Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Tip
Microsoft Fabric Data Warehouse geleceğe hazır mimariye, yerleşik yapay zekaya ve yeni özelliklere sahip data lake foundation üzerinde kurumsal ölçekli ilişkisel bir ambardır. Veri ambarı konusunda yeniyseniz Fabric Data Warehouse ile başlayın. Mevcut özel SQL havuzu iş yükleri, veri bilimi, gerçek zamanlı analiz ve raporlama genelinde yeni özelliklere erişmek için Fabric yükseltilebilir.
Bu makalede, Azure Synapse Analytics sunucusuz SQL havuzunu kullanarak tek bir CSV dosyasını sorgulamayı öğreneceksiniz. CSV dosyalarının farklı biçimleri olabilir:
- Başlık satırı ile ve başlık satırı olmadan
- Virgül ve sekmeyle ayrılmış değerler
- Windows ve Unix stili çizgi sonları
- Tırnak içine alınmamış ve tırnak içine alınmış değerler ve kaçış karakterleri
Yukarıdaki varyasyonların tümü aşağıda ele alınacaktır.
Hızlı başlangıç örneği
OPENROWSET işlevi, dosyanızın URL'sini sağlayarak CSV dosyasının içeriğini okumanızı sağlar.
Csv dosyasını okuma
Dosyanızın CSV içeriğini görmenin en kolay yolu, işlev için OPENROWSET dosya URL'si sağlamak, csv FORMATve 2.0 PARSER_VERSIONbelirtmektir. Dosya genel kullanıma açıksa veya Microsoft Entra kimliğiniz bu dosyaya erişebiliyorsa, aşağıdaki örnekte gösterildiği gibi sorguyu kullanarak dosyanın içeriğini görebilmeniz gerekir:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
Bu durumda üst bilgiyi temsil eden CSV dosyasındaki ilk satırı atlamak için seçenek firstrow kullanılır. Bu dosyaya erişebildiğinizden emin olun. Dosyanız SAS anahtarı veya özel kimlikle korunuyorsa , SQL oturum açma bilgileri için sunucu düzeyinde kimlik bilgilerini ayarlamanız gerekir.
Önemli
CSV dosyanız UTF-8 karakterleri içeriyorsa, UTF-8 veritabanı harmanlaması kullandığınızdan emin olun (örneğin Latin1_General_100_CI_AS_SC_UTF8).
Dosyadaki metin kodlaması ile harmanlama arasındaki uyuşmazlık beklenmeyen dönüştürme hatalarına neden olabilir.
Aşağıdaki T-SQL deyimini kullanarak geçerli veritabanının varsayılan harmanlamasını kolayca değiştirebilirsiniz: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Veri kaynağı kullanımı
Önceki örnek dosyanın tam yolunu kullanır. Alternatif olarak, depolamanın kök klasörüne işaret eden konumuyla bir dış veri kaynağı oluşturabilirsiniz:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Bir veri kaynağı oluşturduktan sonra, bu veri kaynağını ve işlevindeki OPENROWSET dosyanın göreli yolunu kullanabilirsiniz:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Bir veri kaynağı SAS anahtarı veya özel kimlikle korunuyorsa, veri kaynağını veritabanı kapsamlı kimlik bilgileriyle yapılandırabilirsiniz.
Şemayı açıkça belirtin
OPENROWSET , yan tümcesini kullanarak WITH dosyadan hangi sütunları okumak istediğinizi açıkça belirtmenizi sağlar:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
WITH koşulundaki bir veri türünden sonraki sayılar, CSV dosyasındaki sütun dizinini temsil eder.
Önemli
CSV dosyanız UTF-8 karakter içeriyorsa yan tümcesindeki Latin1_General_100_CI_AS_SC_UTF8 tüm sütunlar için açıkça UTF-8 harmanlaması (örneğinWITH) belirttiğinizden veya veritabanı düzeyinde utf-8 harmanlaması ayarladığınızdan emin olun.
Dosyadaki metin kodlaması ile harmanlama arasındaki uyuşmazlık beklenmeyen dönüştürme hatalarına neden olabilir.
Aşağıdaki T-SQL deyimini kullanarak geçerli veritabanının varsayılan harmanlamasını kolayca değiştirebilirsiniz:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Aşağıdaki tanımı kullanarak sütun türlerinde harmanlamayı kolayca ayarlayabilirsiniz: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
Aşağıdaki bölümlerde, çeşitli csv dosyası türlerini sorgulamayı görebilirsiniz.
Prerequisites
İlk adımınız tabloların oluşturulacağı bir veritabanı oluşturmaktır . Ardından bu veritabanında setup betiği yürüterek nesneleri başlatın. Bu kurulum betiği, bu örneklerde kullanılan veri kaynaklarını, veritabanı kapsamlı kimlik bilgilerini ve dış dosya biçimlerini oluşturur.
Windows stili yeni çizgi
Aşağıdaki sorguda, üst bilgi satırı olmayan, Windows stilinde yeni bir satır ve virgülle ayrılmış sütunlar içeren bir CSV dosyasının nasıl okunduğu gösterilmektedir.
Dosya önizlemesi:
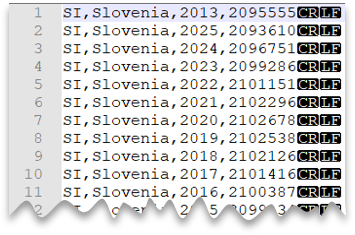
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Unix stili yeni satır
Aşağıdaki sorguda, üst bilgi satırı olmayan, Unix stili yeni bir satır ve virgülle ayrılmış sütunlar içeren bir dosyanın nasıl okunduğu gösterilmektedir. Diğer örneklerle karşılaştırıldığında dosyanın farklı konumunu not edin.
Dosya önizlemesi:
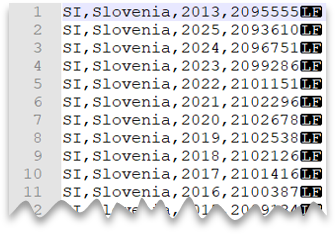
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Başlık satırı
Aşağıdaki sorguda, unix stili yeni bir satır ve virgülle ayrılmış sütunlar içeren üst bilgi satırı içeren bir dosyanın nasıl okunduğu gösterilmektedir. Diğer örneklerle karşılaştırıldığında dosyanın farklı konumunu not edin.
Dosya önizlemesi:
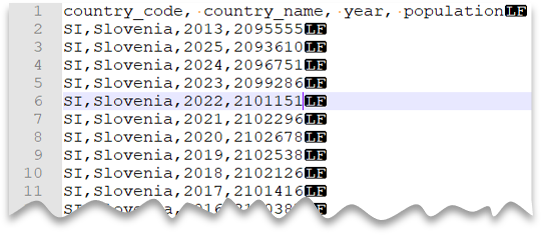
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
Seçenek HEADER_ROW = TRUE , dosyadaki üst bilgi satırından sütun adlarının okunmasıyla sonuçlanır. Dosya içeriği hakkında bilgi sahibi olmadığınız durumlarda keşif amacıyla harika bir hizmettir. En iyi performans için En iyi yöntemler bölümündeki Uygun veri türlerini kullanma bölümüne bakın. Ayrıca, OPENROWSET söz dizimi hakkında daha fazla bilgiyi burada okuyabilirsiniz.
Özel tırnak karakteri
Aşağıdaki sorguda, Unix stili yeni bir satır, virgülle ayrılmış sütunlar ve tırnak içinde değerler içeren üst bilgi satırına sahip bir dosyanın nasıl okunduğu gösterilmektedir. Diğer örneklerle karşılaştırıldığında dosyanın farklı konumunu not edin.
Dosya önizlemesi:
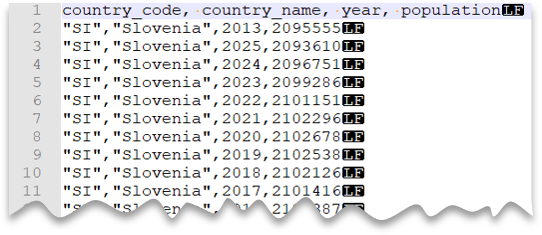
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Note
FIELDQUOTE parametresini atlarsanız bu sorgu aynı sonuçları döndürür çünkü FIELDQUOTE için varsayılan değer çift tırnak işaretidir.
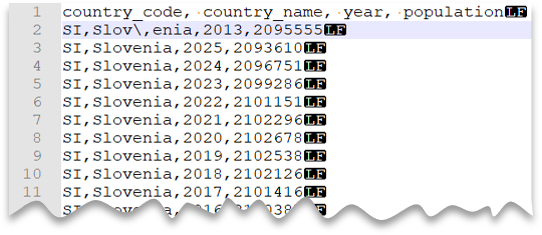
Kaçış karakterleri
Aşağıdaki sorguda, unix stili yeni bir satır, virgülle ayrılmış sütunlar ve değerler içindeki alan sınırlayıcısı (virgül) için kullanılan kaçış karakteriyle üst bilgi satırına sahip bir dosyanın nasıl okunduğu gösterilmektedir. Diğer örneklerle karşılaştırıldığında dosyanın farklı konumunu not edin.
Dosya önizlemesi:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Note
"Slov,enia" içindeki virgül ülke/bölge adının bir parçası yerine alan sınırlayıcısı olarak ele alınacağı için ESCAPECHAR belirtilmezse bu sorgu başarısız olur. "Slov,enia" iki sütun olarak değerlendirilir. Bu nedenle, belirli bir satırda diğer satırlardan bir sütun daha fazla ve WITH yan tümcesinde tanımladığınızdan bir sütun daha fazla olacaktır.
