Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Microsoft Fabric, ölçeklenebilir PREDICT işlevini kullanarak machine learning modelleri kullanıma hazır hale getirmenizi sağlar. Bu işlev herhangi bir işlem altyapısında toplu puanlama desteği sağlar. Toplu tahminleri doğrudan bir Microsoft Fabric not defterinden veya belirli bir ML modelinin öğe sayfasından oluşturabilirsiniz.
Bu makalede, kendiniz kod yazarak veya toplu puanlama işlemini işleyen kılavuzlu bir kullanıcı arabirimi deneyimi kullanarak PREDICT uygulamasını öğreneceksiniz.
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak ücretsiz Microsoft Fabric deneme sürümüne kaydolabilirsiniz.
Microsoft Fabric'e giriş yapın.
Giriş sayfanızın sol alt köşesindeki deneyim değiştiriciyi kullanarak Fabric'e geçin.

Sınırlamalar
- PREDICT işlevi şu anda yalnızca aşağıdaki ML modeli çeşitlerini destekler:
- CatBoost
- Keras
- LightGBM
- ONNX
- Peygamber
- PyTorch
- Sklearn
- Spark
- İstatistik modelleri
- TensorFlow
- XGBoost
- PREDICT , ML modellerini imzaları doldurulmuş şekilde MLflow biçiminde kaydetmenizi gerektirir.
- PREDICT, çok tensörlü girişlere veya çıkışlara sahip ML modellerini desteklemez .
Bir defterden PREDICT çağırın.
PREDICT, Microsoft Fabric kayıt defterinde MLflow paketli modelleri destekler. Çalışma alanınızda zaten eğitilmiş ve kayıtlı bir ML modeli varsa, 2. adıma atlayabilirsiniz. Aksi takdirde, 1. adım örnek bir lojistik regresyon modelini eğitme konusunda size yol gösterecek örnek kod sağlar. Yordamın sonunda toplu tahminler oluşturmak için bu modeli kullanın.
Ml modelini eğitin ve MLflow'a kaydedin. Sonraki kod örneği, machine learning denemesi oluşturmak için MLflow API'sini kullanır ve ardından scikit-learn lojistik regresyon modeli için bir MLflow çalıştırması başlatır. Model sürümü daha sonra Microsoft Fabric kayıt defterinde depolanır ve kaydedilir. Modelleri eğitmek ve kendi denemelerinizi izlemek hakkında daha fazla bilgi için bkz. scikit-learn ile ML modellerini eğitmeyi öğrenin.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Test verilerini Spark DataFrame olarak yükleyin. Önceki adımda eğitilen ML modeliyle toplu tahminler oluşturmak için Spark DataFrame biçiminde test verilerine ihtiyacınız vardır. Aşağıdaki kodda değişken değerini kendi verilerinizle değiştirin
test.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Çıkarım için ML modelini yüklemek için bir
MLFlowTransformernesne oluşturun. Toplu tahminler oluşturmak üzere birMLFlowTransformernesne oluşturmak için şu eylemleri gerçekleştirin:- Model girişi olarak ihtiyacınız olan
testDataFrame sütunlarını belirtin (bu örnekte bunların tümü). - Yeni çıkış sütunu için bir ad seçin (bu örnekte).
predictions - Bu tahminlerin oluşturulması için doğru model adını ve model sürümünü sağlayın.
Kendi ML modelinizi kullanıyorsanız, giriş sütunları, çıkış sütunu adı, model adı ve model sürümü değerlerini değiştirin.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- Model girişi olarak ihtiyacınız olan
PREDICT işlevini kullanarak tahminler oluşturun. PREDICT işlevini çağırmak için Transformer API'sini, Spark SQL API'sini veya PySpark kullanıcı tanımlı işlevini (UDF) kullanın. Aşağıdaki bölümlerde, PREDICT işlevini çağırmak için farklı yöntemleri kullanarak önceki adımlarda tanımlanan test verileri ve ML modeliyle toplu tahminlerin nasıl oluşturulacağı gösterilmektedir.
Transformer API ile PREDICT
Bu kod Transformer API'siyle PREDICT işlevini çağırır. Kendi ML modelinizi kullanıyorsanız, modelin değerlerini değiştirin ve verileri test edin.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
Spark SQL API'siyle PREDICT
Bu kod Spark SQL API'sini kullanarak PREDICT işlevini çağırır. Kendi ML modelinizi kullanıyorsanız , model_nameve model_version değerlerini featuresmodel adınız, model sürümünüz ve özellik sütunlarınızla değiştirin.
Not
Tahmin oluşturmak için Spark SQL API'sini kullandığınızda, 3. adımda gösterildiği gibi yine de bir MLFlowTransformer nesne oluşturmanız gerekir.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
Kullanıcı tanımlı bir işlevle PREDICT
Bu kod, PySpark UDF kullanarak PREDICT işlevini çağırır. Kendi ML modelinizi kullanıyorsanız modelin ve özelliklerin değerlerini değiştirin.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
ML modelinin öğe sayfasından PREDICT kodu oluşturma
Herhangi bir ML modelinin öğe sayfasından PREDICT işlevini kullanarak belirli bir model sürümü için toplu tahmin oluşturmayı başlatmak üzere bu seçeneklerden birini belirleyebilirsiniz:
- Not defterine bir kod şablonu kopyalayın ve parametreleri kendiniz özelleştirin.
- PREDICT kodu oluşturmak için kılavuzlu kullanıcı arabirimi deneyimi kullanın.
Kılavuzlu kullanıcı arabirimi deneyimi kullanma
Kılavuzlu kullanıcı arabirimi deneyimi şu adımlarda size yol gösterir:
- Puanlama için kaynak verileri seçin.
- Verileri ML modeli girişlerinizle doğru şekilde eşleyin.
- Model çıkışlarınız için hedefi belirtin.
- Tahmin sonuçları oluşturmak ve depolamak için PREDICT kullanan bir not defteri oluşturun.
Destekli deneyimi kullanmak için
Belirli bir ML modeli sürümünün öğe sayfasına gidin.
Bu sürümünü uygula açılır listesinden Bu modeli sihirbaza uygula'yı seçin.
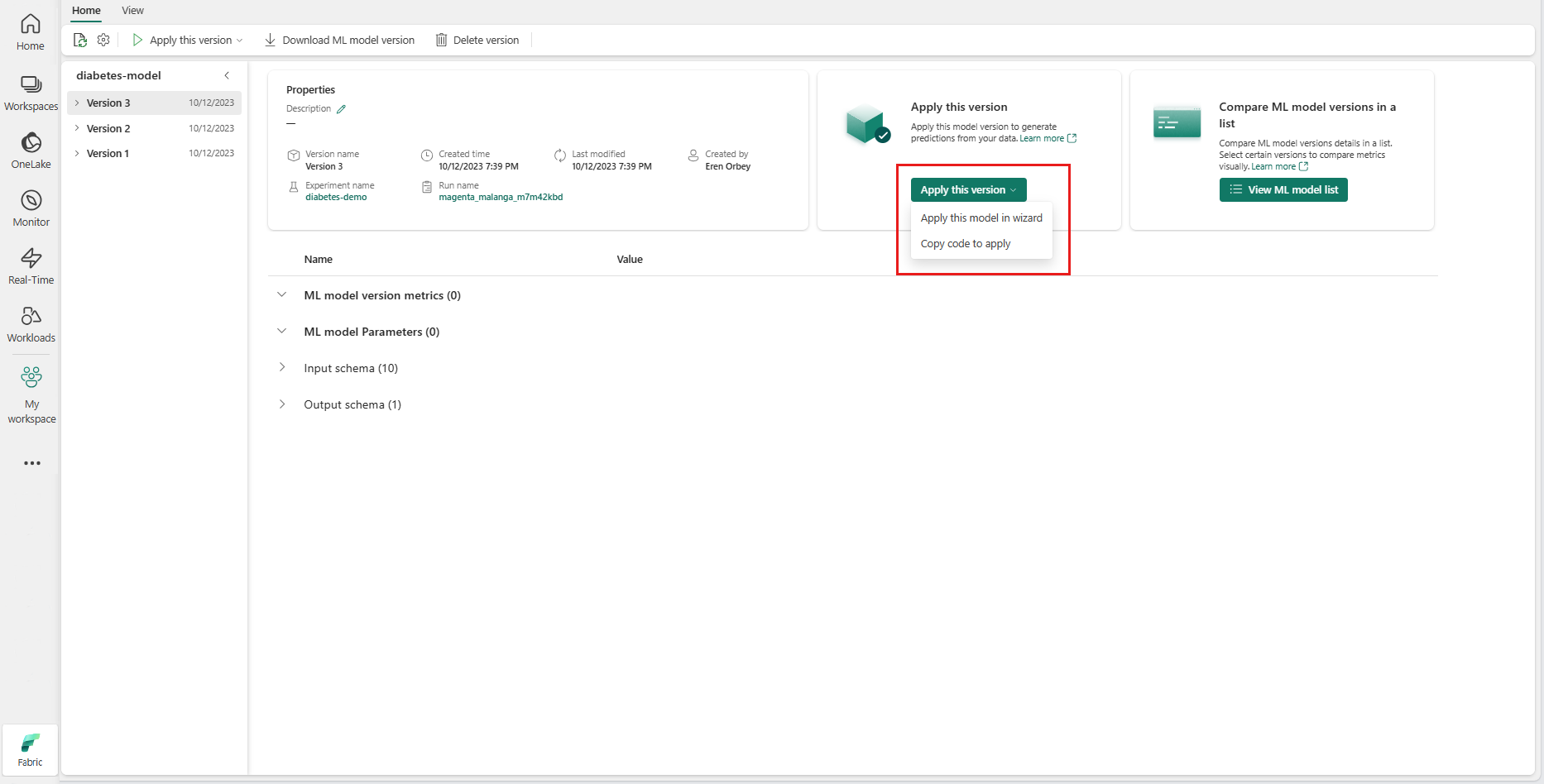
"Giriş tablosunu seçin" adımında "ML modeli tahminlerini uygula" penceresi açılır.
Geçerli çalışma alanınızdaki bir lakehouse'tan girdi tablosu seçin.

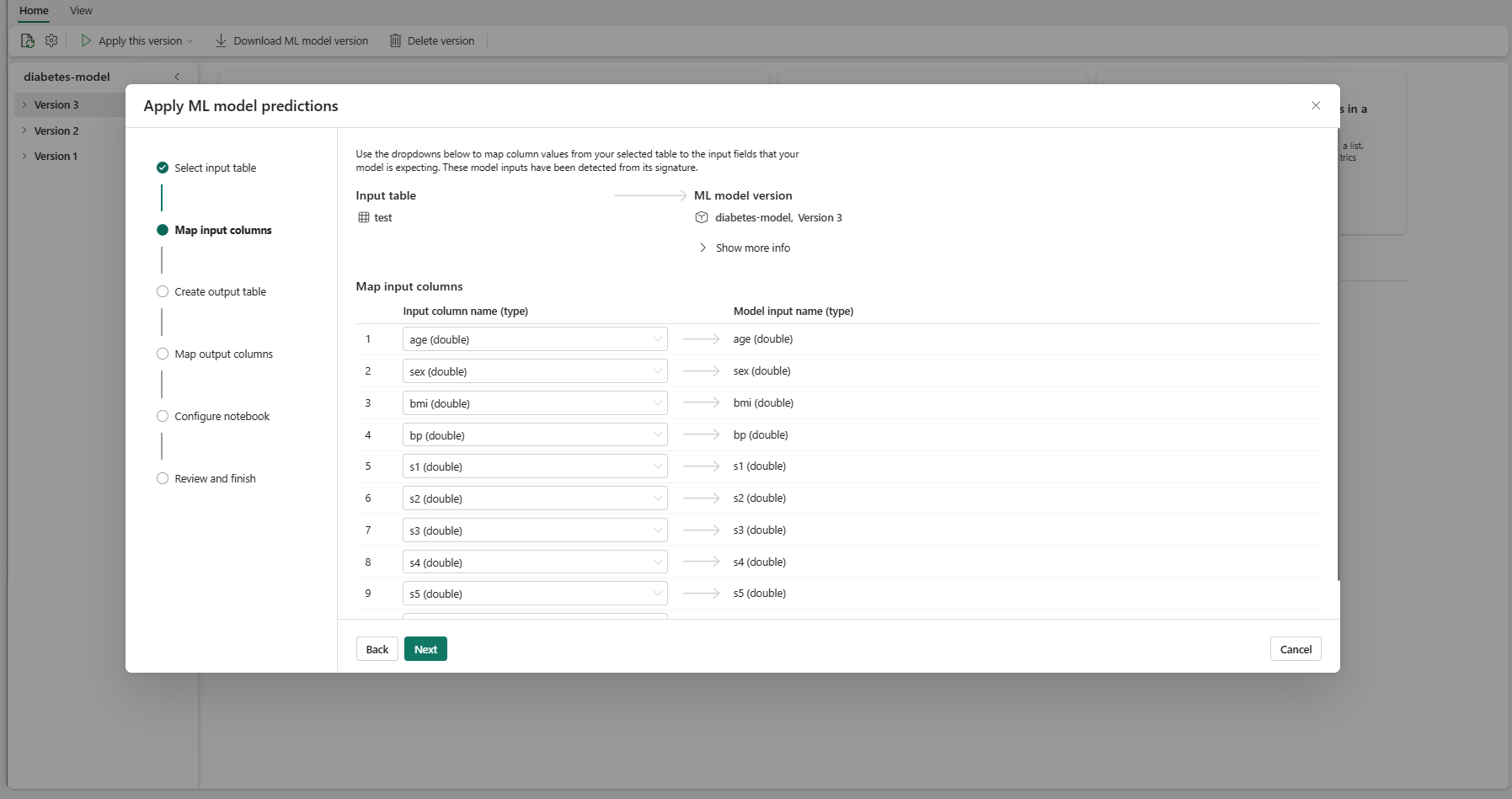
"Giriş sütunlarını eşle" adımına gitmek için İleri'yi seçin.
Kaynak tablodaki sütun adlarını, model imzasından alınan makine öğrenimi modelinin giriş alanlarıyla eşleştirin. Modelin tüm gerekli alanları için bir giriş sütunu sağlamanız gerekir. Ayrıca, kaynak sütun veri türlerinin modelin beklenen veri türleriyle eşleşmesi gerekir.
İpucu
Giriş tablosu sütunlarının adları ML modeli imzasında günlüğe kaydedilen sütun adlarıyla eşleşiyorsa, sihirbaz bu eşlemeyi önceden doldurur.
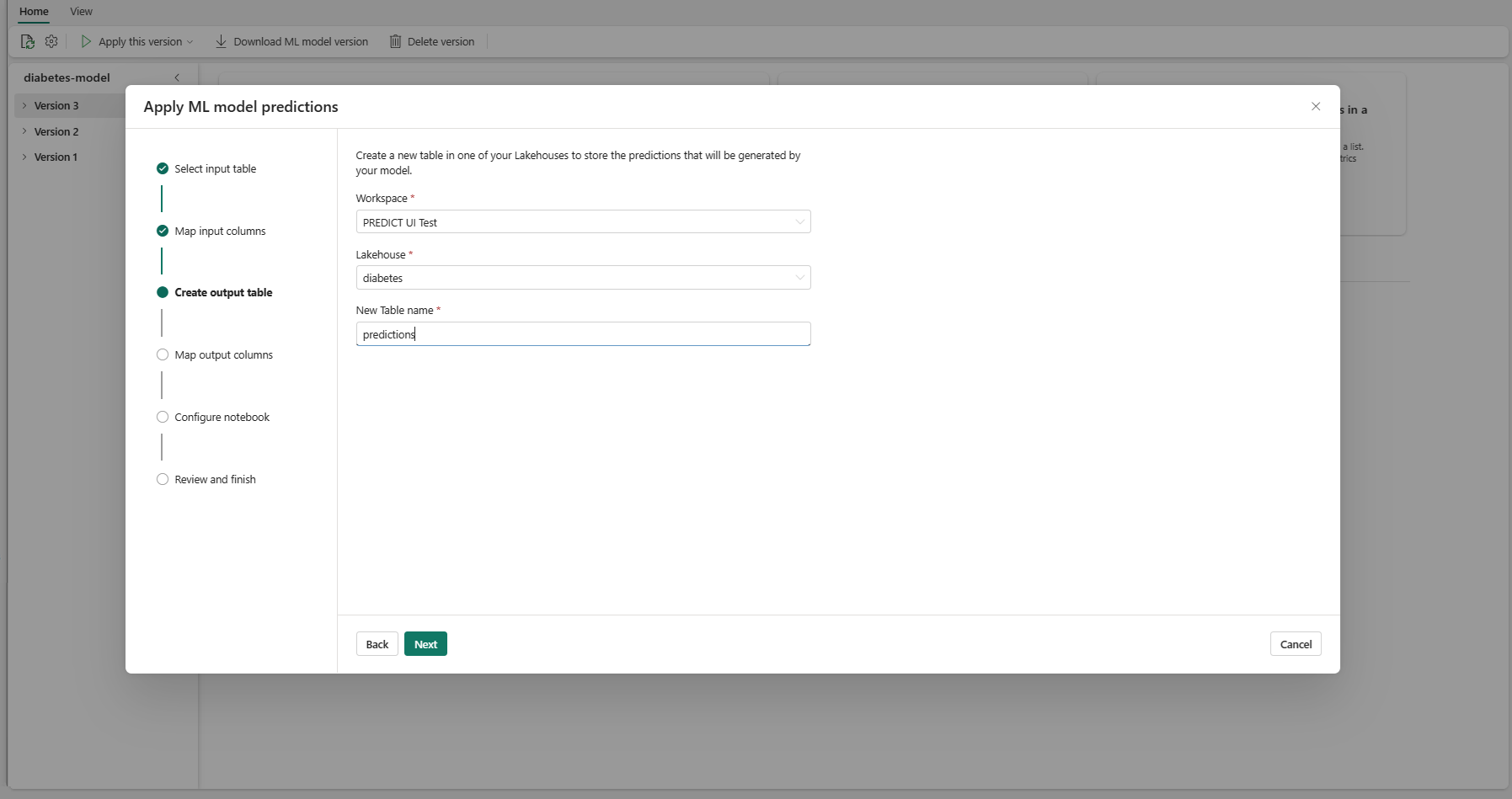
"Çıkış tablosu oluştur" adımına gitmek için İleri'yi seçin.
Seçili lakehouse'taki yeni tablo için, mevcut çalışma alanınızda bir ad sağlayın. Bu çıkış tablosu ML modelinizin giriş