Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Boyutlandırmayı, iyileştirmeyi ve sorun gidermeyi temel kavramlar temel alır. Spark'ı Fabric içinde kullanmaya yeni başlıyorsanız, önce bunu okuyun.
Genel Yapılacaklar ve Yapılmayacaklar
Senaryo: Spark'ta yenisiniz. Yapılacaklar ve Yapılmayacaklar nelerdir?
| Kullanım örneği | En iyi yöntemler |
|---|---|
| Optimize edilmiş serileştirme formatlarını kullan | Do: Şema eklediklerinden, sıkıştırıldığından ve depolama ile işlemeyi iyileştirdiklerinden Avro, Parquet veya İyileştirilmiş Satır Sütunu (ORC) gibi biçimleri tercih edin. Dokuda Bölünmezlik, Tutarlılık, Yalıtım, Dayanıklılık (ACID) garantileri ve performans avantajları için Delta biçimini kullanın |
| XML/JSON konusunda dikkatli olun | Büyük JavaScript Nesne Gösterimi (JSON) veya Genişletilebilir Biçimlendirme Dili (XML) dosyaları için şema çıkarımına güvenmeyin çünkü Spark, işlemeyi yavaşlatan ve yoğun bellek tüketen şemayı çıkarsamak için veri kümesinin tamamını okur. JSON/XML okurken statik birincil şema sağlayın veya okumaları hızlandırmak için kullanın .option("samplingRatio", 0.1) , ancak örnek tam veri kümesini temsil etmiyorsa okumaların başarısız olabileceğini unutmayın. Daha güvenli bir yaklaşım, şemayı temsili bir örnekten çıkarır ve tüm okumalar için korur.Büyük XML dosyalarını ayrıştırmaktan kaçının. XML ayrıştırma, etiket işleme ve tür ataması nedeniyle doğal olarak daha yavaş çalışır. |
| Birleştirmeleri ve filtrelemeyi iyileştirme | Do: Karıştırma ve bellek kullanımını azaltmak için birleştirmelerden önce sütun ayıklama ve satır düzeyi filtreleme uygulayın. Catalyst iyileştiricisi, DataFrame API'lerini kullandığınızda koşul itelemesini otomatik olarak yönetir. Katalizör iyileştirmelerini atladıkları için Dayanıklı Dağıtılmış Veri Kümesi (RDD) API'lerinden kaçının. |
| RDD'ler yerine DataFrame'leri tercih edin | Do: Çoğu işlem için RDD yerine DataFrames kullanın. DataFrame'ler verimli yürütme için Catalyst iyileştiricisini ve Tungsten yürütme altyapısını kullanır. |
| Uyarlamalı sorgu yürütmeyi (AQE) etkinleştirme | Yapılması gereken: Karıştırma bölümlerini dinamik olarak optimize etmek ve çarpık verileri otomatik olarak işlemek için AQE'yi etkinleştirin. |
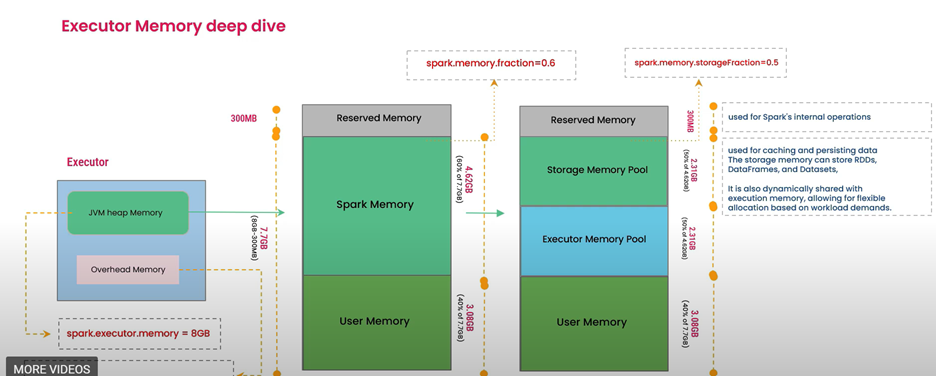
Yürütücü Bellek Yönetimi
Senaryo: Performans ayarlama için yürütücü bellek yönetimini anlamak istiyorsunuz.
Yürütücü 56 GB bellekle yapılandırılsa bile Spark, bunların tümünün doğrudan kullanıcı verileri için kullanılmasına izin vermez. Spark Core yürütücü belleği böler ve yönetir:
Ayrılmış Bellek: Sistem ve Spark'a özgü iç yükler (örneğin, Java Sanal Makinesi (JVM), dahili işlemler) için ayrılmış sabit bir bölüm.
Kullanıcı Belleği: Kullanıcı Tanımlı İşlevleri (UDF), yerel değişkenleri, veri yapılarını (listeler, haritalar, sözlükler) ve hesaplama sırasında oluşturulan nesneleri depolar.
Depolama Belleği: Önbelleğe alınmış/kalıcı verileri, yayın değişkenlerini ve önbelleğe alınabilen karıştırma verilerini tutar.
Yürütme Belleği: Ara hesaplamalar (karıştırmalar, birleştirmeler, sıralamalar, toplamalar) için kullanılır.
Dinamik Bellek Paylaşımı: Depolama ve Yürütme belleği arasındaki sınır taşınabilir. Spark, belleği bir bölgeden diğerine ödünç alabilir ve esnek bellek kullanımına olanak sağlar.
Taşma: Depolama veya Yürütme bellek talebi, ödünç alma sonrasında kullanılabilir belleği aştığında gerçekleşir. Bu, verileri diske zorlar ve bu da performansı etkileyebilir.

Bellek Yetersizliği (OOM) Hataları
Senaryo: Spark işleri Yetersiz Bellek (OOM) Hatalarıyla başarısız olur.
Sürücü OOM'u:
Spark sürücüsü ayrılan belleği aştığında sürücü OOM hataları oluşur.
Yaygın neden: , collect()gibi countByKey()yoğun sürücü işlemleri veya sürücü belleğine çok fazla veri çeken büyük toPandas() çağrılar.
Önlem: Mümkün olduğunca sürücü yoğun işlemlerden kaçının. Kaçınılmazsa, en iyi yapılandırmayı bulmak için sürücü boyutunu ve karşılaştırmayı artırın.
Yürütücü Yetersiz Bellek (OOM):
Spark yürütücüsü ayrılan belleği aştığında yürütücü OOM hataları oluşur.
Yaygın neden: Büyük veri kümelerinde bellek ve işlem yoğunluklu dönüştürmeler (örneğin, geniş birleşimler, toplamalar, karıştırmalar) veya yürütücülerin kullanılabilir belleğini (yürütme + depolama bölgeleri) aşan önbelleğe alınmış/kalıcı veri kümeleri.
Önlem: Gerekirse yürütücü belleğini artırın, Spark bellek kesirlerini (spark.memory.fraction, spark.memory.storageFraction) ayarlayın ve seçici olarak kalıcı hale getirin. Önbelleğe alınan verilerin kullanılabilir belleğe sığdığından emin olun.
Veri Dengesizliği
Dengesizlik belirtileri:
- Spark kullanıcı arabirimindeki birkaç görev diğerlerinden daha uzun sürer (aşama görevleri ağır kuyruk gösterir).
- Aşama ölçümlerinde ortanca ve maksimum görev süreleri arasında büyük boşluk.
- Birkaç bölüm için büyük shuffle okuma veya yazma boyutlarına sahip aşamalar.
Yaygın nedenler:
- Birleştirme/grup anahtarları (sık erişilen anahtarlar) için eşit olmayan veri dağıtımı.
- Veri birimi için yanlış bölümleme veya çok az bölümleme.
- Büyük kayıtlar veya çok sayıda null/boş anahtar üreten yukarı akış veri anomalileri.
Azaltma:
- Bölüm paralelliğini ve denge boyutlarını artırmak için yeniden bölümleme veya birleştirme.
- Yoğun anahtarları bölümlere yaymak için anahtar tuzlaması veya özel bölümlendirme uygulayın.
- Birleştirme sonrası bölümleri birleştirmek ve çarpık birleştirme iyileştirmelerini etkinleştirmek için AQE (Uyarlamalı Sorgu Yürütme) kullanın.
- Karışıklığı tamamen önlemek için küçük arama tablolarında yayın birleşimlerini kullanın.
- Dengeli ara veri kümelerini pahalı aşamalardan önce kalıcı hale getirebilir ve işi yeniden çalıştırabilirsiniz.
UDF En İyi Uygulamaları
Senaryo: Yerleşik DataFrame işlevleriyle ifade edilmeyecek özel mantık uygulamanız gerekir.
Mümkün olduğunda Spark DataFrame API'lerini kullanın. Catalyst iyileştiricisi yerleşik işlevleri iyileştirir ve bunları JVM'de yerel olarak çalıştırarak en iyi performansı sunar.
UDF (Kullanıcı Tanımlı İşlev) kullanmanız gerekiyorsa normal PySpark Python UDF'lerinden kaçının. Bunun yerine aşağıdaki alternatifleri göz önünde bulundurun:
Pandas UDF'leri (Vektörleştirilmiş UDF'ler olarak da bilinir): JVM ile Python arasında verimli veri aktarımı için Apache Arrow kullanın. Pandas UDF'leri vektörleştirilmiş işlemlere izin verir ve satır satır Python UDF'lerine kıyasla performansı önemli ölçüde artırır.
Scala/Java UDF'leri: Python serileştirme ek yükünü önleyerek doğrudan JVM üzerinde çalıştırın. Scala/Java UDF'leri genellikle Python UDF'lerini geride bıraktı.
Python UDF'leri konusunda dikkatli olun. Her yürütücü, JVM ile Python arasında verilerin seri hale getirilmesini ve seri durumdan çıkarılmasını gerektiren ayrı bir Python işlemi başlatır. Bu, özellikle de büyük ölçekte bir performans sorunu oluşturur.
Hata Kaydı
Senaryo: Fabric Spark'ta Hata Günlüğü için En İyi Uygulamalar
log4jyerine, sürücüye aşırı yük bindirenprint()kullanmayın. ilelog4jsürücü günlüklerindeki günlüklere erişebilir ve bunları arayabilirsiniz (günlükçü adını kullanarak, örneğin: PySparkLogger).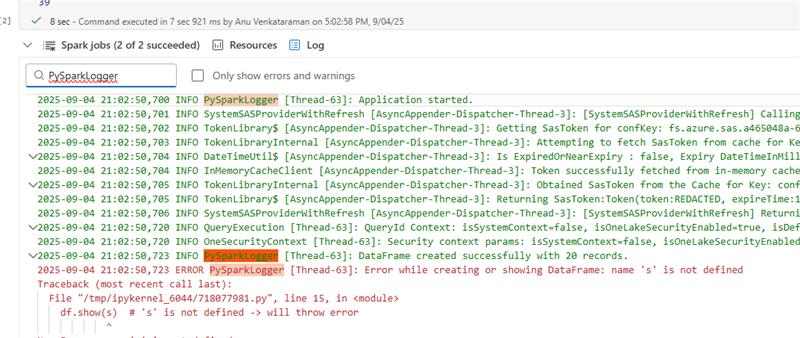
Okuma, yazma ve dönüşümleri try ve except blokları içine alın. Özel durumlar için
logger.error, ilerleme iletileri içinlogger.infokullanın.Python günlüğü: Yalnızca Spark Sürücüsünde yürütülen koddan günlüğe kaydetme işlemleri, durum güncelleştirmeleri veya hata ayıklama bilgileri için idealdir. Python'ın günlük modülü yürütücü günlüklerine yayılmaz. Not defterlerini geliştirme, yürütme ve yönetme belgelerine bakın.
Spark log4j: Spark'ın sürücü/yürütücü günlükleriyle yerel olarak tümleştirildiğinden Spark'ta sağlam, üretim düzeyinde uygulama günlüğü için standarttır.
PySpark'ta örnek log4j kullanımı:
import traceback # Get log4j logger log4jLogger = spark._jvm.org.apache.log4j logger = log4jLogger.LogManager.getLogger("PySparkLogger") logger.info("Application started.") try: # Create DataFrame with 20 records data = [(f"Name{i}", i) for i in range(1, 21)] # 20 records df = spark.createDataFrame(data, ["name", "age"]) logger.info("DataFrame created successfully with 20 records.") df.show(s) # 's' is not defined -> will throw error but the application will not fail except Exception as e: logger.error(f"Error while creating or showing DataFrame: {str(e)}\n{traceback.format_exc()}")Hata izlemeyi merkezileştirin:
Ortamda tanılama yayıcı uzantısını (Azure Log Analytics ile Apache Spark uygulamalarını izleme) kullanın ve Spark uygulamalarını çalıştıran Not Defterlerine ekleyin. Yayımlayıcı olay günlüklerini, özel günlükleri (log4j gibi) ve ölçümleri Azure Log Analytics/Azure Depolama/Azure Event Hubs'a gönderebilir. log4j adını özelliğine geçirin:
spark.synapse.diagnostic.emitter.\<destination\>.filter.loggerName.match.Ayrıca hata ayıklama için, hatalı satırları/kayıtları kayıt düzeyinde hatalı veri yakalama için Lakehouse (LH) tablolarına da toplayabilirsiniz.
