Not defterlerinde gerçek zamanlı öneriler için Apache Spark danışmanı
Apache Spark danışmanı, Apache Spark tarafından çalıştırılan komutları ve kodları analiz eder ve Not Defteri çalıştırmaları için gerçek zamanlı öneriler görüntüler. Apache Spark danışmanı, kullanıcıların yaygın hatalardan kaçınmasına yardımcı olmak için yerleşik desenlere sahiptir. Kod iyileştirme önerileri sunar, hata analizi gerçekleştirir ve hataların kök nedenini bulur.
Yerleşik öneriler
Impulse ile tümleşik bir araç olan Spark danışmanı, Apache Spark uygulamalarında sorunları algılamak ve çözmek için yerleşik desenler sağlar. Bu makalede, araçta yer alan bazı desenler açıklanmaktadır.
İhtiyacınız olan öneri türüne göre Son çalıştırmalar bölmesini açabilirsiniz.
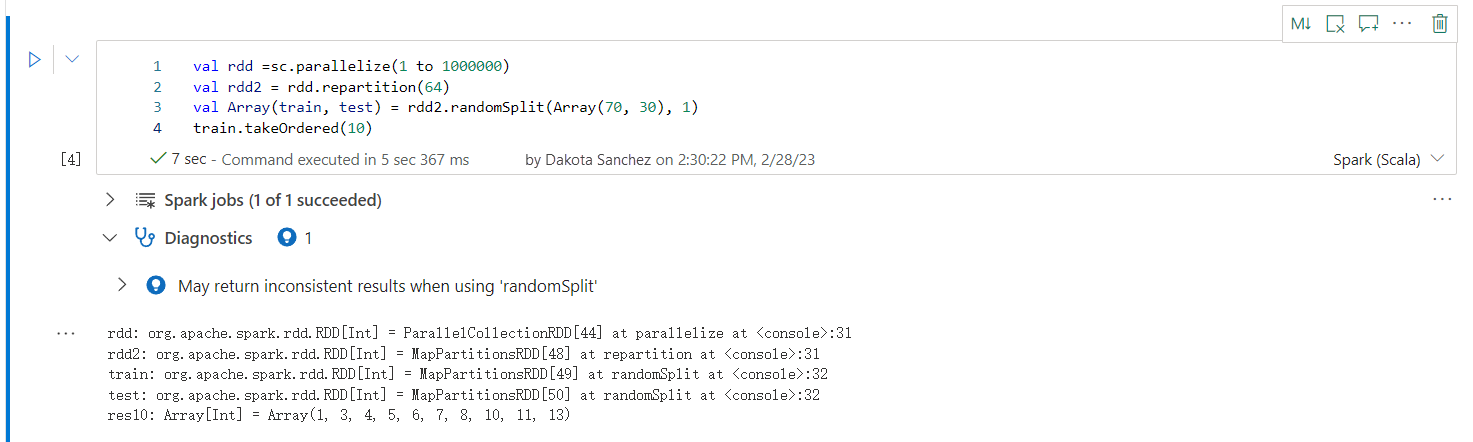
'randomSplit' kullanılırken tutarsız sonuçlar döndürebilir
randomSplit yöntemiyle çalışırken tutarsız veya yanlış sonuçlar döndürülebilir. randomSplit() yöntemini kullanmadan önce Apache Spark (RDD) önbelleğe alma özelliğini kullanın.
randomSplit() yöntemi, veri çerçevenizde birden çok kez sample() gerçekleştirmeye eşdeğerdir. Her örnek, bölümlerin içinde veri çerçevenizi refetches, partitions ve sorts. Bölümler arasında veri dağıtımı ve sıralama düzeni hem randomSplit() hem de sample() için önemlidir. Veri yeniden yapılandırmada değişiklik olursa, bölmeler arasında yinelenenler veya eksik değerler olabilir. Aynı tohumu kullanan örnek farklı sonuçlar verebilir.
Bu tutarsızlıklar her çalıştırmada gerçekleşmeyebilir, ancak bunları tamamen ortadan kaldırmak, veri çerçevenizi önbelleğe almak, sütunlarda yeniden bölümlenmek veya groupBy gibi toplama işlevlerini uygulamak için kullanılabilir.
Tablo/görünüm adı zaten kullanımda
Oluşturulan tabloyla aynı ada sahip bir görünüm zaten var veya oluşturulan görünümle aynı ada sahip bir tablo zaten var. Bu ad sorgularda veya uygulamalarda kullanıldığında, ilk olarak hangisinin oluşturulduğu fark etmez, yalnızca görünüm döndürülür. Çakışmaları önlemek için tabloyu veya görünümü yeniden adlandırın.
İpucu tanınamıyor
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Belirtilen ilişki adları bulunamıyor
İpucunda belirtilen ilişki bulunamıyor. İlişkinin doğru yazıldığını ve ipucu kapsamında erişilebilir olduğunu doğrulayın.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Sorgudaki bir ipucu, başka bir ipucunun uygulanmasını engeller
Seçili sorgu, başka bir ipucunun uygulanmasını engelleyen bir ipucu içeriyor.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Yuvarlama hatası yaymayı azaltmak için 'spark.advise.divisionExprConvertRule.enable' özelliğini etkinleştirin
Bu sorgu, Çift türü olan ifadeyi içerir. Bölme ifadelerini azaltmaya ve yuvarlama hatası yaymayı azaltmaya yardımcı olabilecek 'spark.advise.divisionExprConvertRule.enable' yapılandırmasını etkinleştirmenizi öneririz.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Sorgu performansını geliştirmek için 'spark.advise.nonEqJoinConvertRule.enable' özelliğini etkinleştirin
Bu sorgu, sorgudaki "Veya" koşulu nedeniyle zaman alan birleştirme içeriyor. Bu sorguyu hızlandırmak için "Veya" koşuluyla tetiklenen birleştirmeyi SMJ veya BHJ'ye dönüştürmeye yardımcı olabilecek 'spark.advise.nonEqJoinConvertRule.enable' yapılandırmasını etkinleştirmenizi öneririz.
Kullanıcı deneyimi
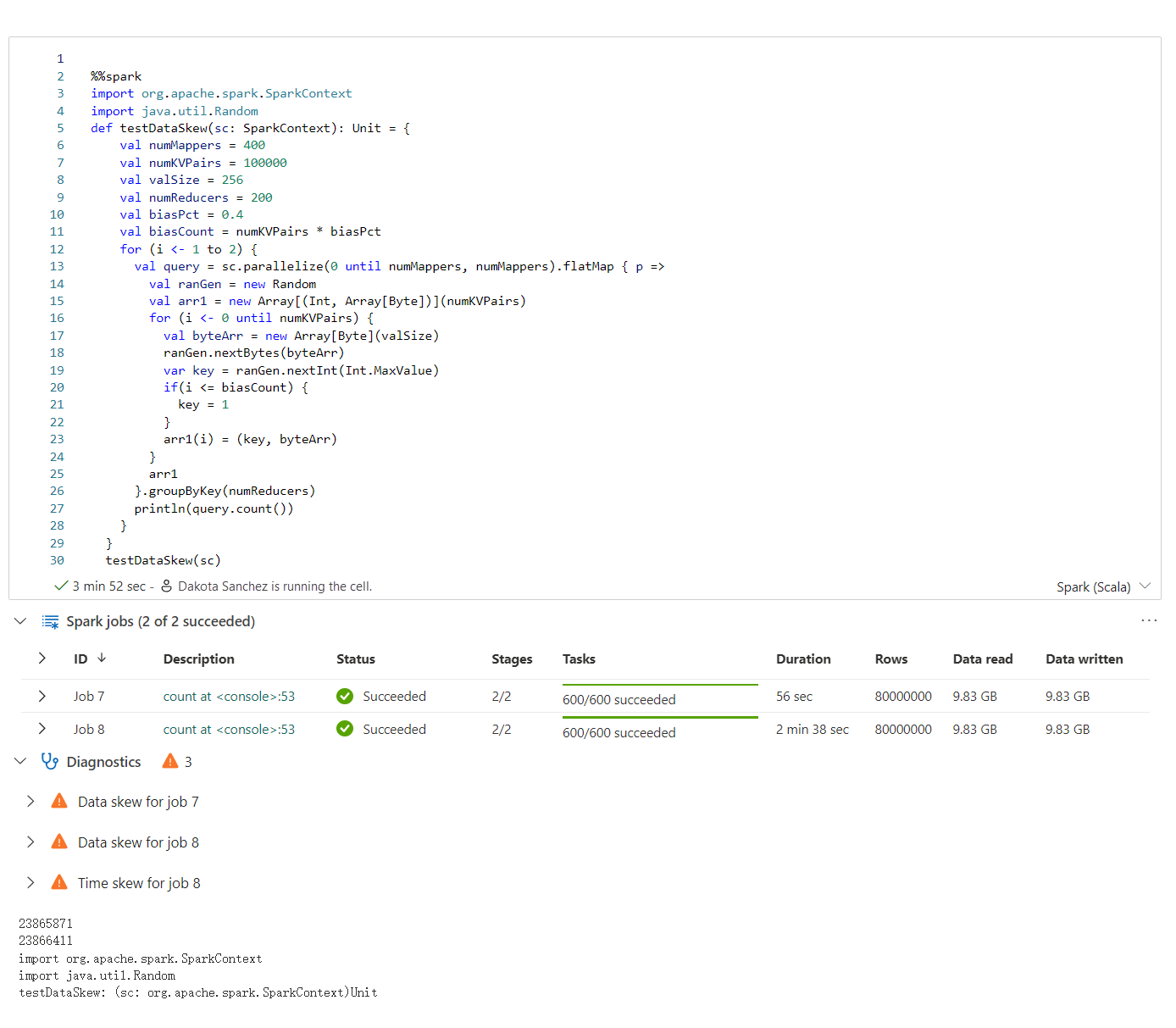
Apache Spark danışmanı, not defteri hücre çıkışında bilgiler, uyarılar ve hatalar gibi önerileri gerçek zamanlı olarak görüntüler.
Bilgi
Uyarı
Hata
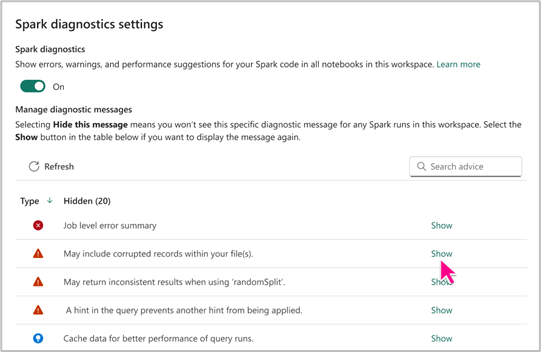
Spark Danışmanı Ayarı
Spark danışmanı ayarı, belirli Spark öneri türlerini gereksinimlerinize göre göstermeyi veya gizlemeyi seçmenizi sağlar. Ayrıca, tercihlerinize bağlı olarak çalışma alanı içindeki Not Defterleriniz için Spark Danışmanı'nı etkinleştirme veya devre dışı bırakma esnekliğine sahip olursunuz.
Avantajlarının keyfini çıkarmak ve üretken bir not defteri yazma deneyimi sağlamak için Doku Not Defteri düzeyinde Spark Danışmanı ayarlarına erişebilirsiniz.
İlgili içerik
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin