Lakehouse'unuza veri yüklemek için not defteri kullanma
Bu öğreticide, bir not defteriyle Fabric lakehouse'unuza veri okuma/yazma hakkında bilgi edinin. Doku, Spark API'sini destekler ve Pandas API bu hedefe ulaşmak için kullanılır.
Apache Spark API'siyle veri yükleme
Not defterinin kod hücresinde aşağıdaki kod örneğini kullanarak kaynaktaki verileri okuyun ve dosyalar, tablolar veya göl evinizdeki her iki bölüme yükleyin.
Okunacak konumu belirtmek için, veriler geçerli not defterinizin varsayılan lakehouse'undan geliyorsa göreli yolu kullanabilirsiniz. Veya veriler farklı bir göl evinden geliyorsa, mutlak Azure Blob Dosya Sistemi (ABFS) yolunu kullanabilirsiniz. Bu yolu verilerin bağlam menüsünden kopyalayın.
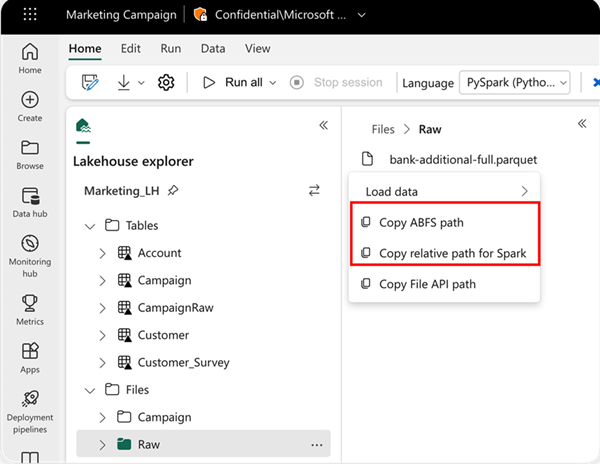
ABFS yolunu kopyala: Bu seçenek dosyanın mutlak yolunu döndürür.
Spark için göreli yolu kopyala: Bu seçenek, varsayılan lakehouse'unuzda dosyanın göreli yolunu döndürür.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Pandas API ile veri yükleme
Pandas API'sini desteklemek için varsayılan lakehouse otomatik olarak not defterine bağlanır. Bağlama noktası:'/lakehouse/default/'. Bu bağlama noktasını, varsayılan lakehouse'dan/bu göl evinden veri okumak/yazmak için kullanabilirsiniz. Bağlam menüsündeki "Dosya API Yolunu Kopyala" seçeneği, bu bağlama noktasından Dosya API'sinin yolunu döndürür. ABFS yolunu kopyala seçeneğinden döndürülen yol Pandas API'sinde de çalışır.
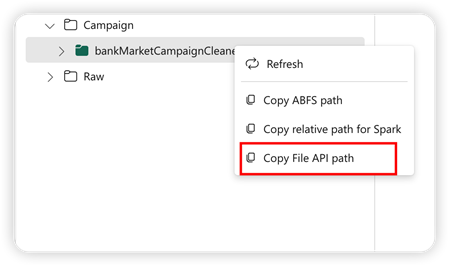
Dosya API'sinin Yolunu Kopyala: Bu seçenek, varsayılan lakehouse'un bağlama noktasının altındaki yolu döndürür.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
İpucu
Spark API'sinde, dosyanın yolunu almak için lütfen Spark için ABFS yolunu kopyala veya Göreli yolu kopyala seçeneğini kullanın. Pandas API'sinde , dosyanın yolunu almak için lütfen ABFS yolunu kopyala veya Dosya API'sini Kopyala yolunu kullanın.
Kodun Spark API veya Pandas API ile çalışmasını sağlamanın en hızlı yolu Verileri yükle seçeneğini kullanmak ve kullanmak istediğiniz API'yi seçmektir. Kod, not defterinin yeni bir kod hücresinde otomatik olarak oluşturulur.

İlgili içerik
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin