Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, Azure Açık Veri Kümeleri ve Apache Spark kullanarak keşif veri analizi gerçekleştirmeyi öğreneceksiniz. Bu makale, New York City taksi veri kümesini analiz eder. Veriler Azure Açık Veri Kümeleri aracılığıyla kullanılabilir. Veri kümesinin bu alt kümesi sarı taksi yolculukları hakkında bilgi içerir: her yolculuk, başlangıç ve bitiş saati ve konumlar, maliyet ve diğer ilginç öznitelikler hakkında bilgiler.
Bu makalede şunları yapacaksınız:
- Verileri indirme ve hazırlama
- Verileri çözümleme
- Verileri görselleştirme
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz bir Microsoft Fabric deneme sürümüne kaydolun.
Giriş sayfanızın sol alt köşesindeki deneyim değiştiriciyi kullanarak Fabric'e geçin.

Verileri indirme ve hazırlama
Başlamak için New York City (NYC) Taxi veri kümesini indirin ve verileri hazırlayın.
PySpark kullanarak bir not defteri oluşturun. Yönergeler için bkz . Not defteri oluşturma.
Not
PySpark çekirdeği nedeniyle açıkça bağlam oluşturmanız gerekmez. spark bağlamı, ilk kod hücresini çalıştırdığınızda sizin için otomatik olarak oluşturulur.
Bu makalede, veri kümesini görselleştirmeye yardımcı olmak için birkaç farklı kitaplık kullanırsınız. Bu çözümlemeyi yapmak için aşağıdaki kitaplıkları içeri aktarın:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdHam veriler Parquet biçiminde olduğundan Spark bağlamını kullanarak dosyayı doğrudan DataFrame olarak belleğe çekebilirsiniz. Verileri almak ve bir Spark DataFrame oluşturmak için Açık Veri Kümeleri API'sini kullanın. Veri türlerini ve şemayı çıkarsamak için okuma özelliklerinde Spark DataFrame şemasını kullanın.
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Veriler okunduktan sonra veri kümesini temizlemek için bazı ilk filtrelemeler yapın. Gereksiz sütunları kaldırabilir ve önemli bilgileri ayıklayan sütunlar ekleyebilirsiniz. Ayrıca veri kümesindeki anomalileri filtreleyebilirsiniz.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Verileri çözümleme
Veri analisti olarak, verilerden içgörüler elde etmenize yardımcı olacak çok çeşitli araçlara sahipsiniz. Makalenin bu bölümünde, Microsoft Fabric not defterlerinde kullanılabilen birkaç yararlı araç hakkında bilgi edinin. Bu analizde, seçilen dönem için daha yüksek taksi ipuçları veren faktörleri anlamak istiyorsunuz.
Apache Spark SQL Magic
İlk olarak, Microsoft Fabric not defteriyle Apache Spark SQL ve magic komutlarını kullanarak keşif veri analizi yapın. Sorguyu aldıktan sonra, yerleşik chart options özelliği kullanarak sonuçları görselleştirin.
Not defterinde yeni bir hücre oluşturun ve aşağıdaki kodu kopyalayın. Bu sorguyu kullanarak, ortalama ipucu tutarlarının seçtiğiniz süre boyunca nasıl değiştiğini anlayabilirsiniz. Bu sorgu, günlük minimum/maksimum ipucu miktarı ve ortalama ücret miktarı dahil olmak üzere diğer yararlı içgörüleri belirlemenize de yardımcı olur.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCSorgunuzun çalışması tamamlandıktan sonra, grafik görünümüne geçerek sonuçları görselleştirebilirsiniz. Bu örnek, alanı anahtar ve
day_of_monthdeğer olarak belirterekavgTipAmountbir çizgi grafik oluşturur. Seçimleri yaptıktan sonra grafiğinizi yenilemek için Uygula'yı seçin.
Verileri görselleştirme
Yerleşik not defteri grafik seçeneklerine ek olarak, kendi görselleştirmelerinizi oluşturmak için popüler açık kaynak kitaplıkları kullanabilirsiniz. Aşağıdaki örneklerde, veri görselleştirmesi için yaygın olarak kullanılan Python kitaplıkları olan Seaborn ve Matplotlib'i kullanın.
