Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu adım adım kılavuzda, matris çarpmasının yürütülmesini hızlandırmak için C++ AMP'nin nasıl kullanılacağı gösterilmektedir. Biri döşemesiz, diğeri de döşemeli iki algoritma sunulur.
Önkoşullar
Başlamadan önce:
- C++ AMP'ye Genel Bakış'a bakın.
- Fayansları Kullanma'yı Oku.
- En az Windows 7 veya Windows Server 2008 R2 çalıştırdığınızdan emin olun.
Uyarı
C++ AMP üst bilgileri Visual Studio 2022 sürüm 17.0'dan itibaren kullanım dışı bırakılmıştır.
AMP üst bilgilerini dahil etmek derleme hatalarına neden olur. AMP üst bilgilerini eklemeden önce uyarıları susturmak için _SILENCE_AMP_DEPRECATION_WARNINGS tanımla.
Proje oluşturmak için
Yeni proje oluşturma yönergeleri, hangi Visual Studio sürümünü yüklediğinize bağlı olarak değişir. Tercih ettiğiniz Visual Studio sürümünün belgelerini görmek için Sürüm seçici denetimini kullanın. Bu sayfadaki içindekiler tablosunun en üstünde bulunur.
Visual Studio'da proje oluşturmak için
Menü çubuğunda Dosya Yeni Proje'yi seçerek >Yeni>Proje Oluştur iletişim kutusunu açın.
İletişim kutusunun üst kısmında Dil'i C++ olarak, Platform'ı Windows olarak ve Proje türü'nü Konsol olarak ayarlayın.
Filtrelenen proje türleri listesinden Projeyi Boşalt'ı ve ardından İleri'yi seçin. Sonraki sayfada, Proje için bir ad belirtmek için Ad kutusuna MatrixMultiply yazın ve isterseniz proje konumunu belirtin.
İstemci projesini oluşturmak için Oluştur düğmesini seçin.
Çözüm Gezgini'nde Kaynak Dosyalar için kısayol menüsünü açın ve ardından Ekle>'yi seçin.
Yeni Öğe Ekle iletişim kutusunda C++ Dosya (.cpp) öğesini seçin, İsim kutusuna MatrixMultiply.cpp girin ve ardından Ekle düğmesini seçin.
Döşeme olmadan çarpma
Bu bölümde, A ve B olmak üzere aşağıdaki gibi tanımlanan iki matrisin çarpımını göz önünde bulundurun:
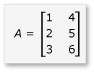

A, 3'e 2 matris, B ise 2'ye 3 matristir. A ile B'nin çarpımının sonucu aşağıdaki 3x3 matristir. Ürün, A'nın satırlarıyla B'nin sütunlarının eleman eleman çarpılmasıyla hesaplanır.

C++ AMP'i kullanmadan çarpmak
MatrixMultiply.cpp açın ve mevcut kodu değiştirmek için aşağıdaki kodu kullanın.
#include <iostream> void MultiplyWithOutAMP() { int aMatrix[3][2] = {{1, 4}, {2, 5}, {3, 6}}; int bMatrix[2][3] = {{7, 8, 9}, {10, 11, 12}}; int product[3][3] = {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}; for (int row = 0; row < 3; row++) { for (int col = 0; col < 3; col++) { // Multiply the row of A by the column of B to get the row, column of product. for (int inner = 0; inner < 2; inner++) { product[row][col] += aMatrix[row][inner] * bMatrix[inner][col]; } std::cout << product[row][col] << " "; } std::cout << "\n"; } } int main() { MultiplyWithOutAMP(); getchar(); }Algoritma, matris çarpma tanımının basit bir uygulamasıdır. Hesaplama süresini azaltmak için paralel veya iş parçacıklı algoritmalar kullanmaz.
Menü çubuğunda Dosya>Tümünü Kaydet seçeneğine tıklayın.
Hata ayıklamayı başlatmak ve çıkışın doğru olduğunu doğrulamak için F5 klavye kısayolunu seçin.
Uygulamadan çıkmak için Enter'ı seçin.
