Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Yerel yürütme altyapısı, Microsoft Fabric'teki Apache Spark iş yürütmeleri için çığır açan bir geliştirmedir. Bu vektörleştirilmiş altyapı, Spark sorgularınızı doğrudan göl evi altyapınızda çalıştırarak performansı ve verimliliğini iyileştirir. Motorun sorunsuz entegrasyonu, kod değişikliği gerektirmemesi ve bir satıcıya bağımlı kalmayı önlemesi anlamına gelir. Apache Spark API'lerini destekler ve Çalışma Zamanı 1.3 (Apache Spark 3.5) ve Çalışma Zamanı 2.0 (Apache Spark 4.1) ile uyumludur ve Parquet, Delta ve CSV biçimleriyle çalışır. Verilerinizin OneLake içindeki konumu ne olursa olsun veya verilere kısayollar aracılığıyla erişiyorsanız, yerel yürütme altyapısı verimliliği ve performansı en üst düzeye çıkarır.
Yerel yürütme altyapısı, operasyonel maliyetleri en aza indirirken sorgu performansını önemli ölçüde artırır. Gerçek sonuçlar iş yükü özelliklerine ve yapılandırmasına göre değişir. Altyapı, rutin veri alımı, toplu işler ve ETL (ayıklama, dönüştürme, yükleme) görevlerinden karmaşık veri bilimi analizine ve duyarlı etkileşimli sorgulara kadar çok çeşitli veri işleme senaryolarını yönetme konusunda ustadır. Kullanıcılar hızlandırılmış işleme sürelerinden, daha yüksek aktarım hızından ve iyileştirilmiş kaynak kullanımından yararlanır.
Yerel Yürütme Altyapısı iki önemli işletim sistemi bileşenini temel alır: Meta tarafından sunulan bir C++ veritabanı hızlandırma kitaplığı olan Velox ve JVM tabanlı SQL altyapılarının yürütmesini Intel tarafından sunulan yerel altyapılara boşaltmaktan sorumlu bir orta katman olan Apache Glüten (inkübating).
Desteklenen işleçler JVM tabanlı Spark'tan vektörleştirilmiş bir C++ yürütme yoluna yüklenerek Parquet ve Delta biçimleri için yerel destekle sütunlu, SIMD hızlandırmalı işleme sağlanır. Yerel altyapı, uyarlamalı sorgu yürütme (AQE), maliyet tabanlı yeniden yazma işlemleri, sütun ayıklama ve koşul gönderme dahil olmak üzere önemli Doku Spark sorgu iyileştirmelerini korur, böylece işleçler boşaltıldığında bu iyileştirici davranışları tamamen etkin kalır. Altyapı ayrıca paralel Delta anlık görüntüsü yüklemeyi destekler ve Delta tablolarında Z sıralama ve Sıvı Kümeleme'den yararlanan işlemleri hızlandırarak düzenli veri düzenleri için daha fazla performans kazancı sağlar.
Yerel yürütme motoru ne zaman kullanılmalı?
Yerel yürütme altyapısı, büyük ölçekli veri kümelerinde sorgu çalıştırmak için bir çözüm sunar; temel alınan veri kaynaklarının yerel özelliklerini kullanarak ve genellikle geleneksel Spark ortamlarında veri taşıma ve serileştirme ile ilişkili ek yükü en aza indirerek performansı iyileştirir. Motor, rollup hash toplama, yayın iç içe döngü birleştirmesi (BNLJ) ve hassas zaman damgası biçimleri dahil olmak üzere çeşitli işleçleri ve veri türlerini destekler. Ancak, motorun özelliklerinden tam olarak yararlanmak için en uygun kullanım örneklerini göz önünde bulundurmanız gerekir:
- Motor, Parquet ve Delta biçimlerindeki verilerle çalışırken etkilidir; bu verileri yerel ve verimli bir şekilde işleyebilir.
- Karmaşık dönüştürmeler ve toplamalar içeren sorgular, altyapının sütunlu işleme ve vektörleştirme özelliklerinden önemli ölçüde yararlanır.
- Performans geliştirmesi, sorguların desteklenmeyen özelliklerden veya ifadelerden kaçınarak geri dönüş mekanizmasını tetiklemediği senaryolarda en dikkat çekicidir.
- Motor, basit veya G/Ç bağlı olmayan, hesaplama açısından yoğun sorgular için uygundur.
Yerel yürütme altyapısı tarafından desteklenen işleçler ve işlevler hakkında bilgi için Apache Gluten belgelerine bakın.
Yerel yürütme motorunu etkinleştir
Önizleme aşamasında yerel yürütme altyapısının tüm özelliklerini kullanmak için belirli yapılandırmalar gereklidir. Aşağıdaki yordamlarda not defterleri, Spark iş tanımları ve tüm ortamlar için bu özelliğin nasıl etkinleştirileceği gösterilmektedir.
Önemli
Yerel yürütme altyapısı Çalışma Zamanı 1.3 (Apache Spark 3.5, Delta Lake 3.2) ve Çalışma Zamanı 2.0 'ı (Apache Spark 4.1, Delta Lake 4.1) destekler.
Ortam düzeyinde etkinleştirme
Tekdüzen performans geliştirmesi sağlamak için ortamınızla ilişkili tüm işlerde ve not defterlerinde yerel yürütme altyapısını etkinleştirin:
Ortamınızı içeren çalışma alanına gidin ve ortamı seçin. Eğer bir ortam oluşturmadıysanız, Fabric'de ortam oluşturma, yapılandırma ve kullanma bölümüne bakın.
Spark işlem altında Hızlandırma'ya tıklayın.
Yerel yürütme motorunu etkinleştir etiketli kutuyu işaretleyin.
Değişiklikleri kaydedin ve yayımlayın .
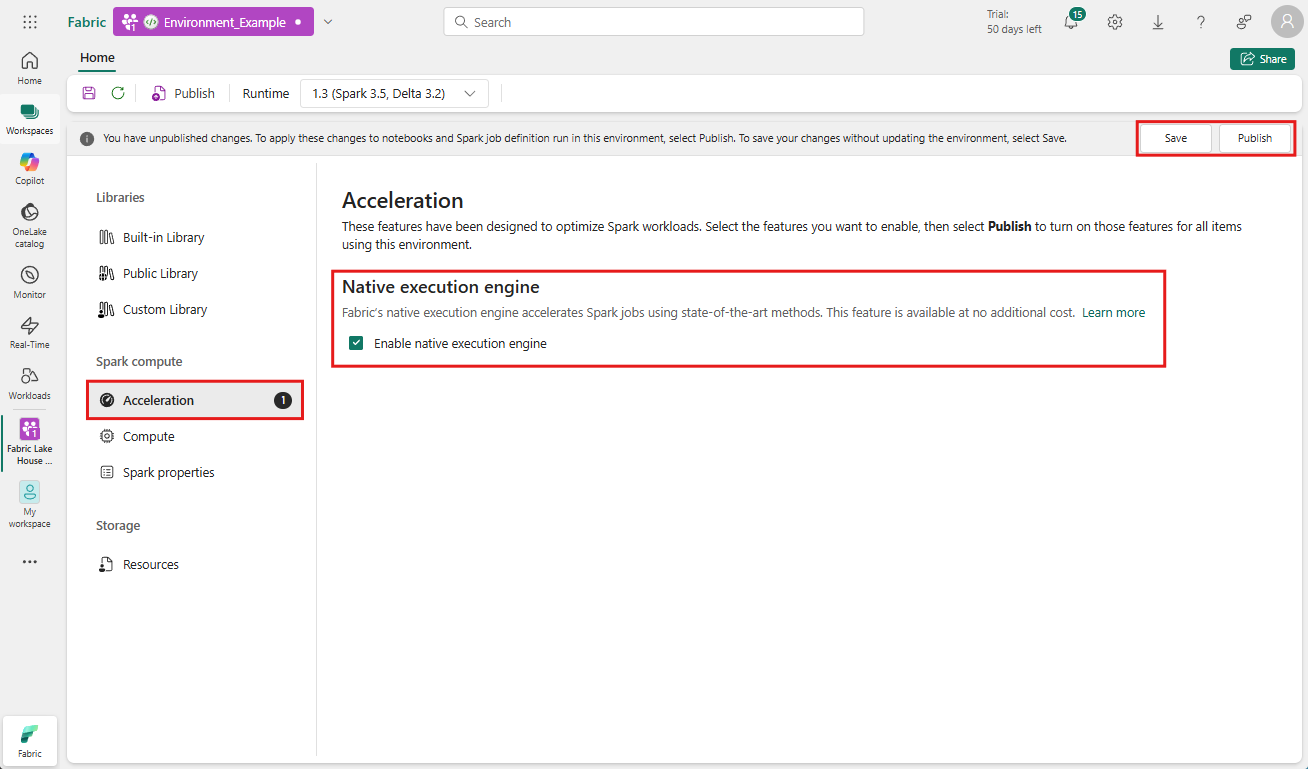

Ortam düzeyinde etkinleştirildiğinde, sonraki tüm işler ve not defterleri ayarı devralır. Bu devralma, ortamda oluşturulan tüm yeni oturumların veya kaynakların gelişmiş yürütme özelliklerinden otomatik olarak yararlanmasını sağlar.