Geliştirmeyi daha kolay ve daha az maliyetli hale getirmek için veri kümesini aşağı örnekle. Yerleşik Apache Spark örnekleme özelliğini kullanın. Ayrıca hem Seaborn hem de Matplotlib için Pandas DataFrame veya NumPy dizisi gerekir. Pandas DataFrame almak için komutunu kullanarak
toPandas()DataFrame'i dönüştürün.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Veri kümesindeki ipuçlarının dağılımını anlayabilirsiniz. İpucu miktarının ve sayısının dağılımını gösteren bir histogram oluşturmak için Matplotlib kullanın. Dağıtıma bağlı olarak, ipuçlarının 10 ABD dolarından küçük veya buna eşit tutarlara doğru eğildiğini görebilirsiniz.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()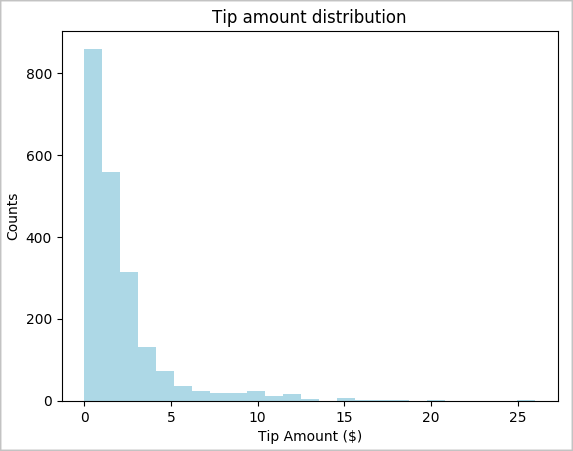
Daha sonra, belirli bir gezinin ipuçlarıyla haftanın günü arasındaki ilişkiyi anlamaya çalışın. Haftanın her günü için eğilimleri özetleyen bir kutu çizimi oluşturmak için Seaborn'u kullanın.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()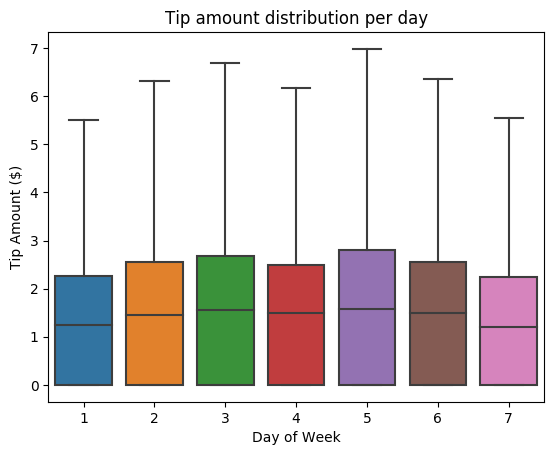
Başka bir hipotez, yolcu sayısı ile toplam taksi ipucu miktarı arasında pozitif bir ilişki olması olabilir. Bu ilişkiyi doğrulamak için aşağıdaki kodu çalıştırarak her yolcu sayısı için ipuçlarının dağılımını gösteren bir kutu çizimi oluşturun.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()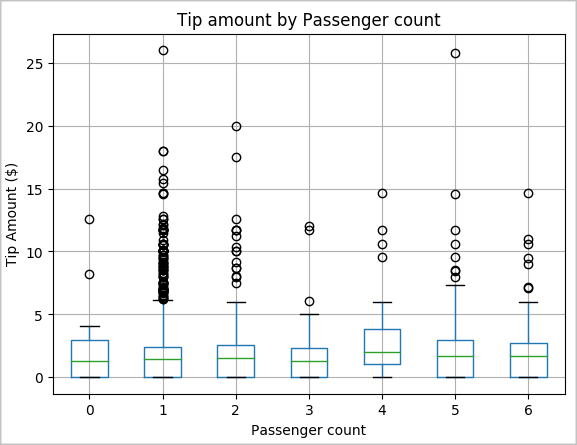
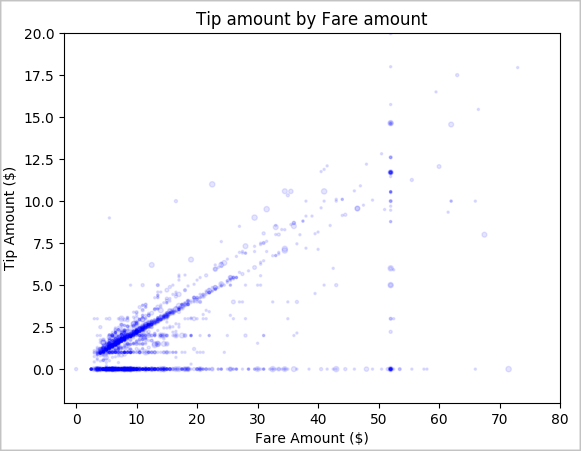
Son olarak, ücret tutarı ile ipucu miktarı arasındaki ilişkiyi keşfedin. Sonuçlara bağlı olarak, insanların ipucu vermediği çeşitli gözlemler olduğunu görebilirsiniz. Ancak, genel ücret ve ipucu miktarları arasında pozitif bir ilişki vardır.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()