C++ AMP kullanarak çarpmak için
MatrixMultiply.cpp dosyasında
mainyönteminden önce aşağıdaki kodu ekleyin.void MultiplyWithAMP() { int aMatrix[] = { 1, 4, 2, 5, 3, 6 }; int bMatrix[] = { 7, 8, 9, 10, 11, 12 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; array_view<int, 2> a(3, 2, aMatrix); array_view<int, 2> b(2, 3, bMatrix); array_view<int, 2> product(3, 3, productMatrix); parallel_for_each(product.extent, [=] (index<2> idx) restrict(amp) { int row = idx[0]; int col = idx[1]; for (int inner = 0; inner <2; inner++) { product[idx] += a(row, inner)* b(inner, col); } }); product.synchronize(); for (int row = 0; row <3; row++) { for (int col = 0; col <3; col++) { //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }AMP kodu, AMP olmayan koda benzer. Çağrı
parallel_for_eachyapıldığında,product.extentiçindeki her öğe için bir iş parçacığı başlatır ve satır ve sütun için döngüleriforile değiştirir. Satır ve sütun ile belirtilen hücrenin değeriidxiçinde mevcuttur. bir nesneninarray_viewöğelerine, işlecini ve dizin değişkenini ya da[]işlecini()ve satır ve sütun değişkenlerini kullanarak erişebilirsiniz. Örnekte her iki yöntem de gösterilmektedir. yöntemi değişkenininarray_view::synchronizedeğerleriniproductdeğişkenineproductMatrixgeri kopyalar.MatrixMultiply.cpp en üstüne aşağıdaki
includeveusingdeyimlerini ekleyin.#include <amp.h> using namespace concurrency;mainyönteminiMultiplyWithAMPyöntemini çağıracak şekilde değiştirin.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); getchar(); }Hata ayıklamayı başlatmak ve çıkışın doğru olduğunu doğrulamak için Ctrl+F5 klavye kısayolunu basın.
Uygulamadan çıkmak için Ara Çubuğu'na basın.
Döşeme ile çarpma
Döşeme, verileri kutucuk olarak bilinen eşit boyutlu alt kümelere bölümlemenizi sağlayan bir tekniktir. Döşemeyi kullandığınızda üç şey değişir.
Değişkenler oluşturabilirsiniz
tile_static. Alan içindekitile_staticverilere erişim, genel alanda verilere erişimden çok daha hızlı olabilir. Her bir kutucuk için birtile_staticdeğişken örneği oluşturulur ve kutucuktaki tüm iş parçacıkları değişkene erişebilir. Döşemenin birincil avantajı,tile_staticerişimi sayesinde elde edilen performans kazancıdır.Belirtilen bir kod satırında, tek bir kutucuktaki tüm iş parçacıklarını bekletmek için tile_barrier::wait yöntemini çağırabilirsiniz. İş parçacıklarının hangi sırayla çalıştırılacağını garanti edemezsiniz; ancak, bir bloktaki tüm iş parçacıklarının yürütmeye
tile_barrier::waitdevam etmeden önce duracağını garanti edebilirsiniz.İş parçacığının tüm
array_viewnesnesine göre ve karoya göre dizinine erişiminiz vardır. Yerel dizini kullanarak kodunuzun daha kolay okunmasını ve hata ayıklamasını sağlayabilirsiniz.
Matris çarpmasında bölmelerden yararlanmak için algoritmanın matrisi parçalara ayırması ve daha hızlı erişim için bu parça verilerini tile_static değişkenlerine kopyalaması gerekir. Bu örnekte matris, eşit boyutta alt matrisler halinde bölümlenmiştir. Ürün, alt matrisler çarpılarak bulunur. Bu örnekteki iki matris ve bunların ürünü şunlardır:
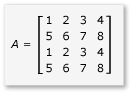
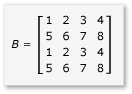
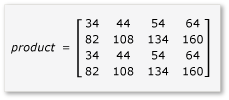
Matrisler dört adet 2x2 matrise ayrılır ve bunlar aşağıdaki gibi tanımlanır:


A ve B'nin ürünü artık aşağıdaki gibi yazılabilir ve hesaplanabilir:
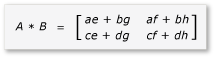
a ile h arasındaki matrislerin 2x2 matrisler olması nedeniyle, bu matrislerin tüm çarpımları ve toplamları da 2x2 matrislerdir. Ayrıca A ve B'nin çarpımının beklendiği gibi 4x4 matris olduğunu da izler. Algoritmayı hızla denetlemek için, ürünün ilk satırındaki ilk sütundaki öğenin değerini hesaplayın. Örnekte, bu, öğesinin ilk satırında ve ilk sütununda yer alan ae + bg değeri olacaktır. Her terim için yalnızca ae ve bg'nin ilk sütununu ve ilk satırını hesaplamanız gerekir.
ae için o değer (1 * 1) + (2 * 5) = 11'dir. için bg değeri şeklindedir (3 * 1) + (4 * 5) = 23. Son değer, 11 + 23 = 34doğru olan değeridir.
Bu algoritmayı uygulamak için kod:
tiled_extentçağrısındaextentnesnesi yerineparallel_for_eachnesnesi kullanır.tiled_indexçağrısındaindexnesnesi yerineparallel_for_eachnesnesi kullanır.Alt matrisleri tutacak
tile_staticdeğişkenler oluşturur.Alt matrislerin ürünlerini hesaplamak için iş parçacıklarını durdurur.
tile_barrier::waityöntemini kullanır.
AMP ve döşeme kullanarak çarpmak için
MatrixMultiply.cpp dosyasında
mainyönteminden önce aşağıdaki kodu ekleyin.void MultiplyWithTiling() { // The tile size is 2. static const int TS = 2; // The raw data. int aMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int bMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; // Create the array_view objects. array_view<int, 2> a(4, 4, aMatrix); array_view<int, 2> b(4, 4, bMatrix); array_view<int, 2> product(4, 4, productMatrix); // Call parallel_for_each by using 2x2 tiles. parallel_for_each(product.extent.tile<TS, TS>(), [=] (tiled_index<TS, TS> t_idx) restrict(amp) { // Get the location of the thread relative to the tile (row, col) // and the entire array_view (rowGlobal, colGlobal). int row = t_idx.local[0]; int col = t_idx.local[1]; int rowGlobal = t_idx.global[0]; int colGlobal = t_idx.global[1]; int sum = 0; // Given a 4x4 matrix and a 2x2 tile size, this loop executes twice for each thread. // For the first tile and the first loop, it copies a into locA and e into locB. // For the first tile and the second loop, it copies b into locA and g into locB. for (int i = 0; i < 4; i += TS) { tile_static int locA[TS][TS]; tile_static int locB[TS][TS]; locA[row][col] = a(rowGlobal, col + i); locB[row][col] = b(row + i, colGlobal); // The threads in the tile all wait here until locA and locB are filled. t_idx.barrier.wait(); // Return the product for the thread. The sum is retained across // both iterations of the loop, in effect adding the two products // together, for example, a*e. for (int k = 0; k < TS; k++) { sum += locA[row][k] * locB[k][col]; } // All threads must wait until the sums are calculated. If any threads // moved ahead, the values in locA and locB would change. t_idx.barrier.wait(); // Now go on to the next iteration of the loop. } // After both iterations of the loop, copy the sum to the product variable by using the global location. product[t_idx.global] = sum; }); // Copy the contents of product back to the productMatrix variable. product.synchronize(); for (int row = 0; row <4; row++) { for (int col = 0; col <4; col++) { // The results are available from both the product and productMatrix variables. //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Bu örnek, döşeme olmadan örnekten önemli ölçüde farklıdır. Kod şu kavramsal adımları kullanır:
tile[0,0] karesini
aiçindenlocAiçerisine kopyalayın. tile[0,0] karesinibiçindenlocBiçerisine kopyalayın.productkutucuklu,avebdeğil. Buna dikkat edin. Bu nedenle,a, bveproductöğelerine erişmek için küresel dizinleri kullanırsınız.tile_barrier::waitçağrısı çok önemlidir. Kutucuktaki tüm iş parçacıklarını, hemlocAhem delocBdoldurulana kadar durdurur.locAvelocBçarpın ve sonuçlarıproductiçine yerleştirin.[0,1]
akutucuğunun öğelerinilocAiçine kopyalayın. [1,0] kutucuğunun öğelerinib,locBiçine kopyalayın.locAvelocBçarpın ve bunlarıproduct'deki mevcut sonuçlara ekleyin.Kutucuk [0,0]'in çarpımı tamamlandı.
Diğer dört kutucuk için yineleyin. Özellikle döşemeler için dizin oluşturma yoktur ve iş parçacıkları herhangi bir sırada çalıştırılabilir. Her iş parçacığı yürütülürken,
tile_staticdeğişkenler her kutucuk için uygun şekilde oluşturulur vetile_barrier::waitfonksiyon/metod çağrısı program akışını denetler.Algoritmayı yakından incelediğinizde, her alt matrisin bir
tile_staticbelleğe iki kez yüklendiğine dikkat edin. Bu veri aktarımı zaman alır. Ancak verilertile_staticbelleğe girdikten sonra verilere erişim çok daha hızlı olur. Ürünlerin hesaplanması alt matrislerdeki değerlere tekrar tekrar erişim gerektirdiğinden, genel bir performans artışı vardır. Her algoritma için, en uygun algoritmayı ve kutucuk boyutunu bulmak için deneme gerekir.
AMP olmayan ve karosuz örneklerde, A ve B'nin her bir elemanına global bellekten dört kez erişilir ve ürün hesaplanır. Kutucuk örneğinde, her öğeye genel bellekten iki kez ve bellekten
tile_staticdört kez erişilir. Bu önemli bir performans kazancı değildir. Ancak, A ve B 1024x1024 matrisleri ve kutucuk boyutu 16 ise önemli bir performans artışı olacaktır. Bu durumda, her öğe yalnızca 16 kez belleğe kopyalanırtile_staticve bellektentile_static1024 kez erişilir.Main yöntemini, gösterildiği gibi,
MultiplyWithTilingyöntemini çağıracak şekilde değiştirin.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); MultiplyWithTiling(); getchar(); }Hata ayıklamayı başlatmak ve çıkışın doğru olduğunu doğrulamak için Ctrl+F5 klavye kısayolunu basın.
Uygulamadan çıkmak için Ara çubuğuna basın.
Ayrıca bakınız
C++ AMP (C++ Hızlandırılmış Yüksek Paralellik)
Adım Adım Kılavuz: C++ AMP Uygulamasında Hata Ayıklama