Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu hızlı başlangıç kılavuzunda, verileri bir lakehouse'a getirmek ve ardından bir SQL analiz uç noktası aracılığıyla sunmak üzere Spark Structured Streaming kullanan Python kodu içeren bir Spark İş Tanımı oluşturmanın nasıl yapılacağı açıklanmaktadır. Bu hızlı başlangıcı tamamladıktan sonra sürekli çalışan bir Spark İş Tanımına sahip olursunuz ve SQL analiz uç noktası gelen verileri görüntüleyebilir.
Python betiği oluşturun
Bir lakehouse tablosuna veri almak için Spark yapılandırılmış akışı kullanan aşağıdaki Python kodunu kullanın.
import sys from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.appName("MyApp").getOrCreate() tableName = "streamingtable" deltaTablePath = "Tables/" + tableName df = spark.readStream.format("rate").option("rowsPerSecond", 1).load() query = df.writeStream.outputMode("append").format("delta").option("path", deltaTablePath).option("checkpointLocation", deltaTablePath + "/checkpoint").start() query.awaitTermination()Betiğinizi yerel bilgisayarınıza Python dosyası (.py) olarak kaydedin.
Göl evi oluşturma
Göl evi oluşturmak için aşağıdaki adımları kullanın:
Microsoft Fabric portalınaoturum açın.
İstediğiniz çalışma alanına gidin veya gerekirse yeni bir çalışma alanı oluşturun.
Bir göl evi oluşturmak için çalışma alanından Yeni öğe'yi ve ardından açılan panelde Lakehouse'u seçin.
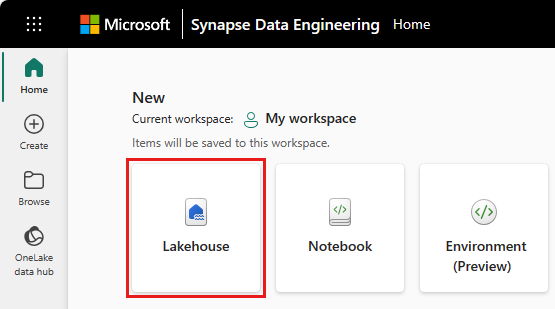
Göl evinizin adını girin ve Oluştur'u seçin.

Spark İş Tanımı Oluşturma
Spark İş Tanımı oluşturmak için aşağıdaki adımları kullanın:
Göl evi oluşturduğunuz çalışma alanından Yeni öğe'yi seçin.
Açılan paneldeki Veri Al altında Spark İş Tanımı'nı seçin.
Spark İş Tanımınızın adını girin ve Oluştur'u seçin.
Karşıya Yükle'yi seçin ve önceki adımda oluşturduğunuz Python dosyasını seçin.
Lakehouse Referansı altında oluşturduğunuz lakehouse'u seçin.
Spark İş Tanımı için Yeniden Deneme ilkesini ayarlama
Spark iş tanımınız için yeniden deneme ilkesini ayarlamak için aşağıdaki adımları kullanın:
Üst menüden Ayar simgesini seçin.
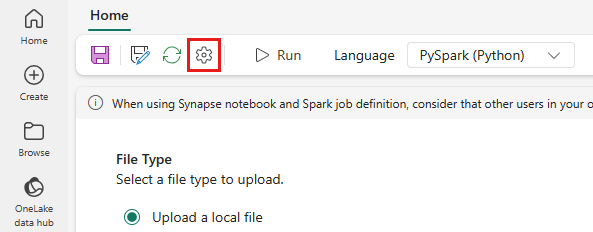
Optimizasyon sekmesini açın ve Yeniden Deneme Politikası tetikleyicisini Açık olarak ayarlayın.
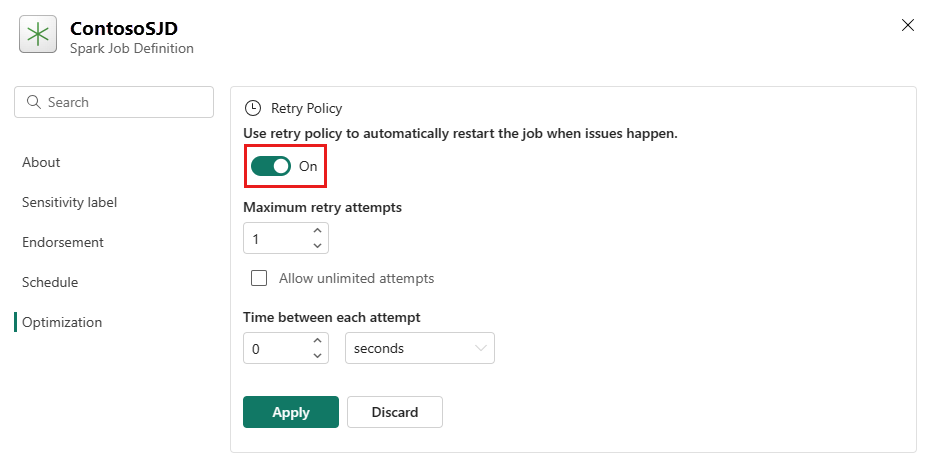
En fazla yeniden deneme denemesi tanımlayın veya Sınırsız denemeye izin ver'i işaretleyin.
Her yeniden deneme girişimi arasındaki süreyi belirtin ve Uygula'yı seçin.
Not
Yeniden deneme ilkesi kurulumu için 90 günlük bir yaşam süresi sınırı vardır. Yeniden deneme ilkesi etkinleştirildikten sonra, iş 90 gün içinde ilkeye göre yeniden başlatılır. Bu süre sonunda yeniden deneme ilkesi otomatik olarak çalışmaz ve iş sonlandırılır. Daha sonra kullanıcıların işi el ile yeniden başlatması gerekir ve bu da yeniden deneme ilkesini yeniden etkinleştirir.
Spark İş Tanımını yürütme ve izleme
Üstteki menüden Çalıştır simgesini seçin.
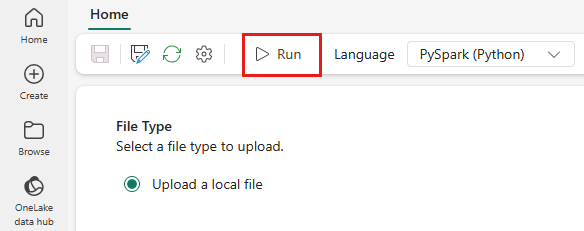
Spark İşi tanımının başarıyla gönderilip gönderilmediğini ve çalıştığını doğrulayın.
SQL analytics uç noktasını kullanarak verileri görüntüleme
Çalışma alanı görünümünde Lakehouse'unuzu seçin.
Sağ köşede Lakehouse'ı ve ardından SQL analiz uç noktasını seçin.
Tablolar'ın altındaki SQL analizi uç noktası görünümünde betiğinizin verileri almak için kullandığı tabloyu seçin. Ardından SQL analytics uç noktasından verilerinizin önizlemesini görüntüleyebilirsiniz.