Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Veri alımı, aşağı akış uygulamalarında kullanılabilmesi için dosyalar, veritabanları, API'ler veya bulut hizmetleri gibi farklı kaynaklardan veri toplama, okuma ve hazırlama işlemidir. Uygulamada, bu işlem Çıkar-Dönüştür-Yükle (ETL) iş akışını izler.
- PDF, Word belgesi, ses dosyası veya web API'si olsun, özgün kaynağından verileri ayıklayın.
- Biçimleri temizleyerek, öbekleyerek, zenginleştirerek veya dönüştürerek verileri dönüştürün.
- Verileri alma ve analiz için veritabanı, vektör deposu veya yapay zeka modeli gibi bir hedefe yükleyin.
Özellikle Retrieval-Augmented Oluşturma (RAG) olmak üzere yapay zeka ve makine öğrenmesi senaryolarında veri alımı yalnızca verileri bir biçimden diğerine dönüştürmekle ilgili değildir. Verileri akıllı uygulamalar için kullanılabilir hale getirmektir. Bu, belgeleri yapılarını ve anlamlarını koruyacak şekilde temsil etmek, yönetilebilir öbeklere bölmek, meta veriler veya eklemelerle zenginleştirmek ve hızlı ve doğru bir şekilde alınabilmeleri için depolamak anlamına gelir.
Yapay zeka uygulamaları için veri alımı neden önemlidir?
Çalışanlarınızın şirketinizin geniş belge koleksiyonunda bilgi bulmasına yardımcı olmak için RAG destekli bir sohbet botu oluşturduğunuzu düşünün. Bu belgeler PDF'leri, Word dosyalarını, PowerPoint sunularını ve farklı sistemlere dağılmış web sayfalarını içerebilir.
Doğru ve bağlamsal yanıtlar sağlamak için sohbet botunuzun binlerce belgeyi anlaması ve arama yapması gerekir. Ancak ham belgeler yapay zeka sistemleri için uygun değildir. Bunları aranabilir ve alınabilir hale getirirken anlamı koruyan bir biçime dönüştürmeniz gerekir.
Burada veri alımı kritik hale gelir. Farklı dosya biçimlerinden metin ayıklamanız, büyük belgeleri yapay zeka modeli sınırlarına uygun küçük parçalara bölmeniz, içeriği meta verilerle zenginleştirmeniz, anlamsal arama için eklemeler oluşturmanız ve her şeyi hızlı alma olanağı sağlayacak şekilde depolamanız gerekir. Her adım, özgün anlamın ve bağlamın nasıl korunduğuna ilişkin dikkatli bir değerlendirme gerektirir.
Microsoft.Extensions.DataIngestion kitaplığı
📦 Microsoft.Extensions.DataIngestion paketi, veri alımı için temel .NET yapı taşları sağlar. Geliştiricilerin yapay zeka ve makine öğrenmesi iş akışları, özellikle Alma-Artırımlı Oluşturma (RAG) senaryoları için belgeleri okumasına, işlemesine ve hazırlamasına olanak tanır.
Bu yapı taşları ile uygulama gereksinimlerinize göre uyarlanmış sağlam, esnek ve akıllı veri alımı işlem hatları oluşturabilirsiniz:
- Birleşik belge gösterimi: Herhangi bir dosya türünü (örneğin, PDF, Görüntü veya Microsoft Word) büyük dil modelleriyle iyi çalışan tutarlı bir biçimde temsil edin.
- Esnek veri alımı: Birden çok yerleşik okuyucu kullanarak hem bulut hizmetlerinden hem de yerel kaynaklardan belgeleri okuyarak, nerede olursa olsun veri getirmeyi kolaylaştırabilirsiniz.
- Yerleşik yapay zeka geliştirmeleri: Özetler, yaklaşım analizi, anahtar sözcük ayıklama ve sınıflandırma ile içeriği otomatik olarak zenginleştirin ve verilerinizi akıllı iş akışları için hazırlar.
- Özelleştirilebilir öbekleme stratejileri: Alma ve analiz gereksinimlerinizi en iyi duruma getirebilmeniz için belirteç tabanlı, bölüm tabanlı veya semantik duyarlı yaklaşımları kullanarak belgeleri öbeklere bölün.
- Üretime hazır depolama: İşlenen öbekleri popüler vektör veritabanlarında ve belge depolarında depolayıp gömme oluşturma desteği sunarak, işlem hatlarınız gerçek dünya senaryolarına hazır hale gelir.
- Uçtan uca işlem hattı oluşturma:IngestionPipeline<T> API ile okuyucuları, işlemcileri, parçalayıcıları ve yazıcılara birbirine bağlayarak gereksiz tekrarları azaltabilir ve tüm iş akışlarını oluşturmayı, özelleştirmeyi ve genişletmeyi kolaylaştırabilirsiniz.
- Performans ve ölçeklenebilirlik: Ölçeklenebilir veri işleme için tasarlanan bu bileşenler, büyük hacimli verileri verimli bir şekilde işleyerek kurumsal düzeydeki uygulamalar için uygun olmasını sağlayabilir.
Bu bileşenlerin tümü açık ve tasarım gereği genişletilebilir. Özel mantık ve yeni bağlayıcılar ekleyebilir ve sistemi yeni yapay zeka senaryolarını destekleyecek şekilde genişletebilirsiniz. .NET geliştiricileri belgelerin temsil edilme, işlenme ve depolanma şeklini standartlaştırarak, her proje için "tekerleği yeniden icat etmeden" güvenilir, ölçeklenebilir ve sürdürülebilir veri işlem hatları oluşturabilir.
Kararlı temeller üzerine kurulmuştur
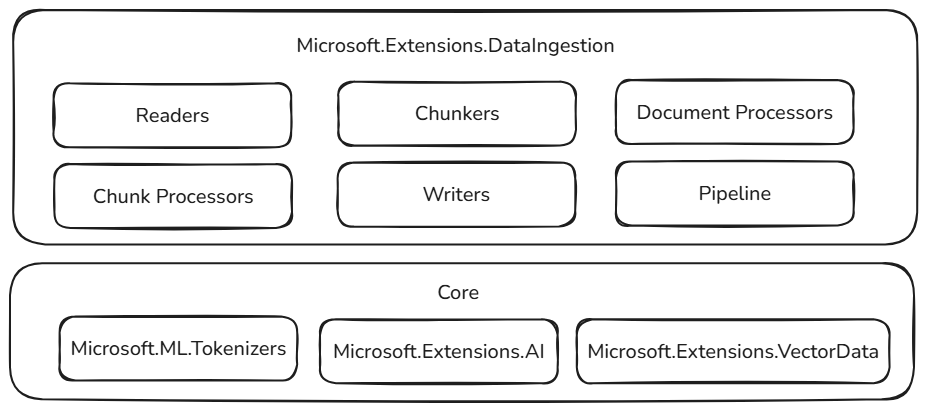
Bu veri alımı yapı taşları, .NET ekosistemindeki kanıtlanmış ve genişletilebilir bileşenlerin üzerine kuruludur ve mevcut yapay zeka iş akışlarıyla güvenilirlik, birlikte çalışabilirlik ve sorunsuz tümleştirme sağlar:
- Microsoft.ML.Tokenizers: Belirteç oluşturucular, belirteçleri temel alarak belgeleri öbeklemenin temelini sağlar. Bu, büyük dil modelleri için veri hazırlamak ve alma stratejilerini iyileştirmek için gerekli olan içeriğin kesin olarak bölünmesini sağlar.
- Microsoft.Extensions.AI: Bu kitaplık kümesi, büyük dil modellerini kullanarak zenginleştirme dönüşümlerini destekler. Özetleme, yaklaşım analizi, anahtar sözcük ayıklama ve ekleme oluşturma gibi özellikleri etkinleştirerek akıllı içgörülerle verilerinizi geliştirmenizi kolaylaştırır.
- Microsoft.Extensions.VectorData: Bu kitaplık kümesi, işlenen öbekleri Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch ve daha birçok farklı vektör deposunda depolamak için tutarlı bir arabirim sunar. Bu, veri işlem hatlarınızın üretim için hazır olmasını ve farklı depolama arka uçlarında ölçeklendirilmesini sağlar.
Tanıdık desenlere ve araçlara ek olarak, bu soyutlamalar zaten genişletilebilir bileşenlere dayalıdır. Eklenti özelliği ve birlikte çalışabilirlik çok önemlidir, bu nedenle .NET yapay zeka ekosisteminin geri kalanı büyüdükçe veri alımı bileşenlerinin özellikleri de artar. Bu yaklaşım, geliştiricilerin yeni sağlayıcıları, zenginleştirmeleri ve depolama seçeneklerini kolayca tümleştirmesini sağlayarak işlem hatlarını geleceğe hazır ve gelişen yapay zeka senaryolarına uyarlanabilir hale getirmelerini sağlar.
Veri alımı yapı taşları
Microsoft.Extensions.DataIngestion kitaplığı, eksiksiz bir veri işleme işlem hattı oluşturmak için birlikte çalışan birkaç temel bileşen etrafında oluşturulur. Bu bölümde her bileşen ve bunların nasıl bir araya geldiği incelenmiştir.
Belgeler ve belge okuyucular
Kitaplığın temelini, önemli bilgileri kaybetmeden herhangi bir dosya biçimini temsil etmek için birleşik bir yol sağlayan IngestionDocument türü oluşturur.
IngestionDocument Büyük dil modelleri Markdown biçimlendirmesiyle en iyi şekilde çalıştığından Markdown merkezlidir.
Soyutlama IngestionDocumentReader , yerel dosyalar veya akışlar olsun, çeşitli kaynaklardan belge yüklemeyi işler. Birkaç okuyucu kullanılabilir:
Gelecekte daha fazla okuyucu ( LlamaParse ve Azure Document Intelligence dahil) eklenecektir.
Bu tasarım, aynı tutarlı API'yi kullanarak farklı kaynaklardan belgelerle çalışabileceğiniz ve kodunuzu daha sürdürülebilir ve esnek hale getirebileceğiniz anlamına gelir.
Belge işleme
Belge işlemcileri, içeriği geliştirmek ve hazırlamak için belge düzeyinde dönüştürmeler uygular. Kütüphane, belgeler içindeki görüntüler için açıklayıcı alternatif metin oluşturmak üzere büyük dil modellerini kullanan yerleşik bir işlemci olan ImageAlternativeTextEnricher sınıfını sağlar.
Öbekler ve öbekleme stratejileri
Bir belge yüklendikten sonra, genellikle öbekler olarak adlandırılan daha küçük parçalara ayırmanız gerekir. Öbekler, bir belgenin yapay zeka sistemleri tarafından verimli bir şekilde işlenebilen, depolanabilen ve alınabilen alt parçalarını temsil eder. Bu öbekleme işlemi, en ilgili bilgi parçalarını hızlı bir şekilde bulmanız gereken alma artırmalı üretim senaryoları için gereklidir.
Kitaplık, farklı kullanım örneklerine uyacak birkaç öbekleme stratejisi sağlar:
- Üst bilgilere ayırmak için üst bilgi tabanlı ayırma.
- Bölümlere dayalı öbekleme, bölümlere (örneğin, sayfalar) bölünmek üzere.
- Semantik duyarlı öbekleme ile tüm düşünceleri korumak.
Bu öbekleme stratejileri, microsoft.ML.Tokenizers kitaplığını temel alır ve metni büyük dil modelleriyle iyi çalışan uygun boyutta parçalara akıllıca böler. Doğru öbekleme stratejisi, belge türlerinize ve bilgileri nasıl almayı planladığınıza bağlıdır.
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel("gpt-5");
IngestionChunkerOptions options = new(tokenizer)
{
MaxTokensPerChunk = 2000,
OverlapTokens = 0
};
IngestionChunker<string> chunker = new HeaderChunker(options);
Öbek işleme ve zenginleştirme
Belgeler öbeklere bölündükten sonra, içeriği geliştirmek ve zenginleştirmek için işlemciler uygulayabilirsiniz. Öbek işlemcileri tek tek parçalar üzerinde çalışır ve aşağıdakileri gerçekleştirebilir:
- Otomatik özetler (), yaklaşım analizi () ve anahtar sözcük ayıklama (
SummaryEnricherSentimentEnricherdahil olmak üzereKeywordEnricher). - Önceden tanımlanmış kategorilere ( ) göre otomatik içerik
ClassificationEnricher.
Bu işlemciler, akıllı içerik dönüşümü için büyük dil modellerinden yararlanmak için Microsoft.Extensions.AI.Abstractions kullanır ve bu da öbeklerinizi aşağı akış yapay zeka uygulamaları için daha kullanışlı hale getirir.
Belge yazıcı ve depolama
IngestionChunkWriter<T> işlenen öbekleri daha sonra almak üzere bir veri deposunda depolar. Kitaplık, Microsoft.Extensions.AI ve Microsoft.Extensions.VectorData kullanan, VectorStoreWriter<T> sınıfını sağlar. Bu yazar
Vektör depoları Qdrant, SQL Server, CosmosDB, MongoDB ve ElasticSearch gibi popüler seçenekleri içerir. Sağlayıcılar hakkında daha fazla bilgi için bkz. Hazır Vektör Deposu sağlayıcıları. (Paket adlarına "SemanticKernel" eklenmesine rağmen, bu sağlayıcıların Anlam Çekirdeği ile hiçbir ilgisi yoktur ve Agent Framework dahil olmak üzere .NET'te herhangi bir yerde kullanılabilir.)
Araç ayrıca Microsoft.Extensions.AI kullanarak parçalarınız için otomatik olarak gömüler oluşturabilir ve bunları anlamsal arama ve alma senaryolarına hazırlayabilir.
OpenAIClient openAIClient = new(
new ApiKeyCredential(Environment.GetEnvironmentVariable("GITHUB_TOKEN")!),
new OpenAIClientOptions { Endpoint = new Uri("https://models.github.ai/inference") });
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator =
openAIClient.GetEmbeddingClient("text-embedding-3-small").AsIEmbeddingGenerator();
using SqliteVectorStore vectorStore = new(
"Data Source=vectors.db;Pooling=false",
new()
{
EmbeddingGenerator = embeddingGenerator
});
// The writer requires the embedding dimension count to be specified.
// For OpenAI's `text-embedding-3-small`, the dimension count is 1536.
using VectorStoreWriter<string> writer = new(vectorStore, dimensionCount: 1536);
Belge işleme işlem hattı
API, IngestionPipeline<T> çeşitli veri alımı bileşenlerini eksiksiz bir iş akışına zincirlemenizi sağlar. Şunu birleştirebilirsiniz:
- Çeşitli kaynaklardan belge yüklemek için okuyucular.
- Belge içeriğini dönüştürmek ve zenginleştirmek için işlemciler.
- Belgeleri yönetilebilir parçalara ayırmak için parçalayıcılar.
- Veri yazıcıları, seçtiğiniz veri deposunda son sonuçları depolamak üzere kullanılır.
Bu işlem hattı yaklaşımı, ortak kodu azaltır ve karmaşık veri alımı iş akışlarını oluşturmayı, test etmeyi ve korumayı kolaylaştırır.
using IngestionPipeline<string> pipeline = new(reader, chunker, writer, loggerFactory: loggerFactory)
{
DocumentProcessors = { imageAlternativeTextEnricher },
ChunkProcessors = { summaryEnricher }
};
await foreach (var result in pipeline.ProcessAsync(new DirectoryInfo("."), searchPattern: "*.md"))
{
Console.WriteLine($"Completed processing '{result.DocumentId}'. Succeeded: '{result.Succeeded}'.");
}
Tek bir belge işleme hatası, işlem hattının bütününü başarısız yapmamalıdır. Bu nedenle IngestionPipeline<T>.ProcessAsync döndürerek IAsyncEnumerable<IngestionResult> kısmi başarı uygular. Çağrıyı yapan, hataların işlenmesinden sorumludur (örneğin, başarısız belgeleri yeniden deneyerek veya ilk hatada durdurarak).
GitHub'da bizimle işbirliği yapın
Bu içeriğin kaynağı GitHub'da bulunabilir; burada ayrıca sorunları ve çekme isteklerini oluşturup gözden geçirebilirsiniz. Daha fazla bilgi için katkıda bulunan kılavuzumuzu inceleyin.