Önemli
Daha önce yerel yürütme altyapısı, ortam yapılandırmasındaki Spark ayarları aracılığıyla etkinleştirildi. Yerel yürütme altyapısı artık ortam ayarlarının Hızlandırma sekmesindeki bir geçiş tuşu kullanılarak daha kolay etkinleştirilebilir. Kullanmaya devam etmek için Hızlandırma sekmesine gidin ve anahtarı açın. İsterseniz Spark özellikleri aracılığıyla da etkinleştirebilirsiniz.
Not defteri veya Spark iş tanımı için etkinleştirme
Yerel yürütme altyapısını tek bir not defteri veya Spark iş tanımı için de etkinleştirebilirsiniz; yürütme betiğinizin başında gerekli yapılandırmaları dahil etmeniz gerekir:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Not defterleri için gerekli yapılandırma komutlarını ilk hücreye ekleyin. Spark iş tanımları için, Spark iş tanımınızın ön cephesine yapılandırmaları ekleyin. Yerel Yürütme Altyapısı canlı havuzlarla tümleşiktir, bu nedenle özelliği etkinleştirdikten sonra yeni bir oturum başlatmanıza gerek kalmadan hemen geçerlilik kazanır.
Sorgu düzeyinde denetim
Yerel Yürütme Altyapısı'nı kiracı, çalışma alanı ve ortam düzeylerinde etkinleştirme mekanizmaları, kullanıcı arabirimiyle sorunsuz bir şekilde tümleştirilmiştir ve etkin geliştirme aşamasındadır. Bu arada, özellikle şu anda desteklenmeyen işleçler içeriyorsa belirli sorgular için yerel yürütme altyapısını devre dışı bırakabilirsiniz (bkz . sınırlamalar). Devre dışı bırakmak için spark.native.enabled Spark yapılandırmasını sorgunuzu içeren belirli bir hücre için false olarak ayarlayın.
%%sql
SET spark.native.enabled=FALSE;

Yerel yürütme altyapısının devre dışı bırakıldığı sorguyu yürütürken spark.native.enabled değerini true olarak ayarlayarak sonraki hücreler için yeniden etkinleştirmeniz gerekir. Spark kod hücrelerini sırayla yürüttüğü için bu adım gereklidir.
%%sql
SET spark.native.enabled=TRUE;
Motor tarafından yürütülen işlemleri tanımlama
Apache Spark işinizdeki bir işlecin yerel yürütme altyapısı kullanılarak işlenip işlenmediğini belirlemek için çeşitli yöntemler vardır.
Spark kullanıcı arabirimi ve Spark geçmiş sunucusu
İncelemeniz gereken sorguyu bulmak için Spark kullanıcı arabirimine veya Spark geçmiş sunucusuna erişin. Spark web kullanıcı arabirimine erişmek için Spark İş Tanımınıza gidin ve çalıştırın. Çalıştırmalar sekmesinde, Uygulama adı yanındaki ... seçin ve ardından Spark web kullanıcı arabirimini Açseçin. Spark kullanıcı arabirimine çalışma alanının İzleyici sekmesinden de erişebilirsiniz. İzleme sayfasından not defterini veya işlem hattını seçin, etkin işler için doğrudan bir Spark UI bağlantısı mevcuttur.
spark web kullanıcı arabirimine nasıl gidilir gösteren ekran görüntüsü 
Spark UI arabiriminde görüntülenen sorgu planında, Transformer, *NativeFileScan veya

DataFrame açıklaması
Alternatif olarak, yürütme planını görüntülemek için komutunu not defterinizde yürütebilirsiniz df.explain() . Çıktıda, aynı Transformer, *NativeFileScan veya VeloxColumnarToRowExec soneklerini arayın. Bu yöntem, belirli işlemlerin yerel yürütme altyapısı tarafından işlenip işlenmediğini onaylamak için hızlı bir yol sağlar.

Fabric Spark Danışmanı uyarıları
Fabric Spark Danışmanı, not defteri hücresinin yürütülmesi sırasında gerçek zamanlı yedekleme görünürlüğü sağlar. İşleç veya plan kesimi yerel yol yerine JVM tabanlı Spark'a geri döndüğünde Danışman, not defterinden çıkmadan desteklenmeyen işleçleri veya yapılandırmaları hızla belirlemenize yardımcı olan bir uyarıyı doğrudan not defteri hücre çıkışına gösterir. Yerel boşaltmanın ne zaman uygulanmadığını tanılamak ve sorgunuzu veya yapılandırmanızı ayarlayıp ayarlamamaya karar vermek için bu uyarıları kullanabilirsiniz.
Geri dönüş mekanizması
Bazı durumlarda, desteklenmeyen özellikler gibi nedenlerle yerel yürütme altyapısı sorgu yürütemeyebilir. Bu gibi durumlarda, geleneksel Spark motoruna dönülür. Bu otomatik geri dönüş mekanizması, iş akışınızda kesinti olmamasını sağlar.


Motor tarafından yürütülen sorguları ve DataFrame'leri izleme
Yerel Yürütme altyapısının SQL sorgularına ve DataFrame işlemlerine nasıl uygulandığını daha iyi anlamak ve aşama ve işleç düzeylerinde detaya gitmek için, yerel altyapı yürütmesi hakkında daha ayrıntılı bilgi için Spark kullanıcı arabirimine ve Spark Geçmiş Sunucusu'na başvurabilirsiniz.
Yerel Yürütme Altyapısı Sekmesi
Glüten derleme bilgilerini ve sorgu yürütme ayrıntılarını görüntülemek için yeni 'Gluten SQL / DataFrame' sekmesine gidebilirsiniz. Sorgular tablosu, her sorgu için Yerel motor üzerinde çalışan düğüm sayısı ve JVM'ye geri dönen düğümler hakkında içgörüler sağlar.

Sorgu Yürütme Grafı
Apache Spark sorgu yürütme planı görselleştirmesi için sorgu açıklamasında da seçim yapabilirsiniz. Yürütme grafı, aşamalar ve bunların ilgili işlemleri arasında doğal yürütme ayrıntılarını sağlar. Arka plan renkleri yürütme altyapılarını ayırt eder: yeşil, Yerel Yürütme Altyapısı'nı temsil ederken açık mavi, işlemin varsayılan JVM Altyapısı'nda çalıştığını gösterir.

Sınırlamalar
Microsoft Fabric'teki Yerel Yürütme Altyapısı (NEE), Apache Spark işlerinin performansını önemli ölçüde artırsa da şu anda aşağıdaki sınırlamalara sahiptir:
Mevcut sınırlamalar
Uyumsuz Spark özellikleri: Yerel yürütme altyapısı şu anda yapılandırılmış akışı desteklemez. Desteklenmeyen özellikler doğrudan veya içeri aktarılan kitaplıklar aracılığıyla kullanılıyorsa Spark varsayılan altyapısına geri döner. Python UDF'ler, Scala UDF'leri ve karmaşık veri türleri (diziler, haritalar, yapılar) artık desteklenmektedir. Daha fazla bilgi için yerel yürütme altyapısında Python UDF'leri, Scala UDF'leri ve karmaşık veri türleri bölümüne bakın.
Desteklenmeyen dosya biçimleri: ve
JSONbiçimlerine yönelikXMLsorgular yerel yürütme altyapısı tarafından hızlandırılmaz. Bunlar varsayılan olarak yürütme için normal Spark JVM altyapısına döner. CSV artık vektörleştirilmiş CSV ayrıştırıcısı aracılığıyla desteklenmektedir.ANSI modu desteklenmiyor: Yerel yürütme altyapısı ANSI SQL modunu desteklemez. Etkinleştirilirse yürütme, standart Spark motoruna geri döner.
Tarih filtresi türü uyuşmazlıkları: Yerel yürütme altyapısının hızlandırmasından yararlanmak için tarih karşılaştırmasının her iki tarafının da veri türünde eşleştiğinden emin olun. Örneğin, bir
DATETIMEsütunu bir dize değişmez değeriyle karşılaştırmak yerine, açıkça gösterildiği gibi dönüştürün:CAST(order_date AS DATE) = '2024-05-20'
Diğer önemli noktalar ve sınırlamalar
Ondalıktan Kayan Noktalı Sayıya Dönüştürme Uyuşmazlığı:
DECIMAL'denFLOAT'e tür dönüşü yapılırken Spark, duyarlılığı korumak için veriyi önce dizeye dönüştürür ve sonra onu ayrıştırır. NEE (Velox aracılığıyla), içint128_tgösterimden doğrudan dönüştürme işlemi gerçekleştirir, bu da yuvarlama tutarsızlıklarına neden olabilir.Saat dilimi yapılandırma hataları : Spark'ta tanınmayan bir saat diliminin ayarlanması işin NEE altında başarısız olmasına neden olurken Spark JVM bunu düzgün bir şekilde işler. Örneğin:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEETutarsız yuvarlama davranışı:
round()işlevi, Spark’ın yuvarlama mantığını çoğaltmayanstd::roundöğesine bağlı olduğu için NEE'de farklı şekilde çalışır. Bu, yuvarlama sonuçlarında sayısal tutarsızlıklara yol açabilir.Yinelenen anahtar kontrolü eksik
map()işlevi:spark.sql.mapKeyDedupPolicyÖZEL DURUM olarak ayarlandığında Spark, yinelenen anahtarlar için bir hata verir. NEE şu anda bu denetimi atlar ve sorgunun yanlış başarılı olmasını sağlar.
Örnek:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Sipariş varyansı
collect_list()ile sıralama:DISTRIBUTE BYveSORT BYkullanırken Spark'ta öğe sırasınıcollect_list()korur. NEE, karıştırma farklılıkları nedeniyle değerleri farklı bir sırada döndürebilir ve bu da sıralamaya duyarlı mantık için eşleşmeyen beklentilere neden olabilir.collect_list()/collect_set()için ara tür uyuşmazlığı: Spark bu toplamalar için ara tür olarakBINARYkullanırken, NEEARRAYkullanır. Bu uyuşmazlık, sorgu planlama veya yürütme sırasında uyumluluk sorunlarına yol açabilir.Depolama erişimi için gereken yönetilen özel uç noktalar: Yerel Yürütme Altyapısı (NEE) etkinleştirildiğinde ve Spark işleri yönetilen özel uç nokta kullanarak depolama hesabına erişmeye çalışıyorsa, kullanıcıların aynı depolama hesabına işaret etseler bile hem Blob (blob.core.windows.net) hem de DFS / Dosya Sistemi (dfs.core.windows.net) uç noktaları için ayrı yönetilen özel uç noktalar yapılandırması gerekir. Her ikisi için de tek bir uç nokta yeniden kullanılamaz. Bu geçerli bir sınırlamadır ve depolama hesapları için yönetilen özel uç noktaları olan bir çalışma alanında yerel yürütme altyapısını etkinleştirirken ek ağ yapılandırması gerektirebilir.