Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Uygulamanızın hızlandırmasını en üst düzeye çıkarmak için döşemeyi kullanabilirsiniz. Döşeme, iş parçacıklarını eşit dikdörtgen alt kümelere veya kutucuklara böler. Uygun bir kutucuk boyutu ve kutucuklu algoritma kullanıyorsanız, C++ AMP kodunuzdan daha da fazla hızlandırma elde edebilirsiniz. Döşemenin temel bileşenleri şunlardır:
tile_staticDeğişken. Döşemenin birincil avantajı erişimdentile_staticelde edilen performans kazancıdır. Bellektekitile_staticverilere erişim, genel alanda (arrayveyaarray_viewnesnelerde) verilere erişimden önemli ölçüde daha hızlı olabilir. Her kutucuk için birtile_staticdeğişken örneği oluşturulur ve kutucuktaki tüm iş parçacıkları değişkene erişebilir. Tipik bir kutucuklu algoritmada veriler genel bellekten bir kez belleğe kopyalanırtile_staticve ardından bellektentile_staticbirçok kez erişilir.tile_barrier::wait Yöntemi. Çağrısı,
tile_barrier::waitaynı kutucuktaki tüm iş parçacıkları çağrısına ulaşana kadar geçerli iş parçacığının yürütülmesinitile_barrier::waitaskıya alır. İş parçacıklarının çalıştırılacağı sırayı garanti edemezsiniz, yalnızca kutucuktaki hiçbir iş parçacığının çağrısının ardından tüm iş parçacıkları çağrıya ulaşanatile_barrier::waitkadar yürütülmeyecektir. Bu, yöntemini kullanaraktile_barrier::waitgörevleri iş parçacığı temelinde değil kutucuk temelinde gerçekleştirebileceğiniz anlamına gelir. Tipik bir döşeme algoritması, kutucuğuntile_statictamamı için belleği başlatmak için koda ve ardından çağrısınatile_barrier::waitsahiptir. Aşağıdakitile_barrier::waitkod, tümtile_staticdeğerlere erişim gerektiren hesaplamalar içerir.Yerel ve genel dizin oluşturma. İş parçacığının dizinine veya
array_viewnesnesinin tamamınaarrayve kutucuğa göre dizine erişiminiz vardır. Yerel dizini kullanmak kodunuzun okunmasını ve hatalarını ayıklamayı kolaylaştırabilir. Genellikle, değişkenlere erişmektile_staticiçin yerel dizinleme ve erişim vearraydeğişkenler içinarray_viewgenel dizinleme kullanırsınız.Tiled_extent Sınıfı ve tiled_index Sınıfı. Çağrıda
tiled_extentnesne yerine birextentnesne kullanırsınızparallel_for_each. Çağrıdatiled_indexnesne yerine birindexnesne kullanırsınızparallel_for_each.
Döşemeden yararlanmak için algoritmanızın işlem etki alanını kutucuklara ayırması ve daha hızlı erişim için kutucuk verilerini değişkenlere tile_static kopyalaması gerekir.
Genel, Kutucuk ve Yerel Dizin örneği
Not
C++ AMP üst bilgileri Visual Studio 2022 sürüm 17.0'dan itibaren kullanım dışı bırakılmıştır.
Tüm AMP üst bilgileri dahil olmak derleme hataları oluşturur. Uyarıları susturmak için AMP üst bilgilerini eklemeden önce tanımlayın _SILENCE_AMP_DEPRECATION_WARNINGS .
Aşağıdaki diyagram, 2x3 kutucuklar halinde düzenlenmiş 8x9 veri matrisini temsil eder.
