Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğreticide, lakehouse'unuzda ham verileri dönüştürmek ve hazırlamak için Spark çalışma zamanı ile not defterlerini kullanacaksınız.
Önkoşullar
Başlamadan önce, bu serideki önceki eğitimleri tamamlamanız gerekir:
- Göl evi oluşturma
- Lakehouse'a veri yükleme
- Lakehouse şemaları lakehouse'ınızda etkinleştirilmiş olduğundan emin olun.
Verileri hazırlama
Önceki öğretici adımlardan, kaynaktan lakehouse'un Dosyalar bölümüne alınan ham verileriniz bulunmaktadır. Artık bu verileri dönüştürebilir ve Delta tabloları oluşturmaya hazırlayabilirsiniz.
Not defterlerini Lakehouse Öğreticisi Kaynak Kodu klasöründen indirin.
Tarayıcınızda, Fabric portalında Fabric çalışma alanınıza gidin.
Bu bilgisayardan Not Defterini>İçeri> seçin.
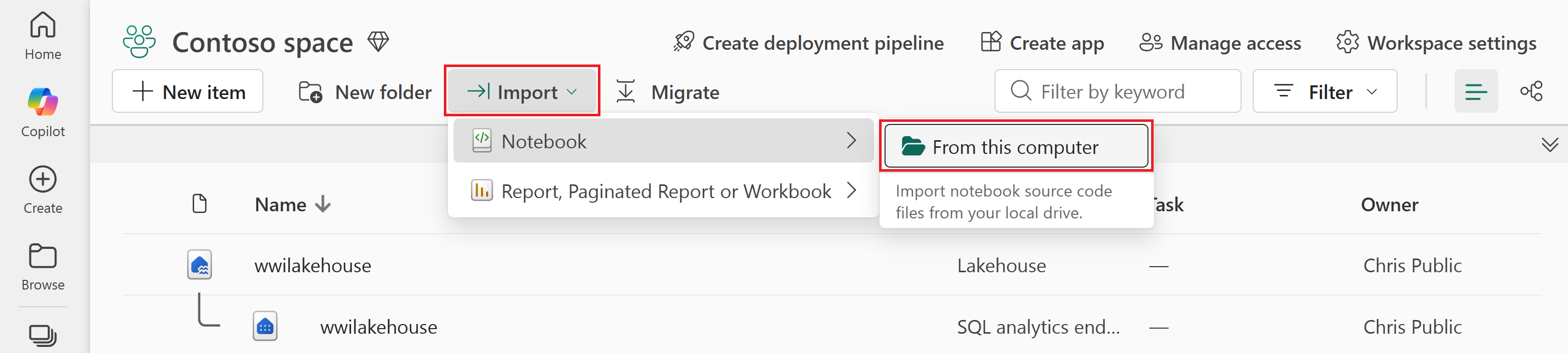
Ekranın sağ tarafında açılan İçe Aktarma durumu bölmesinden karşıya yükle'yi seçin.
Yalnızca tercih ettiğiniz kodlama diliyle eşleşen not defterini seçin.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Aç'ı seçin. tarayıcı penceresinin sağ üst köşesinde içeri aktarmanın durumunu belirten bir bildirim görüntülenir.
İçeri aktarma işlemi başarılı olduktan sonra, içeri aktarılan not defterini doğrulamak için çalışma alanının öğeler görünümüne gidin.
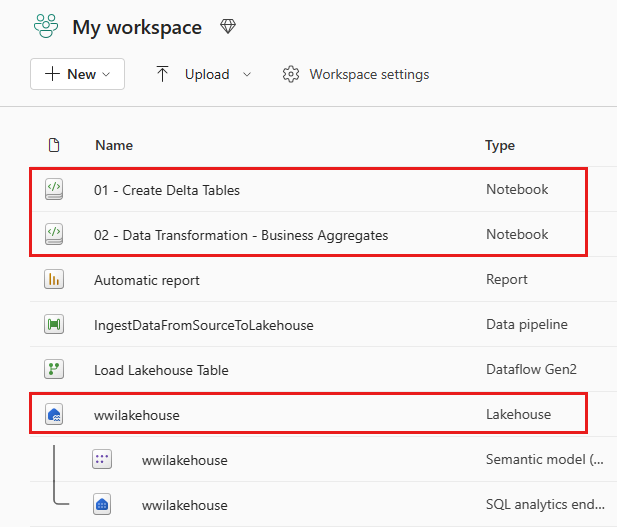
Wwilakehouse lakehouse'u seçerek açın; böylece bir sonraki açışınızda açtığınız not defteri buna bağlanır.
Üst gezinti menüsünden Not defterini aç> aç'ı seçin.
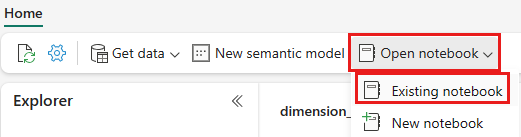
PySpark veya Spark SQL için içeri aktarılan not defterinizi seçin ve Aç'ı seçin. Not defteri, göl evi Gezgini'nde gösterildiği gibi açılmış göl evinizle zaten bağlantılıdır.