değerlerini depolar ve tahmin değerlerini bu tabloya ekler. Varsayılan olarak, çıkış tablosu giriş tablosuyla aynı lakehouse'da oluşturulur. Hedef lakehouse'unu değiştirebilirsiniz.
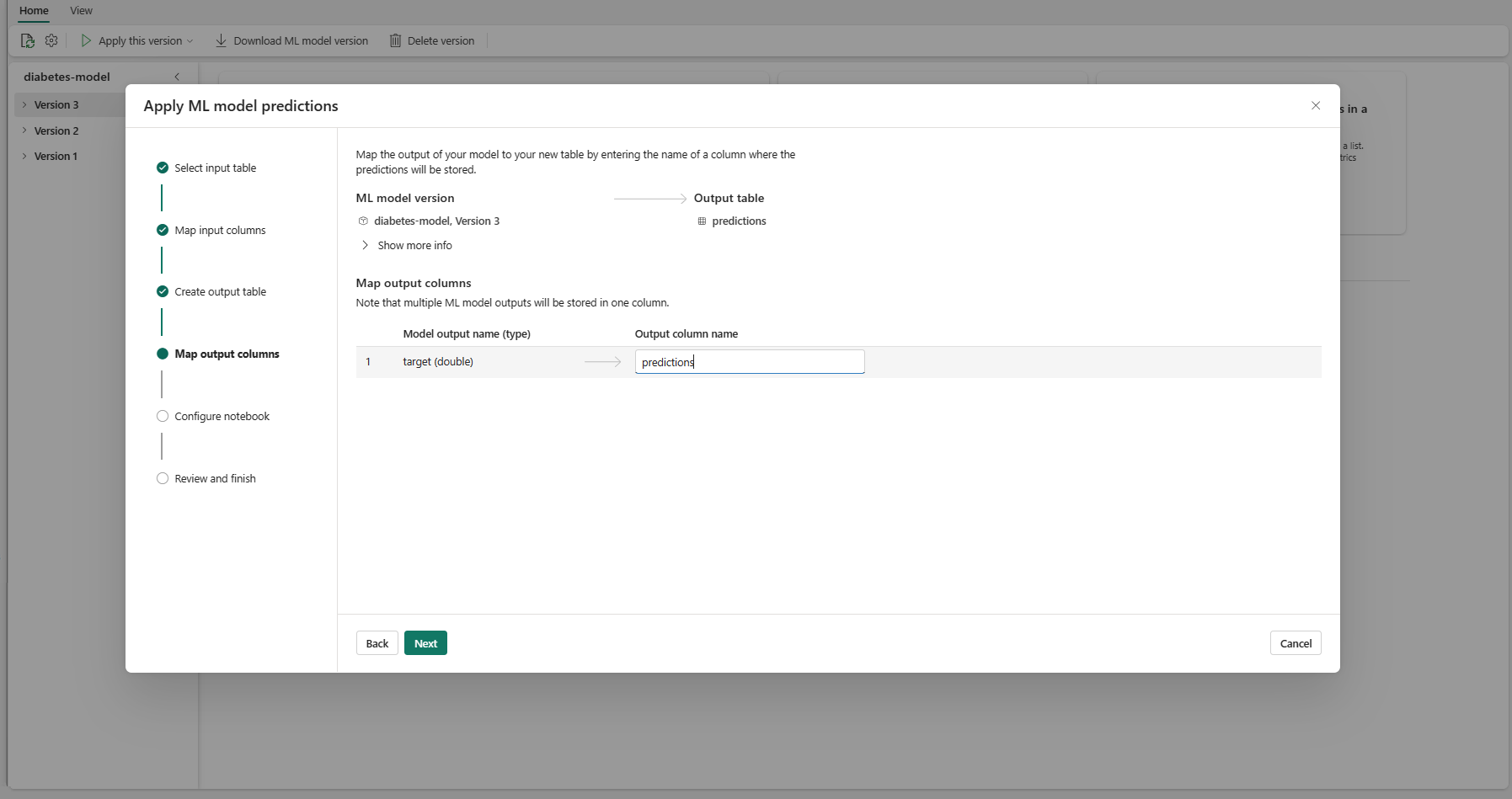
"Çıkış sütunlarını eşle" adımına gitmek için İleri'yi seçin.
Ml modeli tahminlerini depolayan çıktı tablosunun sütunlarını adlandırmak için sağlanan metin alanlarını kullanın.
"Not defterini yapılandır" adımına gitmek için İleri'yi seçin.
Oluşturulan PREDICT kodunu çalıştıran yeni bir not defteri için bir ad sağlayın. Sihirbaz, bu adımda oluşturulan kodun önizlemesini görüntüler. İsterseniz, kodu panonuza kopyalayıp var olan bir not defterine yapıştırabilirsiniz.
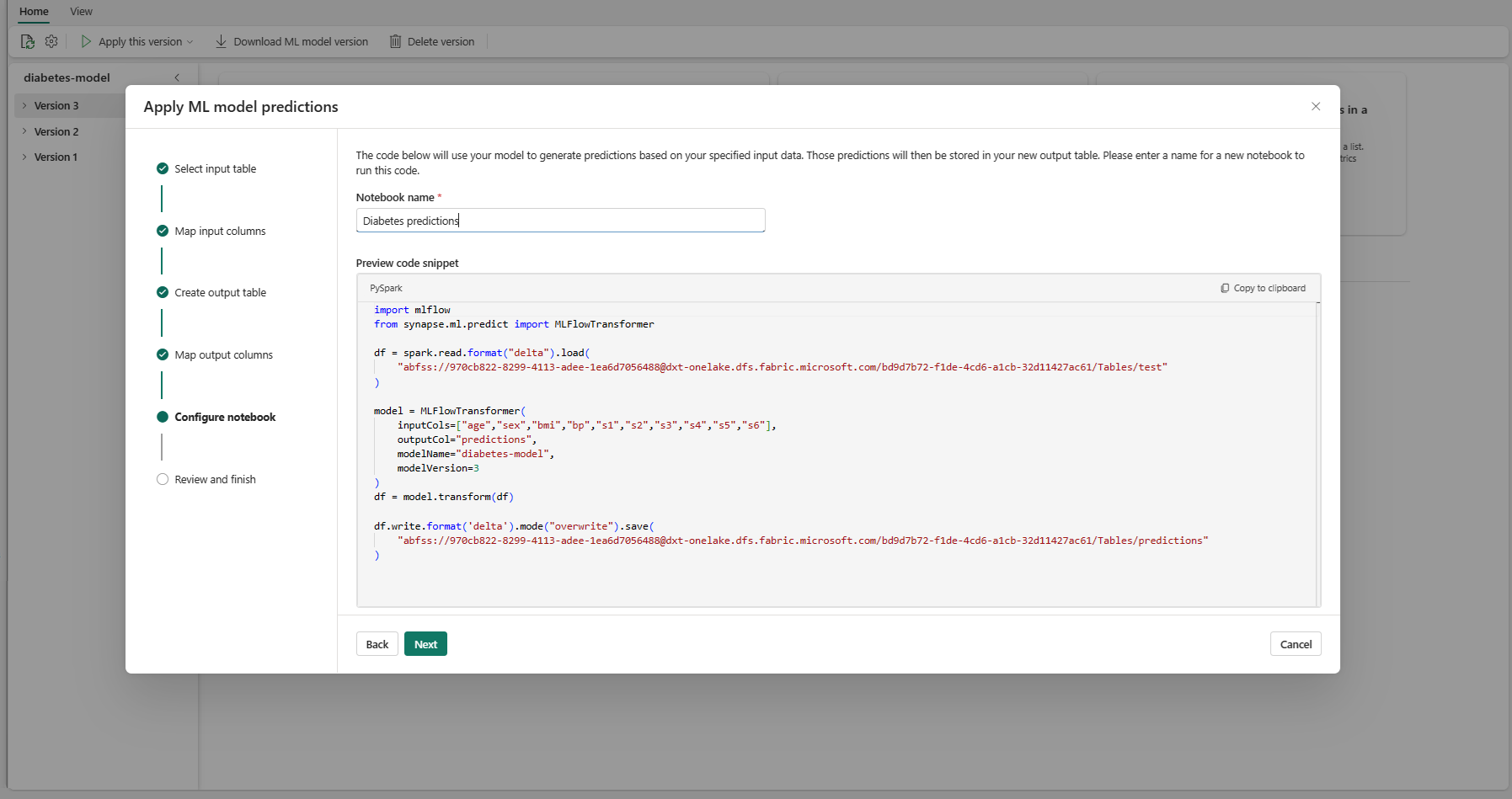
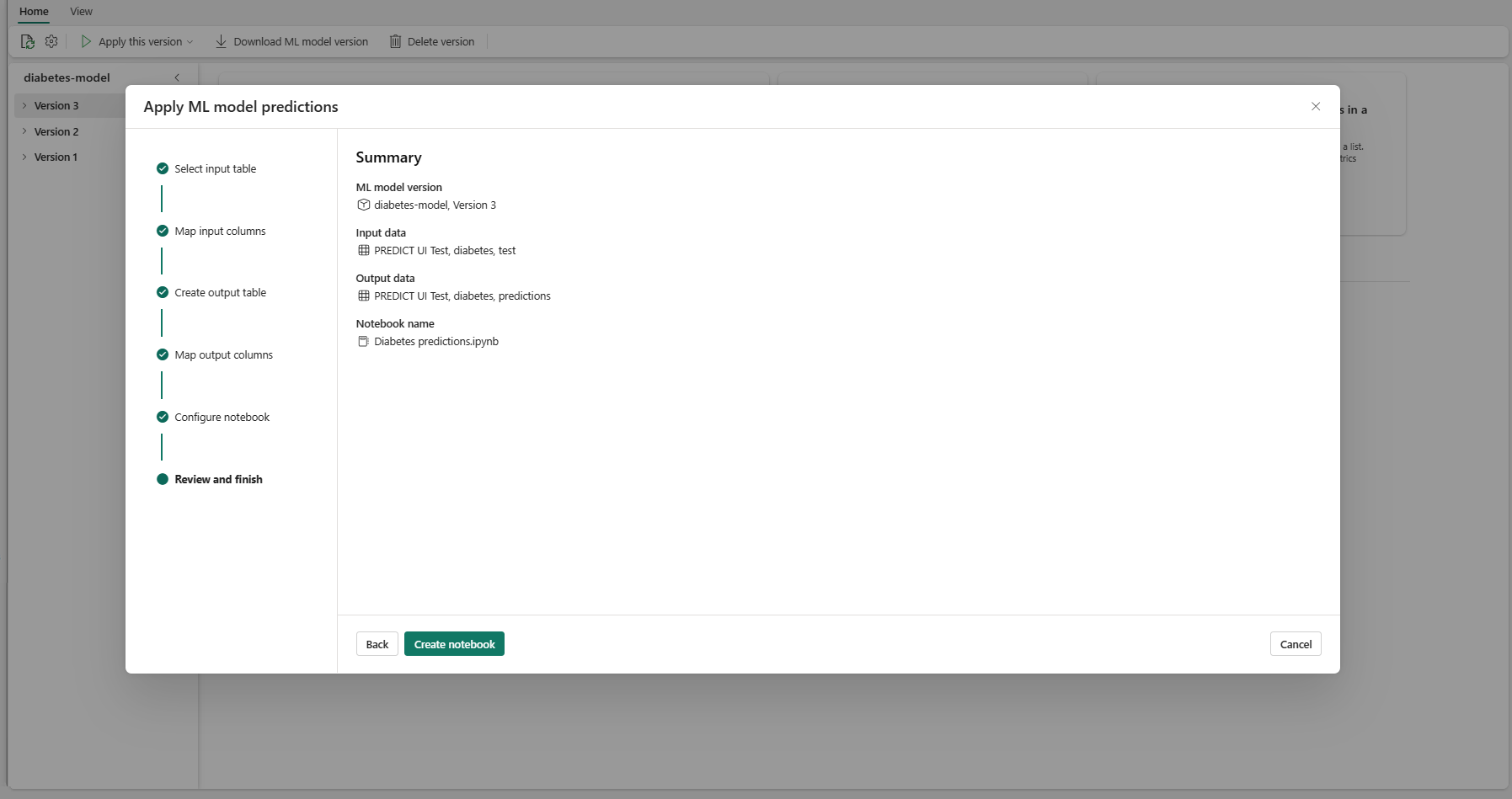
"Gözden geçir ve bitir" adımına gitmek için İleri'yi seçin.
Özet sayfasındaki ayrıntıları gözden geçirin ve oluşturulan kodu içeren yeni not defterini çalışma alanınıza eklemek için Not defteri oluştur'u seçin. Doğrudan bu not defterine yönlendirilirsiniz; burada tahminleri oluşturmak ve depolamak için kodu çalıştırabilirsiniz.







Özelleştirilebilir kod şablonu kullanma
Toplu tahminler oluşturmak için bir kod şablonu kullanmak için:
- Belirli bir ML modeli sürümü için öğe sayfasına gidin.
- Bu sürümü uygula açılan listesinden Uygulamak için Kodu kopyala seçeneğini seçin. Seçim, özelleştirilebilir bir kod şablonunu kopyalar.
ML modelinizle toplu tahminler oluşturmak için bu kod şablonunu bir not defterine yapıştırabilirsiniz. Kod şablonunu başarıyla çalıştırmak için aşağıdaki değerleri el ile değiştirin:
-
<INPUT_TABLE>: ML modeline giriş sağlayan tablonun dosya yolu. -
<INPUT_COLS>: ML modeline beslemek için giriş tablosundan sütun adları dizisi. -
<OUTPUT_COLS>: Çıkış tablosunda tahminleri depolayan yeni bir sütunun adı. -
<MODEL_NAME>: Tahmin oluşturmak için kullanılacak ML modelinin adı. -
<MODEL_VERSION>: Tahmin oluşturmak için kullanılacak ML modelinin sürümü. -
<OUTPUT_TABLE>: Tahminleri depolayan tablonun dosya yolu.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)