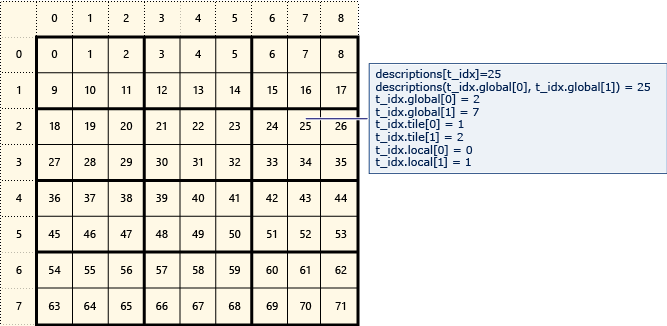
Aşağıdaki örnek, bu kutucuklu matrisin genel, kutucuk ve yerel dizinlerini görüntüler. Nesne array_view türündeki Descriptionöğeler kullanılarak oluşturulur. , Description matristeki öğenin genel, kutucuk ve yerel dizinlerini tutar. çağrısındaki parallel_for_each kod, her öğenin genel, kutucuk ve yerel dizinlerinin değerlerini ayarlar. Çıkış, yapılardaki Description değerleri görüntüler.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Örneğin temel çalışması, nesnesinin array_view tanımında ve çağrısındadır parallel_for_each.
Yapıların vektöru
Descriptionbir 8x9array_viewnesnesine kopyalanır.parallel_for_eachyöntemi, işlem etki alanı olarak birtiled_extentnesneyle çağrılır.tiled_extentnesnesi değişkenininextent::tile()yöntemidescriptionsçağrılarak oluşturulur. çağrısınınextent::tile()tür parametreleri,<2,3>2x3 kutucukların oluşturulduğunu belirtir. Bu nedenle, 8x9 matrisi 12 kutucuk, dört satır ve üç sütun halinde döşenir.parallel_for_eachyöntemi, dizin olarak birtiled_index<2,3>nesne (t_idx) kullanılarak çağrılır. Dizinin (t_idx) tür parametreleri, işlem etki alanının (descriptions.extent.tile< 2, 3>()) tür parametreleriyle eşleşmelidir.Her iş parçacığı yürütürken dizin, iş parçacığının
t_idxhangi kutucukta (tiled_index::tileözellik) olduğuna ve iş parçacığının kutucuk içindeki konumuna (tiled_index::localözellik) ilişkin bilgileri döndürür.
Kutucuk Eşitleme—tile_static ve tile_barrier::wait
Önceki örnekte kutucuk düzeni ve dizinleri gösterilmektedir, ancak kendi içinde çok kullanışlı değildir. Döşeme, kutucuklar algoritmanın ayrılmaz bir parçası olduğunda ve değişkenlerden yararlandığında tile_static yararlı olur. Bir kutucuktaki tüm iş parçacıklarının değişkenlere tile_static erişimi olduğundan, değişkenlerin erişimini eşitlemek tile_barrier::wait için tile_static çağrısı kullanılır. Bir kutucuktaki tüm iş parçacıklarının değişkenlere tile_static erişimi olsa da, kutucuktaki iş parçacıklarının yürütülmesi için garantili bir sıra yoktur. Aşağıdaki örnekte, her kutucuğun tile_static ortalama değerini hesaplamak için değişkenlerin ve yönteminin nasıl kullanılacağı tile_barrier::wait gösterilmektedir. Örneği anlamanın anahtarları şunlardır:
rawData, 8x8 matrisinde depolanır.
Kutucuk boyutu 2x2'dir. Bu, 4x4 kutucuk kılavuzu oluşturur ve ortalamalar bir nesne kullanılarak
array4x4 matrisinde depolanabilir. AMP kısıtlanmış işlevinde başvuruyla yakalayabileceğiniz yalnızca sınırlı sayıda tür vardır. Sınıfarraybunlardan biridir.Matris boyutu ve örnek boyutu, , , ve
#definetür parametrelerininarraysabit değerler olması gerektiğinden deyimler kullanılarakarray_viewextenttanımlanır.tiled_indexBildirimleri de kullanabilirsinizconst int static. Ek bir avantaj olarak, 4x4'ün üzerindeki kutucukların ortalamasını hesaplamak için örnek boyutunu değiştirmek basit bir işlemdir.tile_staticHer kutucuk için 2x2 kayan değer dizisi bildirilir. Bildirim her iş parçacığının kod yolunda olsa da matristeki her kutucuk için yalnızca bir dizi oluşturulur.Her kutucuktaki değerleri diziye kopyalamak için
tile_staticbir kod satırı vardır. Her iş parçacığı için, değer diziye kopyalandıktan sonra, çağrısıtile_barrier::waitnedeniyle iş parçacığında yürütme durdurulur.Bir kutucuktaki tüm iş parçacıkları engele ulaştığında ortalama hesaplanabilir. Kod her iş parçacığı için yürütülür çünkü yalnızca bir iş parçacığında ortalamayı hesaplamak için bir
ifdeyimi vardır. Ortalama, averages değişkeninde depolanır. Engel temelde hesaplamaları kutucuklara göre denetleyerek döngü kullanabileceğiniz yapıdırfor.Değişkendeki
averagesveriler birarraynesne olduğundan konağa geri kopyalanmalıdır. Bu örnekte vektör dönüştürme işleci kullanılır.Tam örnekte SAMPLESIZE değerini 4 olarak değiştirebilirsiniz ve kod başka bir değişiklik yapmadan doğru şekilde yürütülür.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Yarış Koşulları
Adlı tile_static bir total değişken oluşturmak ve her iş parçacığı için bu değişkeni artırmak cazip olabilir, örneğin:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Bu yaklaşımdaki ilk sorun, değişkenlerin tile_static başlatıcıları olamayacağıdır. İkinci sorun, kutucuktaki tüm iş parçacıklarının değişkene totalbelirli bir sırada erişmesi nedeniyle atamasında bir yarış durumu olmasıdır. Bir algoritmayı, bir sonraki adımda gösterildiği gibi her bir engeldeki toplama yalnızca bir iş parçacığının erişmesine izin verecek şekilde programlayabilirsiniz. Ancak, bu çözüm genişletilebilir değildir.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Bellek Çitleri
Eşitlenmesi gereken iki tür bellek erişimi vardır: genel bellek erişimi ve tile_static bellek erişimi. Nesne concurrency::array yalnızca genel bellek ayırır. , concurrency::array_view genel belleğe, tile_static belleğe veya her ikisinde de nasıl oluşturulduğuna bağlı olarak başvurabilir. Eşitlenmesi gereken iki tür bellek vardır:
genel bellek
tile_static
Bellek çiti , bellek erişimlerinin iş parçacığı kutucuğundaki diğer iş parçacıkları için kullanılabilir olmasını ve bellek erişimlerinin program sırasına göre yürütülmesini sağlar. Bunu sağlamak için, derleyiciler ve işlemciler okumaları ve yazmaları çit boyunca yeniden sıralamaz. C++ AMP'de, şu yöntemlerden birine yapılan bir çağrıyla bir bellek çiti oluşturulur:
tile_barrier::wait Yöntemi: Hem genel
tile_statichem de bellek çevresinde bir çit oluşturur.tile_barrier::wait_with_all_memory_fence Yöntemi: Hem genel
tile_statichem de bellek çevresinde bir çit oluşturur.tile_barrier::wait_with_global_memory_fence Yöntemi: Yalnızca genel belleğin çevresinde bir çit oluşturur.
tile_barrier::wait_with_tile_static_memory_fence Yöntemi: Yalnızca
tile_staticbelleğin çevresinde bir çit oluşturur.
Size gereken belirli çitleri çağırmak uygulamanızın performansını artırabilir. Engel türü, derleyicinin ve donanımın deyimlerini yeniden sıralama biçimini etkiler. Örneğin, genel bellek çiti kullanırsanız, bu yalnızca genel bellek erişimleri için geçerlidir ve bu nedenle derleyici ve donanım, çitin iki tarafındaki değişkenlere tile_static yönelik okuma ve yazmaları yeniden sıralayabilir.
Sonraki örnekte, bariyer yazmaları ile bir tileValues değişken olarak eşitlertile_static. Bu örnekte yerine tile_barrier::wait_with_tile_static_memory_fence olarak adlandırılır tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Ayrıca bkz.
C++ AMP (C++ Hızlandırılmış Yüksek Paralellik)
tile_static Anahtar Sözcüğü