Artık Delta tablolarınızı oluşturan ve dönüştüren not defteri hücrelerini çalıştırmaya hazırsınız.
Aşağıdaki bölümlerde not defteri hücrelerini sıralı olarak çalıştırın. Bir hücreyi yürütmek için, üzerine gelindiğinde hücrenin solunda görünen Çalıştır simgesini seçin. Tüm hücreleri sırayla çalıştırmak için üst şeritte (Giriş) Tümünü çalıştır'ı da seçebilirsiniz.
Önemli
Bu kılavuz, lakehouse şemalarının etkinleştirilmesini gerektirir. Şemalar etkinleştirilmediyse, bu öğreticideki kod amaçlandığı gibi çalışmaz.
İçeri aktarılan not defterinde hem Yol 1 hem de Yol 2 bölümlerini görürsünüz. Bu öğretici kapsamında Yol 1'i (lakehouse şemaları etkin) kullanın ve Yol 2'yi yoksayın (lakehouse şemaları etkin değil).
Delta tabloları oluşturma
Bu bölümde, not defteri hücrelerini çalıştırarak ham verilerden Delta tabloları oluşturacaksınız.
Tablolar, analiz verilerini düzenlemeye yönelik yaygın bir desen olan yıldız şemasını izler:
-
Olgu tablosu (
fact_sale), işletmenin ölçülebilir olaylarını (bu örnekte miktarlar, fiyatlar ve kar içeren bireysel satış işlemleri) içerir. -
Boyut tabloları (
dimension_city,dimension_customer,dimension_date, ,dimension_employee),dimension_stock_itembir satışın nerede gerçekleştiği, kimin yaptığı ve ne zaman olduğu gibi olgulara bağlam sağlayan açıklayıcı öznitelikleri içerir.
Bu öğretici sayfasında, içeri aktardığınız not defteriyle eşleşen sekmeyi seçin ve tüm adımlar için aynı sekmeyi kullanmaya devam edin. Makalede sekmeler var, not defterinde değil.
Hücre 1 - Spark oturumu ayarları. Bu hücre, sonraki hücrelerde verilerin nasıl yazıldığını ve okunduğunu optimize eden iki Fabric özelliğini etkin hale getirir. V-order, daha hızlı okuma ve daha iyi sıkıştırma için Parquet dosya düzenini iyileştirir. Yazmayı iyileştirme , yazılan dosya sayısını azaltır ve tek tek dosya boyutunu artırır.
Bu hücreyi çalıştırın ve sonraki adıma geçmeden önce bitmesini bekleyin.
Hücre 2 - Olgu - Satış. Bu hücre,
Files/wwi-raw-data/full/fact_sale_1y_fullham parquet verilerini okur, tarih bölümü sütunlarını (Yıl, Çeyrek ve Ay) ekler vefact_sale, Yıl ve Çeyrek ile bölümlenmiş bir Delta tablosu olarak yazar.Bu hücreyi çalıştırın ve sonraki adıma geçmeden önce bitmesini bekleyin.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Hücre 3 - Boyutlar. Bu hücre, beş boyutlu parquet veri kümelerini okur ve Delta tabloları (
dimension_city,dimension_customer,dimension_date,dimension_employeevedimension_stock_item) olarakTables/dbo/...altında yazar.Bu hücreyi çalıştırın ve sonraki adıma geçmeden önce bitmesini bekleyin.
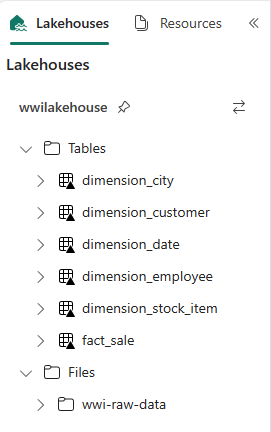
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Oluşturulan tabloları doğrulamak için gezginde wwilakehouse lakehouse'a sağ tıklayın ve yenile'yi seçin. Tablolar görüntülenir.

İş verisi toplamaları veya raporlamaları için verileri dönüştürme
Bu bölümde, aynı not defterinde devam eder ve sonraki hücreleri çalıştırarak önceki bölümde oluşturduğunuz Delta tablolarından toplama tabloları oluşturursunuz.
Not defterinin wwilakehouse'a bağlı olduğundan emin olun.
Hücre 4 - Dönüştürme için kaynak tabloları yükleyin (yalnızca PySpark). PySpark not defterini kullanıyorsanız, aşağıdaki toplama adımları için Delta tablolarını DataFrame'lere yüklemek için bu hücreyi çalıştırın.
Bu hücreyi çalıştırın ve sonraki adıma geçmeden önce bitmesini bekleyin.
Hücre 5 -
aggregate_sale_by_date_city'ı oluşturun. Bu hücre satış, tarih ve şehir verilerini birleştirir, ardından şehir düzeyinde toplama tablosunu oluşturur.Bu hücreyi çalıştırın ve sonraki adıma geçmeden önce bitmesini bekleyin.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Hücre 6 - Oluştur
aggregate_sale_by_date_employee. Bu hücre satış, tarih ve çalışan verilerini birleştirir, ardından çalışan düzeyinde toplama tablosunu oluşturur.Bu hücreyi çalıştırın ve sonraki adıma geçmeden önce bitmesini bekleyin.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Oluşturulan tabloları doğrulamak için gezginde wwilakehouse lakehouse'a sağ tıklayın ve yenile'yi seçin. Toplama tabloları görüntülenir.

Bu öğreticide veriler Delta lake dosyaları olarak yazılır. Fabric bu tabloları otomatik olarak bulur ve meta veri deposuna kaydeder, bu nedenle ayrı CREATE TABLE ifadeler çalıştırmanız gerekmez.