeler yaparsınız: bellek alır |
| Kümelenmiş sütun deposu dizini (CCI) (varsayılan) | * Büyük tablolar (100 milyondan fazla satır) | * Çoğaltılmış tabloda kullanılır * Tablonuzda büyük güncelleştirme işlemleri yaparsınız * Tablonuzu fazla bölümlediniz: satır grupları farklı dağıtım düğümleri ve bölümler arasında dağılmıyor |
Tips:
- Kümelenmiş dizinin üstüne, filtreleme için yoğun olarak kullanılan bir sütuna kümelenmemiş dizin eklemek isteyebilirsiniz.
- CCI ile bir tablodaki belleği nasıl yönettiğinize dikkat edin. Verileri yüklediğinizde, kullanıcının (veya sorgunun) büyük bir kaynak sınıfından yararlanmasını istersiniz. Kırpma ve çok sayıda küçük sıkıştırılmış satır grubu oluşturmamaya özen gösterin.
- CCI tabloları, performansı en üst düzeye çıkarmak için 2. Nesil'de işlem düğümlerinde yerel olarak önbelleğe alınır.
- CCI için, satır gruplarınızın yetersiz sıkıştırılması nedeniyle yavaş performans ortaya çıkabilir. Bu durumda, CCI'nizi yeniden oluşturun veya yeniden organize edin. Sıkıştırılmış satır grupları başına en az 100.000 satır istiyorsunuz. İdeal olan, bir satır grubundaki 1 milyon satırdır.
- Artımlı yük sıklığına ve boyutuna bağlı olarak, dizinlerinizi yeniden düzenlerken veya yeniden oluştururken otomatikleştirmek istersiniz. Bahar temizliği her zaman yararlıdır.
- Satır grubunu kırpmak istediğinizde stratejik olun. Açık satır grupları ne kadar büyük? Önümüzdeki günlerde ne kadar veri yüklemeyi bekliyorsunuz?
Dizinler hakkında daha fazla bilgi edinin.
Bölümleme
Büyük bir olgu tablonuz (1 milyardan fazla satır) olduğunda tablonuzu bölümleyebilirsiniz. Vakaların yüzde 99'unda bölümleme anahtarı tarihe göre belirlenmelidir.
ELT gerektiren hazırlama tablolarıyla bölümleme sayesinde avantaj sağlayabilirsiniz. Veri yaşam döngüsü yönetimini kolaylaştırır. Özellikle kümelenmiş columnstore dizinindeki gerçek veya hazırlama tablonuzu aşırı bölümlememeye dikkat edin.
Bölümler hakkında daha fazla bilgi edinin.
Artımlı yük
Verilerinizi artımlı olarak yükleyecekseniz, önce verilerinizi yüklemek için daha büyük kaynak sınıfları ayırdığınızdan emin olun. Kümelenmiş columnstore dizinlerine sahip tablolara yüklenirken bu özellikle önemlidir. Diğer ayrıntılar için bkz. kaynak sınıfları .
ELT işlem hatlarınızı veri ambarınıza otomatikleştirmek için PolyBase ve ADF V2 kullanmanızı öneririz.
Geçmiş verilerinizde çok sayıda güncelleştirme için INSERT, UPDATE ve DELETE kullanmak yerine tabloya saklamak istediğiniz verileri yazmak için CTAS kullanmayı göz önünde bulundurun.
İstatistiklerin bakımını yapın
Verilerinizde önemli değişiklikler olduğunda istatistikleri güncelleştirmek önemlidir. Önemli değişiklikler olup olmadığını belirlemek için güncelleştirme istatistiklerine bakın. Güncelleştirilmiş istatistikler sorgu planlarınızı iyileştirir. Tüm istatistiklerinizin korunmasının çok uzun sürdüğünü fark ederseniz, hangi sütunların istatistikleri olduğu konusunda daha seçici olun.
Güncelleştirmelerin sıklığını da tanımlayabilirsiniz. Örneğin, yeni değerlerin eklenebileceği tarih sütunlarını günlük olarak güncelleştirmek isteyebilirsiniz. Birleşimlere dahil olan sütunlar, WHERE yan tümcesinde kullanılan sütunlar ve GROUP BY'da bulunan sütunlar hakkında istatistikler elde ederek en iyi avantajı elde edebilirsiniz.
İstatistikler hakkında daha fazla bilgi edinin.
Kaynak sınıfı
Kaynak grupları, sorgulara bellek ayırmanın bir yolu olarak kullanılır. Sorgu veya yükleme hızını artırmak için daha fazla belleğe ihtiyacınız varsa, daha yüksek kaynak sınıfları ayırmanız gerekir. Öte yandan, daha büyük kaynak sınıflarının kullanılması eşzamanlılığı etkileyebilir. Tüm kullanıcılarınızı büyük bir kaynak sınıfına taşımadan önce bunu dikkate almak istiyorsunuz.
Sorguların çok uzun sürdüğünü fark ederseniz, kullanıcılarınızın büyük kaynak sınıflarında çalışmadığını denetleyin. Büyük kaynak sınıfları çok sayıda eşzamanlılık yuvası kullanır. Diğer sorguların kuyruğa alınmasına neden olabilirler.
Son olarak, ayrılmış SQL havuzunun (eski adı SQL DW) 2. Nesil'i kullanarak her kaynak sınıfı 1. Nesil'den 2,5 kat daha fazla bellek alır.
Kaynak sınıfları ve eşzamanlılık ile çalışma hakkında daha fazla bilgi edinin.
Maliyetinizi düşürin
Azure Synapse temel özelliklerinden biri, işlem kaynaklarını <> yönetebilme özelliğidir. Kullanmadığınız zaman ayrılmış SQL havuzunuzu (eski adı SQL DW) duraklatabilirsiniz; bu işlem kaynaklarının faturasını durdurur. Performans taleplerinizi karşılamak için kaynakları ölçeklendirebilirsiniz. Duraklatmak için Azure portalını veya PowerShell kullanın. Ölçeklendirmek için Azure portal, PowerShell, T-SQL veya REST API kullanın.
şimdi Azure İşlevleri ile istediğiniz zamanda otomatik ölçeklendirme:

Mimarinizi performans için optimize edin
Merkez-uç mimarisinde SQL Veritabanı ve Azure Analysis Services göz önünde bulundurmanızı öneririz. Bu çözüm, SQL Veritabanı ve Azure Analysis Services gelişmiş güvenlik özelliklerini kullanırken farklı kullanıcı grupları arasında iş yükü yalıtımı sağlayabilir. Bu, kullanıcılarınıza sınırsız eşzamanlılık sağlamanın da bir yoludur.
Azure Synapse Analytics'teki ayrılmış SQL havuzundan (eski adı SQL DW) yararlanan tipik mimariler hakkında daha fazla bilgi edinin.
SQL veritabanlarındaki dallarınızı ayrılmış SQL havuzundan (önceden SQL DW olarak bilinen) dağıtın.