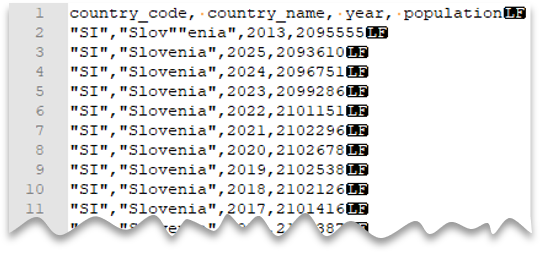
Karakterleri alıntılama kaçışı
Aşağıdaki sorgu, başlık satırına sahip bir dosyanın nasıl okunacağını göstermektedir; bu dosya, Unix tarzı satır sonu, virgülle ayrılmış sütunlar ve içerisinde kaçış için çift tırnak karakteri bulunan değerler içerir. Diğer örneklerle karşılaştırıldığında dosyanın farklı konumunu not edin.
Dosya önizlemesi:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Note
Alıntı karakteri, başka bir alıntı karakteriyle kaçırılmalıdır. Alıntı karakteri, sütun değeri içinde yalnızca değer, alıntı karakterleriyle kapsüllenmişse görünebilir.
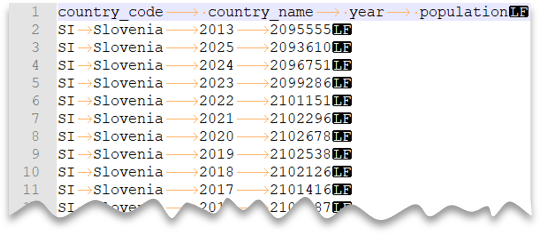
Sekmeyle ayrılmış dosyalar
Aşağıdaki sorgu, üst bilgi satırı bulunan, Unix stili satır sonu ve sekmeyle ayrılmış sütunlar içeren bir dosyanın nasıl okunacağını göstermektedir. Diğer örneklerle karşılaştırıldığında dosyanın farklı konumunu not edin.
Dosya önizlemesi:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Sütunların bir alt kümesini döndürme
Şimdiye kadar, WITH kullanarak CSV dosya şemasını belirttiniz ve tüm sütunları listelediniz. Sorgunuzda ihtiyacınız olan sütunları yalnızca gereken her sütun için bir sıra numarası kullanarak belirtebilirsiniz. Ayrıca ilgi alanı olmayan sütunları atlayacaksınız.
Aşağıdaki sorgu, bir dosyadaki ayrı ülke/bölge adlarının sayısını döndürür ve yalnızca gerekli sütunları belirtir:
Note
Aşağıdaki sorguda WITH yan tümcesine göz atın, ve [country_name] sütununu tanımladığınız satırda, son kısımda "2" (tırnak işareti olmadan) olduğuna dikkat edin. Bu , [country_name] sütununun dosyadaki ikinci sütun olduğu anlamına gelir. Sorgu, dosyadaki ikinci sütun dışındaki tüm sütunları yoksayar.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Eklenebilir dosyaları sorgulama
Sorgu çalışırken sorguda kullanılan CSV dosyaları değiştirilmemelidir. Uzun süre çalışan sorguda SQL havuzu okumaları yeniden deneyebilir, dosyaların bölümlerini okuyabilir, hatta dosyayı birden çok kez okuyabilir. Dosya içeriğinde yapılan değişiklikler yanlış sonuçlara neden olabilir. Bu nedenle, sorgu yürütme sırasında herhangi bir dosyanın değişiklik zamanının değiştiğini algılarsa SQL havuzu sorguda başarısız olur.
Bazı senaryolarda, sürekli eklenen dosyaları okumak isteyebilirsiniz. Sürekli eklenen dosyalar nedeniyle sorgu hatalarını önlemek için, ROWSET_OPTIONS ayarını kullanarak OPENROWSET işlevinin potansiyel olarak tutarsız okumaları yoksaymasına izin verebilirsiniz.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
ALLOW_INCONSISTENT_READS Okuma seçeneği, sorgu yaşam döngüsü sırasında dosya değiştirme süresi denetimini devre dışı bırakır ve dosyada kullanılabilir olan her şeyi okur. Eklenebilir dosyalara mevcut içerik güncelleştirilmez ve yalnızca yeni satırlar eklenir. Bu nedenle, güncelleştirilebilir dosyalara kıyasla yanlış sonuç olasılığı en aza indirilir. Bu seçenek, hataları işlemeden sık eklenen dosyaları okumanızı sağlayabilir. Çoğu senaryoda SQL havuzu, sorgu yürütme sırasında dosyalara eklenen bazı satırları yoksayar.
İlgili içerik
Sonraki makalelerde aşağıdakileri nasıl yapacağınızı göreceksiniz: