Makine öğrenimi modellerinin sonuçları
Bu makalede, makine öğrenimi (ML) modellerindeki karışıklık matrisleri, sınıflandırma problemleri ve doğruluk konuları ele alınmaktadır. Amaç, ML tahmin sonuçlarındaki doğruluğu daha iyi anlamanıza yardımcı olmaktır. Hedef kitle, veri bilimi alanında bilgi ve becerilerini geliştirmek isteyen mühendisleri, analistleri ve yöneticileri kapsar.
Karışıklık matrisi
Denetlenen bir ML problemi belirli bir geçmiş veriler kümesinde eğitildikten sonra eğitim sürecinde kullanılmayan verilerle test edilir. Bu şekilde, eğitilen modellerdeki tahminleri gerçek değerlerle karşılaştırabilirsiniz. Karışıklık matrisi, bir sınıflandırma probleminin başarısını ve hata yaptığı yerleri ("karışıklık" oluşan yerleri) değerlendirme yöntemi sunar.
Örneğin, bir evcil hayvanın bazı fiziksel özniteliklere ve davranış özniteliklerine göre köpek mi yoksa kedi mi olduğunu tahmin etmeyi amaçladığınızı düşünelim. 30 köpek ve 20 kedi içeren bir veri kümeniz varsa karışıklık matrisi aşağıdaki çizime benzeyebilir.
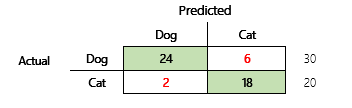
Yeşil hücrelerdeki sayılar doğru tahminleri temsil eder. Gördüğünüz gibi model, gerçek kedileri daha yüksek bir oranla doğru tahmin etti. Modelin genel doğruluğunu hesaplamak kolaydır. Bu durumda doğruluk şudur: 42 ÷ 50 veya 0,84.
Bir karışıklık matrisinde çok sınıflandırıcılar
Karışıklık matrisiyle ilgili tartışmaların çoğu, önceki örnekteki gibi ikili sınıflandırıcılara odaklanır. Bu durum, duyarlılık ve yakalama gibi diğer ölçümlerin dikkate alınabileceği özel bir durumdur.
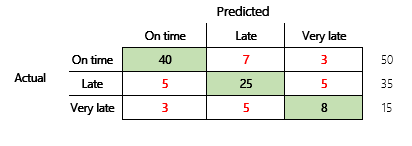
Daha sonra, üç durumlu bir mali senaryo için bir sınıflandırma problemini ele alacağız. Model, bir müşteri faturasının zamanında, geç veya çok geç ödenme durumunu tahmin eder. Örneğin, 100 test faturasından 50'si zamanında ödenir, 35'i geç ödenir ve 15'i çok geç ödenir. Bu durumda, bir model aşağıdaki şekile benzeyen bir karışıklık matrisi üretebilir.
 ]
]
Bir karışıklık matrisi, basit bir doğruluk ölçümüne kıyasla önemli ölçüde daha fazla bilgi sağlar. Ancak, anlaşılması yine de daha kolaydır. Bir karışıklık matrisi, çıkış sınıfı sayılarının benzer olduğu dengeli bir veri kümesine sahip olup olmadığınızı gösterir. Çoklu sınıf senaryosu için müşteri ödemelerini ele alan bir önceki örnekte olduğu gibi, çıkış sınıflarının sıralı olduğu durumlarda tahminin gerçek değerlerden ne kadar uzakta olabileceğini gösterir.
Model doğruluğu
Farklı doğruluk ölçümlerinin model kalitesini ölçme avantajı bulunur.
Doğruluk anlaşılması kolay bir ölçüm olduğundan, modeli başta veri bilimci olmayan model kullanıcıları olmak üzere diğer kişilere açıklamak için iyi bir başlangıç noktasıdır. Modelin doğruluğunu anlamak için istatistiklerin anlaşılmasına gerek yoktur. Karışıklık matrisi sunulduğunda modelin performansı hakkında ayrıntılı bilgiler sağlanır.
Ancak, modelin daha kapsamlı anlaşılması için doğrulukla ilgili bazı zorluklara dikkat edilmelidir. Ölçümün kullanışlılığı problemin bağlamına bağlıdır. Model performansıyla ilgili olarak genellikle "Model ne kadar iyidir?" numaralı bir soru ortaya çıkar Ancak, bu sorunun yanıtının basit olması gerekmez. Aşağıdaki karışıklık matrisini göz önünde bulundurun (model 2).
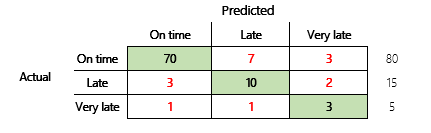
Hızlı bir hesaplamayla bu modelin doğruluğu (70 + 10 + 3) ÷ 100 veya 0,83 olarak bulunabilir. Görünüşte bu sonuç, 0,73 doğruluğa sahip olan bir önceki çok sınıflı modelin (model 1) sonucundan daha iyi görünebilir. Ancak daha iyi midir?
Bu soruyu ele almak için basit bir tahminin doğruluğunu düşünelim. Sınıflandırma problemlerinde basit bir tahmin, her zaman en yaygın sınıfı tahmin eder. Model 1 için bu tahmin "zamanında" olacak ve 0,50 doğruluk üretecektir. Model 2 için de tahmin "zamanında" olacak ve 0,80 doğruluk üretecektir. Model 1; 0,73 – 0,50 = 0,23 basit tahmininden yola çıkarken model 2; 0,83 – 0,80 = 0,03 basit tahmininden yola çıktığı için model 1'in doğruluğu daha düşük olsa da daha iyi bir modeldir. Bu hesaplamda, model kalitesinin etkili şekilde değerlendirilmesi için doğruluk değerinden daha fazla bağlam gerektiği gösterilmiştir.
Dikkate alınması gereken bir başka husus daha vardır. Bir hastada hastalığın tespiti için tıbbi bir testin kullanıldığı bir senaryoyu ele alalım. Bu problem, pozitif sonucun hastanın hastalığa sahip olduğunu gösteren ikili sınıflandırma problemidir. Bu senaryoda, aşağıdaki hataların etkisini dikkate almalısınız:
- Testin hastanın hastalığa sahip olduğunu göstermesine rağmen hastanın, hastalığa sahip olmadığı hatalı pozitif sonuçlar.
- Testin hastanın hastalığa sahip olmadığını göstermesine rağmen hastanın, aslında hastalığa sahip olduğu hatalı negatif sonuçlar.
Elbette iki hata türü de istenmeyen sonuçlardır ancak hangisi daha kötüdür? Bu da duruma göre değişir. Hayati tehlike oluşturan ve hızlı tedavi gerektiren bir hastalıkta hatalı negatiflerin azaltılması (ve ek testlerin yapılması) önceliklidir. Daha az kritik durumlarda, modeli oluşturanlar bunun yerine hatalı pozitif durumları en aza düşürebilir. Her durumda, bu örnekten modelin kalitesini etkili bir şekilde belirlemek için doğruluk ölçümünün sağladığından daha fazla bilgiye sahip olmanız gerektiği sonucu çıkarılabilir.
Öneriler
Doğruluk, istatistiklere aşina olmayan etki alanı uzmanlarıyla iletişim kurmak için önemli bir araçtır. Ancak bu bilgilerin yararlı olması için doğruluk değeriyle birlikte bağlam hakkında ek bilgilerin sağlanması kritik önem taşır.
Ödeme tahmini senaryosu için, farklı ödeme davranışlarıyla ilgili faktörleri içeren bir ML modeli hedefi belirleyebilirsinzi. Hedef, modelin yanlış sayısını en az yüzde 50 azaltarak basit bir tahmini geliştirmesidir. Diğer bir ifadeyle, basit bir tahminin doğruluğuyla yüzde 100 arasındaki farkı yarıya bölen bri hedef doğruluğu istiyorsunuz.
Aşağıdaki tabloda bu makaledeki karışıklık matrisleri için bu ilke özetlenmiştir.
| Model | Basit tahmin | Hedef | Model doğruluğu | Hedefe ulaşıldı mı? |
|---|---|---|---|---|
| Model 1 | 0.50 | 0.75 | 0.73 | Neredeyse. Bu model tahmini önemli ölçüde iyileştirir. |
| Model 2 | 0.80 | 0.90 | 0.83 | Hayır. İyileştirme gereklidir. |
Sınıflandırma F1 doğruluğu
Bu makalede dikkate alınması gereken en son husus, sınıflandırma ML performansının daha gelişmiş bir ölçümü olan F1 doğruluğudur.
F1 doğruluğunu tanımlamadan önce iki ek ölçüm açıklanmalıdır: duyarlık ve yakalama. Duyarlık, pozitif olarak belirtilen toplam tahmin sayısından kaç tanesinin doğru atandığını gösterir. Bu ölçüm pozitif tahmine dayalı değer olarak da bilinir. Yakalama, doğru şekilde öngörülen gerçek pozitif durumların toplam sayısıdır. Bu ölçüm aynı zamanda hassasiyet olarak da bilinir.
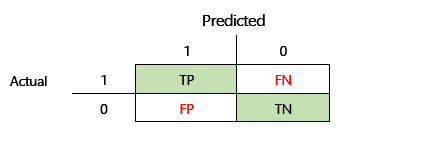
Önceki çizimdeki karışıklık matrisinde bu ölçümler aşağıdaki şekilde hesaplanır:
- Duyarlık = TP ÷ (TP + FP)
- Yakalama = TP ÷ (TP + FN)
F1 ölçümü, duyarlık ile yakalamayı birleştirir. Sonuçta iki değerin harmonik ortalaması elde edilir. Aşağıdaki şekilde hesaplanır:
- F1 = 2 × (Duyarlık × Yakalama) ÷ (Duyarlık + Yakalama)
Daha somut bir örneği inceleyelim. Bu makalenin ilk kısmında bir hayvanın köpek mi kedi mi olduğunu tahmin eden bir modeli incelemiştik. Çizimi burada tekrar inceleyelim.
"Köpek" pozitif yanıt olarak kullanılırsa sonuçlar aşağıdaki gibi olur.
- Duyarlık = 24 ÷ (24 + 2) = 0,9231
- Yakalama = 24 ÷ (24 + 6) = 0,8
- F1 = 2 × (0,9231 × 0,8) ÷ (0,9231 + 0,8) = 0,8572
Gördüğünüz gibi, F1 değeri duyarlık ve yakalama değerlerinin arasındadır.
F1 doğruluğu kolay anlaşılır olmasa da temel doğruluk numarasının yanında ince ayrıntıları da gösterir. Ayrıca, aşağıda ele alındığı üzere dengesiz veri kümelerinde de faydalı olur.
Bu makalenin Model doğruluğu bölümünde aşağıdaki iki karışıklık matrisi karşılaştırılmıştır. İlk modelin doğruluk değeri daha düşük olsa da varsayılan zamanında ödeme tahmininden daha fazla iyileşme gösterdiği için daha kullanışlı bir model olduğu kabul edilmiştir.
F1 puanı kullanıldığında bu iki modelin karşılaştırmasının nasıl olacağını inceleyelim. F1 puanı, her durum için duyarlığı ve yakalamayı hesaba katar ve ardından F1 makro hesaplaması, genel bir F1 puanı belirlemek için durumlar genelinde F1 puanlarının ortalamasını alır. Başka F1 türevleri de mevcuttur ancak her üç duruma da verilen eşit önem göz önünde bulundurulduğunda makro sürümü dikkate almak daha önemlidir.
Hesaplamaları basitleştirmek amacıyla gerçek ve öngörülen değerleri eşleştirmek için örnek diziler oluşturulmuştur. Bu diziler değerleri hesaplamak için Python'daki sklearn ölçümler kitaplığını kullanır. Sonuç aşağıdaki gibidir.
| Model | Basit tahmin | Doğruluk | F1 makro |
|---|---|---|---|
| Model 1 | 0.5 | 0.73 | 0.67 |
| Model 2 | 0.80 | 0.83 | 0.66 |
Bu hesaplamanın nasıl çalıştığı hakkında daha ayrıntılı bilgiyi model 1 için sklearn.metrics sınıflandırma raporunda bulabilirsiniz. "Zamanında", "Geç" ve "Çok geç" olmak üzere üç durum, sırasıyla 1, 2 ve 3 olarak etiketlenen satırlarla temsil edilir. Makro ortalaması yalnızca "f1-score" sütununun ortalamasıdır.
| duyarlık | yakalama | f1-score | |
|---|---|---|---|
| 1 | 0.83 | 0.80 | 0.82 |
| 2 | 0.68 | 0.71 | 0.69 |
| 3 | 0.50 | 0.50 | 0.50 |
Bu sonuçlarda gösterildiği gibi iki model, neredeyse aynı F1 makro doğruluk puanlarına sahiptir. Bunun gibi daha pek çok örnekte F1 doğruluğu, modelin becerilerini daha iyi gösterir. Doğruluk açısından, bu sonuçları yorumlayabilmek için modelde dikkate alınması gereken en önemli unsuru anlamış olmanız gerekir.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin